 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Persian Sentiment Analysis Framework: Integrating Dependency Grammar Based Rules and Deep Neural Networks
Sep 30, 2019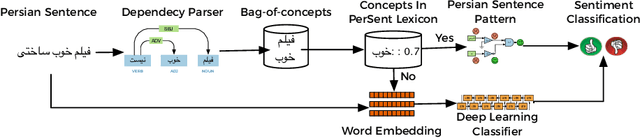

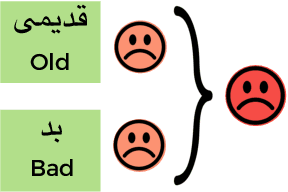
Social media hold valuable, vast and unstructured information on public opinion that can be utilized to improve products and services. The automatic analysis of such data, however, requires a deep understanding of natural language. Current sentiment analysis approaches are mainly based on word co-occurrence frequencies, which are inadequate in most practical cases. In this work, we propose a novel hybrid framework for concept-level sentiment analysis in Persian language, that integrates linguistic rules and deep learning to optimize polarity detection. When a pattern is triggered, the framework allows sentiments to flow from words to concepts based on symbolic dependency relations. When no pattern is triggered, the framework switches to its subsymbolic counterpart and leverages deep neural networks (DNN) to perform the classification. The proposed framework outperforms state-of-the-art approaches (including support vector machine, and logistic regression) and DNN classifiers (long short-term memory, and Convolutional Neural Networks) with a margin of 10-15% and 3-4% respectively, using benchmark Persian product and hotel reviews corpora.
CochleaNet: A Robust Language-independent Audio-Visual Model for Speech Enhancement
Sep 23, 2019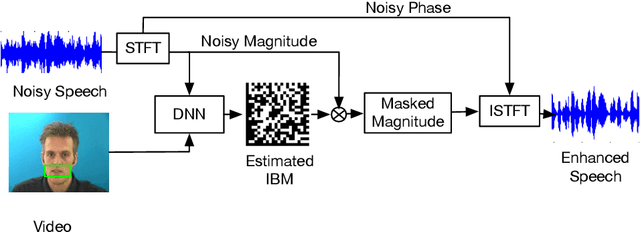
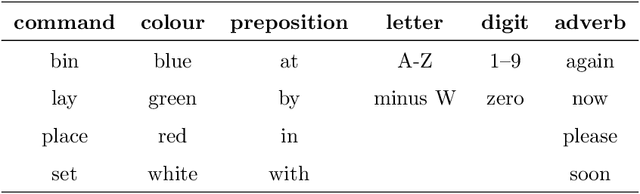
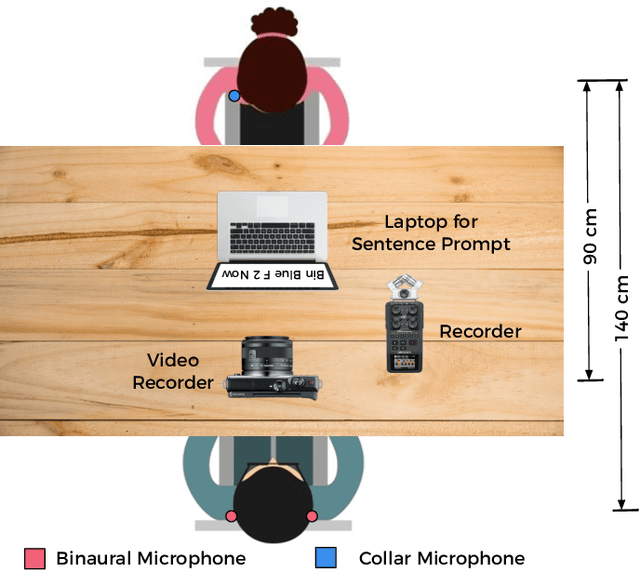
Noisy situations cause huge problems for suffers of hearing loss as hearing aids often make the signal more audible but do not always restore the intelligibility. In noisy settings, humans routinely exploit the audio-visual (AV) nature of the speech to selectively suppress the background noise and to focus on the target speaker. In this paper, we present a causal, language, noise and speaker independent AV deep neural network (DNN) architecture for speech enhancement (SE). The model exploits the noisy acoustic cues and noise robust visual cues to focus on the desired speaker and improve the speech intelligibility. To evaluate the proposed SE framework a first of its kind AV binaural speech corpus, called ASPIRE, is recorded in real noisy environments including cafeteria and restaurant. We demonstrate superior performance of our approach in terms of objective measures and subjective listening tests over the state-of-the-art SE approaches as well as recent DNN based SE models. In addition, our work challenges a popular belief that a scarcity of multi-language large vocabulary AV corpus and wide variety of noises is a major bottleneck to build a robust language, speaker and noise independent SE systems. We show that a model trained on synthetic mixture of Grid corpus (with 33 speakers and a small English vocabulary) and ChiME 3 Noises (consisting of only bus, pedestrian, cafeteria, and street noises) generalise well not only on large vocabulary corpora but also on completely unrelated languages (such as Mandarin), wide variety of speakers and noises.
