 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefinite Non-Ancestral Relations and Structure Learning
May 20, 2021
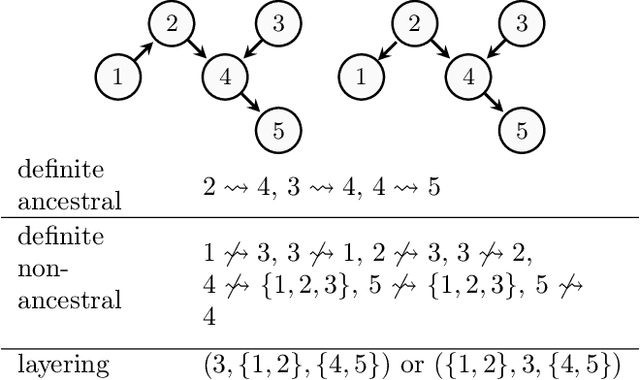
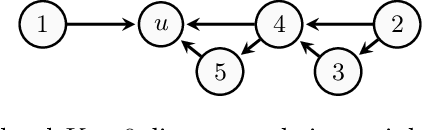
In causal graphical models based on directed acyclic graphs (DAGs), directed paths represent causal pathways between the corresponding variables. The variable at the beginning of such a path is referred to as an ancestor of the variable at the end of the path. Ancestral relations between variables play an important role in causal modeling. In existing literature on structure learning, these relations are usually deduced from learned structures and used for orienting edges or formulating constraints of the space of possible DAGs. However, they are usually not posed as immediate target of inference. In this work we investigate the graphical characterization of ancestral relations via CPDAGs and d-separation relations. We propose a framework that can learn definite non-ancestral relations without first learning the skeleton. This frame-work yields structural information that can be used in both score- and constraint-based algorithms to learn causal DAGs more efficiently.
Granger Causality: A Review and Recent Advances
May 07, 2021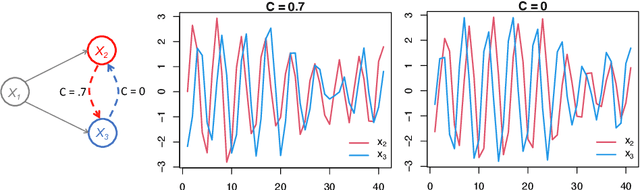
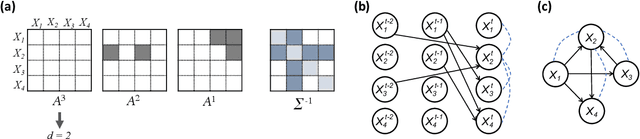
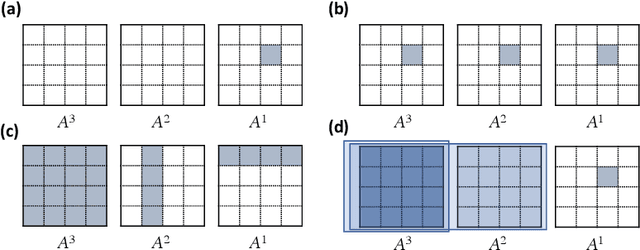
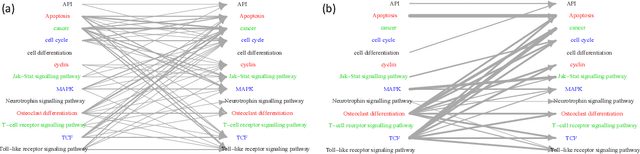
Introduced more than a half century ago, Granger causality has become a popular tool for analyzing time series data in many application domains, from economics and finance to genomics and neuroscience. Despite this popularity, the validity of this notion for inferring causal relationships among time series has remained the topic of continuous debate. Moreover, while the original definition was general, limitations in computational tools have primarily limited the applications of Granger causality to simple bivariate vector auto-regressive processes or pairwise relationships among a set of variables. Starting with a review of early developments and debates, this paper discusses recent advances that address various shortcomings of the earlier approaches, from models for high-dimensional time series to more recent developments that account for nonlinear and non-Gaussian observations and allow for sub-sampled and mixed frequency time series.
