 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Intelligence Augmentation in Multi-Domain Operations
Oct 16, 2019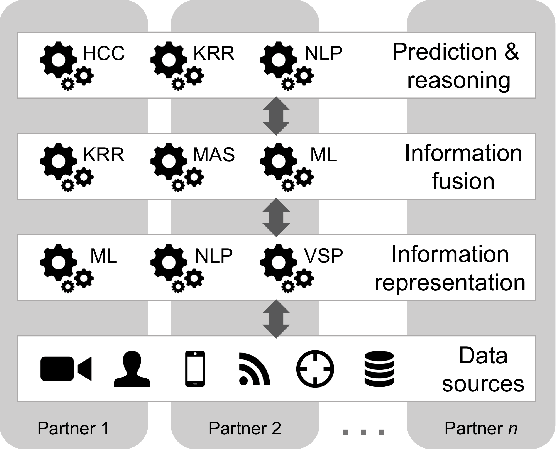
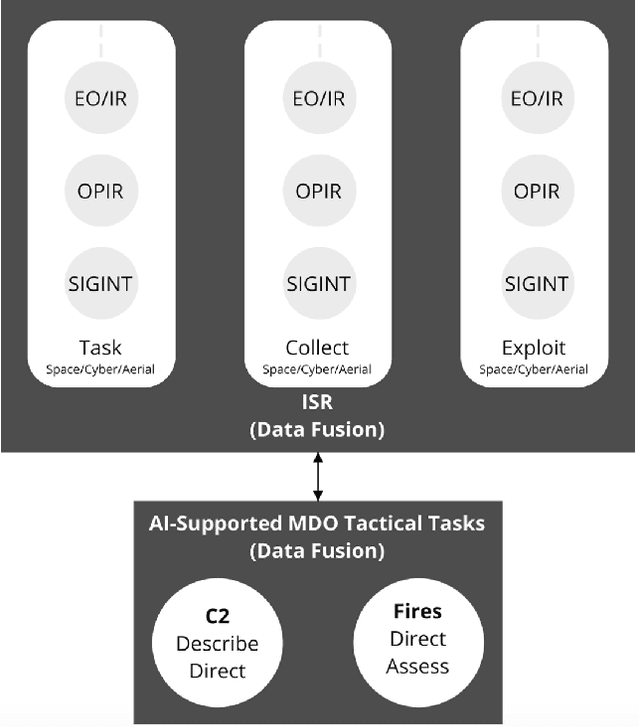
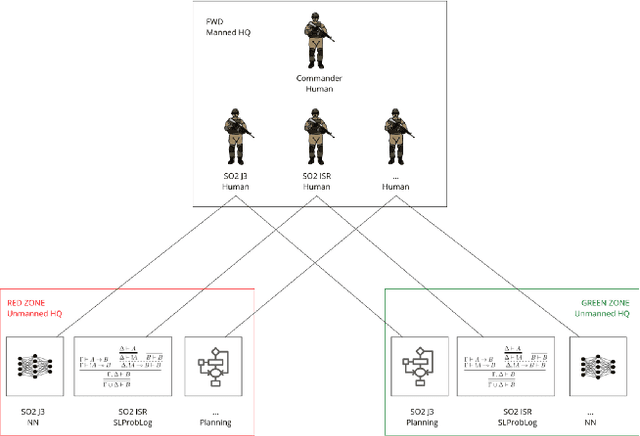
Central to the concept of multi-domain operations (MDO) is the utilization of an intelligence, surveillance, and reconnaissance (ISR) network consisting of overlapping systems of remote and autonomous sensors, and human intelligence, distributed among multiple partners. Realising this concept requires advancement in both artificial intelligence (AI) for improved distributed data analytics and intelligence augmentation (IA) for improved human-machine cognition. The contribution of this paper is threefold: (1) we map the coalition situational understanding (CSU) concept to MDO ISR requirements, paying particular attention to the need for assured and explainable AI to allow robust human-machine decision-making where assets are distributed among multiple partners; (2) we present illustrative vignettes for AI and IA in MDO ISR, including human-machine teaming, dense urban terrain analysis, and enhanced asset interoperability; (3) we appraise the state-of-the-art in explainable AI in relation to the vignettes with a focus on human-machine collaboration to achieve more rapid and agile coalition decision-making. The union of these three elements is intended to show the potential value of a CSU approach in the context of MDO ISR, grounded in three distinct use cases, highlighting how the need for explainability in the multi-partner coalition setting is key.
BMVC 2019: Workshop on Interpretable and Explainable Machine Vision
Sep 16, 2019Proceedings of the BMVC 2019 Workshop on Interpretable and Explainable Machine Vision, Cardiff, UK, September 12, 2019.
