 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Conceal: A Deep Learning Based Method for Preserving Privacy and Avoiding Prejudice
Sep 19, 2019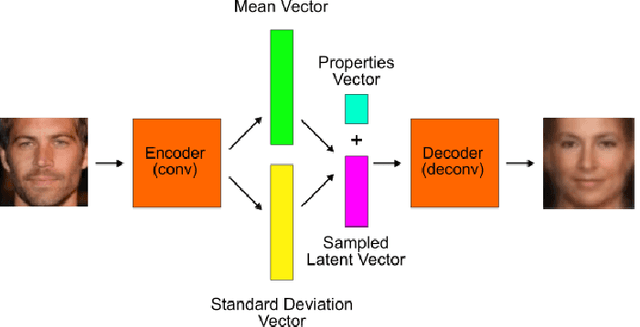
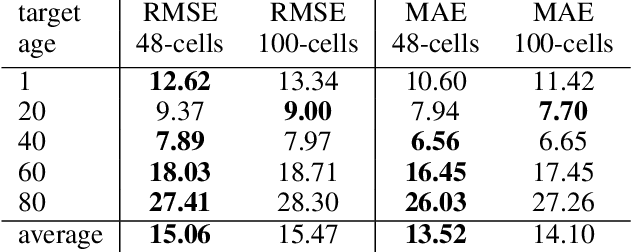
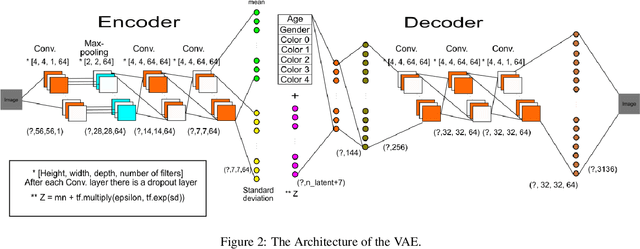

In this paper, we introduce a learning model able to conceals personal information (e.g. gender, age, ethnicity, etc.) from an image, while maintaining any additional information present in the image (e.g. smile, hair-style, brightness). Our trained model is not provided the information that it is concealing, and does not try learning it either. Namely, we created a variational autoencoder (VAE) model that is trained on a dataset including labels of the information one would like to conceal (e.g. gender, ethnicity, age). These labels are directly added to the VAE's sampled latent vector. Due to the limited number of neurons in the latent vector and its appended noise, the VAE avoids learning any relation between the given images and the given labels, as those are given directly. Therefore, the encoded image lacks any of the information one wishes to conceal. The encoding may be decoded back into an image according to any provided properties (e.g. a 40 year old woman). The proposed architecture can be used as a mean for privacy preserving and can serve as an input to systems, which will become unbiased and not suffer from prejudice. We believe that privacy and discrimination are two of the most important aspects in which the community should try and develop methods to prevent misuse of technological advances.