On the Optimality of Nuclear-norm-based Matrix Completion for Problems with Smooth Non-linear Structure
May 05, 2021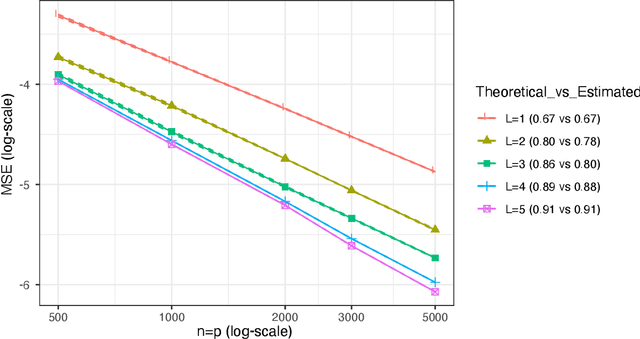
Originally developed for imputing missing entries in low rank, or approximately low rank matrices, matrix completion has proven widely effective in many problems where there is no reason to assume low-dimensional linear structure in the underlying matrix, as would be imposed by rank constraints. In this manuscript, we build some theoretical intuition for this behavior. We consider matrices which are not necessarily low-rank, but lie in a low-dimensional non-linear manifold. We show that nuclear-norm penalization is still effective for recovering these matrices when observations are missing completely at random. In particular, we give upper bounds on the rate of convergence as a function of the number of rows, columns, and observed entries in the matrix, as well as the smoothness and dimension of the non-linear embedding. We additionally give a minimax lower bound: This lower bound agrees with our upper bound (up to a logarithmic factor), which shows that nuclear-norm penalization is (up to log terms) minimax rate optimal for these problems.
Generalized Score Matching for General Domains
Sep 24, 2020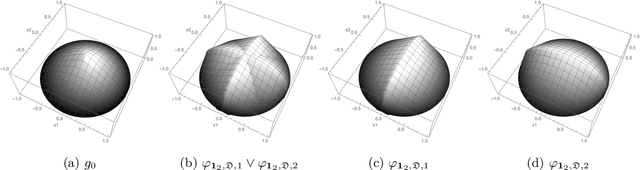
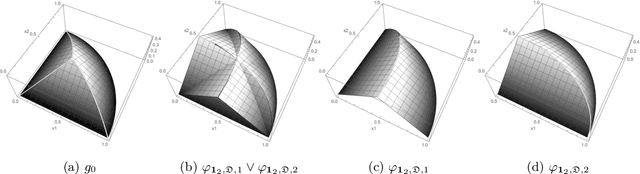
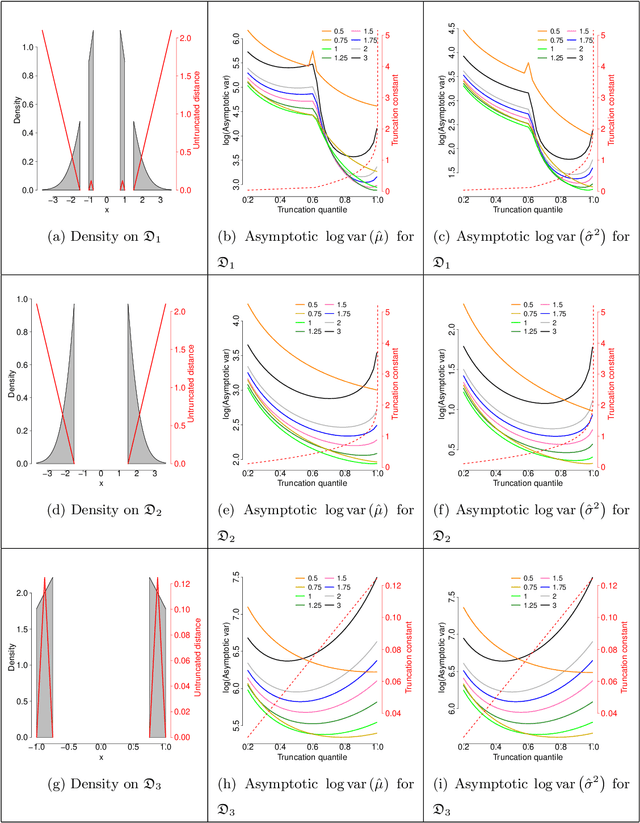
Estimation of density functions supported on general domains arises when the data is naturally restricted to a proper subset of the real space. This problem is complicated by typically intractable normalizing constants. Score matching provides a powerful tool for estimating densities with such intractable normalizing constants, but as originally proposed is limited to densities on $\mathbb{R}^m$ and $\mathbb{R}_+^m$. In this paper, we offer a natural generalization of score matching that accommodates densities supported on a very general class of domains. We apply the framework to truncated graphical and pairwise interaction models, and provide theoretical guarantees for the resulting estimators. We also generalize a recently proposed method from bounded to unbounded domains, and empirically demonstrate the advantages of our method.