Explainable Deep Learning for Video Recognition Tasks: A Framework & Recommendations
Sep 07, 2019The popularity of Deep Learning for real-world applications is ever-growing. With the introduction of high performance hardware, applications are no longer limited to image recognition. With the introduction of more complex problems comes more and more complex solutions, and the increasing need for explainable AI. Deep Neural Networks for Video tasks are amongst the most complex models, with at least twice the parameters of their Image counterparts. However, explanations for these models are often ill-adapted to the video domain. The current work in explainability for video models is still overshadowed by Image techniques, while Video Deep Learning itself is quickly gaining on methods for still images. This paper seeks to highlight the need for explainability methods designed with video deep learning models, and by association spatio-temporal input in mind, by first illustrating the cutting edge for video deep learning, and then noting the scarcity of research into explanations for these methods.
Discriminating Spatial and Temporal Relevance in Deep Taylor Decompositions for Explainable Activity Recognition
Aug 14, 2019

Current techniques for explainable AI have been applied with some success to image processing. The recent rise of research in video processing has called for similar work n deconstructing and explaining spatio-temporal models. While many techniques are designed for 2D convolutional models, others are inherently applicable to any input domain. One such body of work, deep Taylor decomposition, propagates relevance from the model output distributively onto its input and thus is not restricted to image processing models. However, by exploiting a simple technique that removes motion information, we show that it is not the case that this technique is effective as-is for representing relevance in non-image tasks. We instead propose a discriminative method that produces a na\"ive representation of both the spatial and temporal relevance of a frame as two separate objects. This new discriminative relevance model exposes relevance in the frame attributed to motion, that was previously ambiguous in the original explanation. We observe the effectiveness of this technique on a range of samples from the UCF-101 action recognition dataset, two of which are demonstrated in this paper.
Quantifying Transparency of Machine Learning Systems through Analysis of Contributions
Jul 08, 2019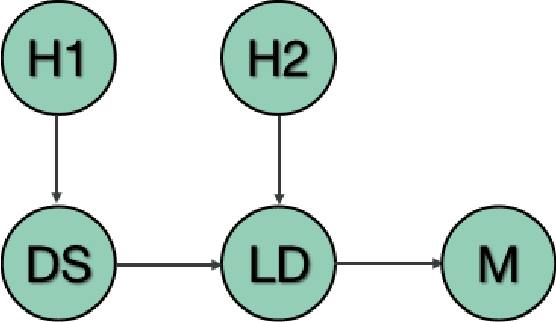

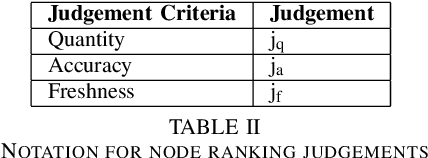
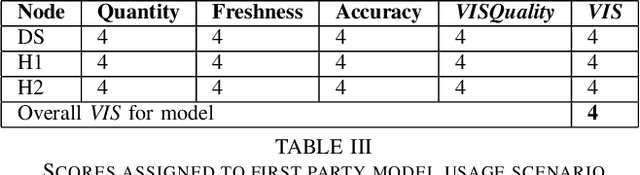
Increased adoption and deployment of machine learning (ML) models into business, healthcare and other organisational processes, will result in a growing disconnect between the engineers and researchers who developed the models and the model's users and other stakeholders, such as regulators or auditors. This disconnect is inevitable, as models begin to be used over a number of years or are shared among third parties through user communities or via commercial marketplaces, and it will become increasingly difficult for users to maintain ongoing insight into the suitability of the parties who created the model, or the data that was used to train it. This could become problematic, particularly where regulations change and once-acceptable standards become outdated, or where data sources are discredited, perhaps judged to be biased or corrupted, either deliberately or unwittingly. In this paper we present a method for arriving at a quantifiable metric capable of ranking the transparency of the process pipelines used to generate ML models and other data assets, such that users, auditors and other stakeholders can gain confidence that they will be able to validate and trust the data sources and human contributors in the systems that they rely on for their business operations. The methodology for calculating the transparency metric, and the type of criteria that could be used to make judgements on the visibility of contributions to systems are explained and illustrated through an example scenario.
