 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Evaluating Knowledge or Phrasing? Mitigating MCQA Sensitivity with ParaEval
Jun 09, 2026Multiple-choice (MCQA) benchmarks are the standard for evaluating pretrained large language models, but their reliance on log-likelihood scoring makes them unreliable. Specifically, standard scores are highly sensitive to the exact phrasing (surface form) of the answers, conflating a model's familiarity with a specific phrase with its actual capability. We demonstrate this flaw using a controlled testbed of 1B-8B models trained on the same knowledge. Despite having identical knowledge, standard metrics falsely report a performance gap of over 2 points. To solve this, we propose ParaEval, an evaluation framework that queries models using multiple paraphrases per answer option. By scoring each model based on its most favorable phrasing, ParaEval successfully reduces the false performance gap to below 1 point. We confirm that these evaluation artifacts, and the improvements from ParaEval, persist in frontier 70B and 120B open-source models. Ultimately, ParaEval provides a robust and efficient way to evaluate true underlying capability rather than surface-form familiarity.
Omnilingual MT: Machine Translation for 1,600 Languages
Mar 17, 2026High-quality machine translation (MT) can scale to hundreds of languages, setting a high bar for multilingual systems. However, compared to the world's 7,000 languages, current systems still offer only limited coverage: about 200 languages on the target side, and maybe a few hundreds more on the source side, supported due to cross-lingual transfer. And even these numbers have been hard to evaluate due to the lack of reliable benchmarks and metrics. We present Omnilingual Machine Translation (OMT), the first MT system supporting more than 1,600 languages. This scale is enabled by a comprehensive data strategy that integrates large public multilingual corpora with newly created datasets, including manually curated MeDLEY bitext. We explore two ways of specializing a Large Language model (LLM) for machine translation: as a decoder-only model (OMT-LLaMA) or as a module in an encoder-decoder architecture (OMT-NLLB). Notably, all our 1B to 8B parameter models match or exceed the MT performance of a 70B LLM baseline, revealing a clear specialization advantage and enabling strong translation quality in low-compute settings. Moreover, our evaluation of English-to-1,600 translations further shows that while baseline models can interpret undersupported languages, they frequently fail to generate them with meaningful fidelity; OMT-LLaMA models substantially expand the set of languages for which coherent generation is feasible. Additionally, OMT models improve in cross-lingual transfer, being close to solving the "understanding" part of the puzzle in MT for the 1,600 evaluated. Our leaderboard and main human-created evaluation datasets (BOUQuET and Met-BOUQuET) are dynamically evolving towards Omnilinguality and freely available.
A Survey on Knowledge Editing of Neural Networks
Oct 30, 2023


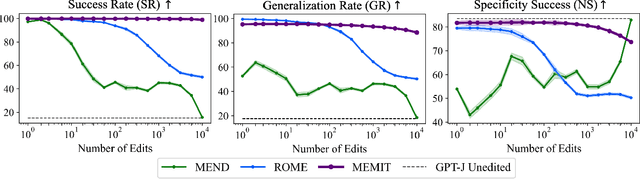
Deep neural networks are becoming increasingly pervasive in academia and industry, matching and surpassing human performance on a wide variety of fields and related tasks. However, just as humans, even the largest artificial neural networks make mistakes, and once-correct predictions can become invalid as the world progresses in time. Augmenting datasets with samples that account for mistakes or up-to-date information has become a common workaround in practical applications. However, the well-known phenomenon of catastrophic forgetting poses a challenge in achieving precise changes in the implicitly memorized knowledge of neural network parameters, often requiring a full model re-training to achieve desired behaviors. That is expensive, unreliable, and incompatible with the current trend of large self-supervised pre-training, making it necessary to find more efficient and effective methods for adapting neural network models to changing data. To address this need, knowledge editing is emerging as a novel area of research that aims to enable reliable, data-efficient, and fast changes to a pre-trained target model, without affecting model behaviors on previously learned tasks. In this survey, we provide a brief review of this recent artificial intelligence field of research. We first introduce the problem of editing neural networks, formalize it in a common framework and differentiate it from more notorious branches of research such as continuous learning. Next, we provide a review of the most relevant knowledge editing approaches and datasets proposed so far, grouping works under four different families: regularization techniques, meta-learning, direct model editing, and architectural strategies. Finally, we outline some intersections with other fields of research and potential directions for future works.