Statistical Inference for Networks of High-Dimensional Point Processes
Jul 15, 2020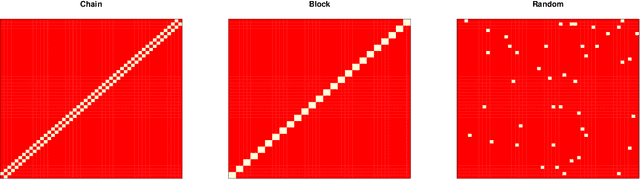
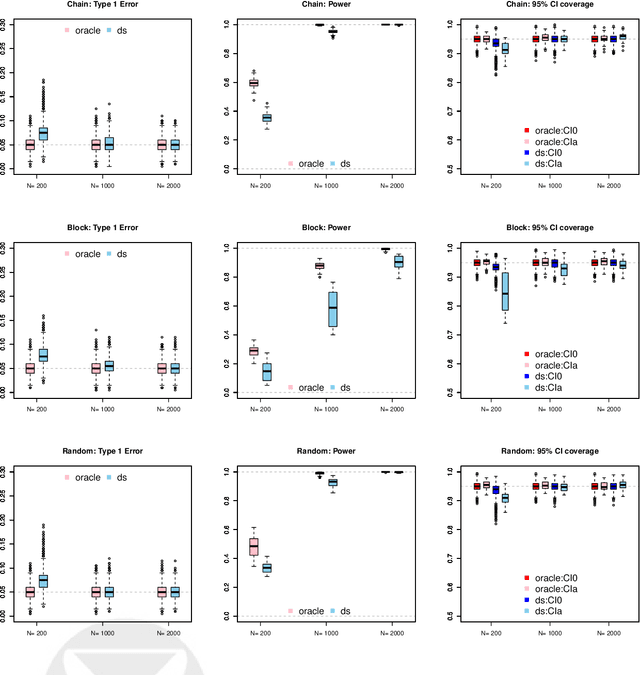
Fueled in part by recent applications in neuroscience, the multivariate Hawkes process has become a popular tool for modeling the network of interactions among high-dimensional point process data. While evaluating the uncertainty of the network estimates is critical in scientific applications, existing methodological and theoretical work has primarily addressed estimation. To bridge this gap, this paper develops a new statistical inference procedure for high-dimensional Hawkes processes. The key ingredient for this inference procedure is a new concentration inequality on the first- and second-order statistics for integrated stochastic processes, which summarize the entire history of the process. Combining recent results on martingale central limit theory with the new concentration inequality, we then characterize the convergence rate of the test statistics. We illustrate finite sample validity of our inferential tools via extensive simulations and demonstrate their utility by applying them to a neuron spike train data set.
Consistent Second-Order Conic Integer Programming for Learning Bayesian Networks
Jun 13, 2020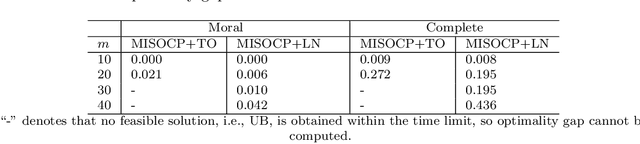
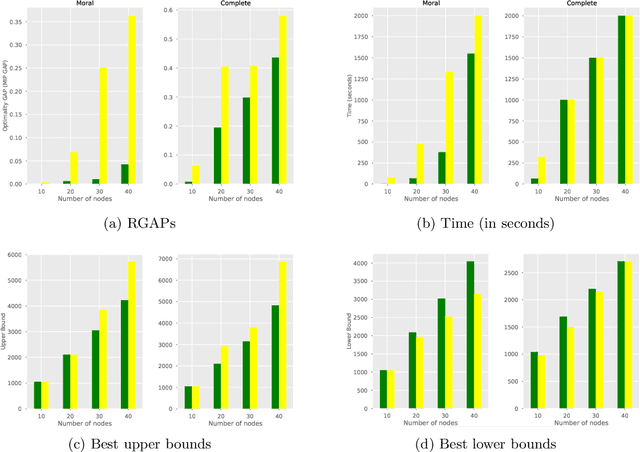
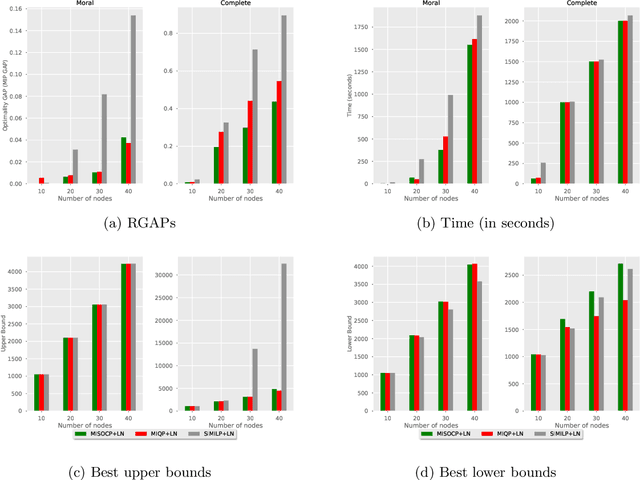
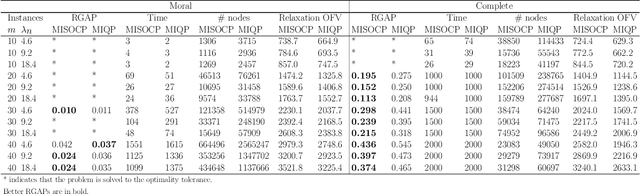
Bayesian Networks (BNs) represent conditional probability relations among a set of random variables (nodes) in the form of a directed acyclic graph (DAG), and have found diverse applications in knowledge discovery. We study the problem of learning the sparse DAG structure of a BN from continuous observational data. The central problem can be modeled as a mixed-integer program with an objective function composed of a convex quadratic