Deep Q-Learning for Directed Acyclic Graph Generation
Jun 05, 2019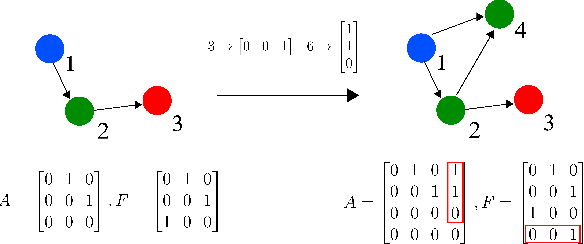
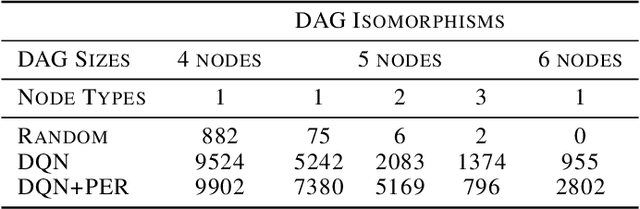
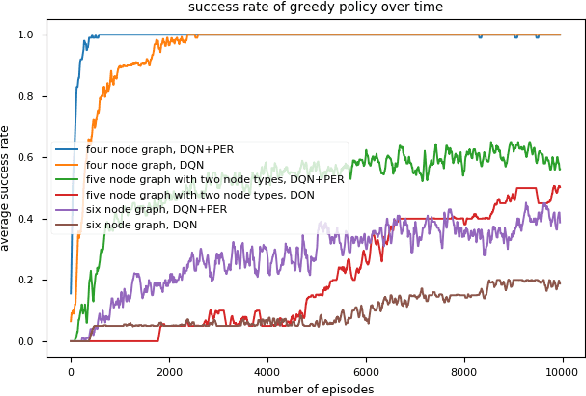
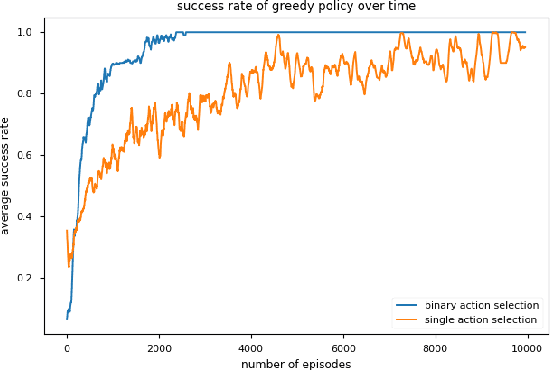
We present a method to generate directed acyclic graphs (DAGs) using deep reinforcement learning, specifically deep Q-learning. Generating graphs with specified structures is an important and challenging task in various application fields, however most current graph generation methods produce graphs with undirected edges. We demonstrate that this method is capable of generating DAGs with topology and node types satisfying specified criteria in highly sparse reward environments.
Hows and Whys of Artificial Intelligence for Public Sector Decisions: Explanation and Evaluation
Oct 19, 2018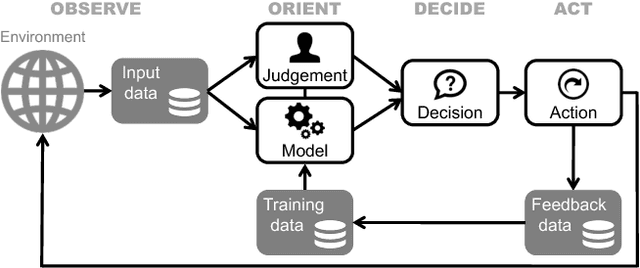
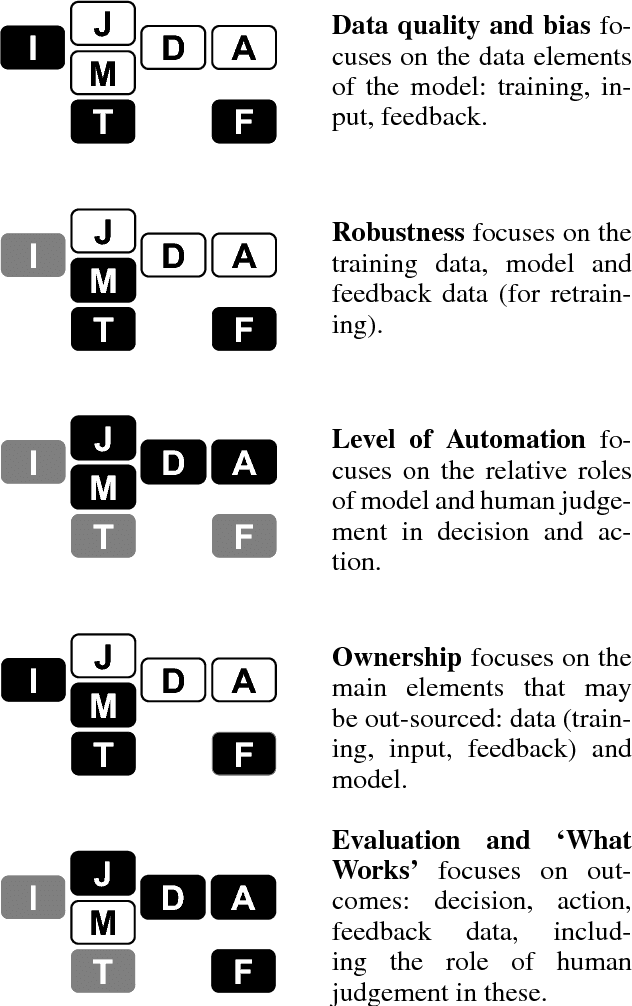
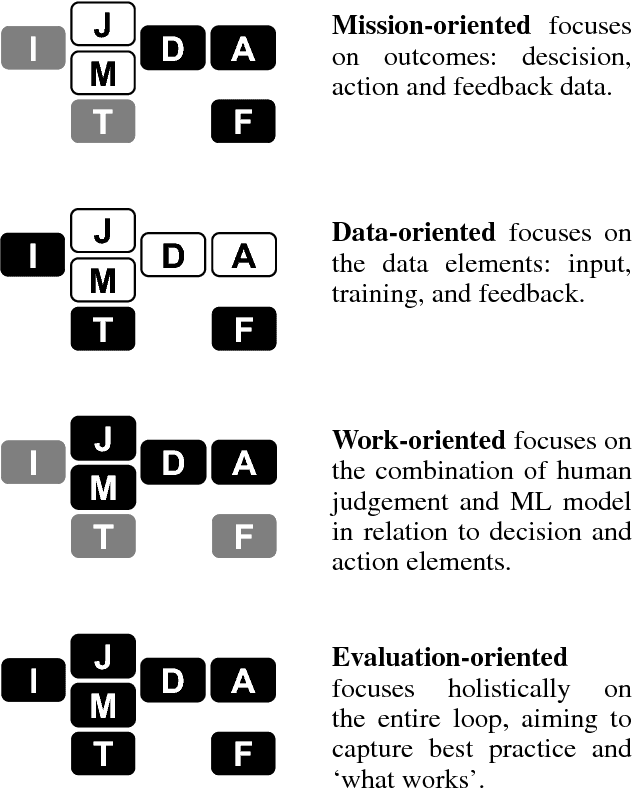
Evaluation has always been a key challenge in the development of artificial intelligence (AI) based software, due to the technical complexity of the software artifact and, often, its embedding in complex sociotechnical processes. Recent advances in machine learning (ML) enabled by deep neural networks has exacerbated the challenge of evaluating such software due to the opaque nature of these ML-based artifacts. A key related issue is the (in)ability of such systems to generate useful explanations of their outputs, and we argue that the explanation and evaluation problems are closely linked. The paper models the elements of a ML-based AI system in the context of public sector decision (PSD) applications involving both artificial and human intelligence, and maps these elements against issues in both evaluation and explanation, showing how the two are related. We consider a number of common PSD application patterns in the light of our model, and identify a set of key issues connected to explanation and evaluation in each case. Finally, we propose multiple strategies to promote wider adoption of AI/ML technologies in PSD, where each is distinguished by a focus on different elements of our model, allowing PSD policy makers to adopt an approach that best fits their context and concerns.
