 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat graph neural networks cannot learn: depth vs width
Jul 06, 2019
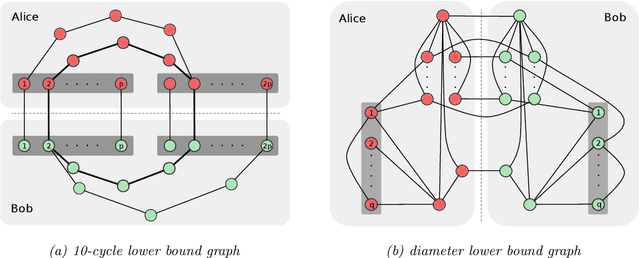
This paper studies the capacity limits of graph neural networks (GNN). Rather than focusing on a specific architecture, the networks considered here are those that fall within the message-passing framework, a model that encompasses several state-of-the-art networks. Two main results are presented. First, GNN are shown to be Turing universal under sufficient conditions on their depth, width, node identification, and layer expressiveness. In addition, it is discovered that GNN can lose a significant portion of their power when their depth and width is restricted. The proposed impossibility statements stem from a new technique that enables the re-purposing of seminal results from theoretical computer science. This leads to lower bounds for an array of decision, optimization, and estimation problems involving graphs. Strikingly, several of these problems are deemed impossible unless the product of a GNN's depth and width exceeds the graph size; this dependence remains significant even for tasks that appear simple or when considering approximation.
Discriminative structural graph classification
Jun 05, 2019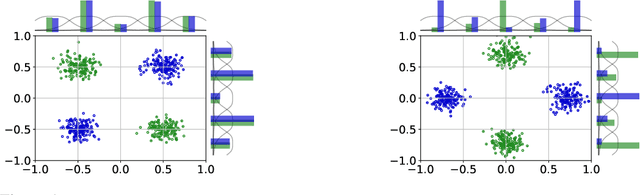

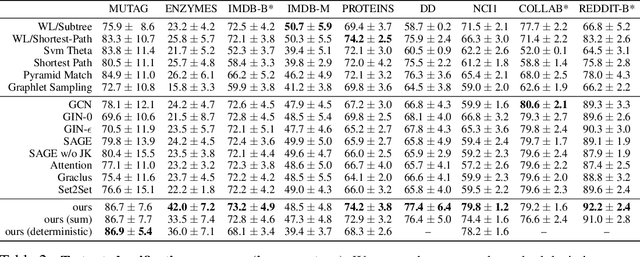
This paper focuses on the discrimination capacity of aggregation functions: these are the permutation invariant functions used by graph neural networks to combine the features of nodes. Realizing that the most powerful aggregation functions suffer from a dimensionality curse, we consider a restricted setting. In particular, we show that the standard sum and a novel histogram-based function have the capacity to discriminate between any fixed number of inputs chosen by an adversary. Based on our insights, we design a graph neural network aiming, not to maximize discrimination capacity, but to learn discriminative graph representations that generalize well. Our empirical evaluation provides evidence that our choices can yield benefits to the problem of structural graph classification.
Some limitations of norm based generalization bounds in deep neural networks
May 23, 2019
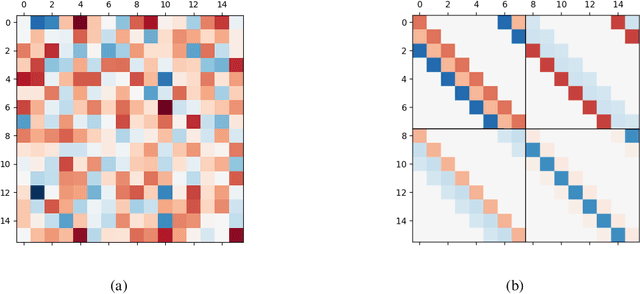

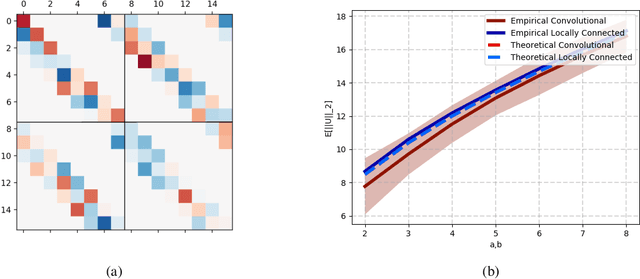
Deep convolutional neural networks have been shown to be able to fit a labeling over random data while still being able to generalize well on normal datasets. Describing deep convolutional neural network capacity through the measure of spectral complexity has been recently proposed to tackle this apparent paradox. Spectral complexity correlates with GE and can distinguish networks trained on normal and random labels. We propose the first GE bound based on spectral complexity for deep convolutional neural networks and provide tighter bounds by orders of magnitude from the previous estimate. We then investigate theoretically and empirically the insensitivity of spectral complexity to invariances of modern deep convolutional neural networks, and show several limitations of spectral complexity that occur as a result.