loss function and a regularization penalty subject to linear constraints. The optimal solution to this mathematical program is known to have desirable statistical properties under certain conditions. However, the state-of-the-art optimization solvers are not able to obtain provably optimal solutions to the existing mathematical formulations for medium-size problems within reasonable computational times. To address this difficulty, we tackle the problem from both computational and statistical perspectives. On the one hand, we propose a concrete early stopping criterion to terminate the branch-and-bound process in order to obtain a near-optimal solution to the mixed-integer program, and establish the consistency of this approximate solution. On the other hand, we improve the existing formulations by replacing the linear "big-$M$" constraints that represent the relationship between the continuous and binary indicator variables with second-order conic constraints. Our numerical results demonstrate the effectiveness of the proposed approaches.
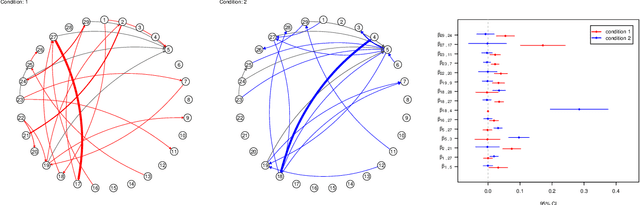
Differential Network Analysis: A Statistical Perspective
Mar 09, 2020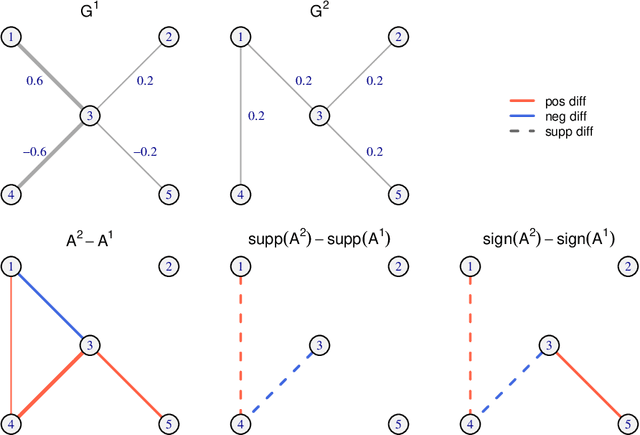
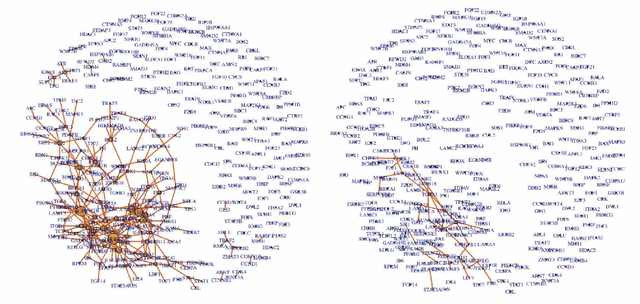
Networks effectively capture interactions among components of complex systems, and have thus become a mainstay in many scientific disciplines. Growing evidence, especially from biology, suggest that networks undergo changes over time, and in response to external stimuli. In biology and medicine, these changes have been found to be predictive of complex diseases. They have also been used to gain insight into mechanisms of disease initiation and progression. Primarily motivated by biological applications, this article provides a review of recent statistical machine learning methods for inferring networks and identifying changes in their structures.