Contextual Audio-Visual Switching For Speech Enhancement in Real-World Environments
Aug 28, 2018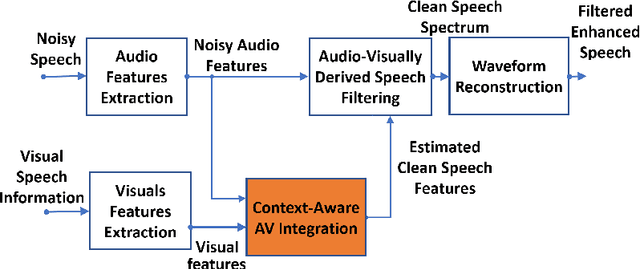
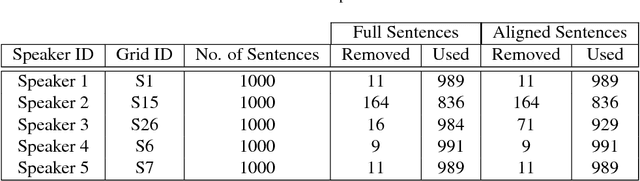
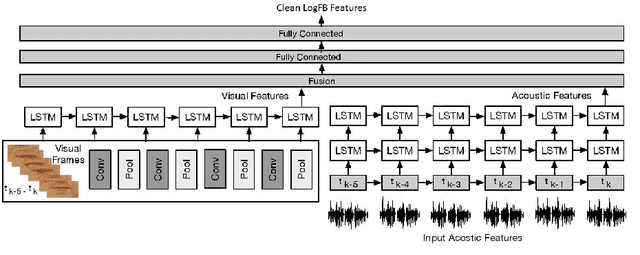
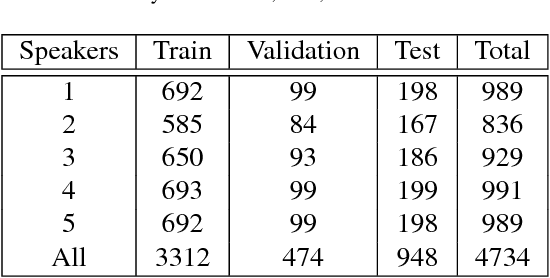
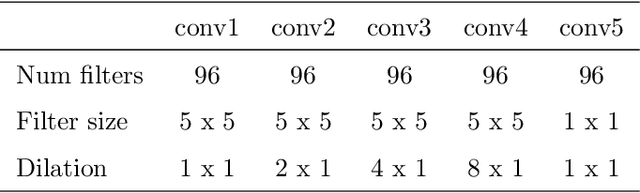
Human speech processing is inherently multimodal, where visual cues (lip movements) help to better understand the speech in noise. Lip-reading driven speech enhancement significantly outperforms benchmark audio-only approaches at low signal-to-noise ratios (SNRs). However, at high SNRs or low levels of background noise, visual cues become fairly less effective for speech enhancement. Therefore, a more optimal, context-aware audio-visual (AV) system is required, that contextually utilises both visual and noisy audio features and effectively accounts for different noisy conditions. In this paper, we introduce a novel contextual AV switching component that contextually exploits AV cues with respect to different operating conditions to estimate clean audio, without requiring any SNR estimation. The switching module switches between visual-only (V-only), audio-only (A-only), and both AV cues at low, high and moderate SNR levels, respectively. The contextual AV switching component is developed by integrating a convolutional neural network and long-short-term memory network. For testing, the estimated clean audio features are utilised by the developed novel enhanced visually derived Wiener filter for clean audio power spectrum estimation. The contextual AV speech enhancement method is evaluated under real-world scenarios using benchmark Grid and ChiME3 corpora. For objective testing, perceptual evaluation of speech quality is used to evaluate the quality of the restored speech. For subjective testing, the standard mean-opinion-score method is used. The critical analysis and comparative study demonstrate the outperformance of proposed contextual AV approach, over A-only, V-only, spectral subtraction, and log-minimum mean square error based speech enhancement methods at both low and high SNRs, revealing its capability to tackle spectro-temporal variation in any real-world noisy condition.