Extrapolating paths with graph neural networks
Mar 18, 2019
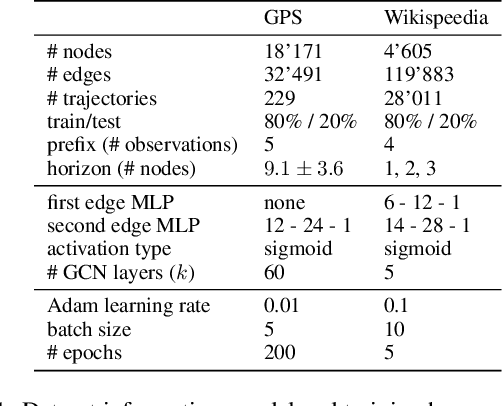
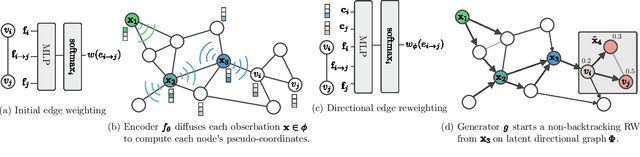
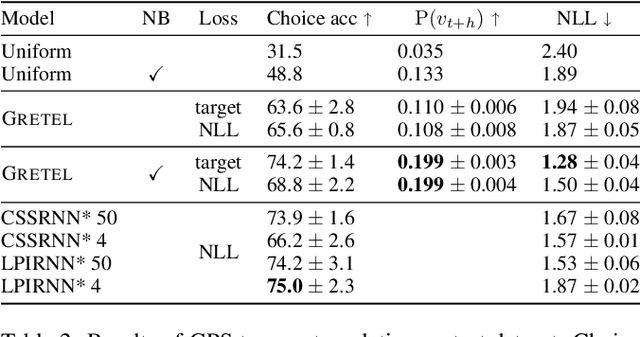
We consider the problem of path inference: given a path prefix, i.e., a partially observed sequence of nodes in a graph, we want to predict which nodes are in the missing suffix. In particular, we focus on natural paths occurring as a by-product of the interaction of an agent with a network---a driver on the transportation network, an information seeker in Wikipedia, or a client in an online shop. Our interest is sparked by the realization that, in contrast to shortest-path problems, natural paths are usually not optimal in any graph-theoretic sense, but might still follow predictable patterns. Our main contribution is a graph neural network called Gretel. Conditioned on a path prefix, this network can efficiently extrapolate path suffixes, evaluate path likelihood, and sample from the future path distribution. Our experiments with GPS traces on a road network and user-navigation paths in Wikipedia confirm that Gretel is able to adapt to graphs with very different properties, while also comparing favorably to previous solutions.
Approximating Spectral Clustering via Sampling: a Review
Jan 29, 2019
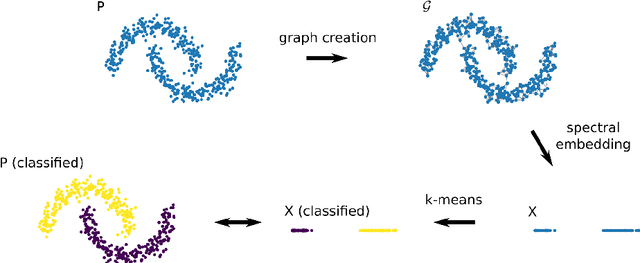
Spectral clustering refers to a family of unsupervised learning algorithms that compute a spectral embedding of the original data based on the eigenvectors of a similarity graph. This non-linear transformation of the data is both the key of these algorithms' success and their Achilles heel: forming a graph and computing its dominant eigenvectors can indeed be computationally prohibitive when dealing with more that a few tens of thousands of points. In this paper, we review the principal research efforts aiming to reduce this computational cost. We focus on methods that come with a theoretical control on the clustering performance and incorporate some form of sampling in their operation. Such methods abound in the machine learning, numerical linear algebra, and graph signal processing literature and, amongst others, include Nystr\"om-approximation, landmarks, coarsening, coresets, and compressive spectral clustering. We present the approximation guarantees available for each and discuss practical merits and limitations. Surprisingly, despite the breadth of the literature explored, we conclude that there is still a gap between theory and practice: the most scalable methods are only intuitively motivated or loosely controlled, whereas those that come with end-to-end guarantees rely on strong assumptions or enable a limited gain of computation time.