Statistical significance in high-dimensional linear mixed models
Dec 16, 2019
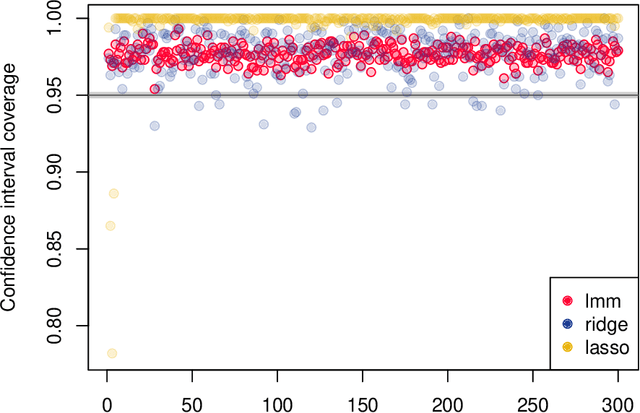
This paper concerns the development of an inferential framework for high-dimensional linear mixed effect models. These are suitable models, for instance, when we have $n$ repeated measurements for $M$ subjects. We consider a scenario where the number of fixed effects $p$ is large (and may be larger than $M$), but the number of random effects $q$ is small. Our framework is inspired by a recent line of work that proposes de-biasing penalized estimators to perform inference for high-dimensional linear models with fixed effects only. In particular, we demonstrate how to correct a `naive' ridge estimator in extension of work by B\"uhlmann (2013) to build asymptotically valid confidence intervals for mixed effect models. We validate our theoretical results with numerical experiments, in which we show our method outperforms those that fail to account for correlation induced by the random effects. For a practical demonstration we consider a riboflavin production dataset that exhibits group structure, and show that conclusions drawn using our method are consistent with those obtained on a similar dataset without group structure.
Integer Programming for Learning Directed Acyclic Graphs from Continuous Data
Apr 23, 2019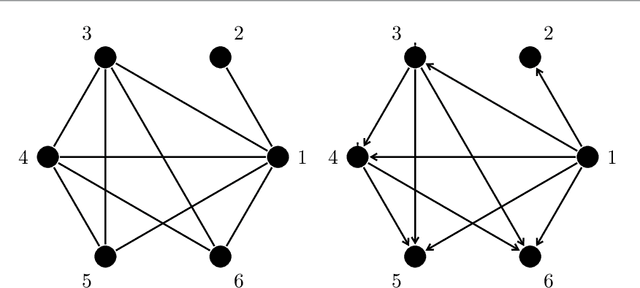

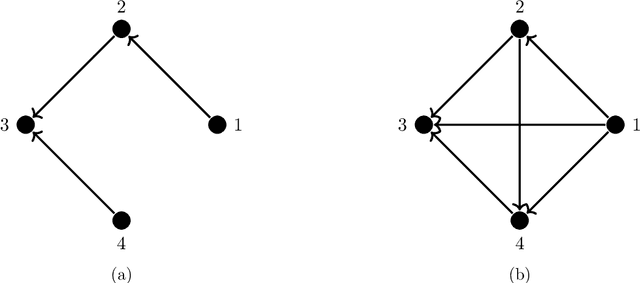
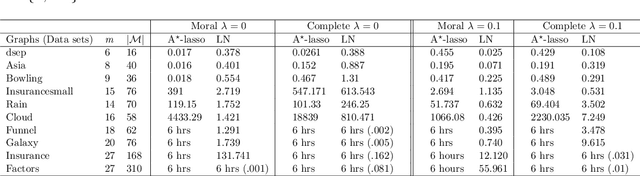
Learning directed acyclic graphs (DAGs) from data is a challenging task both in theory and in practice, because the number of possible DAGs scales superexponentially with the number of nodes. In this paper, we study the problem of learning an optimal DAG from continuous observational data. We cast this problem in the form of a mathematical programming model which can naturally incorporate a super-structure in order to reduce the set of possible candidate DAGs. We use the penalized negative log-likelihood score function with both $\ell_0$ and $\ell_1$ regularizations and propose a new mixed-integer quadratic optimization (MIQO) model, referred to as a layered network (LN) formulation. The LN formulation is a compact model, which enjoys as tight an optimal continuous relaxation value as the stronger but larger formulations under a mild condition. Computational results indicate that the proposed formulation outperforms existing mathematical formulations and scales better than available algorithms that can solve the same problem with only $\ell_1$ regularization. In particular, the LN formulation clearly outperforms existing methods in terms of computational time needed to find an optimal DAG in the presence of a sparse super-structure.
