 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVeriTeC: A Dataset for Real-world Claim Verification with Evidence from the Web
May 24, 2023Existing datasets for automated fact-checking have substantial limitations, such as relying on artificial claims, lacking annotations for evidence and intermediate reasoning, or including evidence published after the claim. In this paper we introduce AVeriTeC, a new dataset of 4,568 real-world claims covering fact-checks by 50 different organizations. Each claim is annotated with question-answer pairs supported by evidence available online, as well as textual justifications explaining how the evidence combines to produce a verdict. Through a multi-round annotation process, we avoid common pitfalls including context dependence, evidence insufficiency, and temporal leakage, and reach a substantial inter-annotator agreement of $\kappa=0.619$ on verdicts. We develop a baseline as well as an evaluation scheme for verifying claims through several question-answering steps against the open web.
The Intended Uses of Automated Fact-Checking Artefacts: Why, How and Who
Apr 27, 2023Automated fact-checking is often presented as an epistemic tool that fact-checkers, social media consumers, and other stakeholders can use to fight misinformation. Nevertheless, few papers thoroughly discuss how. We document this by analysing 100 highly-cited papers, and annotating epistemic elements related to intended use, i.e., means, ends, and stakeholders. We find that narratives leaving out some of these aspects are common, that many papers propose inconsistent means and ends, and that the feasibility of suggested strategies rarely has empirical backing. We argue that this vagueness actively hinders the technology from reaching its goals, as it encourages overclaiming, limits criticism, and prevents stakeholder feedback. Accordingly, we provide several recommendations for thinking and writing about the use of fact-checking artefacts.
Opening up Minds with Argumentative Dialogues
Jan 16, 2023



Recent research on argumentative dialogues has focused on persuading people to take some action, changing their stance on the topic of discussion, or winning debates. In this work, we focus on argumentative dialogues that aim to open up (rather than change) people's minds to help them become more understanding to views that are unfamiliar or in opposition to their own convictions. To this end, we present a dataset of 183 argumentative dialogues about 3 controversial topics: veganism, Brexit and COVID-19 vaccination. The dialogues were collected using the Wizard of Oz approach, where wizards leverage a knowledge-base of arguments to converse with participants. Open-mindedness is measured before and after engaging in the dialogue using a questionnaire from the psychology literature, and success of the dialogue is measured as the change in the participant's stance towards those who hold opinions different to theirs. We evaluate two dialogue models: a Wikipedia-based and an argument-based model. We show that while both models perform closely in terms of opening up minds, the argument-based model is significantly better on other dialogue properties such as engagement and clarity.
How to disagree well: Investigating the dispute tactics used on Wikipedia
Dec 16, 2022Disagreements are frequently studied from the perspective of either detecting toxicity or analysing argument structure. We propose a framework of dispute tactics that unifies these two perspectives, as well as other dialogue acts which play a role in resolving disputes, such as asking questions and providing clarification. This framework includes a preferential ordering among rebuttal-type tactics, ranging from ad hominem attacks to refuting the central argument. Using this framework, we annotate 213 disagreements (3,865 utterances) from Wikipedia Talk pages. This allows us to investigate research questions around the tactics used in disagreements; for instance, we provide empirical validation of the approach to disagreement recommended by Wikipedia. We develop models for multilabel prediction of dispute tactics in an utterance, achieving the best performance with a transformer-based label powerset model. Adding an auxiliary task to incorporate the ordering of rebuttal tactics further yields a statistically significant increase. Finally, we show that these annotations can be used to provide useful additional signals to improve performance on the task of predicting escalation.
* Accepted to EMNLP 2022 (Long paper)
Natural Logic-guided Autoregressive Multi-hop Document Retrieval for Fact Verification
Dec 10, 2022A key component of fact verification is thevevidence retrieval, often from multiple documents. Recent approaches use dense representations and condition the retrieval of each document on the previously retrieved ones. The latter step is performed over all the documents in the collection, requiring storing their dense representations in an index, thus incurring a high memory footprint. An alternative paradigm is retrieve-and-rerank, where documents are retrieved using methods such as BM25, their sentences are reranked, and further documents are retrieved conditioned on these sentences, reducing the memory requirements. However, such approaches can be brittle as they rely on heuristics and assume hyperlinks between documents. We propose a novel retrieve-and-rerank method for multi-hop retrieval, that consists of a retriever that jointly scores documents in the knowledge source and sentences from previously retrieved documents using an autoregressive formulation and is guided by a proof system based on natural logic that dynamically terminates the retrieval process if the evidence is deemed sufficient. This method is competitive with current state-of-the-art methods on FEVER, HoVer and FEVEROUS-S, while using $5$ to $10$ times less memory than competing systems. Evaluation on an adversarial dataset indicates improved stability of our approach compared to commonly deployed threshold-based methods. Finally, the proof system helps humans predict model decisions correctly more often than using the evidence alone.
