 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022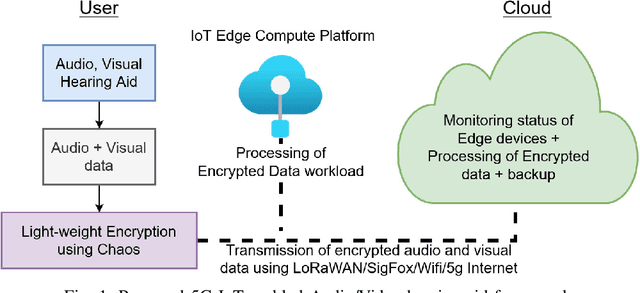

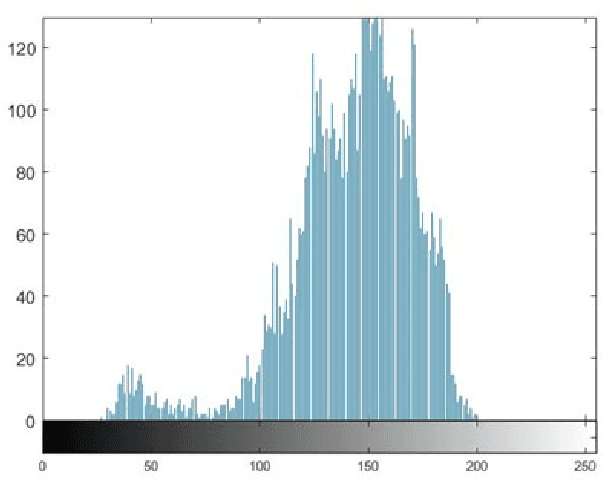
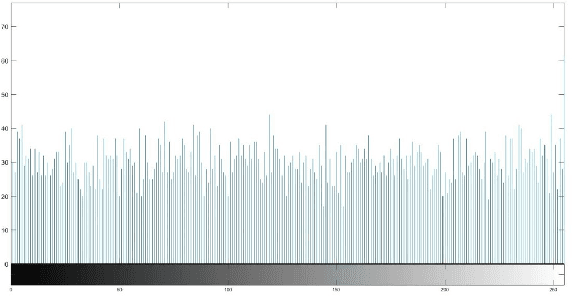
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
A Multimodal Canonical-Correlated Graph Neural Network for Energy-Efficient Speech Enhancement
Feb 09, 2022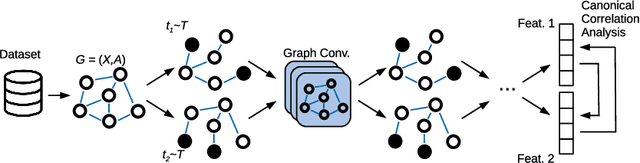
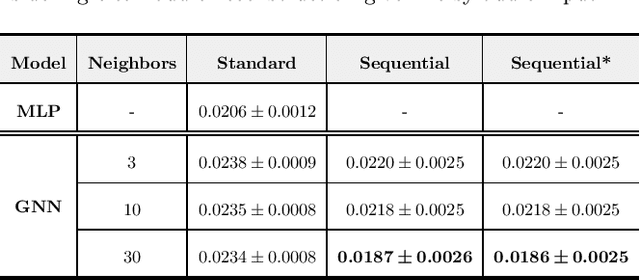
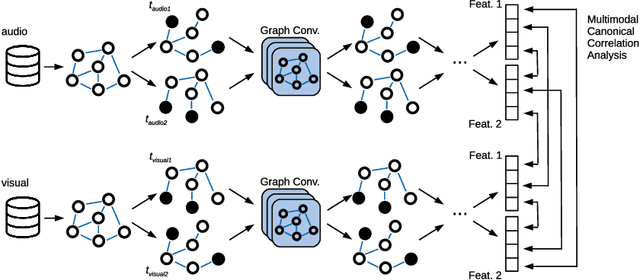
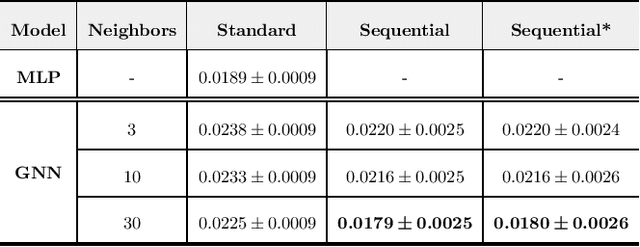
This paper proposes a novel multimodal self-supervised architecture for energy-efficient AV speech enhancement by integrating graph neural networks with canonical correlation analysis (CCA-GNN). This builds on a state-of-the-art CCA-GNN that aims to learn representative embeddings by maximizing the correlation between pairs of augmented views of the same input while decorrelating disconnected features. The key idea of the conventional CCA-GNN involves discarding augmentation-variant information and preserving augmentation-invariant information whilst preventing capturing of redundant information. Our proposed AV CCA-GNN model is designed to deal with the challenging multimodal representation learning context. Specifically, our model improves contextual AV speech processing by maximizing canonical correlation from augmented views of the same channel, as well as canonical correlation from audio and visual embeddings. In addition, we propose a positional encoding of the nodes that considers a prior-frame sequence distance instead of a feature-space representation while computing the node's nearest neighbors. This serves to introduce temporal information in the embeddings through the neighborhood's connectivity. Experiments conducted with the benchmark ChiME3 dataset show that our proposed prior frame-based AV CCA-GNN reinforces better feature learning in the temporal context, leading to more energy-efficient speech reconstruction compared to state-of-the-art CCA-GNN and multi-layer perceptron models. The results demonstrate the potential of our proposed approach for exploitation in future assistive technology and energy-efficient multimodal devices.
