 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Reduced Stochastic Learning by Networked Agents under Random Reshuffling
May 29, 2018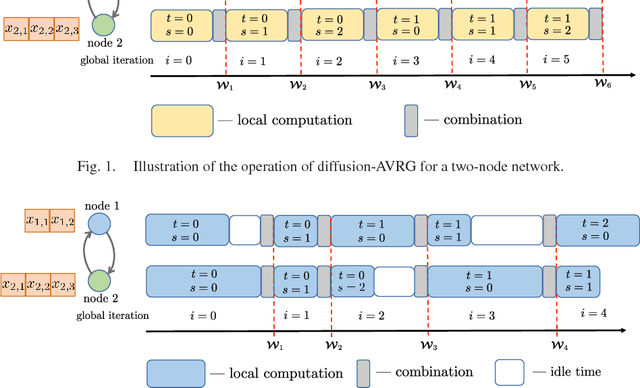

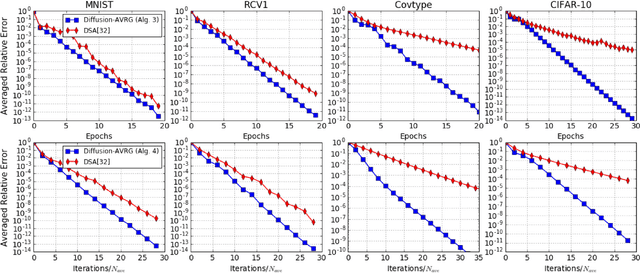
A new amortized variance-reduced gradient (AVRG) algorithm was developed in \cite{ying2017convergence}, which has constant storage requirement in comparison to SAGA and balanced gradient computations in comparison to SVRG. One key advantage of the AVRG strategy is its amenability to decentralized implementations. In this work, we show how AVRG can be extended to the network case where multiple learning agents are assumed to be connected by a graph topology. In this scenario, each agent observes data that is spatially distributed and all agents are only allowed to communicate with direct neighbors. Moreover, the amount of data observed by the individual agents may differ drastically. For such situations, the balanced gradient computation property of AVRG becomes a real advantage in reducing idle time caused by unbalanced local data storage requirements, which is characteristic of other reduced-variance gradient algorithms. The resulting diffusion-AVRG algorithm is shown to have linear convergence to the exact solution, and is much more memory efficient than other alternative algorithms. In addition, we propose a mini-batch strategy to balance the communication and computation efficiency for diffusion-AVRG. When a proper batch size is employed, it is observed in simulations that diffusion-AVRG is more computationally efficient than exact diffusion or EXTRA while maintaining almost the same communication efficiency.
Learning Under Distributed Features
May 29, 2018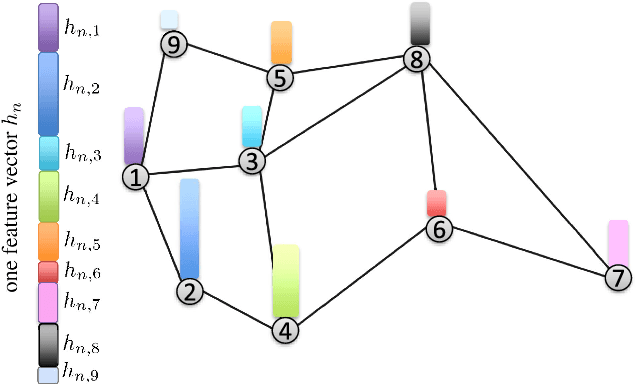
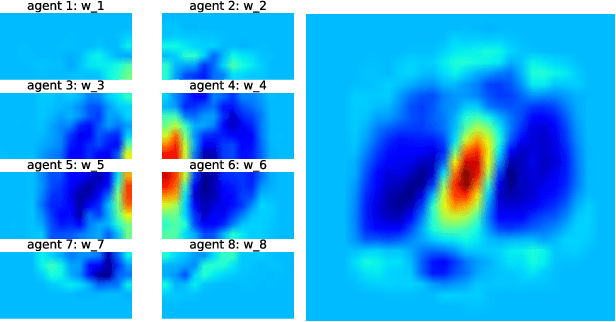
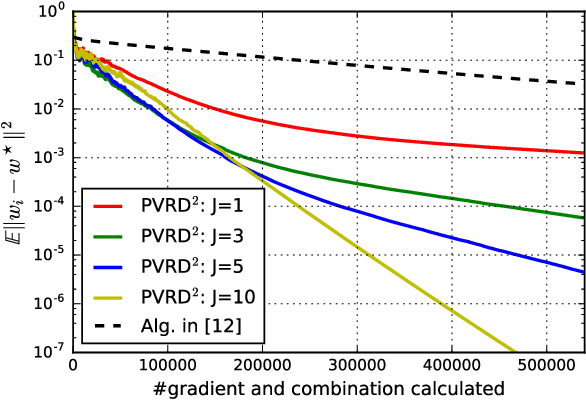
This work studies the problem of learning under both large data and large feature space scenarios. The feature information is assumed to be spread across agents in a network, where each agent observes some of the features. Through local cooperation, the agents are supposed to interact with each other to solve the inference problem and converge towards the global minimizer of the empirical risk. We study this problem exclusively in the primal domain, and propose new and effective distributed solutions with guaranteed convergence to the minimizer. This is achieved by combining a dynamic diffusion construction, a pipeline strategy, and variance-reduced techniques. Simulation results illustrate the conclusions.
