 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards medical AI misalignment: a preliminary study
May 22, 2025Despite their staggering capabilities as assistant tools, often exceeding human performances, Large Language Models (LLMs) are still prone to jailbreak attempts from malevolent users. Although red teaming practices have already identified and helped to address several such jailbreak techniques, one particular sturdy approach involving role-playing (which we named `Goofy Game') seems effective against most of the current LLMs safeguards. This can result in the provision of unsafe content, which, although not harmful per se, might lead to dangerous consequences if delivered in a setting such as the medical domain. In this preliminary and exploratory study, we provide an initial analysis of how, even without technical knowledge of the internal architecture and parameters of generative AI models, a malicious user could construct a role-playing prompt capable of coercing an LLM into producing incorrect (and potentially harmful) clinical suggestions. We aim to illustrate a specific vulnerability scenario, providing insights that can support future advancements in the field.
Integrating Explainable AI in Medical Devices: Technical, Clinical and Regulatory Insights and Recommendations
May 10, 2025There is a growing demand for the use of Artificial Intelligence (AI) and Machine Learning (ML) in healthcare, particularly as clinical decision support systems to assist medical professionals. However, the complexity of many of these models, often referred to as black box models, raises concerns about their safe integration into clinical settings as it is difficult to understand how they arrived at their predictions. This paper discusses insights and recommendations derived from an expert working group convened by the UK Medicine and Healthcare products Regulatory Agency (MHRA). The group consisted of healthcare professionals, regulators, and data scientists, with a primary focus on evaluating the outputs from different AI algorithms in clinical decision-making contexts. Additionally, the group evaluated findings from a pilot study investigating clinicians' behaviour and interaction with AI methods during clinical diagnosis. Incorporating AI methods is crucial for ensuring the safety and trustworthiness of medical AI devices in clinical settings. Adequate training for stakeholders is essential to address potential issues, and further insights and recommendations for safely adopting AI systems in healthcare settings are provided.
On Calibrated Model Uncertainty in Deep Learning
Jun 15, 2022
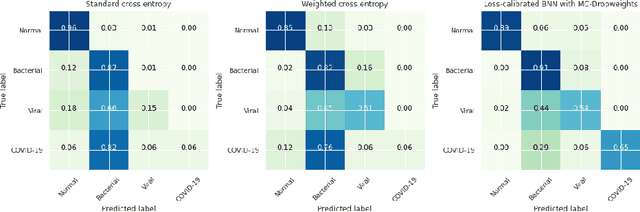
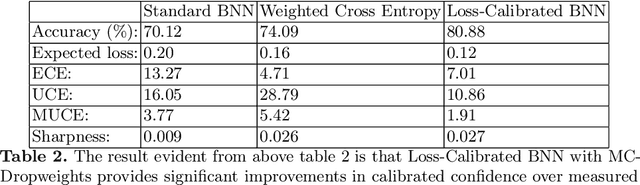
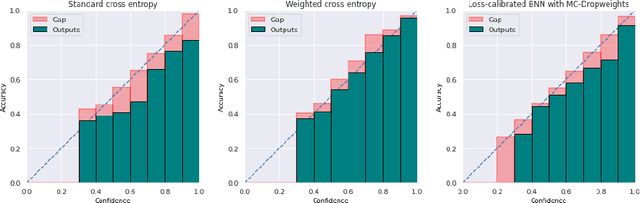
Estimated uncertainty by approximate posteriors in Bayesian neural networks are prone to miscalibration, which leads to overconfident predictions in critical tasks that have a clear asymmetric cost or significant losses. Here, we extend the approximate inference for the loss-calibrated Bayesian framework to dropweights based Bayesian neural networks by maximising expected utility over a model posterior to calibrate uncertainty in deep learning. Furthermore, we show that decisions informed by loss-calibrated uncertainty can improve diagnostic performance to a greater extent than straightforward alternatives. We propose Maximum Uncertainty Calibration Error (MUCE) as a metric to measure calibrated confidence, in addition to its prediction especially for high-risk applications, where the goal is to minimise the worst-case deviation between error and estimated uncertainty. In experiments, we show the correlation between error in prediction and estimated uncertainty by interpreting Wasserstein distance as the accuracy of prediction. We evaluated the effectiveness of our approach to detecting Covid-19 from X-Ray images. Experimental results show that our method reduces miscalibration considerably, without impacting the models accuracy and improves reliability of computer-based diagnostics.