Design of Flexible Meander Line Antenna for Healthcare for Wireless Medical Body Area Networks
Feb 08, 2022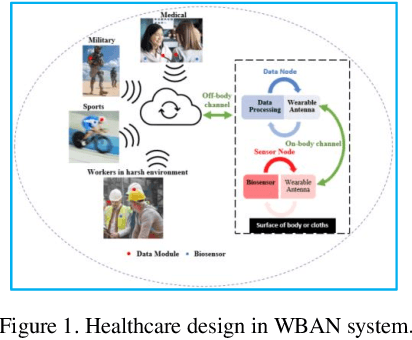
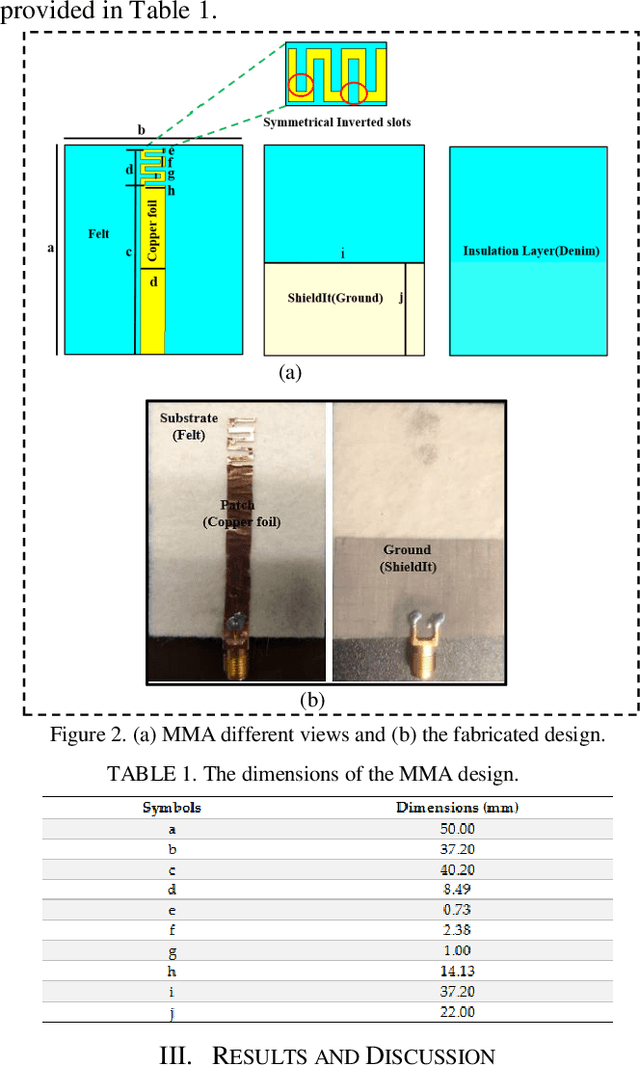
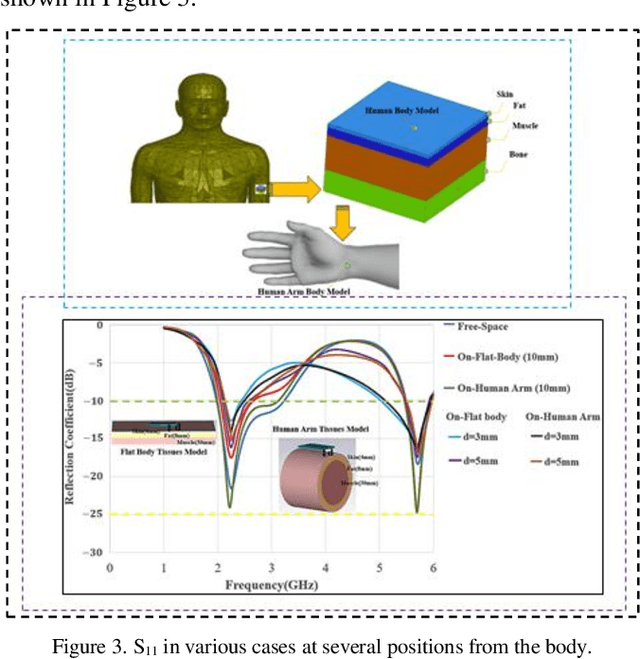
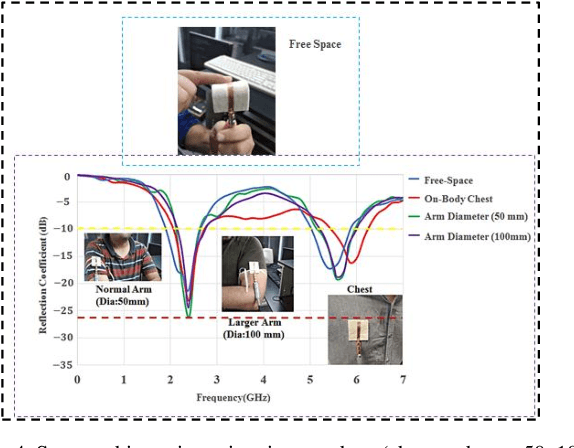
A flexible meander line monopole antenna (MMA) is presented in this paper. The antenna can be worn for on-and off-body applications. The overall dimension of the MMA is 37 mm x 50 mm x2.37 mm3. The MMA was manufactured and measured, and the results matched with simulation results. The MMA design shows a bandwidth of up to 1282.4 (450.5) MHz and provides gains of 3.03 (4.85) dBi in the lower and upper operating bands, respectively, showing omnidirectional radiation patterns in free space. While worn on the chest or arm, bandwidths as high as 688.9 (500.9) MHz and 1261.7 (524.2) MHz, and the gains of 3.80 (4.67) dBi and 3.00 (4.55) dBi were observed. The experimental measurements of the read range confirmed the results of the coverage range of up to 11 meters.
A Novel Temporal Attentive-Pooling based Convolutional Recurrent Architecture for Acoustic Signal Enhancement
Jan 24, 2022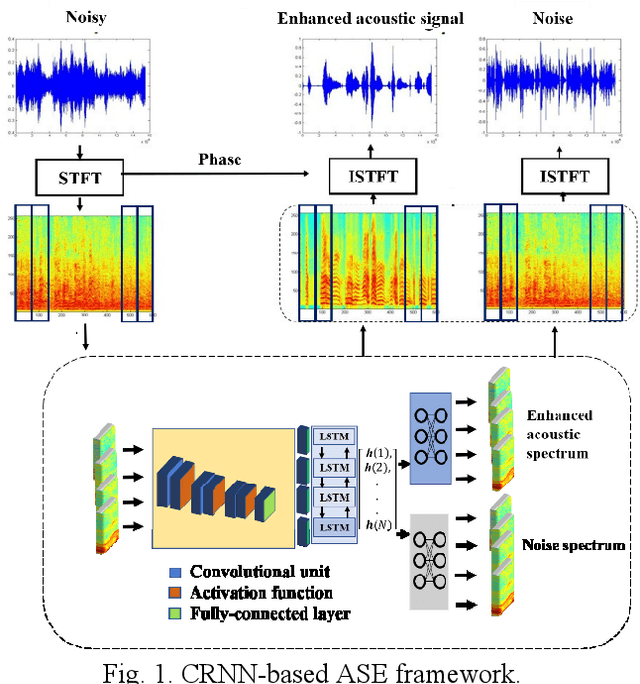
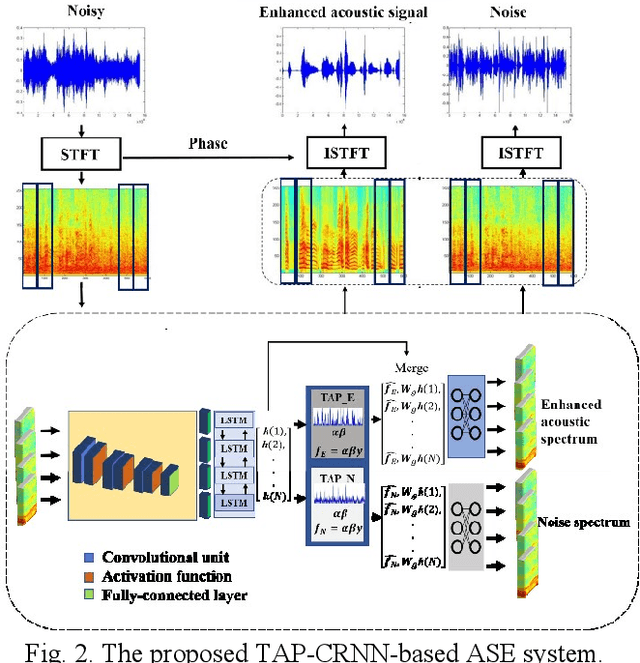
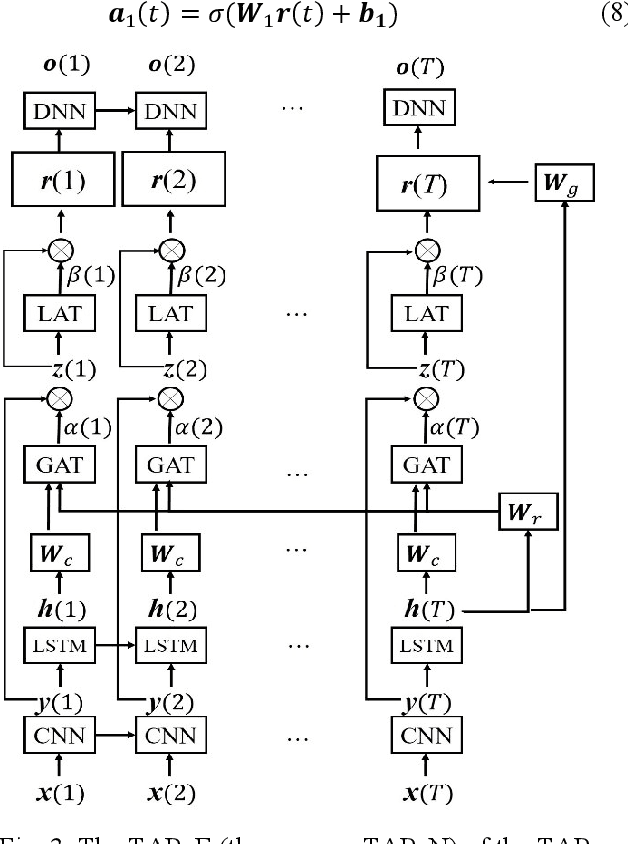
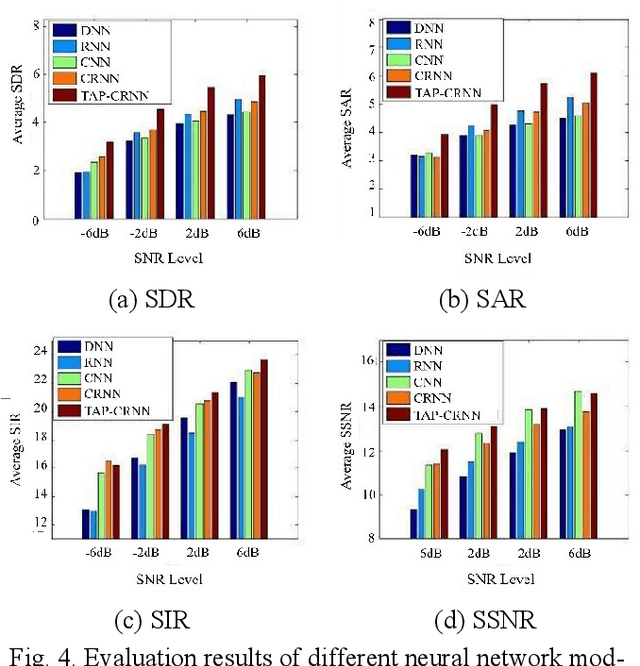
In acoustic signal processing, the target signals usually carry semantic information, which is encoded in a hierarchal structure of short and long-term contexts. However, the background noise distorts these structures in a nonuniform way. The existing deep acoustic signal enhancement (ASE) architectures ignore this kind of local and global effect. To address this problem, we propose to integrate a novel temporal attentive-pooling (TAP) mechanism into a conventional convolutional recurrent neural network, termed as TAP-CRNN. The proposed approach considers both global and local attention for ASE tasks. Specifically, we first utilize a convolutional layer to extract local information of the acoustic signals and then a recurrent neural network (RNN) architecture is used to characterize temporal contextual information. Second, we exploit a novelattention mechanism to contextually process salient regions of the noisy signals. The proposed ASE system is evaluated using a benchmark infant cry dataset and compared with several well-known methods. It is shown that the TAPCRNN can more effectively reduce noise components from infant cry signals in unseen background noises at challenging signal-to-noise levels.