Saliency Detection via Bidirectional Absorbing Markov Chain
Aug 25, 2018
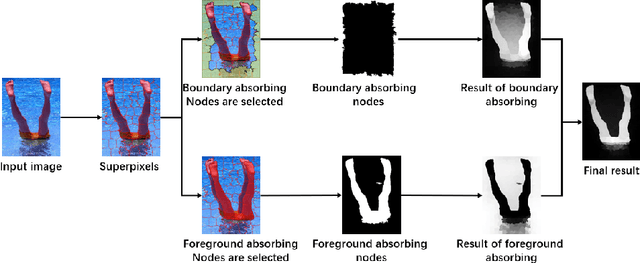


Traditional saliency detection via Markov chain only considers boundaries nodes. However, in addition to boundaries cues, background prior and foreground prior cues play a complementary role to enhance saliency detection. In this paper, we propose an absorbing Markov chain based saliency detection method considering both boundary information and foreground prior cues. The proposed approach combines both boundaries and foreground prior cues through bidirectional Markov chain. Specifically, the image is first segmented into superpixels and four boundaries nodes (duplicated as virtual nodes) are selected. Subsequently, the absorption time upon transition node's random walk to the absorbing state is calculated to obtain foreground possibility. Simultaneously, foreground prior as the virtual absorbing nodes is used to calculate the absorption time and obtain the background possibility. Finally, two obtained results are fused to obtain the combined saliency map using cost function for further optimization at multi-scale. Experimental results demonstrate the outperformance of our proposed model on 4 benchmark datasets as compared to 17 state-of-the-art methods.
SentiALG: Automated Corpus Annotation for Algerian Sentiment Analysis
Aug 15, 2018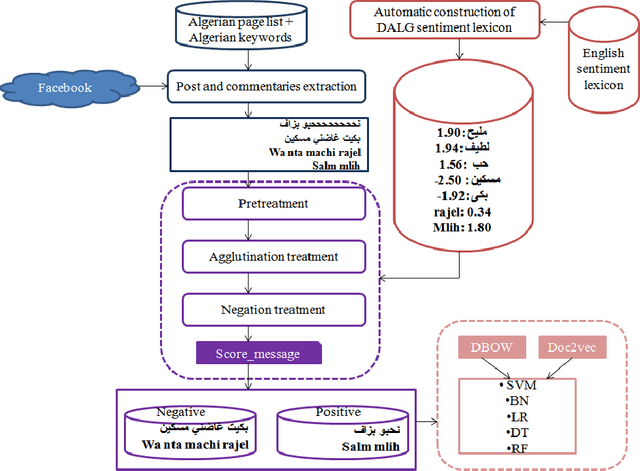
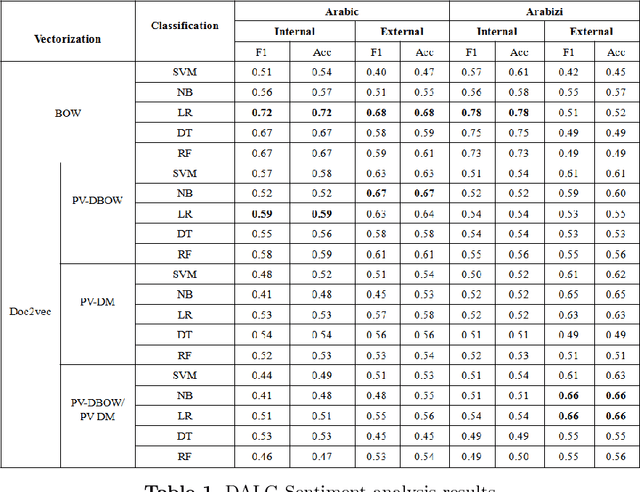
Data annotation is an important but time-consuming and costly procedure. To sort a text into two classes, the very first thing we need is a good annotation guideline, establishing what is required to qualify for each class. In the literature, the difficulties associated with an appropriate data annotation has been underestimated. In this paper, we present a novel approach to automatically construct an annotated sentiment corpus for Algerian dialect (a Maghrebi Arabic dialect). The construction of this corpus is based on an Algerian sentiment lexicon that is also constructed automatically. The presented work deals with the two widely used scripts on Arabic social media: Arabic and Arabizi. The proposed approach automatically constructs a sentiment corpus containing 8000 messages (where 4000 are dedicated to Arabic and 4000 to Arabizi). The achieved F1-score is up to 72% and 78% for an Arabic and Arabizi test sets, respectively. Ongoing work is aimed at integrating transliteration process for Arabizi messages to further improve the obtained results.