Leveraging Uncertainty in Deep Learning for Pancreatic Adenocarcinoma Grading
Jun 15, 2022
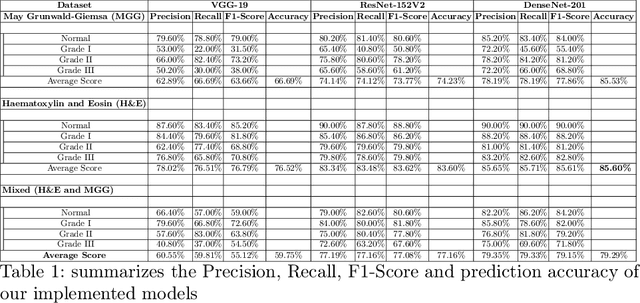
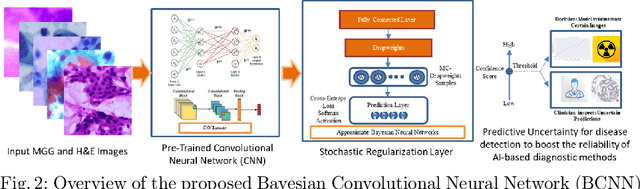
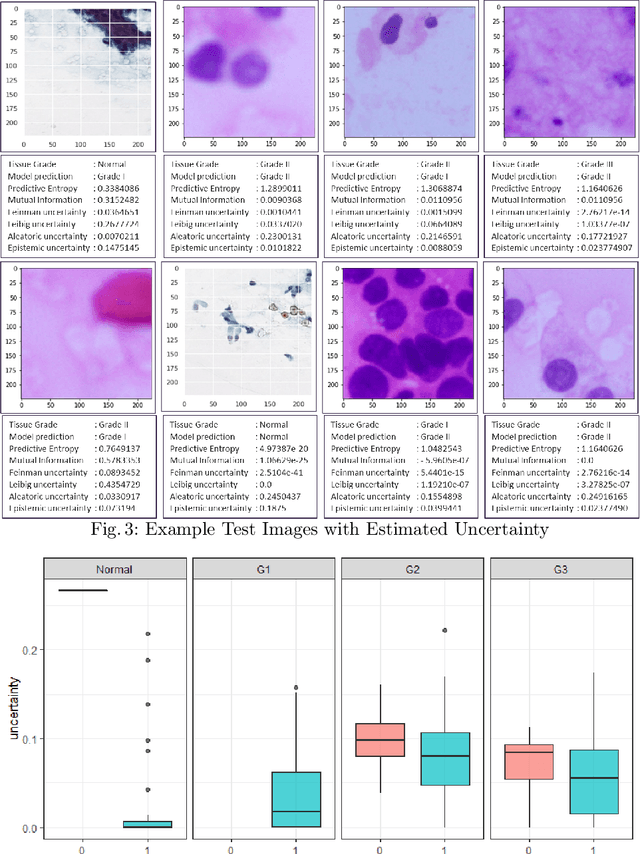
Pancreatic cancers have one of the worst prognoses compared to other cancers, as they are diagnosed when cancer has progressed towards its latter stages. The current manual histological grading for diagnosing pancreatic adenocarcinomas is time-consuming and often results in misdiagnosis. In digital pathology, AI-based cancer grading must be extremely accurate in prediction and uncertainty quantification to improve reliability and explainability and are essential for gaining clinicians trust in the technology. We present Bayesian Convolutional Neural Networks for automated pancreatic cancer grading from MGG and HE stained images to estimate uncertainty in model prediction. We show that the estimated uncertainty correlates with prediction error. Specifically, it is useful in setting the acceptance threshold using a metric that weighs classification accuracy-reject trade-off and misclassification cost controlled by hyperparameters and can be employed in clinical settings.