Towards Robust Real-time Audio-Visual Speech Enhancement
Dec 16, 2021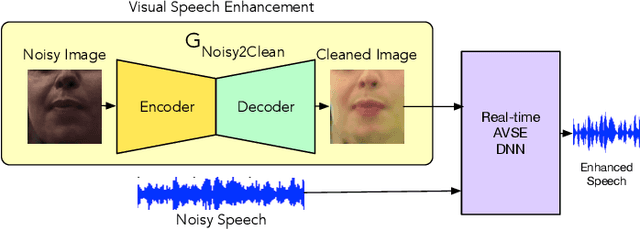
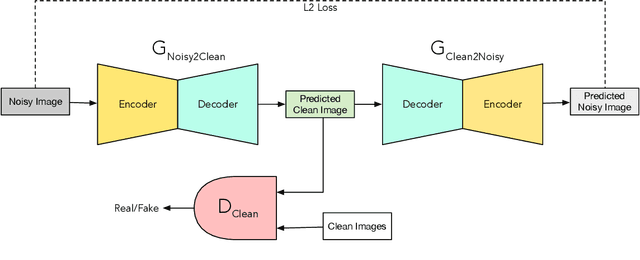

The human brain contextually exploits heterogeneous sensory information to efficiently perform cognitive tasks including vision and hearing. For example, during the cocktail party situation, the human auditory cortex contextually integrates audio-visual (AV) cues in order to better perceive speech. Recent studies have shown that AV speech enhancement (SE) models can significantly improve speech quality and intelligibility in very low signal to noise ratio (SNR) environments as compared to audio-only SE models. However, despite significant research in the area of AV SE, development of real-time processing models with low latency remains a formidable technical challenge. In this paper, we present a novel framework for low latency speaker-independent AV SE that can generalise on a range of visual and acoustic noises. In particular, a generative adversarial networks (GAN) is proposed to address the practical issue of visual imperfections in AV SE. In addition, we propose a deep neural network based real-time AV SE model that takes into account the cleaned visual speech output from GAN to deliver more robust SE. The proposed framework is evaluated on synthetic and real noisy AV corpora using objective speech quality and intelligibility metrics and subjective listing tests. Comparative simulation results show that our real time AV SE framework outperforms state-of-the-art SE approaches, including recent DNN based SE models.
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
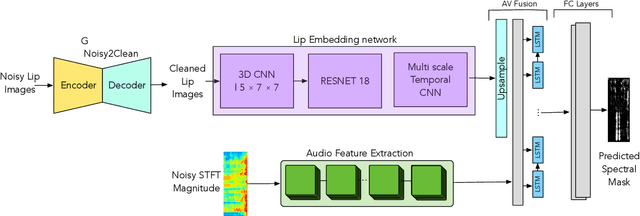
Nov 18, 2021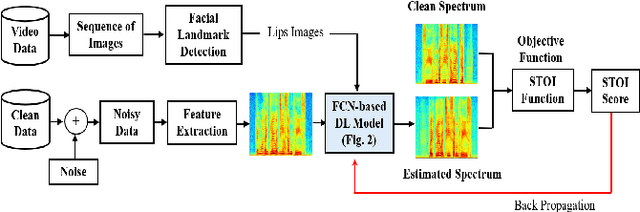
