 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Approximate Spectral Clustering for Dynamic Networks
Jun 12, 2017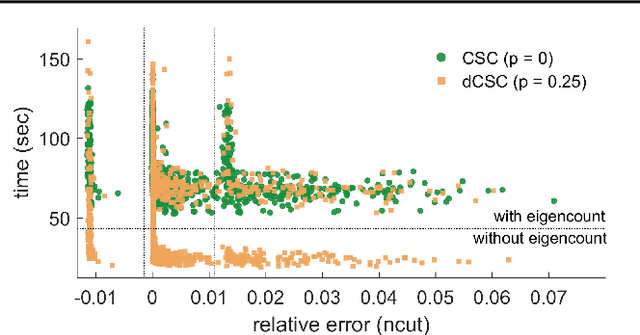
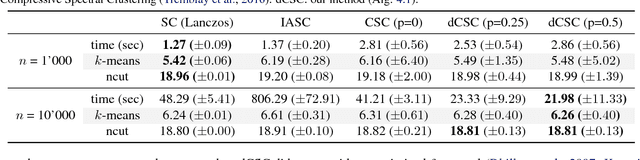
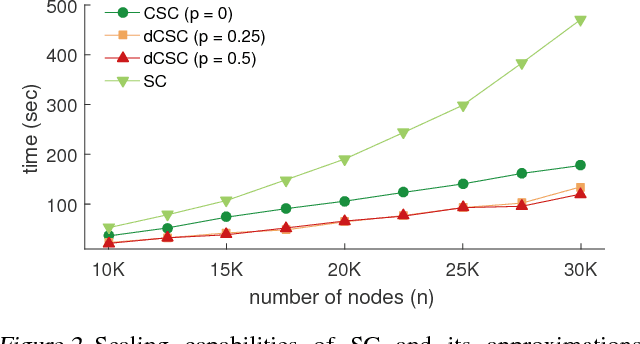
Spectral clustering is a widely studied problem, yet its complexity is prohibitive for dynamic graphs of even modest size. We claim that it is possible to reuse information of past cluster assignments to expedite computation. Our approach builds on a recent idea of sidestepping the main bottleneck of spectral clustering, i.e., computing the graph eigenvectors, by using fast Chebyshev graph filtering of random signals. We show that the proposed algorithm achieves clustering assignments with quality approximating that of spectral clustering and that it can yield significant complexity benefits when the graph dynamics are appropriately bounded.
Fast Eigenspace Approximation using Random Signals
Nov 04, 2016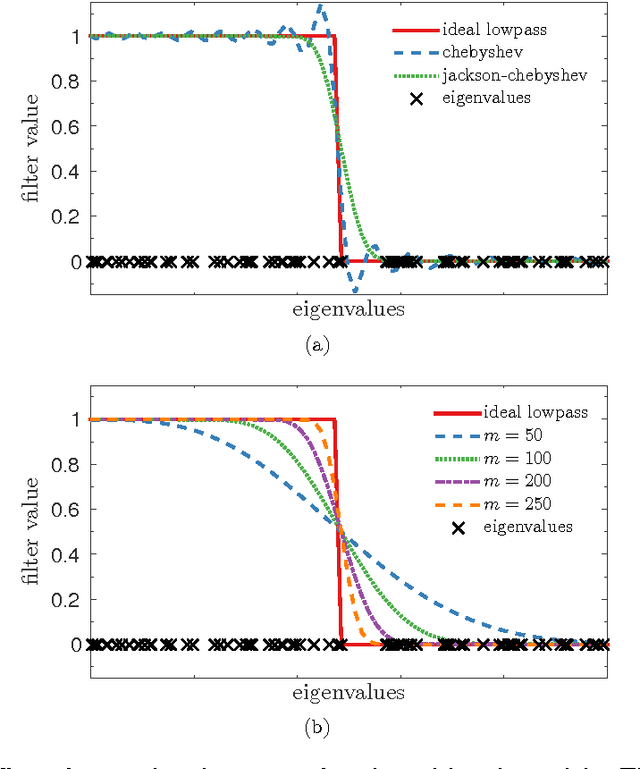
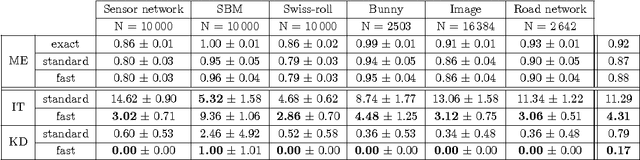
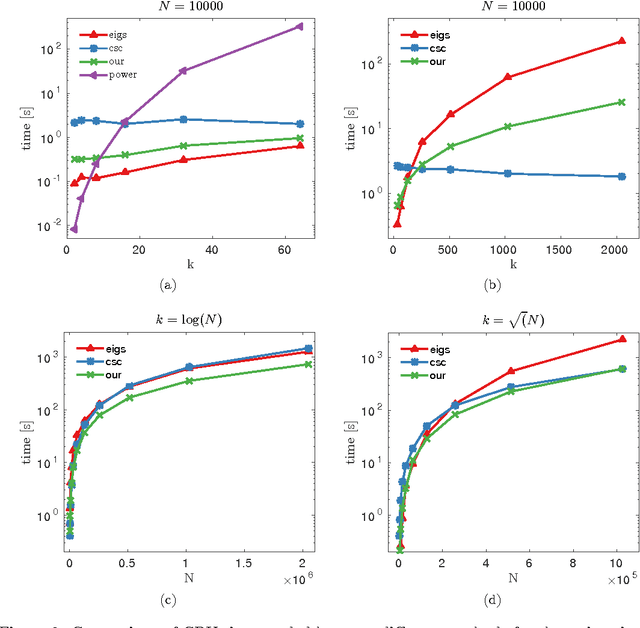
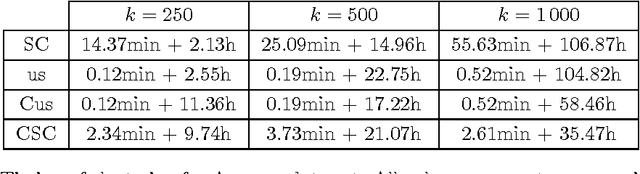
We focus in this work on the estimation of the first $k$ eigenvectors of any graph Laplacian using filtering of Gaussian random signals. We prove that we only need $k$ such signals to be able to exactly recover as many of the smallest eigenvectors, regardless of the number of nodes in the graph. In addition, we address key issues in implementing the theoretical concepts in practice using accurate approximated methods. We also propose fast algorithms both for eigenspace approximation and for the determination of the $k$th smallest eigenvalue $\lambda_k$. The latter proves to be extremely efficient under the assumption of locally uniform distribution of the eigenvalue over the spectrum. Finally, we present experiments which show the validity of our method in practice and compare it to state-of-the-art methods for clustering and visualization both on synthetic small-scale datasets and larger real-world problems of millions of nodes. We show that our method allows a better scaling with the number of nodes than all previous methods while achieving an almost perfect reconstruction of the eigenspace formed by the first $k$ eigenvectors.