Uncertainty Estimation in SARS-CoV-2 B-cell Epitope Prediction for Vaccine Development
Mar 20, 2021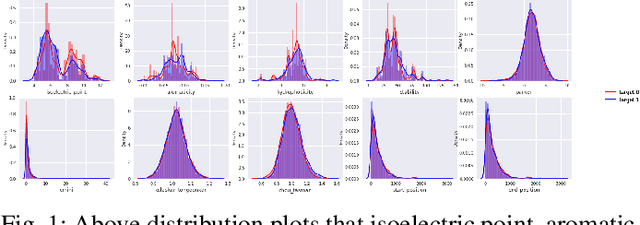
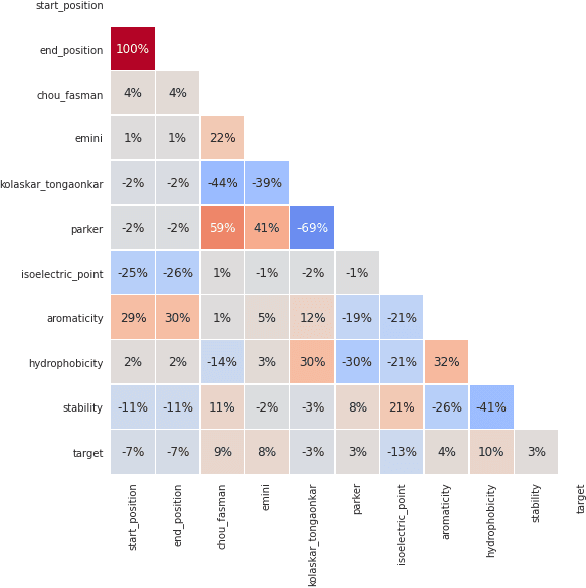

B-cell epitopes play a key role in stimulating B-cells, triggering the primary immune response which results in antibody production as well as the establishment of long-term immunity in the form of memory cells. Consequently, being able to accurately predict appropriate linear B-cell epitope regions would pave the way for the development of new protein-based vaccines. Knowing how much confidence there is in a prediction is also essential for gaining clinicians' trust in the technology. In this article, we propose a calibrated uncertainty estimation in deep learning to approximate variational Bayesian inference using MC-DropWeights to predict epitope regions using the data from the immune epitope database. Having applied this onto SARS-CoV-2, it can more reliably predict B-cell epitopes than standard methods. This will be able to identify safe and effective vaccine candidates against Covid-19.
Estimating Uncertainty and Interpretability in Deep Learning for Coronavirus (COVID-19) Detection
Mar 27, 2020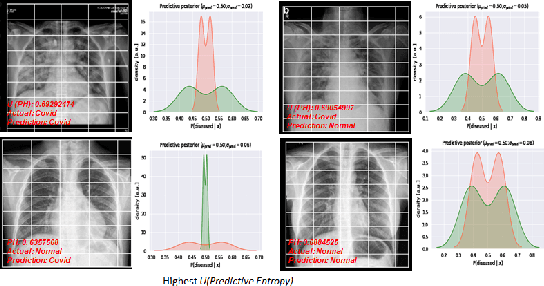
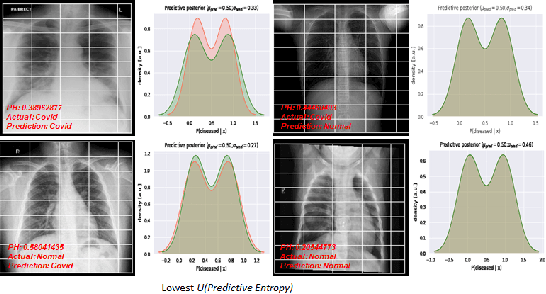

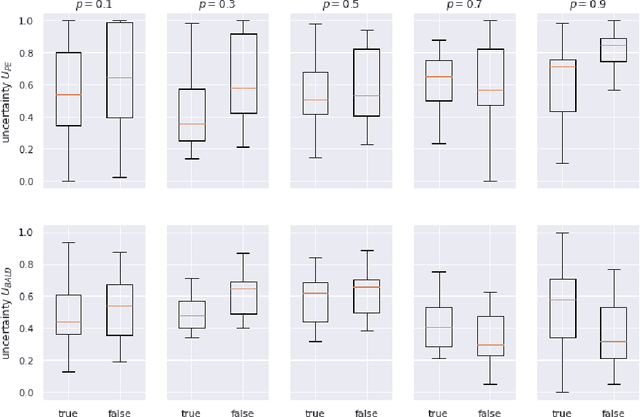
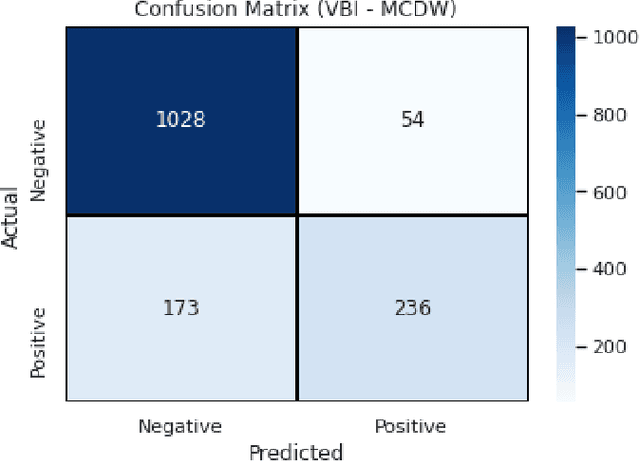
Deep Learning has achieved state of the art performance in medical imaging. However, these methods for disease detection focus exclusively on improving the accuracy of classification or predictions without quantifying uncertainty in a decision. Knowing how much confidence there is in a computer-based medical diagnosis is essential for gaining clinicians trust in the technology and therefore improve treatment. Today, the 2019 Coronavirus (SARS-CoV-2) infections are a major healthcare challenge around the world. Detecting COVID-19 in X-ray images is crucial for diagnosis, assessment and treatment. However, diagnostic uncertainty in the report is a challenging and yet inevitable