 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Why This Avoidance Maneuver?" Contrastive Explanations in Human-Supervised Maritime Autonomous Navigation
Apr 09, 2026Automated maritime collision avoidance will rely on human supervision for the foreseeable future. This necessitates transparency into how the system perceives a scenario and plans a maneuver. However, the causal logic behind avoidance maneuvers is often complex and difficult to convey to a navigator. This paper explores how to explain these factors in a selective, understandable manner for supervisors with a nautical background. We propose a method for generating contrastive explanations, which provide human-centric insights by comparing a system's proposed solution against relevant alternatives. To evaluate this, we developed a framework that uses visual and textual cues to highlight key objectives from a state-of-the-art collision avoidance system. An exploratory user study with four experienced marine officers suggests that contrastive explanations support the understanding of the system's objectives. However, our findings also reveal that while these explanations are highly valuable in complex multi-vessel encounters, they can increase cognitive workload, suggesting that future maritime interfaces may benefit most from demand-driven or scenario-specific explanation strategies.
Explainable Artificial Intelligence: How Subsets of the Training Data Affect a Prediction
Dec 07, 2020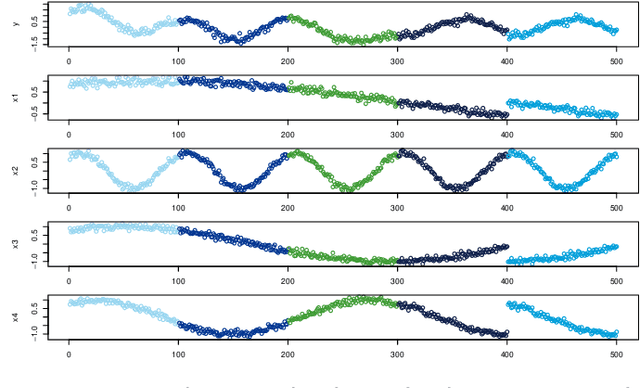



There is an increasing interest in and demand for interpretations and explanations of machine learning models and predictions in various application areas. In this paper, we consider data-driven models which are already developed, implemented and trained. Our goal is to interpret the models and explain and understand their predictions. Since the predictions made by data-driven models rely heavily on the data used for training, we believe explanations should convey information about how the training data affects the predictions. To do this, we propose a novel methodology which we call Shapley values for training data subset importance. The Shapley value concept originates from coalitional game theory, developed to fairly distribute the payout among a set of cooperating players. We extend this to subset importance, where a prediction is explained by treating the subsets of the training data as players in a game where the predictions are the payouts. We describe and illustrate how the proposed method can be useful and demonstrate its capabilities on several examples. We show how the proposed explanations can be used to reveal biasedness in models and erroneous training data. Furthermore, we demonstrate that when predictions are accurately explained in a known situation, then explanations of predictions by simple models correspond to the intuitive explanations. We argue that the explanations enable us to perceive more of the inner workings of the algorithms, and illustrate how models producing similar predictions can be based on very different parts of the training data. Finally, we show how we can use Shapley values for subset importance to enhance our training data acquisition, and by this reducing prediction error.