 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Theoretical Risk Attribution under Covariate-shift Effects
Feb 11, 2026When a source-trained model $Q$ is replaced by a model $\tilde{Q}$ trained on shifted data, its performance on the source domain can change unpredictably. To address this, we study the two-model risk change, $ΔR := R_P(\tilde{Q}) - R_P(Q)$, under covariate shift. We introduce TRACE (Theoretical Risk Attribution under Covariate-shift Effects), a framework that decomposes $|ΔR|$ into an interpretable upper bound. This decomposition disentangles the risk change into four actionable factors: two generalization gaps, a model change penalty, and a covariate shift penalty, transforming the bound into a powerful diagnostic tool for understanding why performance has changed. To make TRACE a fully computable diagnostic, we instantiate each term. The covariate shift penalty is estimated via a model sensitivity factor (from high-quantile input gradients) and a data-shift measure; we use feature-space Optimal Transport (OT) by default and provide a robust alternative using Maximum Mean Discrepancy (MMD). The model change penalty is controlled by the average output distance between the two models on the target sample. Generalization gaps are estimated on held-out data. We validate our framework in an idealized linear regression setting, showing the TRACE bound correctly captures the scaling of the true risk difference with the magnitude of the shift. Across synthetic and vision benchmarks, TRACE diagnostics are valid and maintain a strong monotonic relationship with the true performance degradation. Crucially, we derive a deployment gate score that correlates strongly with $|ΔR|$ and achieves high AUROC/AUPRC for gating decisions, enabling safe, label-efficient model replacement.
Fundamental limits of distributed covariance matrix estimation via a conditional strong data processing inequality
Jul 22, 2025Estimating high-dimensional covariance matrices is a key task across many fields. This paper explores the theoretical limits of distributed covariance estimation in a feature-split setting, where communication between agents is constrained. Specifically, we study a scenario in which multiple agents each observe different components of i.i.d. samples drawn from a sub-Gaussian random vector. A central server seeks to estimate the complete covariance matrix using a limited number of bits communicated by each agent. We obtain a nearly tight minimax lower bound for covariance matrix estimation under operator norm and Frobenius norm. Our main technical tool is a novel generalization of the strong data processing inequality (SDPI), termed the Conditional Strong Data Processing Inequality (C-SDPI) coefficient, introduced in this work. The C-SDPI coefficient shares key properties such as tensorization with the conventional SDPI. Crucially, it quantifies the average contraction in a state-dependent channel and can be significantly lower than the worst-case SDPI coefficient over the state input. Utilizing the doubling trick of Geng-Nair and an operator Jensen inequality, we compute this coefficient for Gaussian mixture channels. We then employ it to establish minimax lower bounds on estimation error, capturing the trade-offs among sample size, communication cost, and data dimensionality. Building on this, we present a nearly optimal estimation protocol whose sample and communication requirements match the lower bounds up to logarithmic factors. Unlike much of the existing literature, our framework does not assume infinite samples or Gaussian distributions, making it broadly applicable. Finally, we extend our analysis to interactive protocols, showing interaction can significantly reduce communication requirements compared to non-interactive schemes.
A New Approach to Backtracking Counterfactual Explanations: A Causal Framework for Efficient Model Interpretability
May 05, 2025Counterfactual explanations enhance interpretability by identifying alternative inputs that produce different outputs, offering localized insights into model decisions. However, traditional methods often neglect causal relationships, leading to unrealistic examples. While newer approaches integrate causality, they are computationally expensive. To address these challenges, we propose an efficient method based on backtracking counterfactuals that incorporates causal reasoning to generate actionable explanations. We first examine the limitations of existing methods and then introduce our novel approach and its features. We also explore the relationship between our method and previous techniques, demonstrating that it generalizes them in specific scenarios. Finally, experiments show that our method provides deeper insights into model outputs.
