 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Complexity of Reinforcement Learning using Linearly Combined Model Ensembles
Oct 23, 2019Reinforcement learning (RL) methods have been shown to be capable of learning intelligent behavior in rich domains. However, this has largely been done in simulated domains without adequate focus on the process of building the simulator. In this paper, we consider a setting where we have access to an ensemble of pre-trained and possibly inaccurate simulators (models). We approximate the real environment using a state-dependent linear combination of the ensemble, where the coefficients are determined by the given state features and some unknown parameters. Our proposed algorithm provably learns a near-optimal policy with a sample complexity polynomial in the number of unknown parameters, and incurs no dependence on the size of the state (or action) space. As an extension, we also consider the more challenging problem of model selection, where the state features are unknown and can be chosen from a large candidate set. We provide exponential lower bounds that illustrate the fundamental hardness of this problem, and develop a provably efficient algorithm under additional natural assumptions.
Thompson Sampling in Non-Episodic Restless Bandits
Oct 12, 2019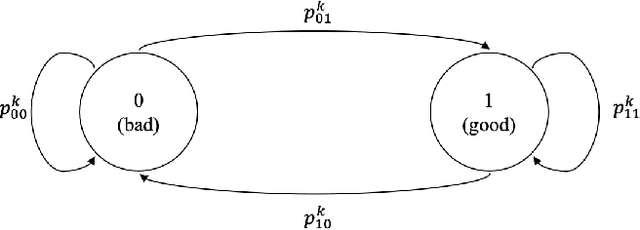
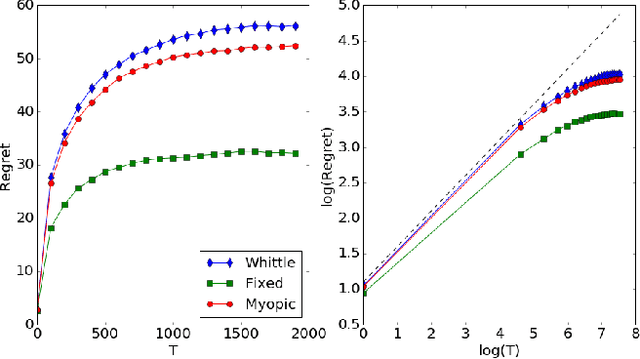
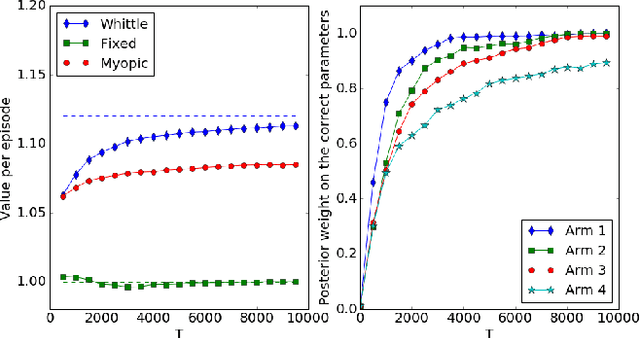
Restless bandit problems assume time-varying reward distributions of the arms, which adds flexibility to the model but makes the analysis more challenging. We study learning algorithms over the unknown reward distributions and prove a sub-linear, $O(\sqrt{T}\log T)$, regret bound for a variant of Thompson sampling. Our analysis applies in the infinite time horizon setting, resolving the open question raised by Jung and Tewari (2019) whose analysis is limited to the episodic case. We adopt their policy mapping framework, which allows our algorithm to be efficient and simultaneously keeps the regret meaningful. Our algorithm adapts the TSDE algorithm of Ouyang et al. (2017) in a non-trivial manner to account for the special structure of restless bandits. We test our algorithm on a simulated dynamic channel access problem with several policy mappings, and the empirical regrets agree with the theoretical bound regardless of the choice of the policy mapping.