Variance-Reduced Stochastic Learning under Random Reshuffling
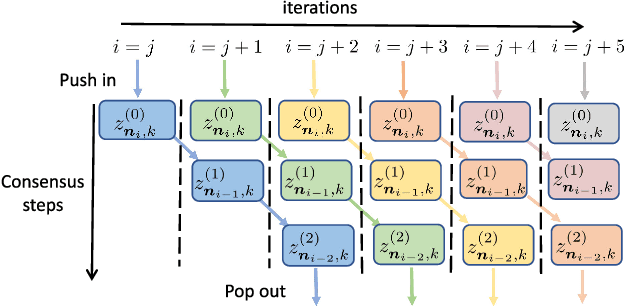
Feb 16, 2018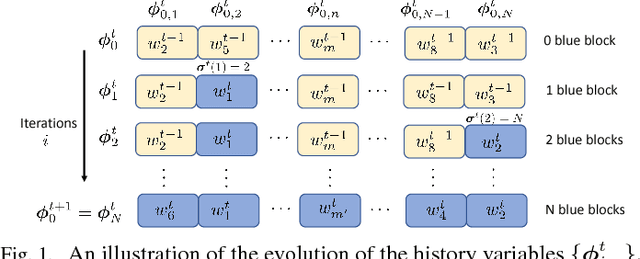
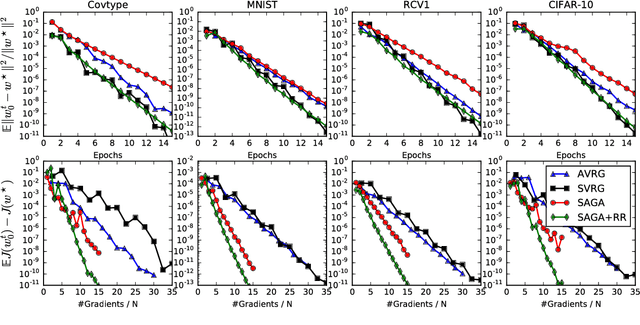

Several useful variance-reduced stochastic gradient algorithms, such as SVRG, SAGA, Finito, and SAG, have been proposed to minimize empirical risks with linear convergence properties to the exact minimizer. The existing convergence results assume uniform data sampling with replacement. However, it has been observed in related works that random reshuffling can deliver superior performance over uniform sampling and, yet, no formal proofs or guarantees of exact convergence exist for variance-reduced algorithms under random reshuffling. This paper makes two contributions. First, it resolves this open issue and provides the first theoretical guarantee of linear convergence under random reshuffling for SAGA; the argument is also adaptable to other variance-reduced algorithms. Second, under random reshuffling, the paper proposes a new amortized variance-reduced gradient (AVRG) algorithm with constant storage requirements compared to SAGA and with balanced gradient computations compared to SVRG. AVRG is also shown analytically to converge linearly.