What makes you change your mind? An empirical investigation in online group decision-making conversations
Jul 25, 2022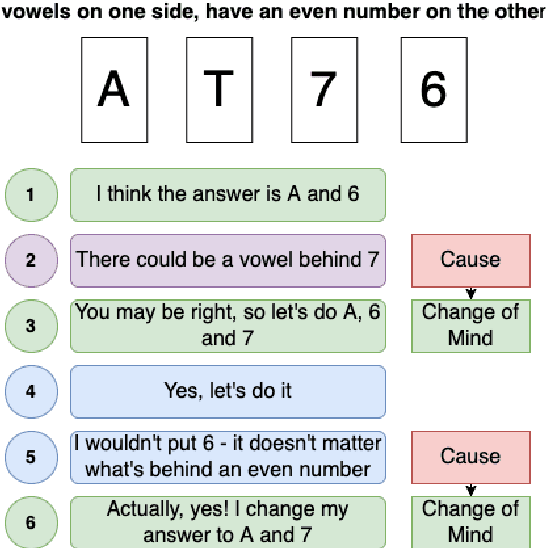
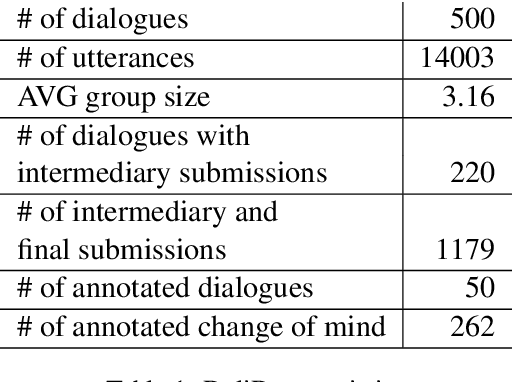
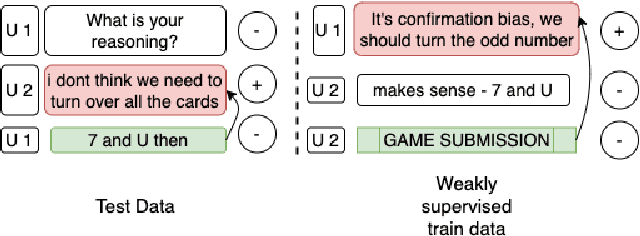
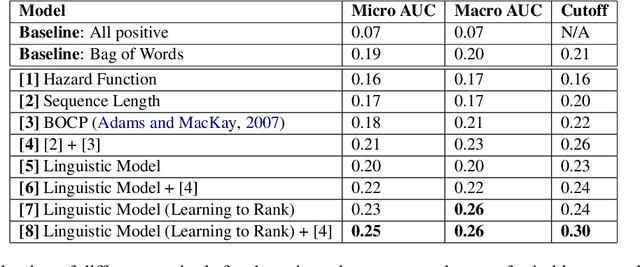
People leverage group discussions to collaborate in order to solve complex tasks, e.g. in project meetings or hiring panels. By doing so, they engage in a variety of conversational strategies where they try to convince each other of the best approach and ultimately reach a decision. In this work, we investigate methods for detecting what makes someone change their mind. To this end, we leverage a recently introduced dataset containing group discussions of people collaborating to solve a task. To find out what makes someone change their mind, we incorporate various techniques such as neural text classification and language-agnostic change point detection. Evaluation of these methods shows that while the task is not trivial, the best way to approach it is using a language-aware model with learning-to-rank training. Finally, we examine the cues that the models develop as indicative of the cause of a change of mind.