InstructableCrowd: Creating IF-THEN Rules for Smartphones via Conversations with the Crowd
Sep 12, 2019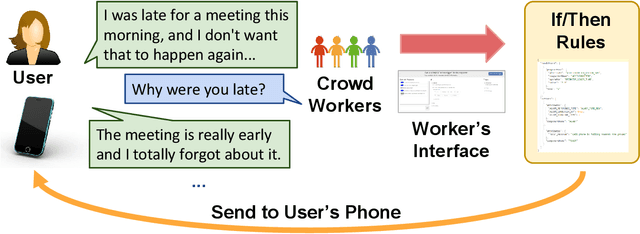
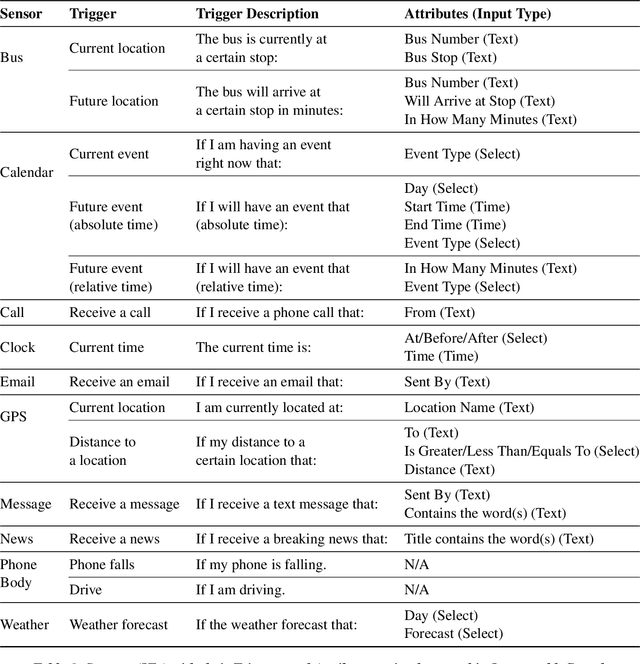
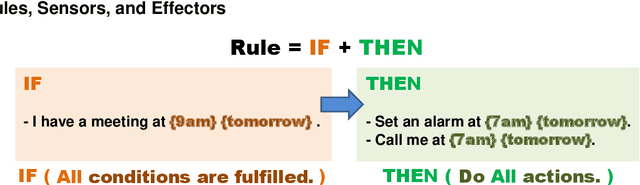
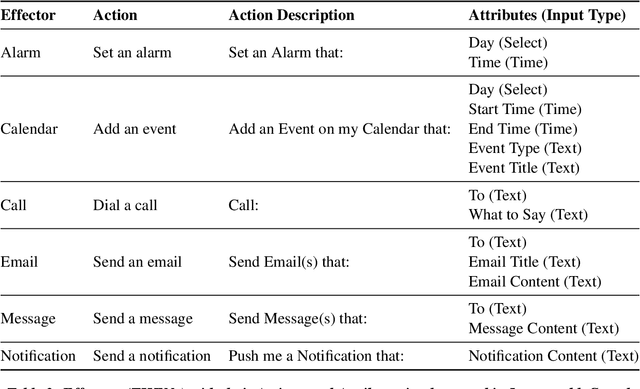
Natural language interfaces have become a common part of modern digital life. Chatbots utilize text-based conversations to communicate with users; personal assistants on smartphones such as Google Assistant take direct speech commands from their users; and speech-controlled devices such as Amazon Echo use voice as their only input mode. In this paper, we introduce InstructableCrowd, a crowd-powered system that allows users to program their devices via conversation. The user verbally expresses a problem to the system, in which a group of crowd workers collectively respond and program relevant multi-part IF-THEN rules to help the user. The IF-THEN rules generated by InstructableCrowd connect relevant sensor combinations (e.g., location, weather, device acceleration, etc.) to useful effectors (e.g., text messages, device alarms, etc.). Our study showed that non-programmers can use the conversational interface of InstructableCrowd to create IF-THEN rules that have similar quality compared with the rules created manually. InstructableCrowd generally illustrates how users may converse with their devices, not only to trigger simple voice commands, but also to personalize their increasingly powerful and complicated devices.