Exploiting Deep Learning for Persian Sentiment Analysis
Aug 15, 2018
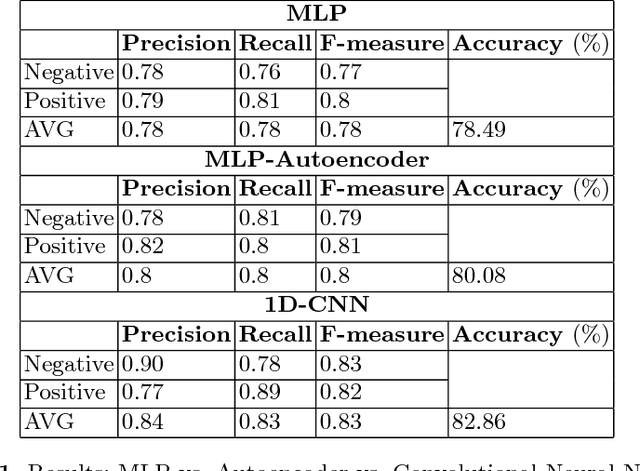
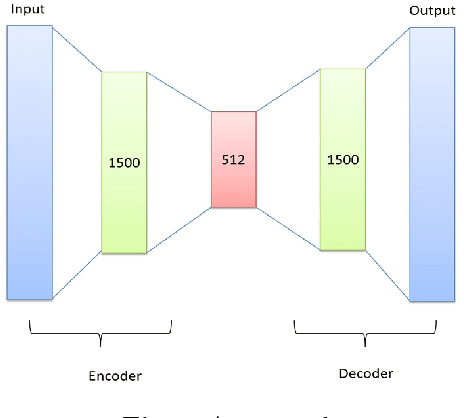
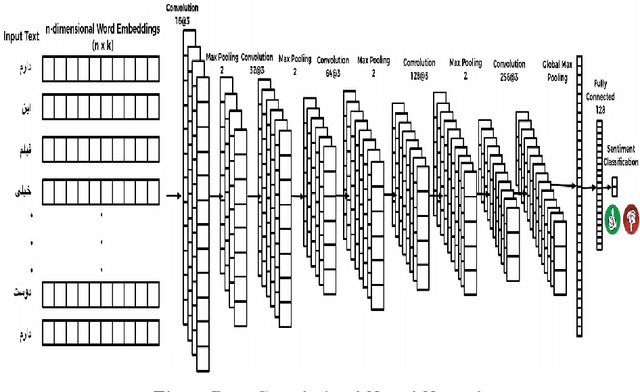
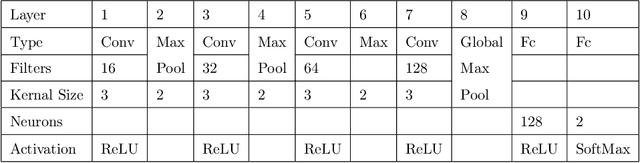
The rise of social media is enabling people to freely express their opinions about products and services. The aim of sentiment analysis is to automatically determine subject's sentiment (e.g., positive, negative, or neutral) towards a particular aspect such as topic, product, movie, news etc. Deep learning has recently emerged as a powerful machine learning technique to tackle a growing demand of accurate sentiment analysis. However, limited work has been conducted to apply deep learning algorithms to languages other than English, such as Persian. In this work, two deep learning models (deep autoencoders and deep convolutional neural networks (CNNs)) are developed and applied to a novel Persian movie reviews dataset. The proposed deep learning models are analyzed and compared with the state-of-the-art shallow multilayer perceptron (MLP) based machine learning model. Simulation results demonstrate the enhanced performance of deep learning over state-of-the-art MLP.