Supermodular f-divergences and bounds on lossy compression and generalization error with mutual f-information
Jun 27, 2022
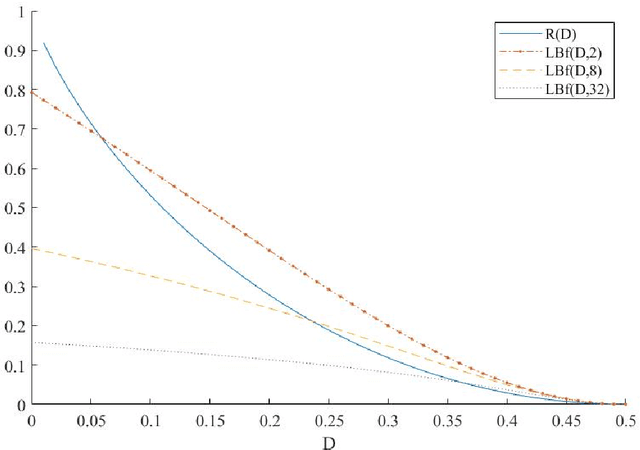
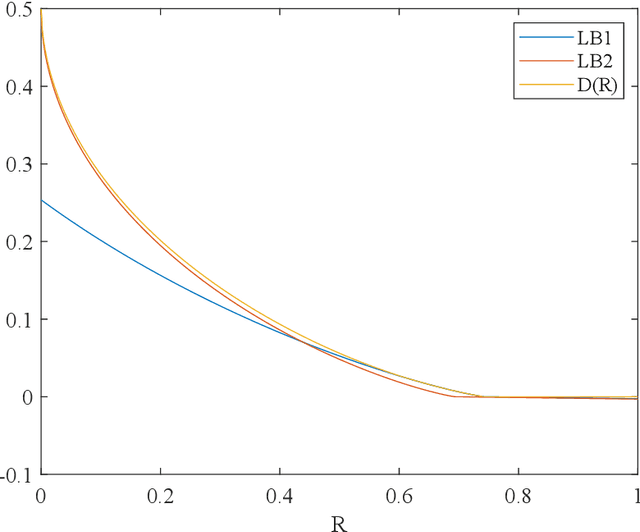
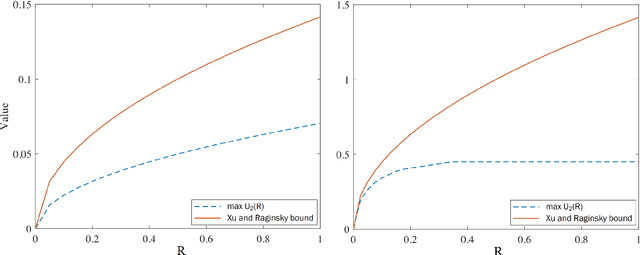
In this paper, we introduce super-modular $\mf$-divergences and provide three applications for them: (i) we introduce Sanov's upper bound on the tail probability of sum of independent random variables based on super-modular $\mf$-divergence and show that our generalized Sanov's bound strictly improves over ordinary one, (ii) we consider the lossy compression problem which studies the set of achievable rates for a given distortion and code length. We extend the rate-distortion function using mutual $\mf$-information and provide new and strictly better bounds on achievable rates in the finite blocklength regime using super-modular $\mf$-divergences, and (iii) we provide a connection between the generalization error of algorithms with bounded input/output mutual $\mf$-information and a generalized rate-distortion problem. This connection allows us to bound the generalization error of learning algorithms using lower bounds on the rate-distortion function. Our bound is based on a new lower bound on the rate-distortion function that (for some examples) strictly improves over previously best-known bounds. Moreover, super-modular $\mf$-divergences are utilized to reduce the dimension of the problem and obtain single-letter bounds.
Sequential Estimation under Multiple Resources: a Bandit Point of View
Sep 29, 2021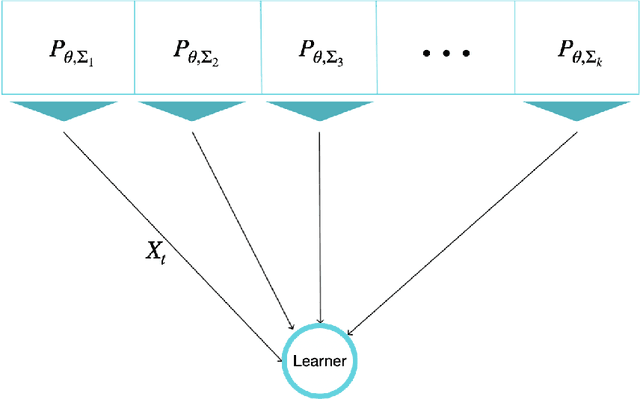
The problem of Sequential Estimation under Multiple Resources (SEMR) is defined in a federated setting. SEMR could be considered as the intersection of statistical estimation and bandit theory. In this problem, an agent is confronting with k resources to estimate a parameter $\theta$. The agent should continuously learn the quality of the resources by wisely choosing them and at the end, proposes an estimator based on the collected data. In this paper, we assume that the resources' distributions are Gaussian. The quality of the final estimator is evaluated by its mean squared error. Also, we restrict our class of estimators to unbiased estimators in order to define a meaningful notion of regret. The regret measures the performance of the agent by the variance of the final estimator in comparison to the optimal variance. We propose a lower bound to determine the fundamental limit of the setting even in the case that the distributions are not Gaussian. Also, we offer an order-optimal algorithm to achieve this lower bound.