What You See May Not Be What You Get: UCB Bandit Algorithms Robust to ε-Contamination
Oct 12, 2019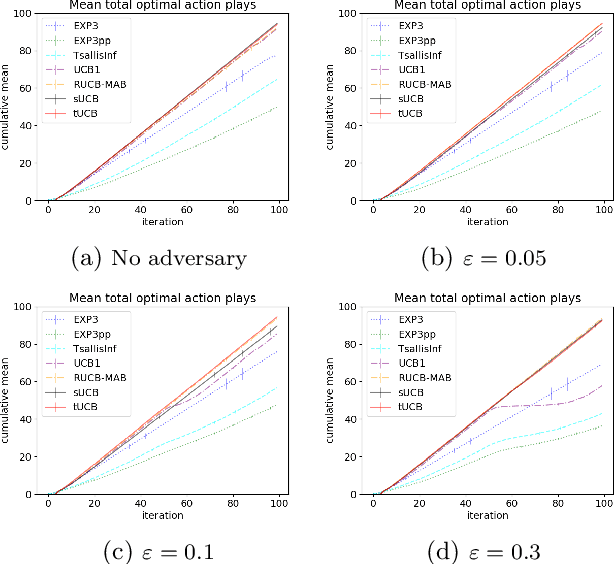
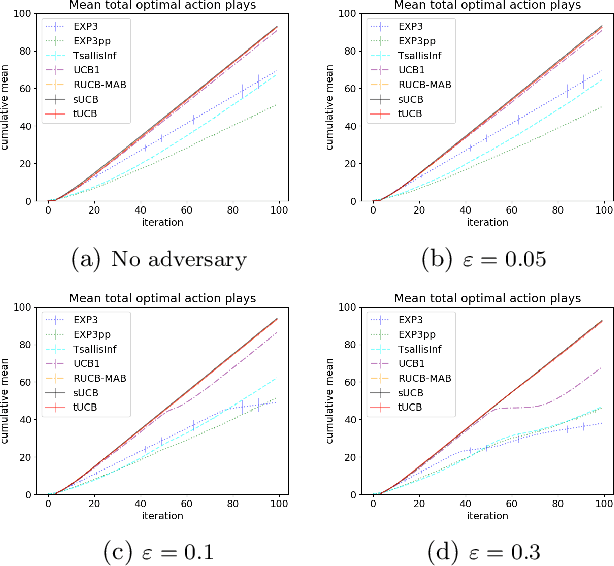
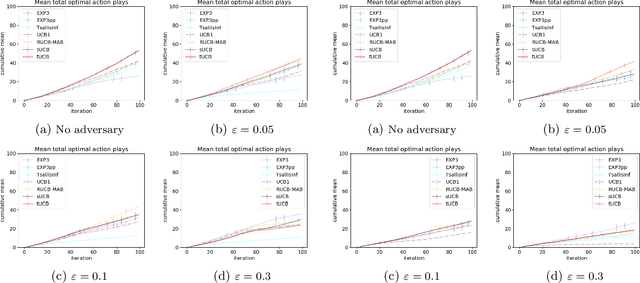
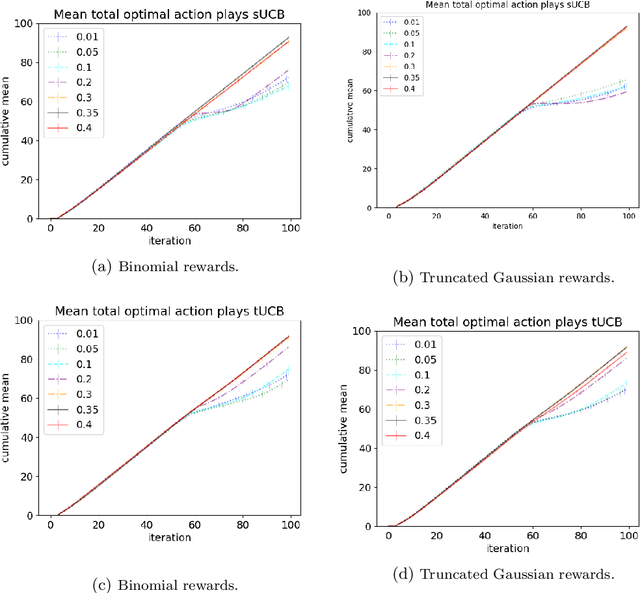
Motivated by applications of bandit algorithms in education, we consider a stochastic multi-armed bandit problem with $\varepsilon$-contaminated rewards. We allow an adversary to arbitrarily give unbounded contaminated rewards with full knowledge of the past and future. We impose only the constraint that at any time $t$ the proportion of contaminated rewards for any action is less than or equal to $\varepsilon$. We derive concentration inequalities for two robust mean estimators for sub-Gaussian distributions in the $\varepsilon$-contamination context. We define the $\varepsilon$-contaminated stochastic bandit problem and use our robust mean estimators to give two variants of a robust Upper Confidence Bound (UCB) algorithm, crUCB. Using regret derived from only the underlying stochastic rewards, both variants of crUCB achieve $\mathcal{O} (\sqrt{KT\log T})$ regret when $\varepsilon$ is small enough. Our simulations are designed to reflect reasonable settings a teacher would experience when implementing a bandit algorithm and thus use a limited horizon. We show that in certain adversarial regimes crUCB not only outperforms algorithms designed for stochastic (UCB1) and adversarial bandits (EXP3) but also those that have "best of both worlds" guarantees (EXP3++ and TsallisInf) even when our constraint on $\varepsilon$ is broken.
Not All are Made Equal: Consistency of Weighted Averaging Estimators Under Active Learning
Oct 11, 2019
Active learning seeks to build the best possible model with a budget of labelled data by sequentially selecting the next point to label. However the training set is no longer \textit{iid}, violating the conditions required by existing consistency results. Inspired by the success of Stone's Theorem we aim to regain consistency for weighted averaging estimators under active learning. Based on ideas in \citet{dasgupta2012consistency}, our approach is to enforce