Graph reduction by local variation
Aug 31, 2018
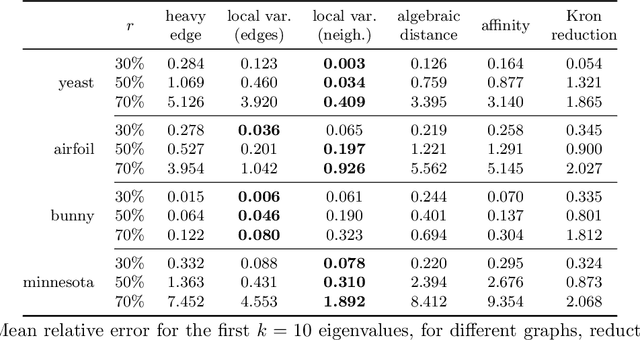
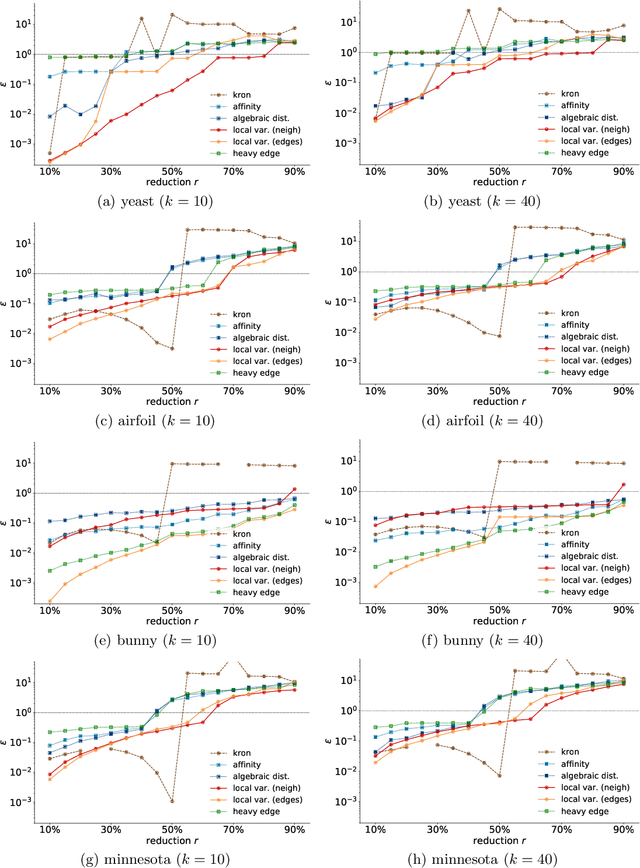
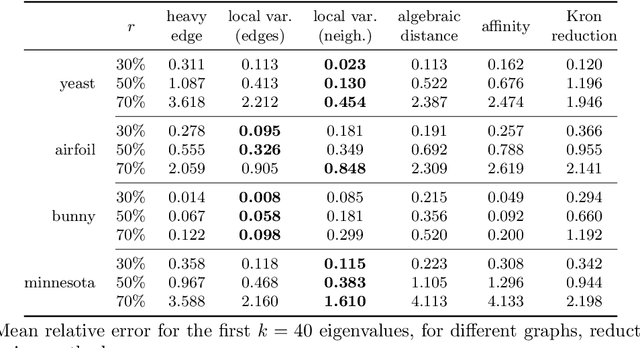
How can we reduce the size of a graph without significantly altering its basic properties? We approach the graph reduction problem from the perspective of restricted similarity, a modification of a well-known measure for graph approximation. Our choice is motivated by the observation that restricted similarity implies strong spectral guarantees and can be used to prove statements about certain unsupervised learning problems. The paper then focuses on coarsening, a popular type of graph reduction. We derive sufficient conditions for a small graph to approximate a larger one in the sense of restricted similarity. Our theoretical findings give rise to a novel quasi-linear algorithm. Compared to both standard and advanced graph reduction methods, the proposed algorithm finds coarse graphs of improved quality -often by a large margin- without sacrificing speed.
