 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Meta-Network for Learning on Kolmogorov-Arnold Networks
Feb 18, 2026Weight-space models learn directly from the parameters of neural networks, enabling tasks such as predicting their accuracy on new datasets. Naive methods -- like applying MLPs to flattened parameters -- perform poorly, making the design of better weight-space architectures a central challenge. While prior work leveraged permutation symmetries in standard networks to guide such designs, no analogous analysis or tailored architecture yet exists for Kolmogorov-Arnold Networks (KANs). In this work, we show that KANs share the same permutation symmetries as MLPs, and propose the KAN-graph, a graph representation of their computation. Building on this, we develop WS-KAN, the first weight-space architecture that learns on KANs, which naturally accounts for their symmetry. We analyze WS-KAN's expressive power, showing it can replicate an input KAN's forward pass - a standard approach for assessing expressiveness in weight-space architectures. We construct a comprehensive ``zoo'' of trained KANs spanning diverse tasks, which we use as benchmarks to empirically evaluate WS-KAN. Across all tasks, WS-KAN consistently outperforms structure-agnostic baselines, often by a substantial margin. Our code is available at https://github.com/BarSGuy/KAN-Graph-Metanetwork.
Billion-Scale Graph Foundation Models
Feb 04, 2026Graph-structured data underpins many critical applications. While foundation models have transformed language and vision via large-scale pretraining and lightweight adaptation, extending this paradigm to general, real-world graphs is challenging. In this work, we present Graph Billion- Foundation-Fusion (GraphBFF): the first end-to-end recipe for building billion-parameter Graph Foundation Models (GFMs) for arbitrary heterogeneous, billion-scale graphs. Central to the recipe is the GraphBFF Transformer, a flexible and scalable architecture designed for practical billion-scale GFMs. Using the GraphBFF, we present the first neural scaling laws for general graphs and show that loss decreases predictably as either model capacity or training data scales, depending on which factor is the bottleneck. The GraphBFF framework provides concrete methodologies for data batching, pretraining, and fine-tuning for building GFMs at scale. We demonstrate the effectiveness of the framework with an evaluation of a 1.4 billion-parameter GraphBFF Transformer pretrained on one billion samples. Across ten diverse, real-world downstream tasks on graphs unseen during training, spanning node- and link-level classification and regression, GraphBFF achieves remarkable zero-shot and probing performance, including in few-shot settings, with large margins of up to 31 PRAUC points. Finally, we discuss key challenges and open opportunities for making GFMs a practical and principled foundation for graph learning at industrial scale.
The Stochastic Complexity of Principal Component Analysis
Dec 31, 2018
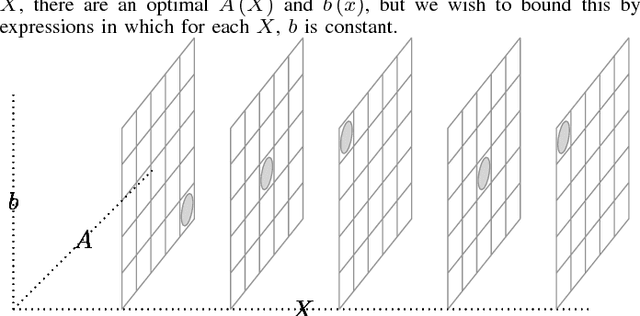


PCA (principal component analysis) and its variants are ubiquitous techniques for matrix dimension reduction and reduced-dimension latent-factor extraction. For an arbitrary matrix, they cannot, on their own, determine the size of the reduced dimension, but rather must be given this as an input. NML (normalized maximum likelihood) is a universal implementation of the Minimal Description Length principle, which gives an objective compression-based criterion for model selection. This work applies NML to PCA. A direct attempt to do so would involve the distributions of singular values of random matrices, which is difficult. A reduction to linear regression with a noisy unitary covariate matrix, however, allows finding closed-form bounds on the NML of PCA.