Asynchronous adaptive networks
Dec 12, 2017
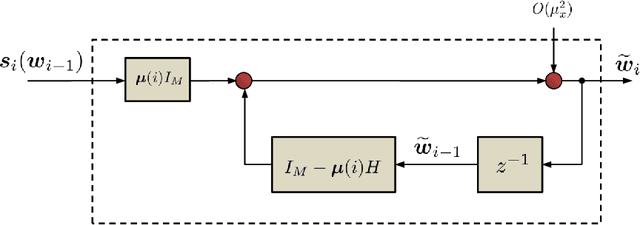
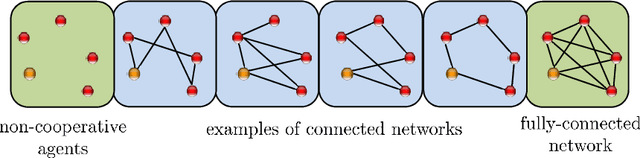
In a recent article [1] we surveyed advances related to adaptation, learning, and optimization over synchronous networks. Various distributed strategies were discussed that enable a collection of networked agents to interact locally in response to streaming data and to continually learn and adapt to track drifts in the data and models. Under reasonable technical conditions on the data, the adaptive networks were shown to be mean-square stable in the slow adaptation regime, and their mean-square-error performance and convergence rate were characterized in terms of the network topology and data statistical moments [2]. Classical results for single-agent adaptation and learning were recovered as special cases. Following the works [3]-[5], this chapter complements the exposition from [1] and extends the results to asynchronous networks. The operation of this class of networks can be subject to various sources of uncertainties that influence their dynamic behavior, including randomly changing topologies, random link failures, random data arrival times, and agents turning on and off randomly. In an asynchronous environment, agents may stop updating their solutions or may stop sending or receiving information in a random manner and without coordination with other agents. The presentation will reveal that the mean-square-error performance of asynchronous networks remains largely unaltered compared to synchronous networks. The results justify the remarkable resilience of cooperative networks in the face of random events.
Performance Limits of Stochastic Sub-Gradient Learning, Part I: Single Agent Case
Apr 21, 2017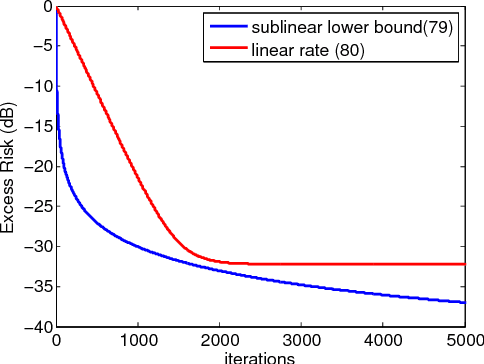
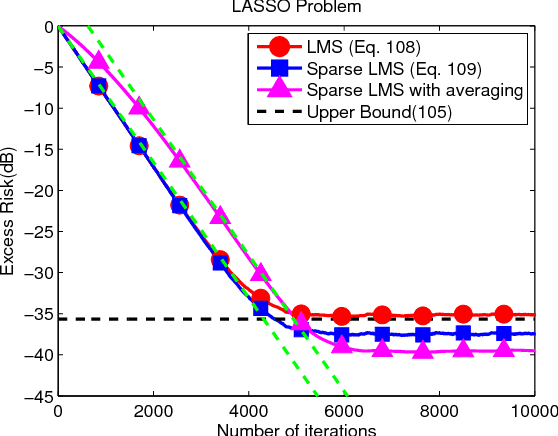
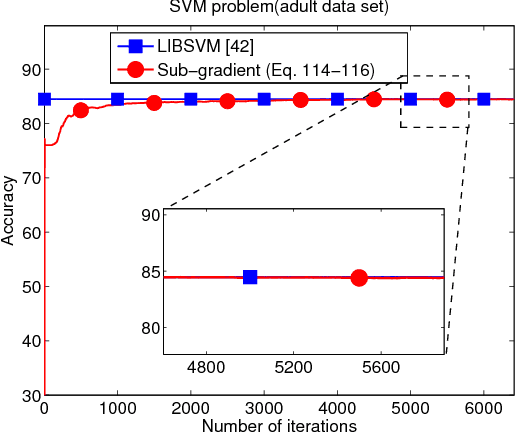
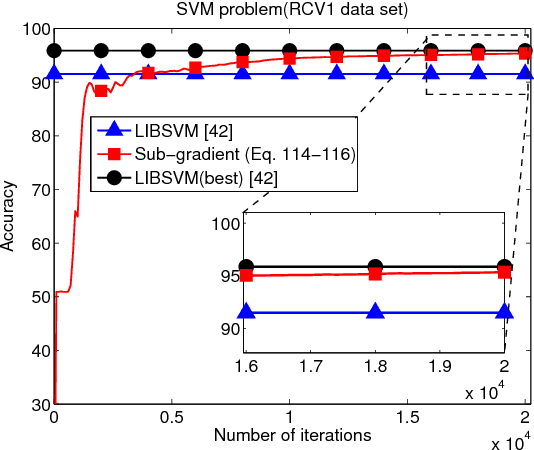
In this work and the supporting Part II, we examine the performance of stochastic sub-gradient learning strategies under weaker conditions than usually considered in the literature. The new conditions are shown to be automatically satisfied by several important cases of interest including SVM, LASSO, and Total-Variation denoising formulations. In comparison, these problems do not satisfy the traditional assumptions used in prior analyses and, therefore, conclusions derived from these earlier treatments are not directly applicable to these problems. The results in