Spectrally approximating large graphs with smaller graphs
Feb 21, 2018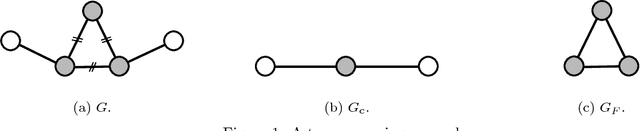
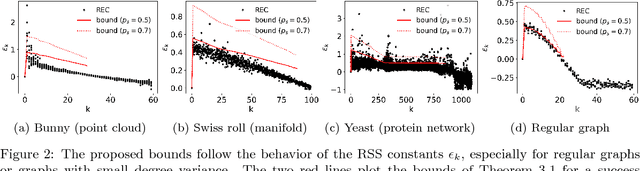
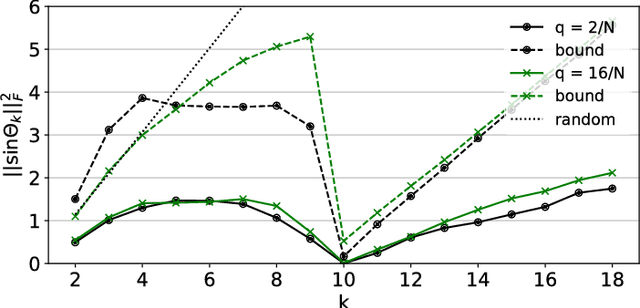
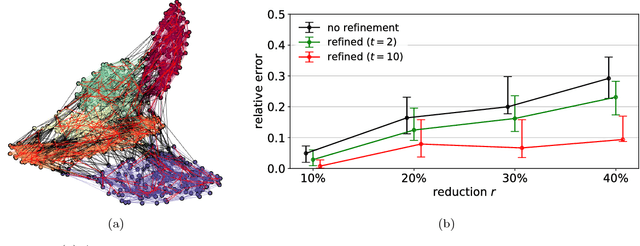
How does coarsening affect the spectrum of a general graph? We provide conditions such that the principal eigenvalues and eigenspaces of a coarsened and original graph Laplacian matrices are close. The achieved approximation is shown to depend on standard graph-theoretic properties, such as the degree and eigenvalue distributions, as well as on the ratio between the coarsened and actual graph sizes. Our results carry implications for learning methods that utilize coarsening. For the particular case of spectral clustering, they imply that coarse eigenvectors can be used to derive good quality assignments even without refinement---this phenomenon was previously observed, but lacked formal justification.
Fast Approximate Spectral Clustering for Dynamic Networks
Jun 12, 2017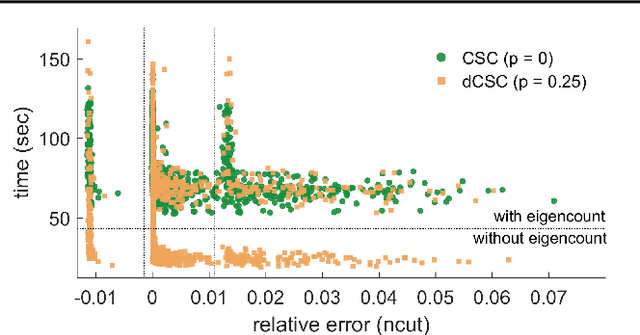
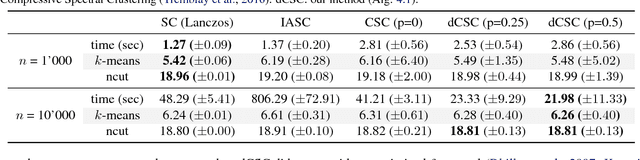
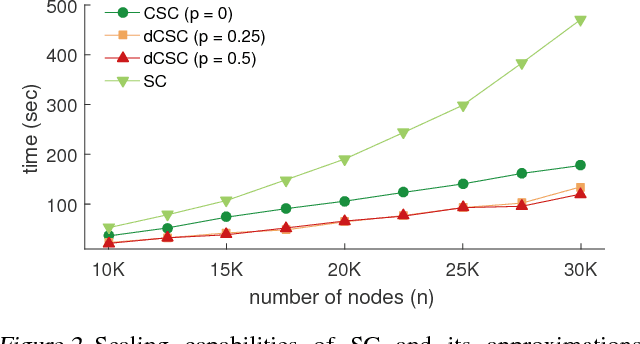
Spectral clustering is a widely studied problem, yet its complexity is prohibitive for dynamic graphs of even modest size. We claim that it is possible to reuse information of past cluster assignments to expedite computation. Our approach builds on a recent idea of sidestepping the main bottleneck of spectral clustering, i.e., computing the graph eigenvectors, by using fast Chebyshev graph filtering of random signals. We show that the proposed algorithm achieves clustering assignments with quality approximating that of spectral clustering and that it can yield significant complexity benefits when the graph dynamics are appropriately bounded.