* Published at Human Computation (2019) 6:1:113-146
Deep Reinforcement Learning for Time Optimal Velocity Control using Prior Knowledge
Mar 12, 2019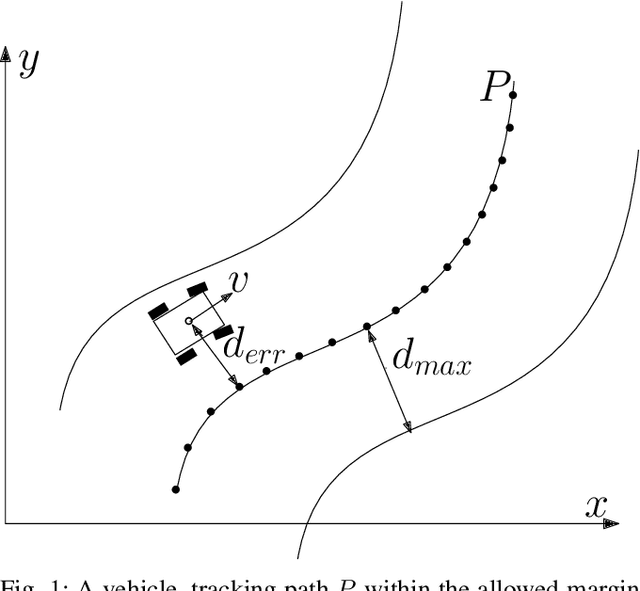
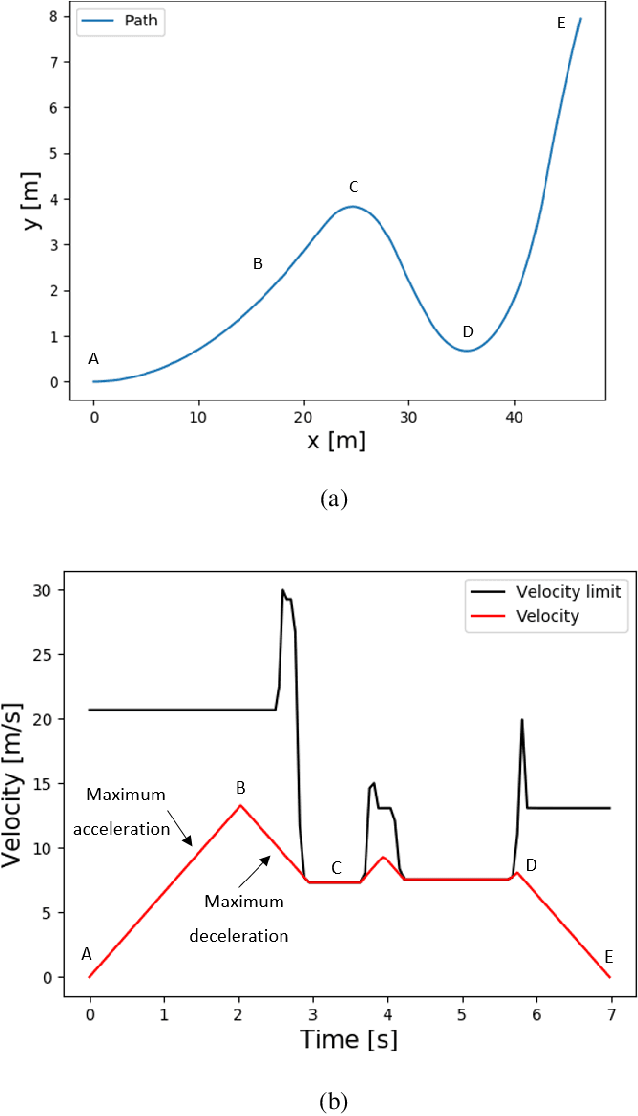
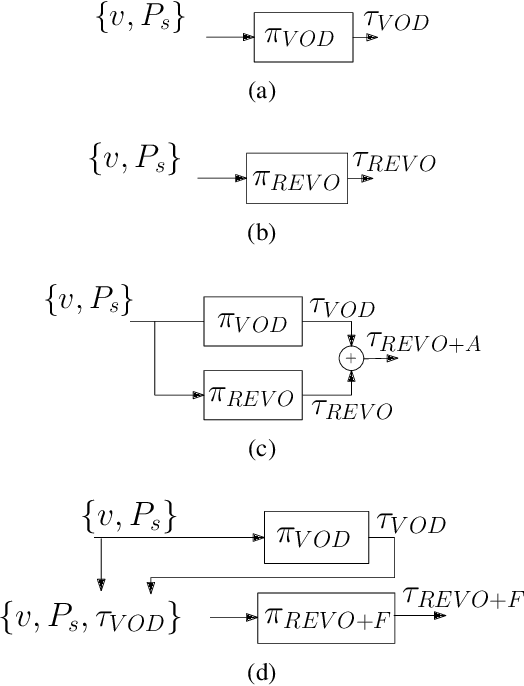
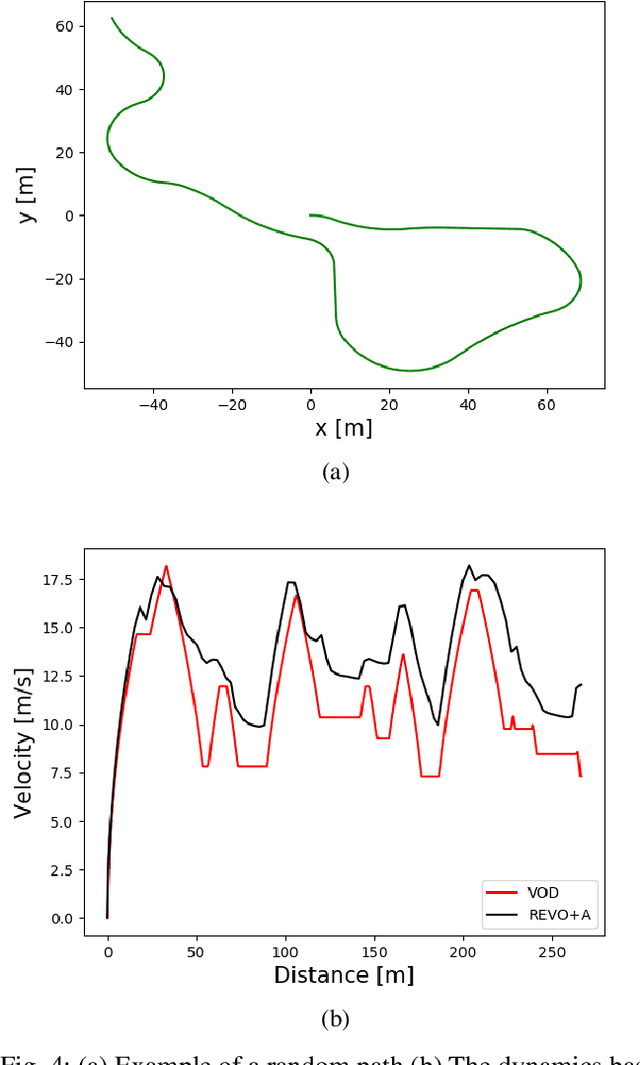
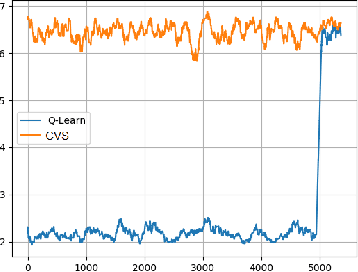
While autonomous navigation has recently gained great interest in the field of reinforcement learning, only a few works in this field have focused on the time optimal velocity control problem, i.e. controlling a vehicle such that it travels at the maximal speed without becoming dynamically unstable. Achieving maximal speed is important in many situations, such as emergency vehicles traveling at high speeds to their destinations, and regular vehicles executing emergency maneuvers to avoid imminent collisions. Time optimal velocity control can be solved numerically using existing methods that are based on optimal control and vehicle dynamics. In this paper, we use deep reinforcement learning to generate the time optimal velocity control. Furthermore, we use the numerical solution to further improve the performance of the reinforcement learner. It is shown that the reinforcement learner outperforms the numerically derived solution, and that the hybrid approach (combining learning with the numerical solution) speeds up the learning process.