a small amount of random sampling by running an augmented version of the underlying active learning algorithm. We generalize Stone's Theorem in the noise free setting, proving consistency for well known classifiers such as $k$-NN, histogram and kernel estimators under conditions which mirror classical results. However in the presence of noise we can no longer deal with these estimators in a unified manner; for some satisfying this condition also guarantees sufficiency in the noisy case, while for others we can achieve near perfect inconsistency while this condition holds. Finally we provide conditions for consistency in the presence of noise, which give insight into why these estimators can behave so differently under the combination of noise and active learning.
Regret Analysis of Causal Bandit Problems
Oct 11, 2019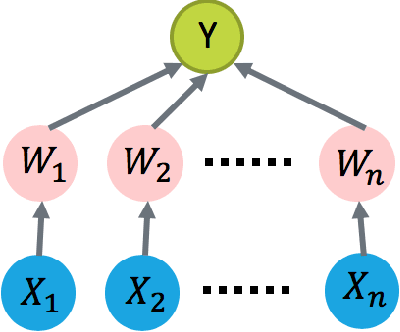
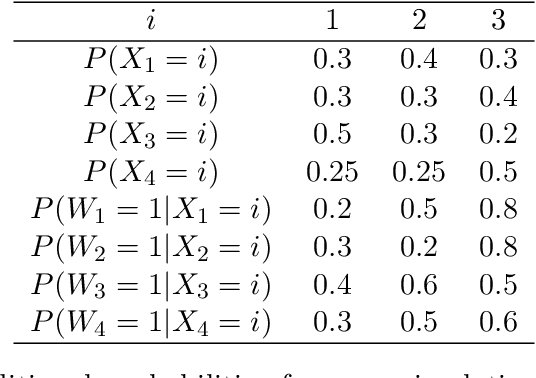
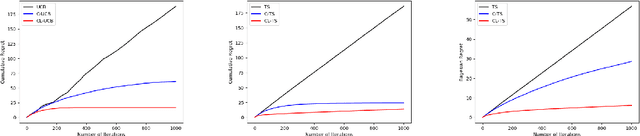

We study how to learn optimal interventions sequentially given causal information represented as a causal graph along with associated conditional distributions. Causal modeling is useful in real world problems like online advertisement where complex causal mechanisms underlie the relationship between interventions and outcomes. We propose two algorithms, causal upper confidence bound (C-UCB) and causal Thompson Sampling (C-TS), that enjoy improved cumulative regret bounds compared with algorithms that do not use causal information. We thus resolve an open problem posed by~\cite{lattimore2016causal}. Further, we extend C-UCB and C-TS to the linear bandit setting and propose causal linear UCB (CL-UCB) and causal linear TS (CL-TS) algorithms. These algorithms enjoy a cumulative regret bound that only scales with the feature dimension. Our experiments show the benefit of using causal information. For example, we observe that even with a few hundreds of iterations, the regret of causal algorithms is less than that of standard algorithms by a factor of three. We also show that under certain causal structures, our algorithms scale better than the standard bandit algorithms as the number of interventions increases.