DNN driven Speaker Independent Audio-Visual Mask Estimation for Speech Separation
Jul 31, 2018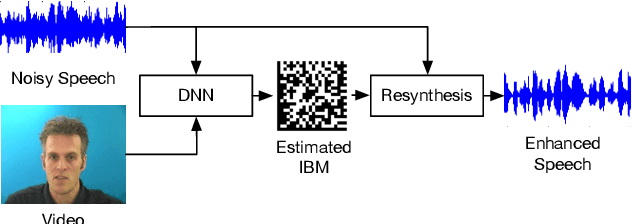

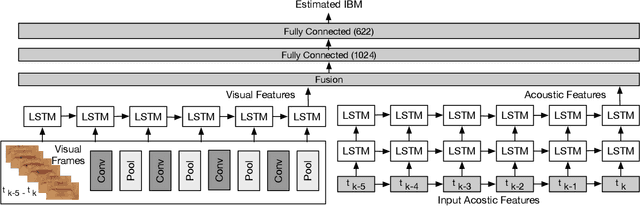
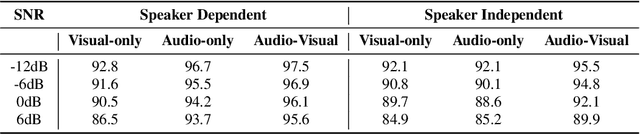
Human auditory cortex excels at selectively suppressing background noise to focus on a target speaker. The process of selective attention in the brain is known to contextually exploit the available audio and visual cues to better focus on target speaker while filtering out other noises. In this study, we propose a novel deep neural network (DNN) based audiovisual (AV) mask estimation model. The proposed AV mask estimation model contextually integrates the temporal dynamics of both audio and noise-immune visual features for improved mask estimation and speech separation. For optimal AV features extraction and ideal binary mask (IBM) estimation, a hybrid DNN architecture is exploited to leverages the complementary strengths of a stacked long short term memory (LSTM) and convolution LSTM network. The comparative simulation results in terms of speech quality and intelligibility demonstrate significant performance improvement of our proposed AV mask estimation model as compared to audio-only and visual-only mask estimation approaches for both speaker dependent and independent scenarios.
Lip-Reading Driven Deep Learning Approach for Speech Enhancement
Jul 31, 2018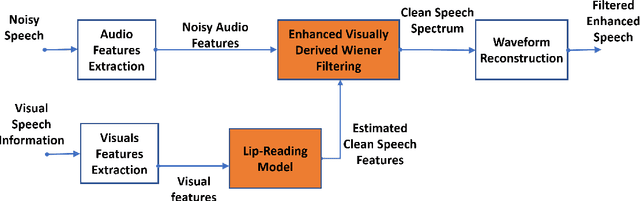
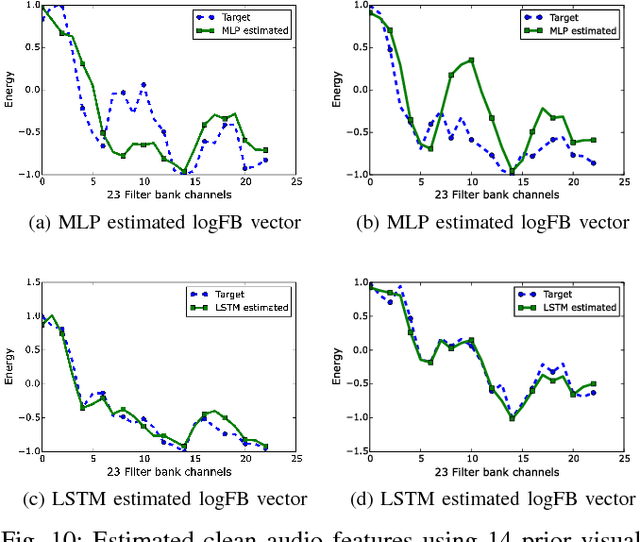
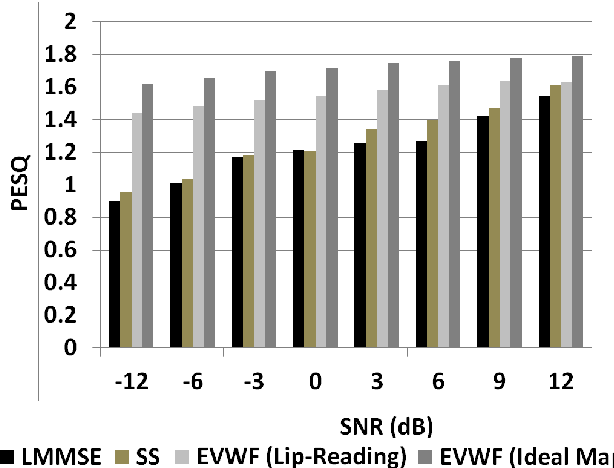
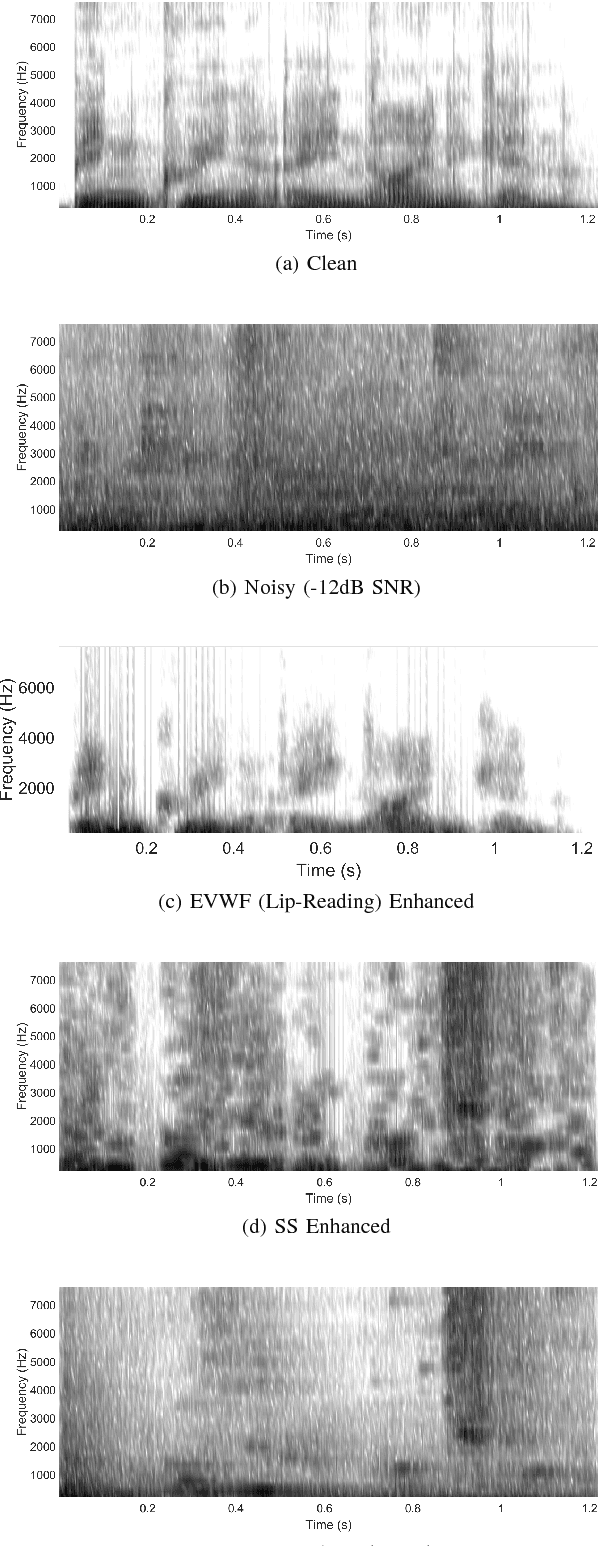