Multi-Relational Question Answering from Narratives: Machine Reading and Reasoning in Simulated Worlds
Feb 25, 2019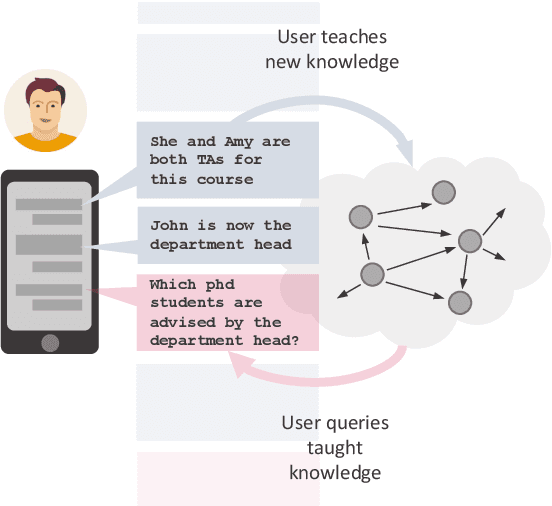
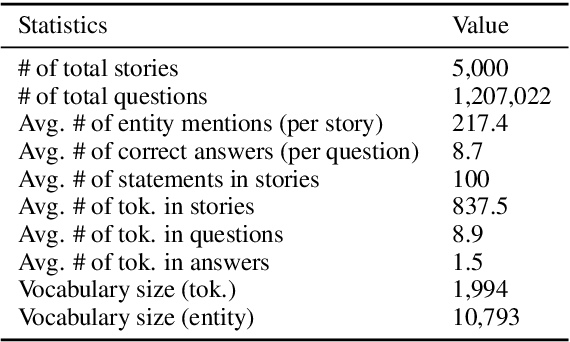

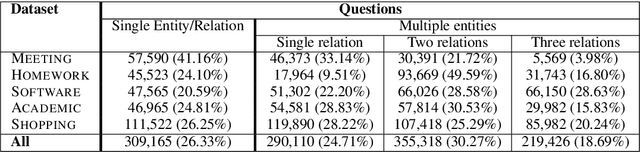
Question Answering (QA), as a research field, has primarily focused on either knowledge bases (KBs) or free text as a source of knowledge. These two sources have historically shaped the kinds of questions that are asked over these sources, and the methods developed to answer them. In this work, we look towards a practical use-case of QA over user-instructed knowledge that uniquely combines elements of both structured QA over knowledge bases, and unstructured QA over narrative, introducing the task of multi-relational QA over personal narrative. As a first step towards this goal, we make three key contributions: (i) we generate and release TextWorldsQA, a set of five diverse datasets, where each dataset contains dynamic narrative that describes entities and relations in a simulated world, paired with variably compositional questions over that knowledge, (ii) we perform a thorough evaluation and analysis of several state-of-the-art QA models and their variants at this task, and (iii) we release a lightweight Python-based framework we call TextWorlds for easily generating arbitrary additional worlds and narrative, with the goal of allowing the community to create and share a growing collection of diverse worlds as a test-bed for this task.
* published at ACL 2018
The Concept of Criticality in Reinforcement Learning
Oct 16, 2018
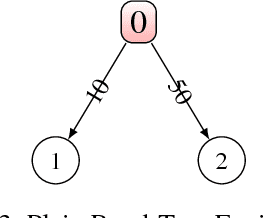
Reinforcement learning methods carry a well known bias-variance trade-off in n-step algorithms for optimal control. Unfortunately, this has rarely been addressed in current research. This trade-off principle holds independent of the choice of the algorithm, such as n-step SARSA, n-step Expected SARSA or n-step Tree backup. A small n results in a large bias, while a large n leads to large variance. The literature offers no straightforward recipe for the best choice of this value. While currently all n-step algorithms use a fixed value of n over the state space we extend the framework of n-step updates by allowing each state to have its specific n. We propose a solution to this problem within the context of human aided reinforcement learning. Our approach is based on the observation that a human can learn more efficiently if she receives input regarding the criticality of a given state and thus the amount of attention she needs to invest into the learning in that state. This observation is related to the idea that each state of the MDP has a certain measure of criticality which indicates how much the choice of the action in that state influences the return. In our algorithm the RL agent utilizes the criticality measure, a function provided by a human trainer, in order to locally choose the best stepnumber n for the update of the Q function.