Regret Bounds for Thompson Sampling in Restless Bandit Problems
May 29, 2019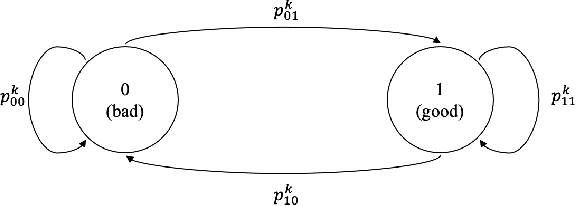
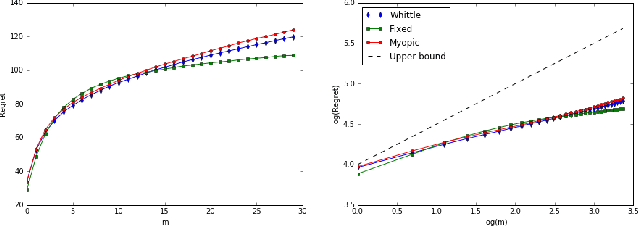
Restless bandit problems are instances of non-stationary multi-armed bandits. These problems have been studied well from the optimization perspective, where we aim to efficiently find a near-optimal policy when system parameters are known. However, very few papers adopt a learning perspective, where the parameters are unknown. In this paper, we analyze the performance of Thompson sampling in restless bandits with unknown parameters. We consider a general policy map to define our competitor and prove an $\tilde{O}(\sqrt{T})$ Bayesian regret bound. Our competitor is flexible enough to represent various benchmarks including the best fixed action policy, the optimal policy, the Whittle index policy, or the myopic policy. We also present empirical results that support our theoretical findings.
Generalization Bounds in the Predict-then-Optimize Framework
May 27, 2019The predict-then-optimize framework is fundamental in many practical settings: predict the unknown parameters of an optimization problem, and then solve the problem using the predicted values of the parameters. A natural loss function in this environment is to consider the cost of the decisions induced by the predicted parameters, in contrast to the prediction error of the parameters. This loss function was recently introduced in Elmachtoub and Grigas (2017), which called it the Smart Predict-then-Optimize (SPO) loss. Since the SPO loss is nonconvex and noncontinuous, standard results for deriving generalization bounds do not apply. In this work, we provide an assortment of generalization bounds for the SPO loss function. In particular, we derive bounds based on the Natarajan dimension that, in the case of a polyhedral feasible region, scale at most logarithmically in the number of extreme points, but, in the case of a general convex set, have poor dependence on the dimension. By exploiting the structure of the SPO loss function and an additional strong convexity assumption on the feasible region, we can dramatically improve the dependence on the dimension via an analysis and corresponding bounds that are akin to the margin guarantees in classification problems.