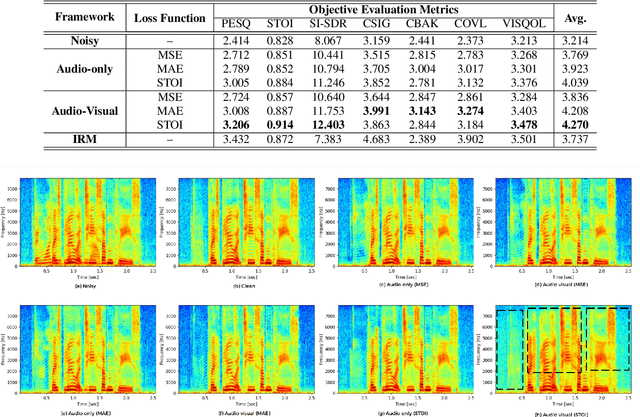
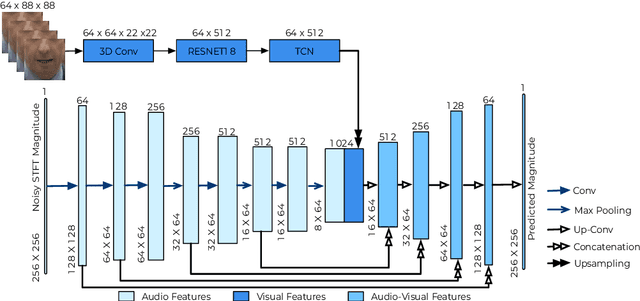
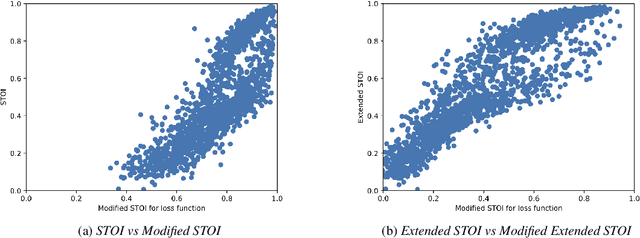
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
PointNu-Net: Simultaneous Multi-tissue Histology Nuclei Segmentation and Classification in the Clinical Wild
Nov 01, 2021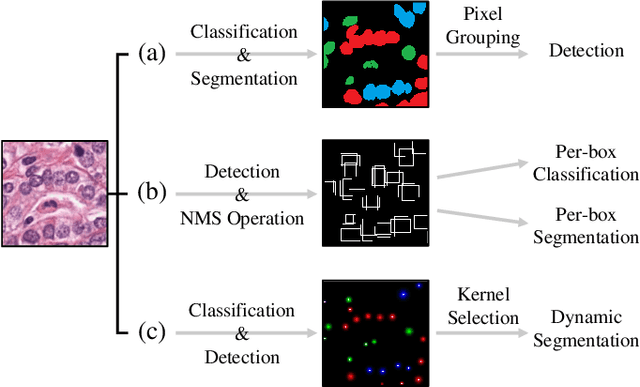
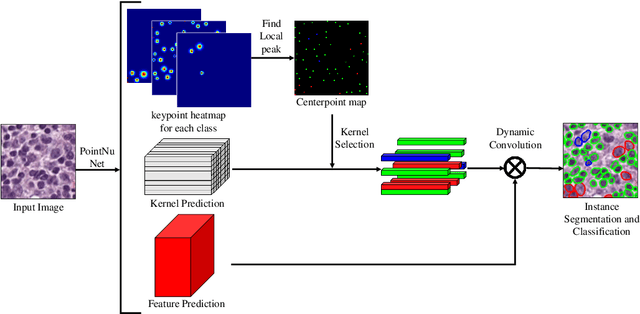
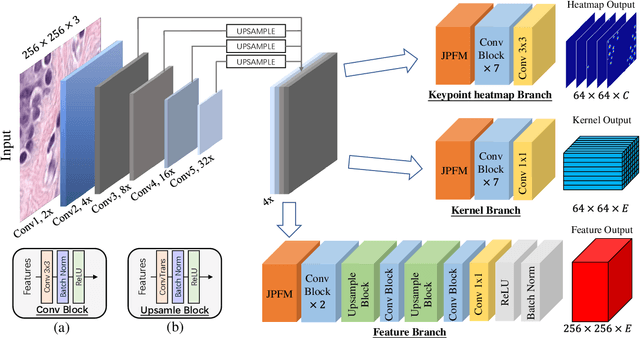
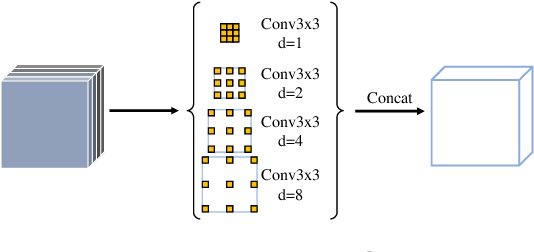
Automatic nuclei segmentation and classification plays a vital role in digital pathology. However, previous works are mostly built on data with limited diversity and small sizes, making the results questionable or misleading in actual downstream tasks. In this paper, we aim to build a reliable and robust method capable of dealing with data from the 'the clinical wild'. Specifically, we study and design a new method to simultaneously detect, segment, and classify nuclei from Haematoxylin and Eosin (H&E) stained histopathology data, and evaluate our approach using the recent largest dataset: PanNuke. We address the detection and classification of each nuclei as a novel semantic keypoint estimation problem to determine the center point of each nuclei. Next, the corresponding class-agnostic masks for nuclei center points are obtained using dynamic instance segmentation. By decoupling two simultaneous challenging tasks, our method can benefit from class-aware detection and class-agnostic segmentation, thus leading to a significant performance boost. We demonstrate the superior performance of our proposed approach for nuclei segmentation and classification across 19 different tissue types, delivering new benchmark results.
