 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Catastrophic Forgetting in IoT Intrusion Detection Systems
Feb 27, 2026Distribution shifts in attack patterns within RPL-based IoT networks pose a critical threat to the reliability and security of large-scale connected systems. Intrusion Detection Systems (IDS) trained on static datasets often fail to generalize to unseen threats and suffer from catastrophic forgetting when updated with new attacks. Ensuring continual adaptability of IDS is therefore essential for maintaining robust IoT network defence. In this focused study, we formulate intrusion detection as a domain continual learning problem and propose a method-agnostic IDS framework that can integrate diverse continual learning strategies. We systematically benchmark five representative approaches across multiple domain-ordering sequences using a comprehensive multi-attack dataset comprising 48 domains. Results show that continual learning mitigates catastrophic forgetting while maintaining a balance between plasticity, stability, and efficiency, a crucial aspect for resource-constrained IoT environments. Among the methods, Replay-based approaches achieve the best overall performance, while Synaptic Intelligence (SI) delivers near-zero forgetting with high training efficiency, demonstrating strong potential for stable and sustainable IDS deployment in dynamic IoT networks.
Automated Model Design using Gated Neuron Selection in Telecom
Feb 11, 2026The telecommunications industry is experiencing rapid growth in adopting deep learning for critical tasks such as traffic prediction, signal strength prediction, and quality of service optimisation. However, designing neural network architectures for these applications remains challenging and time-consuming, particularly when targeting compact models suitable for resource-constrained network environments. Therefore, there is a need for automating the model design process to create high-performing models efficiently. This paper introduces TabGNS (Tabular Gated Neuron Selection), a novel gradient-based Neural Architecture Search (NAS) method specifically tailored for tabular data in telecommunications networks. We evaluate TabGNS across multiple telecommunications and generic tabular datasets, demonstrating improvements in prediction performance while reducing the architecture size by 51-82% and reducing the search time by up to 36x compared to state-of-the-art tabular NAS methods. Integrating TabGNS into the model lifecycle management enables automated design of neural networks throughout the lifecycle, accelerating deployment of ML solutions in telecommunications networks.
Towards Neural Architecture Search for Transfer Learning in 6G Networks
Jun 04, 2024The future 6G network is envisioned to be AI-native, and as such, ML models will be pervasive in support of optimizing performance, reducing energy consumption, and in coping with increasing complexity and heterogeneity. A key challenge is automating the process of finding optimal model architectures satisfying stringent requirements stemming from varying tasks, dynamicity and available resources in the infrastructure and deployment positions. In this paper, we describe and review the state-of-the-art in Neural Architecture Search and Transfer Learning and their applicability in networking. Further, we identify open research challenges and set directions with a specific focus on three main requirements with elements unique to the future network, namely combining NAS and TL, multi-objective search, and tabular data. Finally, we outline and discuss both near-term and long-term work ahead.
Predictive Bandits
Apr 02, 2020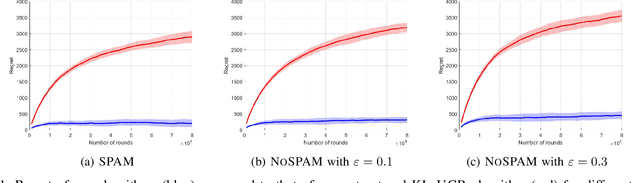
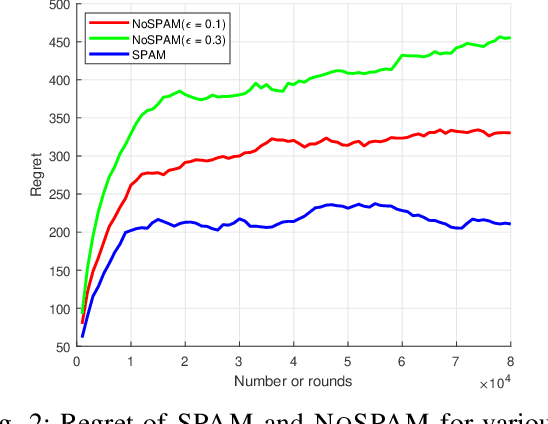
We introduce and study a new class of stochastic bandit problems, referred to as predictive bandits. In each round, the decision maker first decides whether to gather information about the rewards of particular arms (so that their rewards in this round can be predicted). These measurements are costly, and may be corrupted by noise. The decision maker then selects an arm to be actually played in the round. Predictive bandits find applications in many areas; e.g. they can be applied to channel selection problems in radio communication systems. In this paper, we provide the first theoretical results about predictive bandits, and focus on scenarios where the decision maker is allowed to measure at most one arm per round. We derive asymptotic instance-specific regret lower bounds for these problems, and develop algorithms whose regret match these fundamental limits. We illustrate the performance of our algorithms through numerical experiments. In particular, we highlight the gains that can be achieved by using reward predictions, and investigate the impact of the noise in the corresponding measurements.
Predicting SLA Violations in Real Time using Online Machine Learning
Sep 04, 2015



Detecting faults and SLA violations in a timely manner is critical for telecom providers, in order to avoid loss in business, revenue and reputation. At the same time predicting SLA violations for user services in telecom environments is difficult, due to time-varying user demands and infrastructure load conditions. In this paper, we propose a service-agnostic online learning approach, whereby the behavior of the system is learned on the fly, in order to predict client-side SLA violations. The approach uses device-level metrics, which are collected in a streaming fashion on the server side. Our results show that the approach can produce highly accurate predictions (>90% classification accuracy and < 10% false alarm rate) in scenarios where SLA violations are predicted for a video-on-demand service under changing load patterns. The paper also highlight the limitations of traditional offline learning methods, which perform significantly worse in many of the considered scenarios.