Randomized Algorithms for Data-Driven Stabilization of Stochastic Linear Systems
May 16, 2019
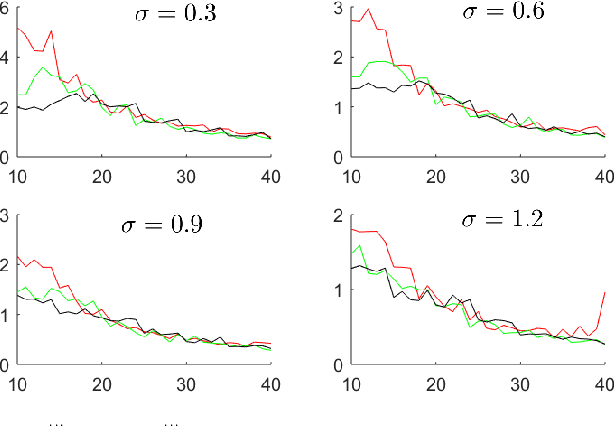
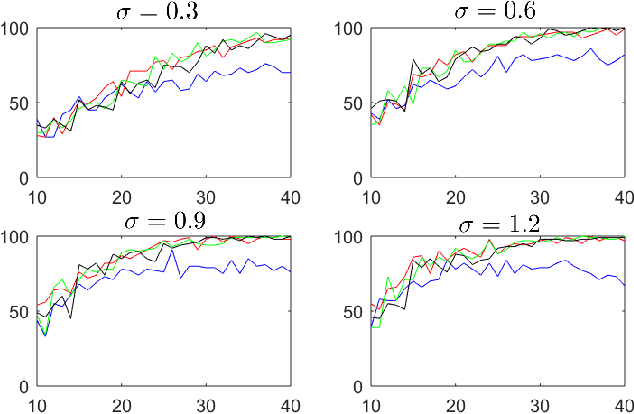
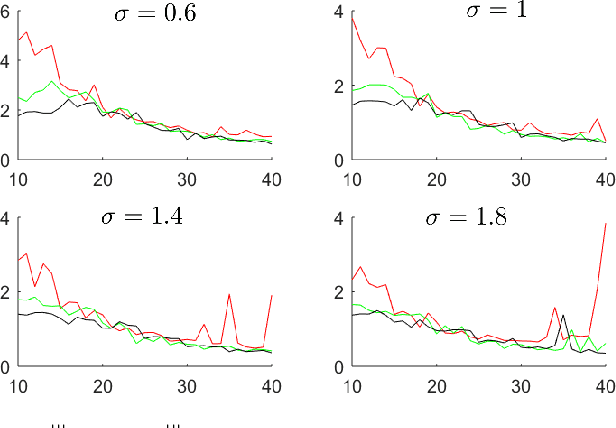
Data-driven control strategies for dynamical systems with unknown parameters are popular in theory and applications. An essential problem is to prevent stochastic linear systems becoming destabilized, due to the uncertainty of the decision-maker about the dynamical parameter. Two randomized algorithms are proposed for this problem, but the performance is not sufficiently investigated. Further, the effect of key parameters of the algorithms such as the magnitude and the frequency of applying the randomizations is not currently available. This work studies the stabilization speed and the failure probability of data-driven procedures. We provide numerical analyses for the performance of two methods: stochastic feedback, and stochastic parameter. The presented results imply that as long as the number of statistically independent randomizations is not too small, fast stabilization is guaranteed.
Contextual Markov Decision Processes using Generalized Linear Models
Mar 14, 2019
We consider the recently proposed reinforcement learning (RL) framework of Contextual Markov Decision Processes (CMDP), where the agent has a sequence of episodic interactions with tabular environments chosen from a possibly infinite set. The parameters of these environments depend on a context vector that is available to the agent at the start of each episode. In this paper, we propose a no-regret online RL algorithm in the setting where the MDP parameters are obtained from the context using generalized linear models (GLMs). The proposed algorithm \texttt{GL-ORL} relies on efficient online updates and is also memory efficient. Our analysis of the algorithm gives new results in the logit link case and improves previous bounds in the linear case. Our algorithm uses efficient Online Newton Step updates to build confidence sets. Moreover, for any strongly convex link function, we also show a generic conversion from any online no-regret algorithm to confidence sets.