Policy Compliance Detection via Expression Tree Inference
May 24, 2022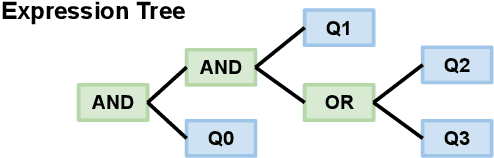

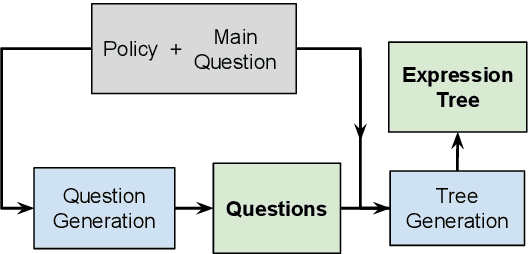
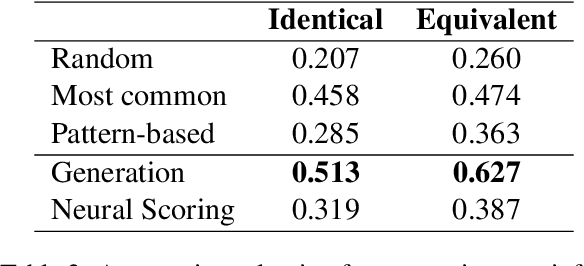
Policy Compliance Detection (PCD) is a task we encounter when reasoning over texts, e.g. legal frameworks. Previous work to address PCD relies heavily on modeling the task as a special case of Recognizing Textual Entailment. Entailment is applicable to the problem of PCD, however viewing the policy as a single proposition, as opposed to multiple interlinked propositions, yields poor performance and lacks explainability. To address this challenge, more recent proposals for PCD have argued for decomposing policies into expression trees consisting of questions connected with logic operators. Question answering is used to obtain answers to these questions with respect to a scenario. Finally, the expression tree is evaluated in order to arrive at an overall solution. However, this work assumes expression trees are provided by experts, thus limiting its applicability to new policies. In this work, we learn how to infer expression trees automatically from policy texts. We ensure the validity of the inferred trees by introducing constrained decoding using a finite state automaton to ensure the generation of valid trees. We determine through automatic evaluation that 63% of the expression trees generated by our constrained generation model are logically equivalent to gold trees. Human evaluation shows that 88% of trees generated by our model are correct.
Mitigating Catastrophic Forgetting in Scheduled Sampling with Elastic Weight Consolidation in Neural Machine Translation
Sep 13, 2021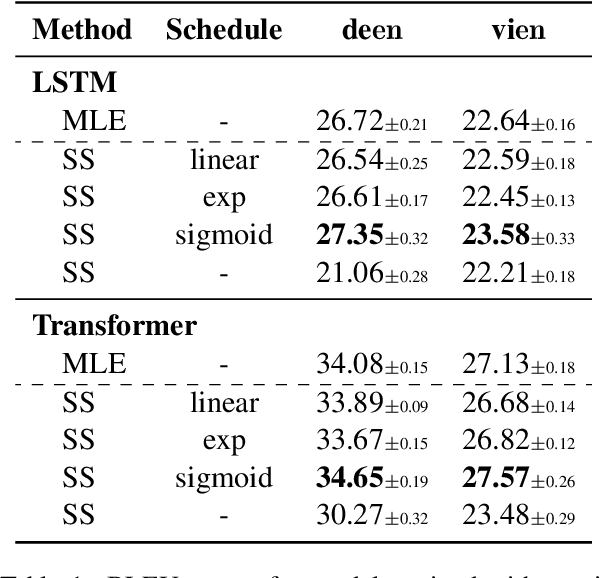
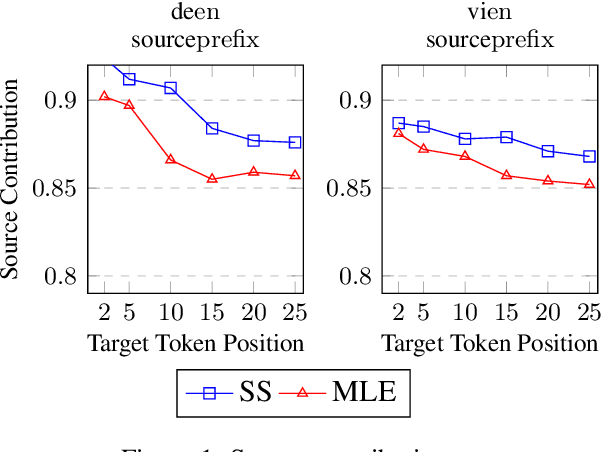
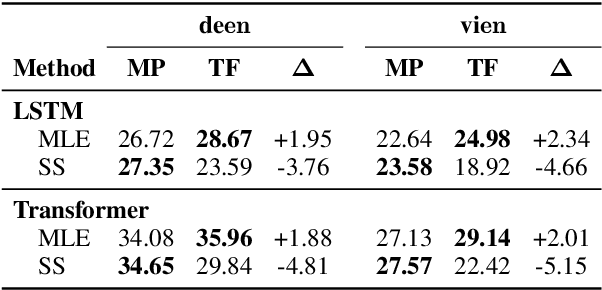
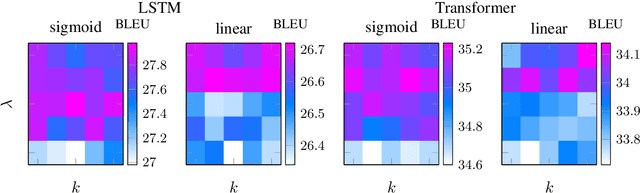
Despite strong performance in many sequence-to-sequence tasks, autoregressive models trained with maximum likelihood estimation suffer from exposure bias, i.e. a discrepancy between the ground-truth prefixes used during training and the model-generated prefixes used at inference time. Scheduled sampling is a simple and often empirically successful approach which addresses this issue by incorporating model-generated prefixes into the training process. However, it has been argued that it is an inconsistent training objective leading to models ignoring the prefixes altogether. In this paper, we conduct systematic experiments and find that it ameliorates exposure bias by increasing model reliance on the input sequence. We also observe that as a side-effect, it worsens performance when the model-generated prefix is correct, a form of catastrophic forgetting. We propose using Elastic Weight Consolidation as trade-off between mitigating exposure bias and retaining output quality. Experiments on two IWSLT'14 translation tasks demonstrate that our approach alleviates catastrophic forgetting and significantly improves BLEU compared to standard scheduled sampling.