Generalized Sparse Additive Models
Mar 11, 2019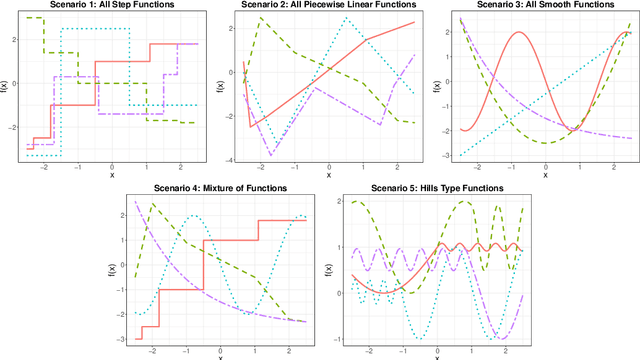
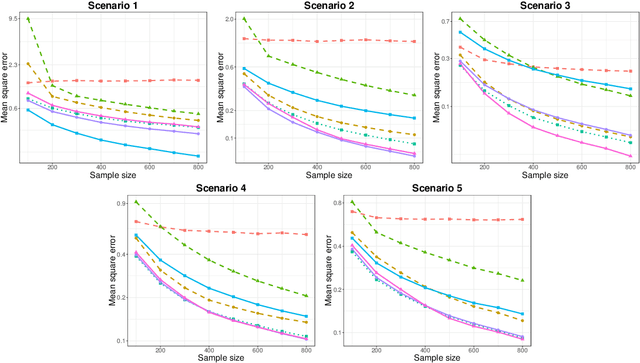
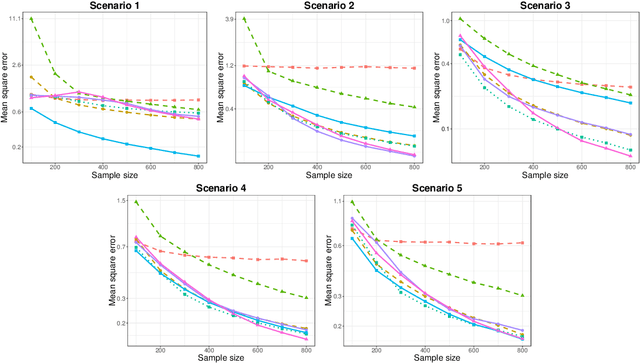
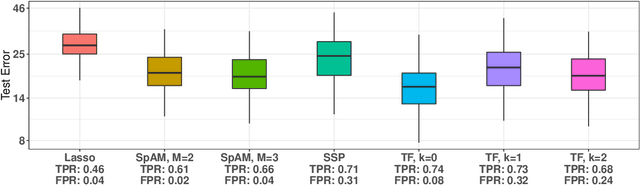
We present a unified framework for estimation and analysis of generalized additive models in high dimensions. The framework defines a large class of penalized regression estimators, encompassing many existing methods. An efficient computational algorithm for this class is presented that easily scales to thousands of observations and features. We prove minimax optimal convergence bounds for this class under a weak compatibility condition. In addition, we characterize the rate of convergence when this compatibility condition is not met. Finally, we also show that the optimal penalty parameters for structure and sparsity penalties in our framework are linked, allowing cross-validation to be conducted over only a single tuning parameter. We complement our theoretical results with empirical studies comparing some existing methods within this framework.