Cloud based Scalable Object Recognition from Video Streams using Orientation Fusion and Convolutional Neural Networks
Jun 19, 2021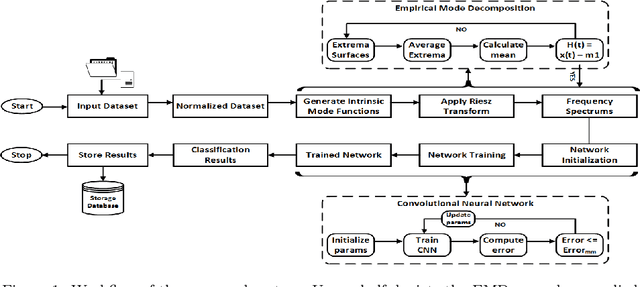
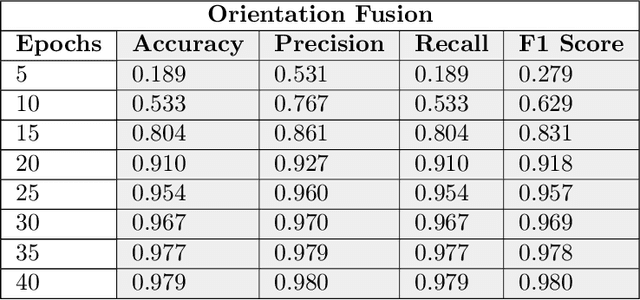
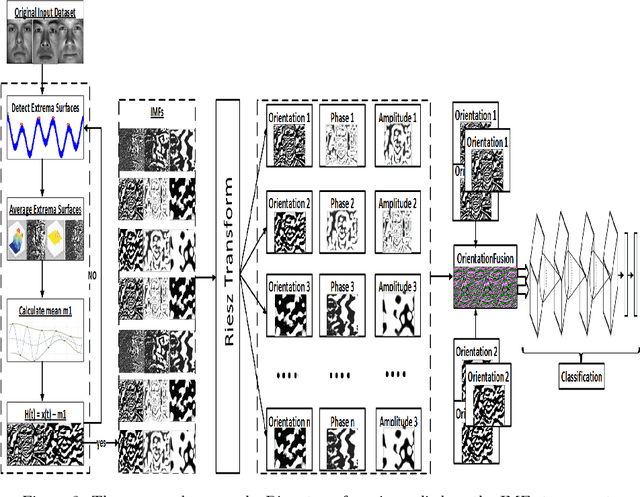

Object recognition from live video streams comes with numerous challenges such as the variation in illumination conditions and poses. Convolutional neural networks (CNNs) have been widely used to perform intelligent visual object recognition. Yet, CNNs still suffer from severe accuracy degradation, particularly on illumination-variant datasets. To address this problem, we propose a new CNN method based on orientation fusion for visual object recognition. The proposed cloud-based video analytics system pioneers the use of bi-dimensional empirical mode decomposition to split a video frame into intrinsic mode functions (IMFs). We further propose these IMFs to endure Reisz transform to produce monogenic object components, which are in turn used for the training of CNNs. Past works have demonstrated how the object orientation component may be used to pursue accuracy levels as high as 93\%. Herein we demonstrate how a feature-fusion strategy of the orientation components leads to further improving visual recognition accuracy to 97\%. We also assess the scalability of our method, looking at both the number and the size of the video streams under scrutiny. We carry out extensive experimentation on the publicly available Yale dataset, including also a self generated video datasets, finding significant improvements (both in accuracy and scale), in comparison to AlexNet, LeNet and SE-ResNeXt, which are the three most commonly used deep learning models for visual object recognition and classification.
Biased Edge Dropout for Enhancing Fairness in Graph Representation Learning
Apr 29, 2021
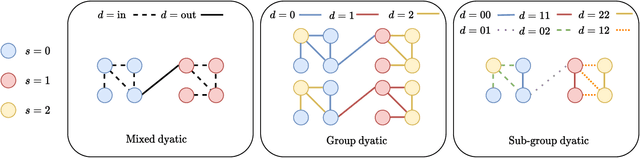
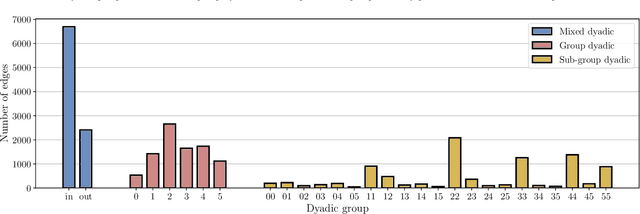

Graph representation learning has become a ubiquitous component in many scenarios, ranging from social network analysis to energy forecasting in smart grids. In several applications, ensuring the fairness of the node (or graph) representations with respect to some protected attributes is crucial for their correct deployment. Yet, fairness in graph deep learning remains under-explored, with few solutions available. In particular, the tendency of similar nodes to cluster on several real-world graphs (i.e., homophily) can dramatically worsen the fairness of these procedures. In this paper, we propose a biased edge dropout algorithm (FairDrop) to counter-act homophily and improve fairness in graph representation learning. FairDrop can be plugged in easily on many existing algorithms, is efficient, adaptable, and can be combined with other fairness-inducing solutions. After describing the general algorithm, we demonstrate its application on two benchmark tasks, specifically, as a random walk model for producing node embeddings, and to a graph convolutional network for link prediction. We prove that the proposed algorithm can successfully improve the fairness of all models up to a small or negligible drop in accuracy, and compares favourably with existing state-of-the-art solutions. In an ablation study, we demonstrate that our algorithm can flexibly interpolate between biasing towards fairness and an unbiased edge dropout. Furthermore, to better evaluate the gains, we propose a new dyadic group definition to measure the bias of a link prediction task when paired with group-based fairness metrics. In particular, we extend the metric used to measure the bias in the node embeddings to take into account the graph structure.