This paper proposes a novel lip-reading driven deep learning framework for speech enhancement. The proposed approach leverages the complementary strengths of both deep learning and analytical acoustic modelling (filtering based approach) as compared to recently published, comparatively simpler benchmark approaches that rely only on deep learning. The proposed audio-visual (AV) speech enhancement framework operates at two levels. In the first level, a novel deep learning-based lip-reading regression model is employed. In the second level, lip-reading approximated clean-audio features are exploited, using an enhanced, visually-derived Wiener filter (EVWF), for the clean audio power spectrum estimation. Specifically, a stacked long-short-term memory (LSTM) based lip-reading regression model is designed for clean audio features estimation using only temporal visual features considering different number of prior visual frames. For clean speech spectrum estimation, a new filterbank-domain EVWF is formulated, which exploits estimated speech features. The proposed EVWF is compared with conventional Spectral Subtraction and Log-Minimum Mean-Square Error methods using both ideal AV mapping and LSTM driven AV mapping. The potential of the proposed speech enhancement framework is evaluated under different dynamic real-world commercially-motivated scenarios (e.g. cafe, public transport, pedestrian area) at different SNR levels (ranging from low to high SNRs) using benchmark Grid and ChiME3 corpora. For objective testing, perceptual evaluation of speech quality is used to evaluate the quality of restored speech. For subjective testing, the standard mean-opinion-score method is used with inferential statistics. Comparative simulation results demonstrate significant lip-reading and speech enhancement improvement in terms of both speech quality and speech intelligibility.
Multimodal Sentiment Analysis: Addressing Key Issues and Setting up Baselines
Mar 19, 2018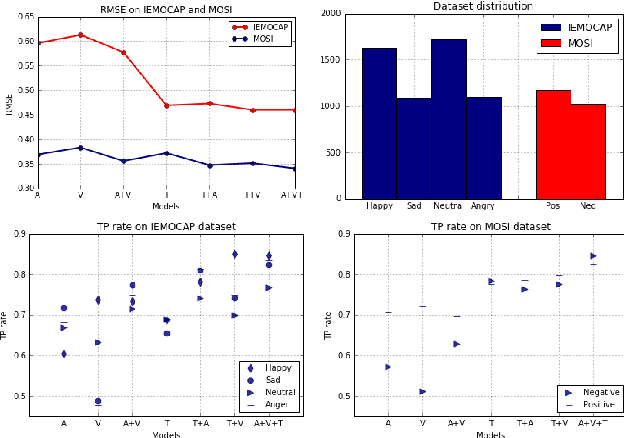
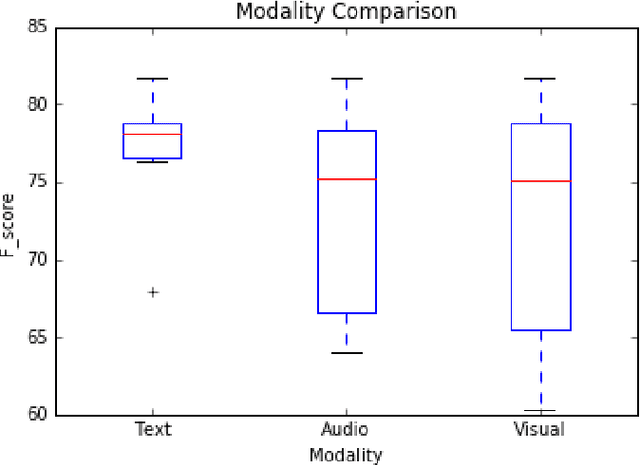
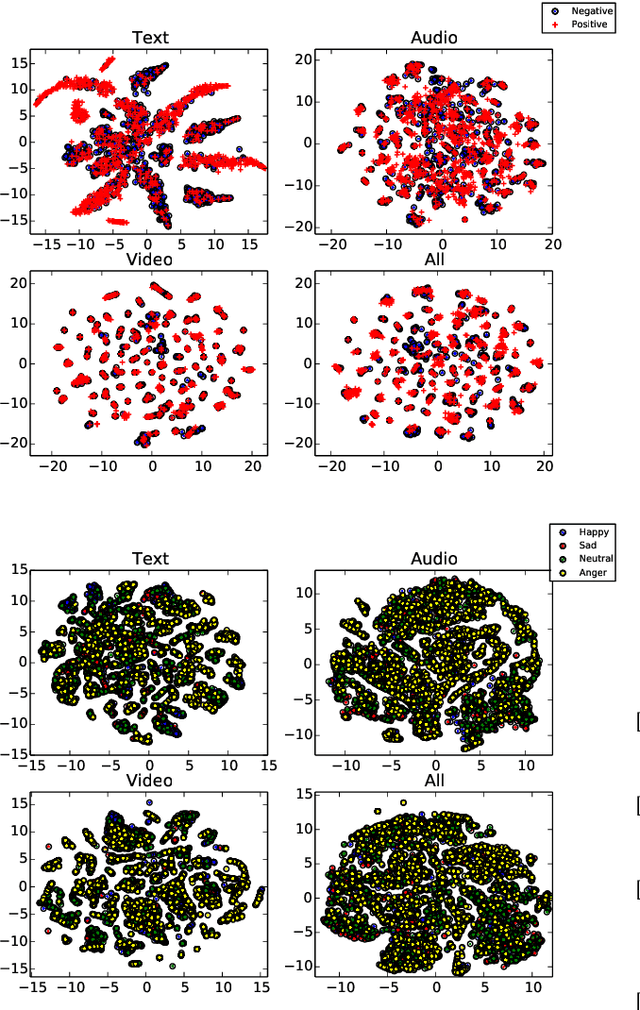
Sentiment analysis is proven to be very useful tool in many applications regarding social media. This has led to a great surge of research in this field. Hence, in this paper, we compile the baselines for such research. In this paper, we explore three different deep-learning based architectures for multimodal sentiment classification, each improving upon the previous. Further, we evaluate these architectures with multiple datasets with fixed train/test partition. We also discuss some major issues, frequently ignored in multimodal sentiment analysis research, e.g., role of speaker-exclusive models, importance of different modalities, and generalizability. This framework illustrates the different facets of analysis to be considered while performing multimodal sentiment analysis and, hence, serves as a new benchmark for future research in this emerging field. We draw a comparison among the methods using empirical data, obtained from the experiments. In the future, we plan to focus on extracting semantics from visual features, cross-modal features and fusion.