Stationary time-vertex signal processing
May 23, 2017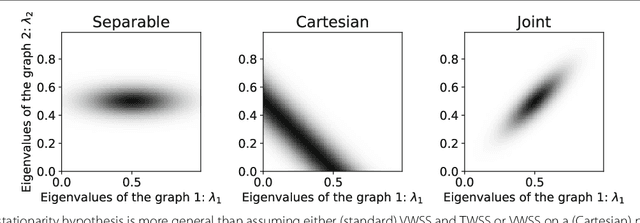
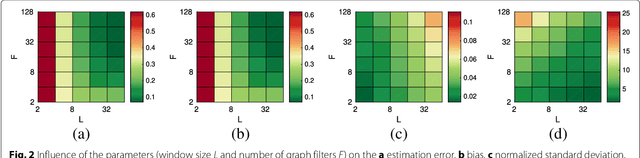
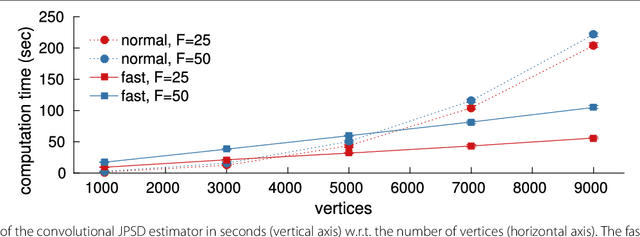
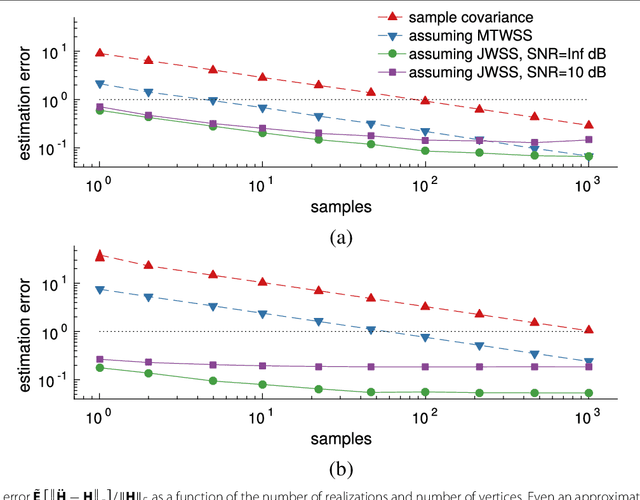
The goal of this paper is to improve learning for multivariate processes whose structure is dependent on some known graph topology; especially when the number of available samples is much smaller than the number of variables. Typically, the graph information is incorporated into the learning process via a smoothness assumption postulating that the values supported on well-connected vertices exhibit small variations. We argue that smoothness is not enough. To capture the behavior of complex interconnected systems, such as transportation and biological networks, it is important to train expressive models, being able to reproduce a wide range of graph and temporal behaviors. Motivated by this need, this paper puts forth a novel definition of time-vertex wide-sense stationarity, or joint stationarity for short. We believe that the proposed definition is natural, at it intimately relates to existing definitions of stationarity in the time and vertex domains. We use joint stationarity to regularize learning and to reduce computational complexity in both estimation and recovery tasks. In particular, we show that for any jointly stationary process: (a) one can learn the covariance structure from O(1) samples, and (b) can solve MMSE recovery problems, such as interpolation, denoising, forecasting, in complexity that is linear to the edges and timesteps. Experiments with three datasets suggest that joint stationarity can yield significant accuracy improvements in the reconstruction effort of under-sampled problems, even when the graph is only approximately known or the process is only close to stationary.