this article establish that stochastic sub-gradient strategies can attain linear convergence rates, as opposed to sub-linear rates, to the steady-state regime. A realizable exponential-weighting procedure is employed to smooth the intermediate iterates and guarantee useful performance bounds in terms of convergence rate and excessive risk performance. Part I of this work focuses on single-agent scenarios, which are common in stand-alone learning applications, while Part II extends the analysis to networked learners. The theoretical conclusions are illustrated by several examples and simulations, including comparisons with the FISTA procedure.
Performance Limits of Stochastic Sub-Gradient Learning, Part II: Multi-Agent Case
Apr 20, 2017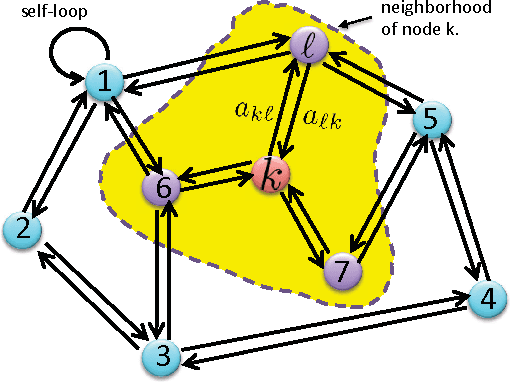
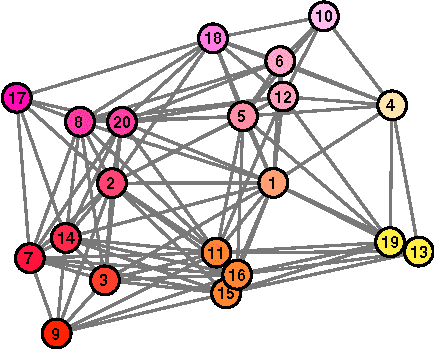
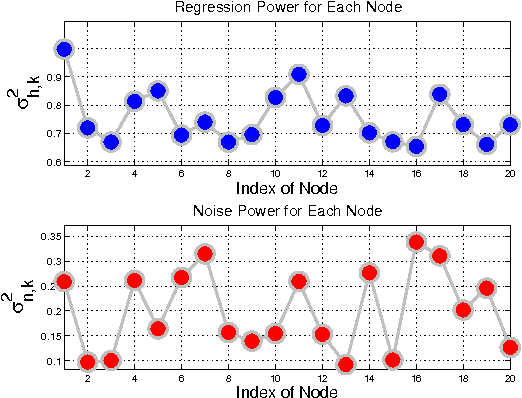
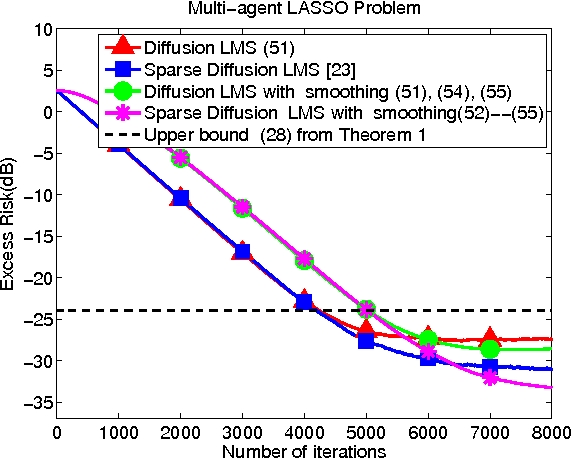
The analysis in Part I revealed interesting properties for subgradient learning algorithms in the context of stochastic optimization when gradient noise is present. These algorithms are used when the risk functions are non-smooth and involve non-differentiable components. They have been long recognized as being slow converging methods. However, it was revealed in Part I that the rate of convergence becomes linear for stochastic optimization problems, with the error iterate converging at an exponential rate $\alpha^i$ to within an $O(\mu)-$neighborhood of the optimizer, for some $\alpha \in (0,1)$ and small step-size $\mu$. The conclusion was established under weaker assumptions than the prior literature and, moreover, several important problems (such as LASSO, SVM, and Total Variation) were shown to satisfy these weaker assumptions automatically (but not the previously used conditions from the literature). These results revealed that sub-gradient learning methods have more favorable behavior than originally thought when used to enable continuous adaptation and learning. The results of Part I were exclusive to single-agent adaptation. The purpose of the current Part II is to examine the implications of these discoveries when a collection of networked agents employs subgradient learning as their cooperative mechanism. The analysis will show that, despite the coupled dynamics that arises in a networked scenario, the agents are still able to attain linear convergence in the stochastic case; they are also able to reach agreement within $O(\mu)$ of the optimizer.