AAAI FSS-18: Artificial Intelligence in Government and Public Sector Proceedings
Oct 14, 2018Proceedings of the AAAI Fall Symposium on Artificial Intelligence in Government and Public Sector, Arlington, Virginia, USA, October 18-20, 2018
Stakeholders in Explainable AI
Sep 29, 2018

There is general consensus that it is important for artificial intelligence (AI) and machine learning systems to be explainable and/or interpretable. However, there is no general consensus over what is meant by 'explainable' and 'interpretable'. In this paper, we argue that this lack of consensus is due to there being several distinct stakeholder communities. We note that, while the concerns of the individual communities are broadly compatible, they are not identical, which gives rise to different intents and requirements for explainability/interpretability. We use the software engineering distinction between validation and verification, and the epistemological distinctions between knowns/unknowns, to tease apart the concerns of the stakeholder communities and highlight the areas where their foci overlap or diverge. It is not the purpose of the authors of this paper to 'take sides' - we count ourselves as members, to varying degrees, of multiple communities - but rather to help disambiguate what stakeholders mean when they ask 'Why?' of an AI.
Defining the Collective Intelligence Supply Chain
Sep 25, 2018Organisations are increasingly open to scrutiny, and need to be able to prove that they operate in a fair and ethical way. Accountability should extend to the production and use of the data and knowledge assets used in AI systems, as it would for any raw material or process used in production of physical goods. This paper considers collective intelligence, comprising data and knowledge generated by crowd-sourced workforces, which can be used as core components of AI systems. A proposal is made for the development of a supply chain model for tracking the creation and use of crowdsourced collective intelligence assets, with a blockchain based decentralised architecture identified as an appropriate means of providing validation, accountability and fairness.