A Time-Vertex Signal Processing Framework
May 05, 2017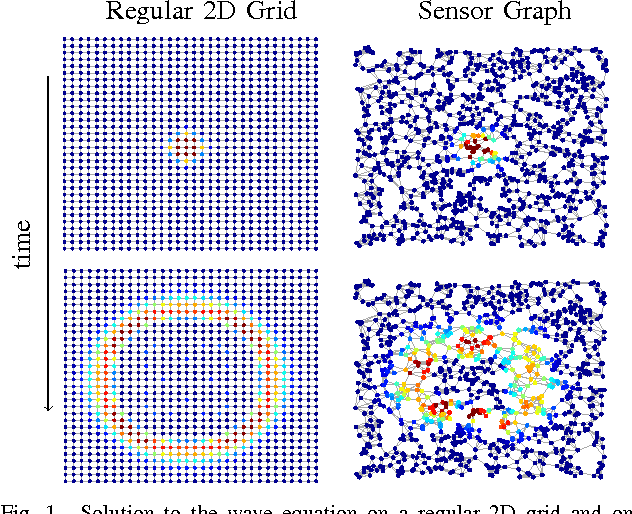
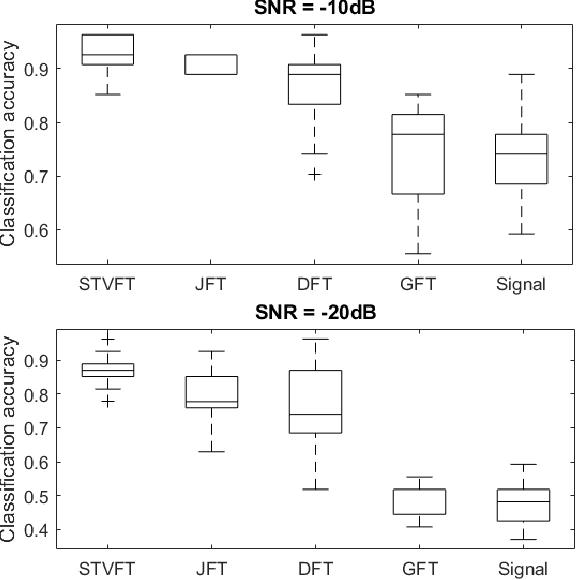
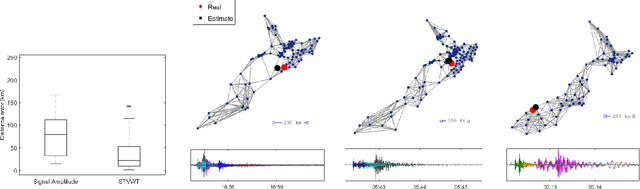
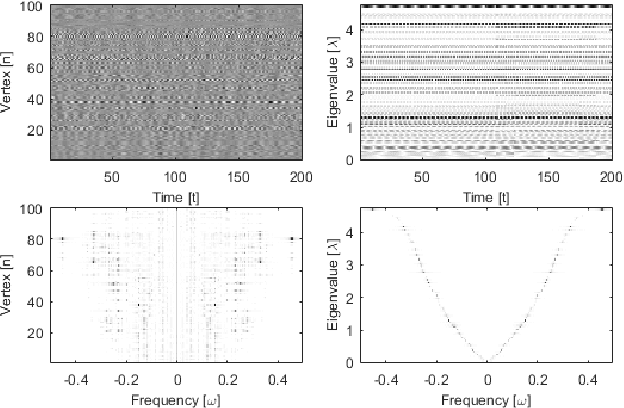
An emerging way to deal with high-dimensional non-euclidean data is to assume that the underlying structure can be captured by a graph. Recently, ideas have begun to emerge related to the analysis of time-varying graph signals. This work aims to elevate the notion of joint harmonic analysis to a full-fledged framework denoted as Time-Vertex Signal Processing, that links together the time-domain signal processing techniques with the new tools of graph signal processing. This entails three main contributions: (a) We provide a formal motivation for harmonic time-vertex analysis as an analysis tool for the state evolution of simple Partial Differential Equations on graphs. (b) We improve the accuracy of joint filtering operators by up-to two orders of magnitude. (c) Using our joint filters, we construct time-vertex dictionaries analyzing the different scales and the local time-frequency content of a signal. The utility of our tools is illustrated in numerous applications and datasets, such as dynamic mesh denoising and classification, still-video inpainting, and source localization in seismic events. Our results suggest that joint analysis of time-vertex signals can bring benefits to regression and learning.