Complex-valued Neural Networks with Non-parametric Activation Functions
Feb 22, 2018
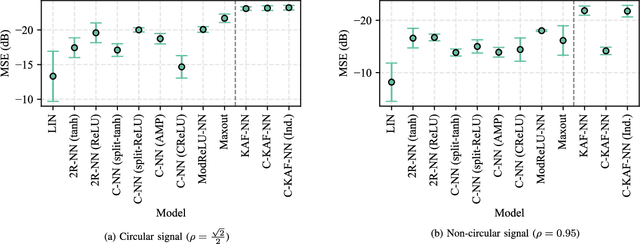
Complex-valued neural networks (CVNNs) are a powerful modeling tool for domains where data can be naturally interpreted in terms of complex numbers. However, several analytical properties of the complex domain (e.g., holomorphicity) make the design of CVNNs a more challenging task than their real counterpart. In this paper, we consider the problem of flexible activation functions (AFs) in the complex domain, i.e., AFs endowed with sufficient degrees of freedom to adapt their shape given the training data. While this problem has received considerable attention in the real case, a very limited literature exists for CVNNs, where most activation functions are generally developed in a split fashion (i.e., by considering the real and imaginary parts of the activation separately) or with simple phase-amplitude techniques. Leveraging over the recently proposed kernel activation functions (KAFs), and related advances in the design of complex-valued kernels, we propose the first fully complex, non-parametric activation function for CVNNs, which is based on a kernel expansion with a fixed dictionary that can be implemented efficiently on vectorized hardware. Several experiments on common use cases, including prediction and channel equalization, validate our proposal when compared to real-valued neural networks and CVNNs with fixed activation functions.