Goldbach's Function Approximation Using Deep Learning
Mar 25, 2018
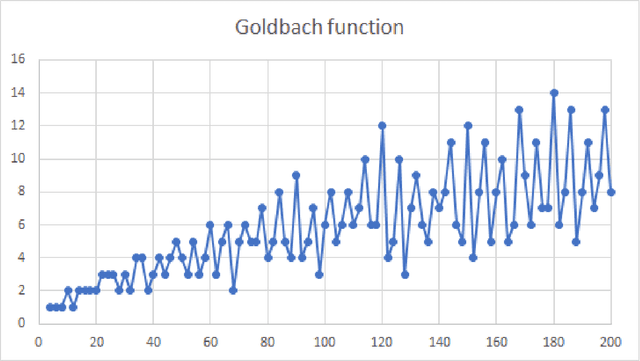
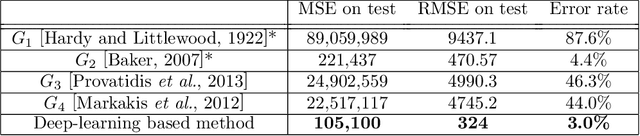
Goldbach conjecture is one of the most famous open mathematical problems. It states that every even number, bigger than two, can be presented as a sum of 2 prime numbers. % In this work we present a deep learning based model that predicts the number of Goldbach partitions for a given even number. Surprisingly, our model outperforms all state-of-the-art analytically derived estimations for the number of couples, while not requiring prime factorization of the given number. We believe that building a model that can accurately predict the number of couples brings us one step closer to solving one of the world most famous open problems. To the best of our knowledge, this is the first attempt to consider machine learning based data-driven methods to approximate open mathematical problems in the field of number theory, and hope that this work will encourage such attempts.
"Is there anything else I can help you with?": Challenges in Deploying an On-Demand Crowd-Powered Conversational Agent
Aug 10, 2017
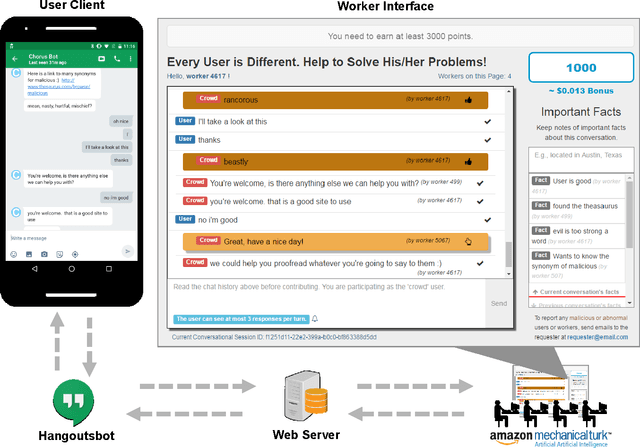

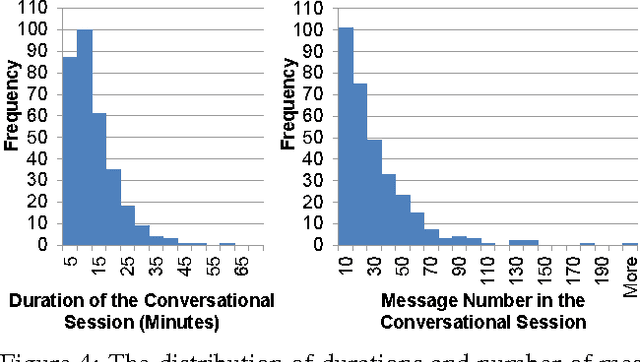
Intelligent conversational assistants, such as Apple's Siri, Microsoft's Cortana, and Amazon's Echo, have quickly become a part of our digital life. However, these assistants have major limitations, which prevents users from conversing with them as they would with human dialog partners. This limits our ability to observe how users really want to interact with the underlying system. To address this problem, we developed a crowd-powered conversational assistant, Chorus, and deployed it to see how users and workers would interact together when mediated by the system. Chorus sophisticatedly converses with end users over time by recruiting workers on demand, which in turn decide what might be the best response for each user sentence. Up to the first month of our deployment, 59 users have held conversations with Chorus during 320 conversational sessions. In this paper, we present an account of Chorus' deployment, with a focus on four challenges: (i) identifying when conversations are over, (ii) malicious users and workers, (iii) on-demand recruiting, and (iv) settings in which consensus is not enough. Our observations could assist the deployment of crowd-powered conversation systems and crowd-powered systems in general.