Cross-Policy Compliance Detection via Question Answering
Sep 08, 2021


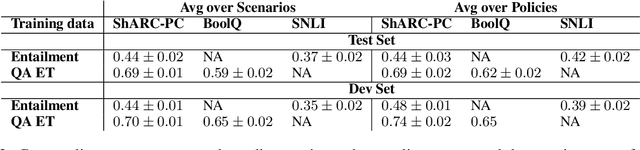
Policy compliance detection is the task of ensuring that a scenario conforms to a policy (e.g. a claim is valid according to government rules or a post in an online platform conforms to community guidelines). This task has been previously instantiated as a form of textual entailment, which results in poor accuracy due to the complexity of the policies. In this paper we propose to address policy compliance detection via decomposing it into question answering, where questions check whether the conditions stated in the policy apply to the scenario, and an expression tree combines the answers to obtain the label. Despite the initial upfront annotation cost, we demonstrate that this approach results in better accuracy, especially in the cross-policy setup where the policies during testing are unseen in training. In addition, it allows us to use existing question answering models pre-trained on existing large datasets. Finally, it explicitly identifies the information missing from a scenario in case policy compliance cannot be determined. We conduct our experiments using a recent dataset consisting of government policies, which we augment with expert annotations and find that the cost of annotating question answering decomposition is largely offset by improved inter-annotator agreement and speed.
A Survey on Automated Fact-Checking
Aug 26, 2021
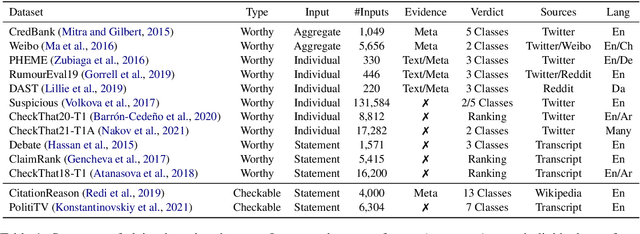
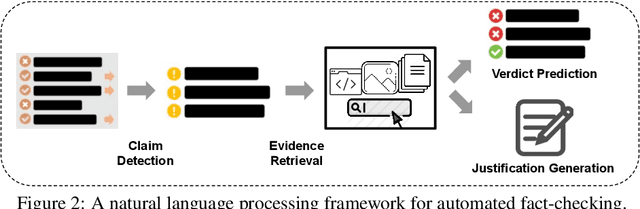
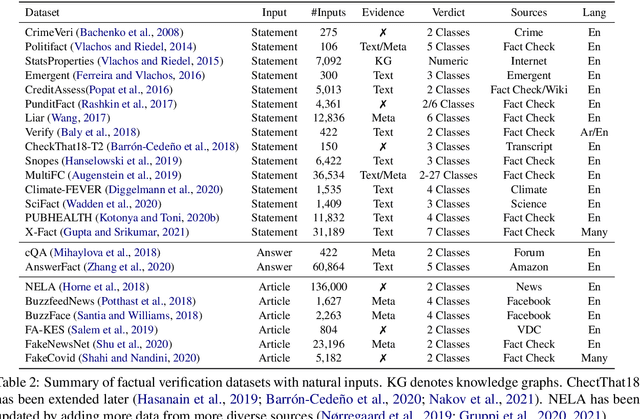
Fact-checking has become increasingly important due to the speed with which both information and misinformation can spread in the modern media ecosystem. Therefore, researchers have been exploring how fact-checking can be automated, using techniques based on natural language processing, machine learning, knowledge representation, and databases to automatically predict the veracity of claims. In this paper, we survey automated fact-checking stemming from natural language processing, and discuss its connections to related tasks and disciplines. In this process, we present an overview of existing datasets and models, aiming to unify the various definitions given and identify common concepts. Finally, we highlight challenges for future research.