Multitask diffusion adaptation over networks with common latent representations
Feb 13, 2017
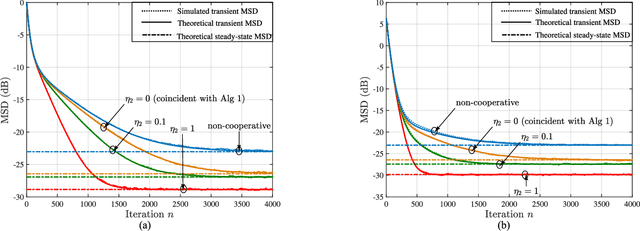
Online learning with streaming data in a distributed and collaborative manner can be useful in a wide range of applications. This topic has been receiving considerable attention in recent years with emphasis on both single-task and multitask scenarios. In single-task adaptation, agents cooperate to track an objective of common interest, while in multitask adaptation agents track multiple objectives simultaneously. Regularization is one useful technique to promote and exploit similarity among tasks in the latter scenario. This work examines an alternative way to model relations among tasks by assuming that they all share a common latent feature representation. As a result, a new multitask learning formulation is presented and algorithms are developed for its solution in a distributed online manner. We present a unified framework to analyze the mean-square-error performance of the adaptive strategies, and conduct simulations to illustrate the theoretical findings and potential applications.
Decentralized Clustering and Linking by Networked Agents
Oct 28, 2016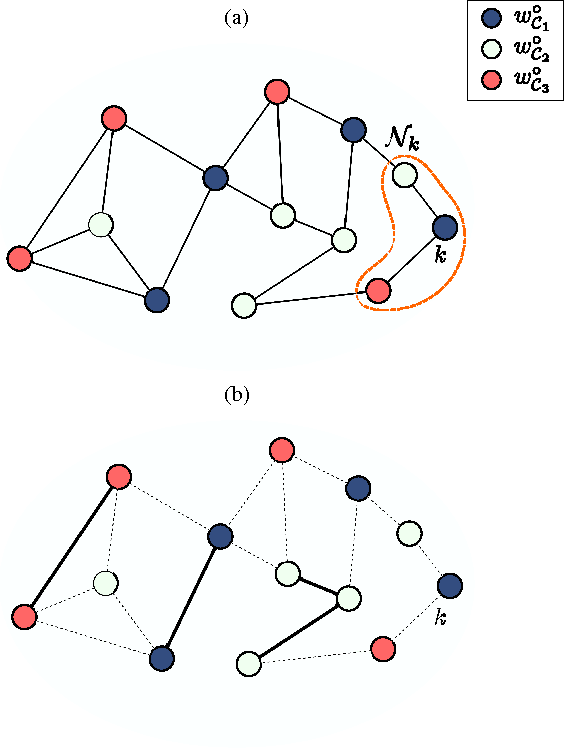
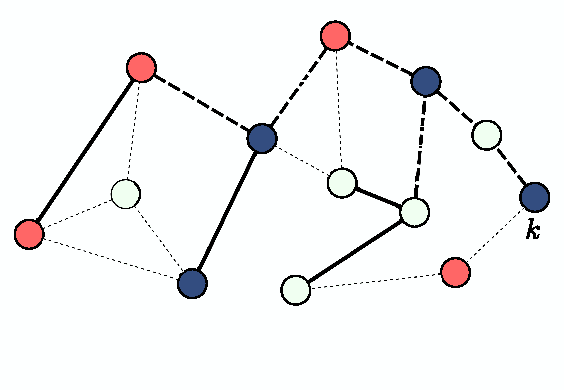