The DARPA Twitter Bot Challenge
Apr 21, 2016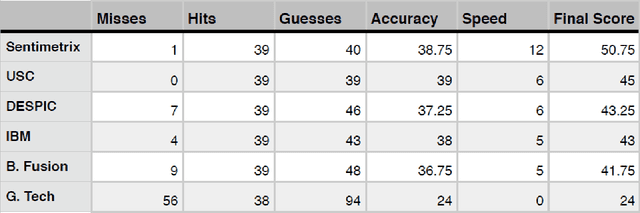
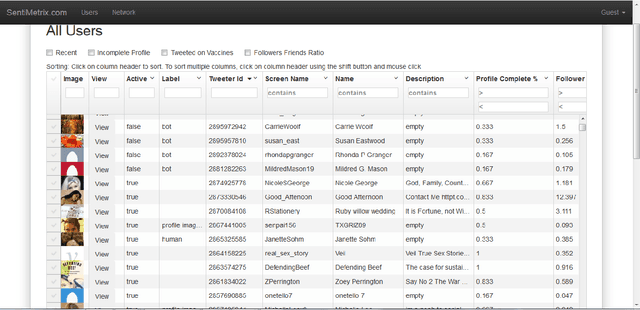
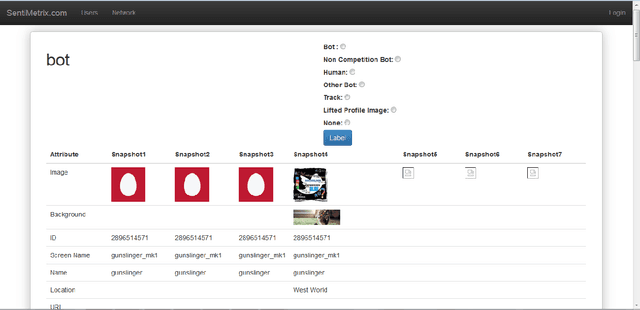
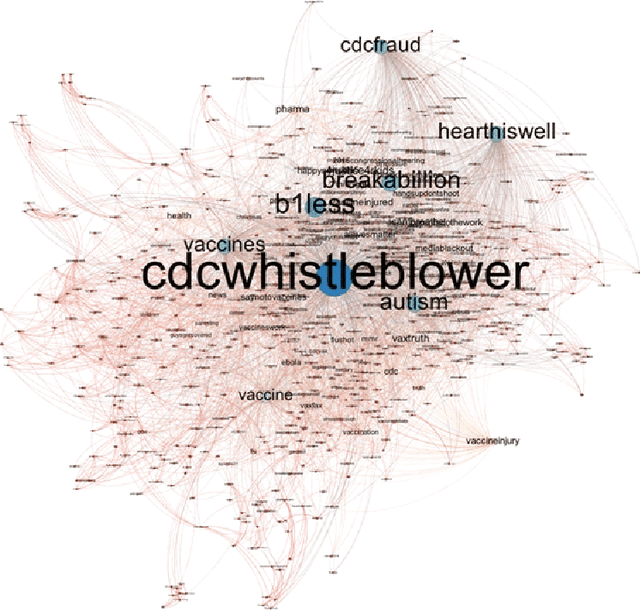
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press