On Applications of Bootstrap in Continuous Space Reinforcement Learning
Mar 14, 2019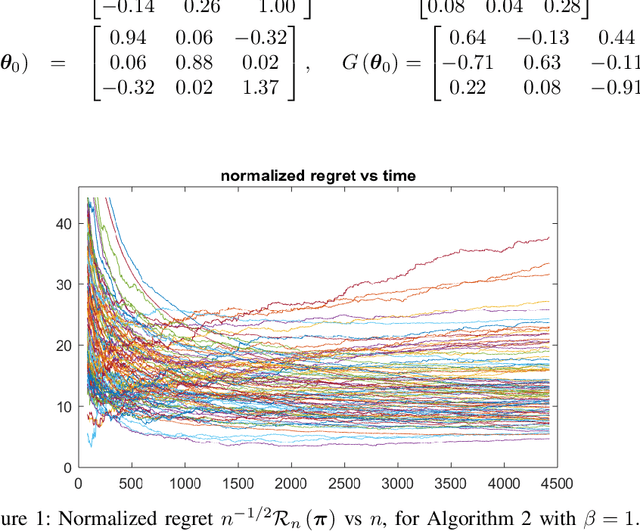
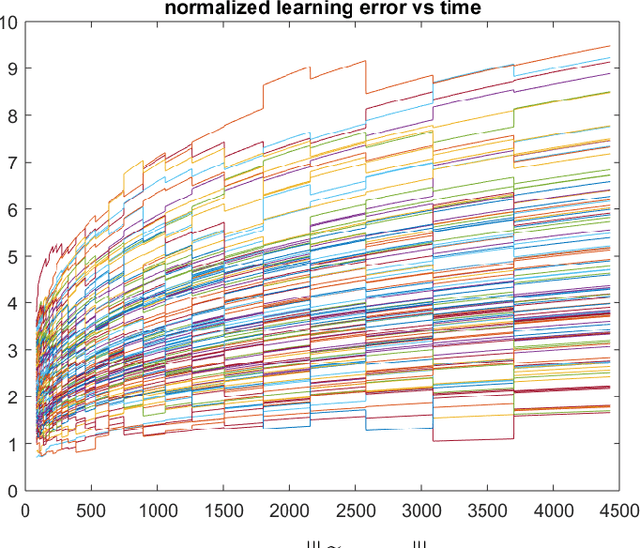
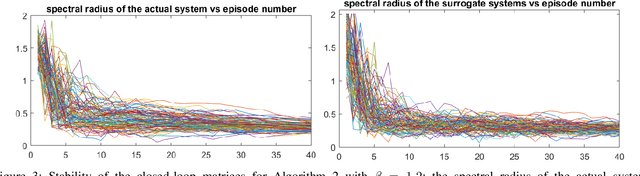
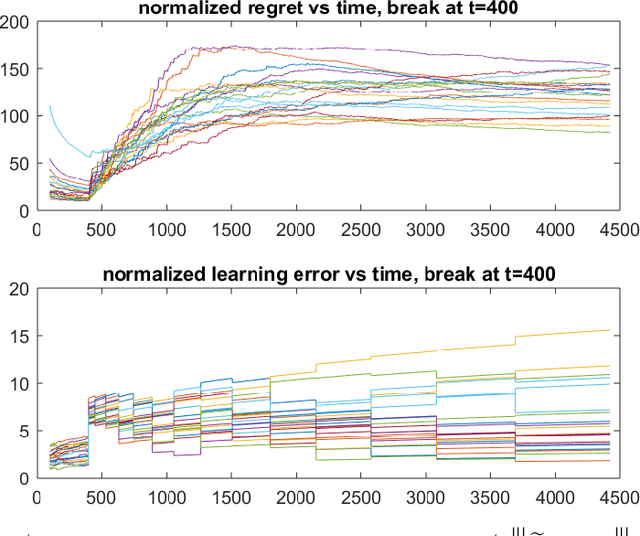
In decision making problems for continuous state and action spaces, linear dynamical models are widely employed. Specifically, policies for stochastic linear systems subject to quadratic cost functions capture a large number of applications in reinforcement learning. Selected randomized policies have been studied in the literature recently that address the trade-off between identification and control. However, little is known about policies based on bootstrapping observed states and actions. In this work, we show that bootstrap-based policies achieve a square root scaling of regret with respect to time. We also obtain results on the accuracy of learning the model's dynamics. Corroborative numerical analysis that illustrates the technical results is also provided.