 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Randomization through Style Transfer for Enhanced Domain Generalization
Apr 07, 2026Deep learning models for computer vision often suffer from poor generalization when deployed in real-world settings, especially when trained on synthetic data due to the well-known Sim2Real gap. Despite the growing popularity of style transfer as a data augmentation strategy for domain generalization, the literature contains unresolved contradictions regarding three key design axes: the diversity of the style pool, the role of texture complexity, and the choice of style source. We present a systematic empirical study that isolates and evaluates each of these factors for driving scene understanding, resolving inconsistencies in prior work. Our findings show that (i) expanding the style pool yields larger gains than repeated augmentation with few styles, (ii) texture complexity has no significant effect when the pool is sufficiently large, and (iii) diverse artistic styles outperform domain-aligned alternatives. Guided by these insights, we derive StyleMixDG (Style-Mixing for Domain Generalization), a lightweight, model-agnostic augmentation recipe that requires no architectural modifications or additional losses. Evaluated on the GTAV $\rightarrow$ {BDD100k, Cityscapes, Mapillary Vistas} benchmark, StyleMixDG demonstrates consistent improvements over strong baselines, confirming that the empirically identified design principles translate into practical gains. The code will be released on GitHub.
MOCCA: Multi-Layer One-Class Classification for Anomaly Detection
Dec 09, 2020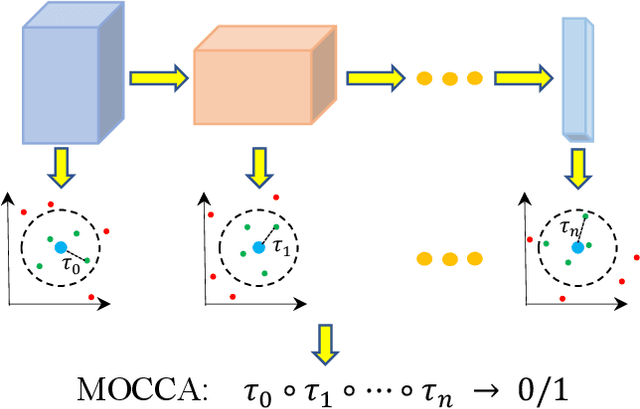
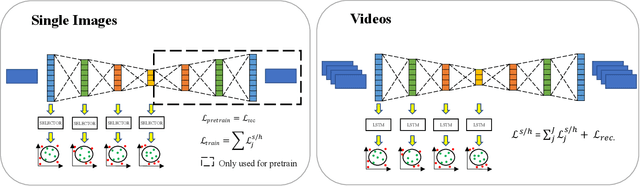
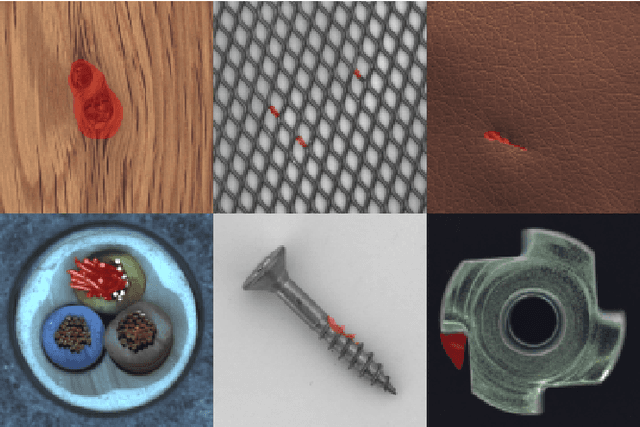

Anomalies are ubiquitous in all scientific fields and can express an unexpected event due to incomplete knowledge about the data distribution or an unknown process that suddenly comes into play and distorts the observations. Due to such events' rarity, it is common to train deep learning models on "normal", i.e. non-anomalous, datasets only, thus letting the neural network to model the distribution beneath the input data. In this context, we propose our deep learning approach to the anomaly detection problem named Multi-LayerOne-Class Classification (MOCCA). We explicitly leverage the piece-wise nature of deep neural networks by exploiting information extracted at different depths to detect abnormal data instances. We show how combining the representations extracted from multiple layers of a model leads to higher discrimination performance than typical approaches proposed in the literature that are based neural networks' final output only. We propose to train the model by minimizing the $L_2$ distance between the input representation and a reference point, the anomaly-free training data centroid, at each considered layer. We conduct extensive experiments on publicly available datasets for anomaly detection, namely CIFAR10, MVTec AD, and ShanghaiTech, considering both the single-image and video-based scenarios. We show that our method reaches superior performances compared to the state-of-the-art approaches available in the literature. Moreover, we provide a model analysis to give insight on how our approach works.