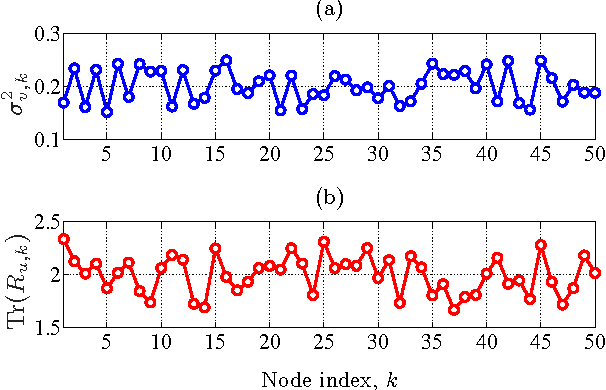
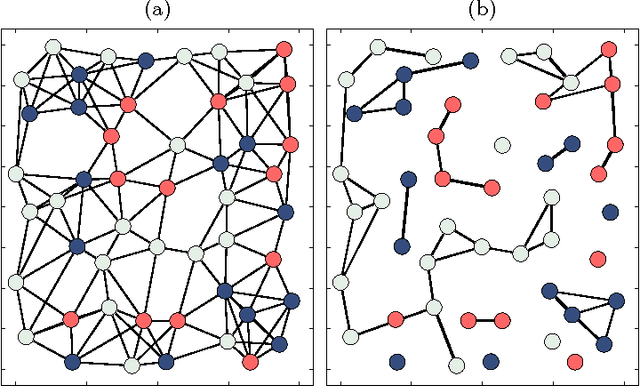
We consider the problem of decentralized clustering and estimation over multi-task networks, where agents infer and track different models of interest. The agents do not know beforehand which model is generating their own data. They also do not know which agents in their neighborhood belong to the same cluster. We propose a decentralized clustering algorithm aimed at identifying and forming clusters of agents of similar objectives, and at guiding cooperation to enhance the inference performance. One key feature of the proposed technique is the integration of the learning and clustering tasks into a single strategy. We analyze the performance of the procedure and show that the error probabilities of types I and II decay exponentially to zero with the step-size parameter. While links between agents following different objectives are ignored in the clustering process, we nevertheless show how to exploit these links to relay critical information across the network for enhanced performance. Simulation results illustrate the performance of the proposed method in comparison to other useful techniques.
On the Influence of Momentum Acceleration on Online Learning
Oct 12, 2016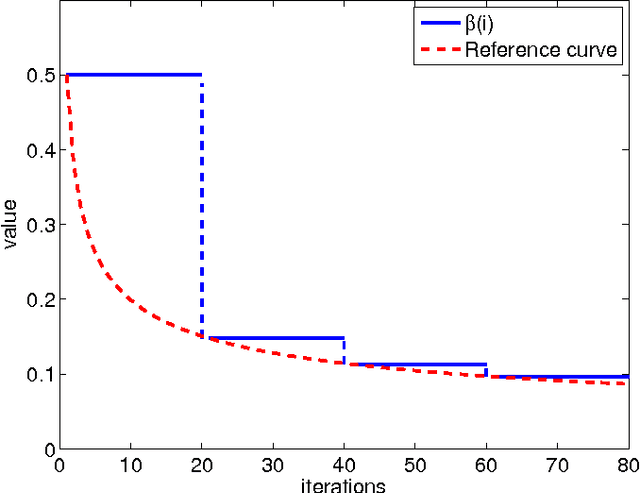