A New Class of Efficient Adaptive Filters for Online Nonlinear Modeling
Apr 19, 2021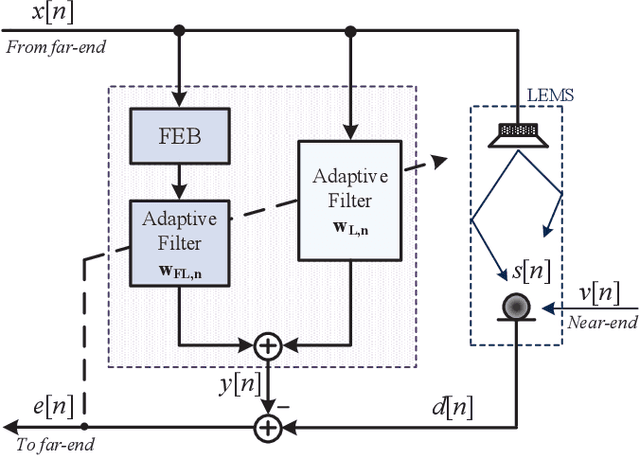
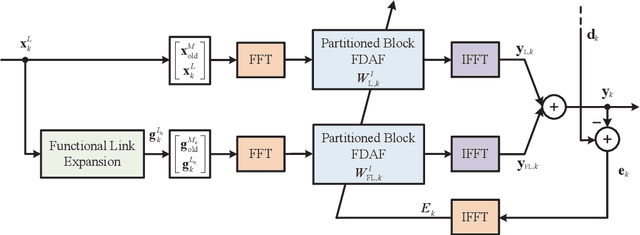
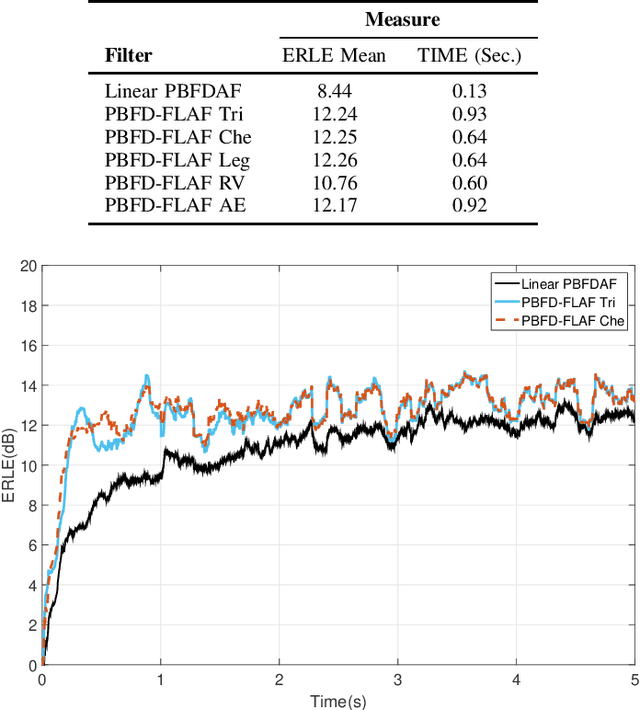

Nonlinear models are known to provide excellent performance in real-world applications that often operate in non-ideal conditions. However, such applications often require online processing to be performed with limited computational resources. In this paper, we propose a new efficient nonlinear model for online applications. The proposed algorithm is based on the linear-in-the-parameters (LIP) nonlinear filters and their implementation as functional link adaptive filters (FLAFs). We focus here on a new effective and efficient approach for FLAFs based on frequency-domain adaptive filters. We introduce the class of frequency-domain functional link adaptive filters (FD-FLAFs) and propose a partitioned block approach for their implementation. We also investigate on the functional link expansions that provide the most significant benefits operating with limited resources in the frequency-domain. We present and compare FD-FLAFs with different expansions to identify the LIP nonlinear filters showing the best tradeoff between performance and computational complexity. Experimental results prove that the frequency domain LIP nonlinear filters can be considered as an efficient and effective solution for online applications, like the nonlinear acoustic echo cancellation.