task for radiologist. In this paper, we investigate how drop-weights based Bayesian Convolutional Neural Networks (BCNN) can estimate uncertainty in Deep Learning solution to improve the diagnostic performance of the human-machine team using publicly available COVID-19 chest X-ray dataset and show that the uncertainty in prediction is highly correlates with accuracy of prediction. We believe that the availability of uncertainty-aware deep learning solution will enable a wider adoption of Artificial Intelligence (AI) in a clinical setting.
The Prevalence of Errors in Machine Learning Experiments
Sep 10, 2019

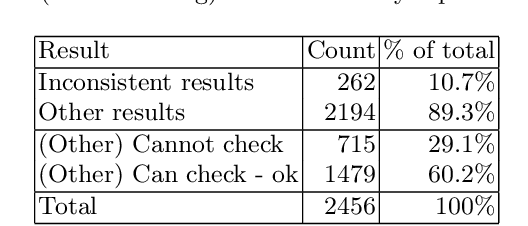
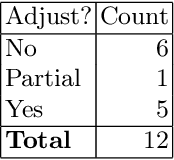
Context: Conducting experiments is central to research machine learning research to benchmark, evaluate and compare learning algorithms. Consequently it is important we conduct reliable, trustworthy experiments. Objective: We investigate the incidence of errors in a sample of machine learning experiments in the domain of software defect prediction. Our focus is simple arithmetical and statistical errors. Method: We analyse 49 papers describing 2456 individual experimental results from a previously undertaken systematic review comparing supervised and unsupervised defect prediction classifiers. We extract the confusion matrices and test for relevant constraints, e.g., the marginal probabilities must sum to one. We also check for multiple statistical significance testing errors. Results: We find that a total of 22 out of 49 papers contain demonstrable errors. Of these 7 were statistical and 16 related to confusion matrix inconsistency (one paper contained both classes of error). Conclusions: Whilst some errors may be of a relatively trivial nature, e.g., transcription errors their presence does not engender confidence. We strongly urge researchers to follow open science principles so errors can be more easily be detected and corrected, thus as a community reduce this worryingly high error rate with our computational experiments.