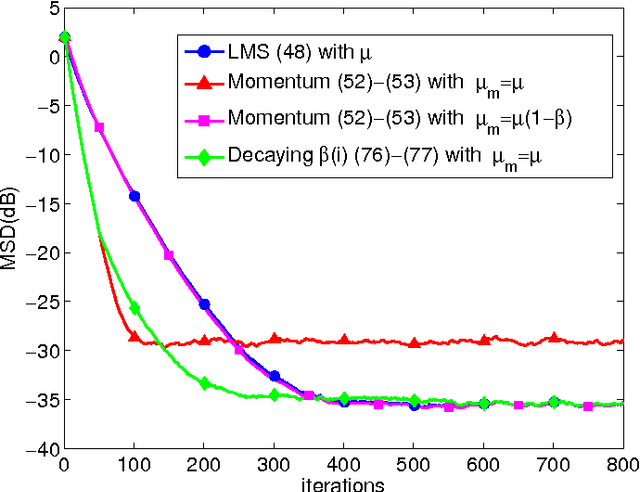
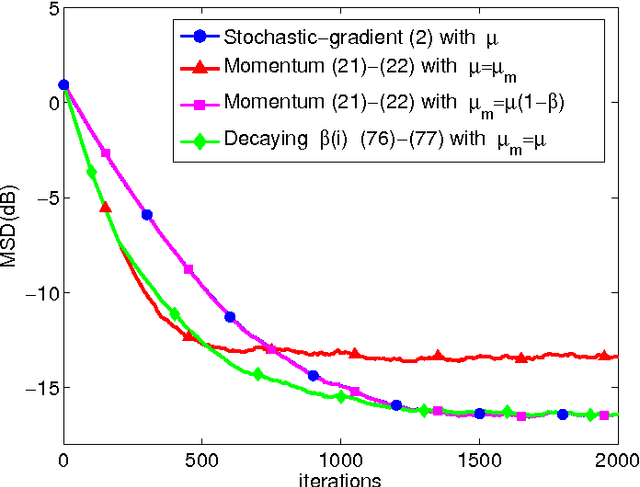
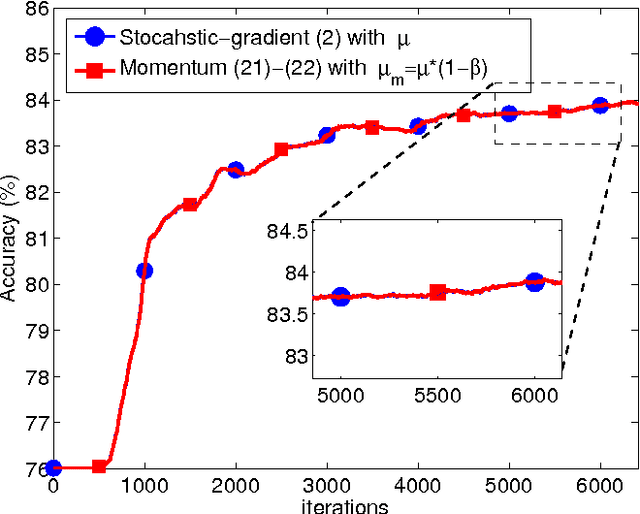
The article examines in some detail the convergence rate and mean-square-error performance of momentum stochastic gradient methods in the constant step-size and slow adaptation regime. The results establish that momentum methods are equivalent to the standard stochastic gradient method with a re-scaled (larger) step-size value. The size of the re-scaling is determined by the value of the momentum parameter. The equivalence result is established for all time instants and not only in steady-state. The analysis is carried out for general strongly convex and smooth risk functions, and is not limited to quadratic risks. One notable conclusion is that the well-known bene ts of momentum constructions for deterministic optimization problems do not necessarily carry over to the adaptive online setting when small constant step-sizes are used to enable continuous adaptation and learn- ing in the presence of persistent gradient noise. From simulations, the equivalence between momentum and standard stochastic gradient methods is also observed for non-differentiable and non-convex problems.
Online Dual Coordinate Ascent Learning
Feb 24, 2016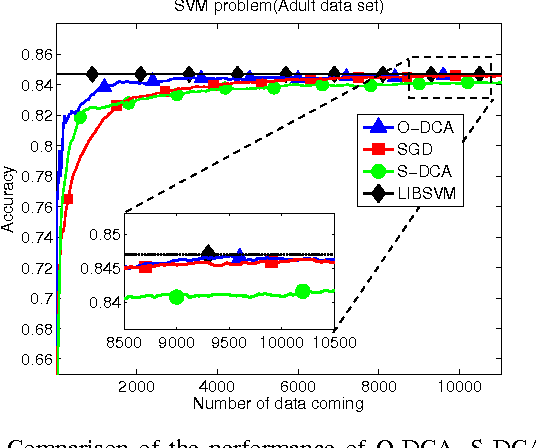
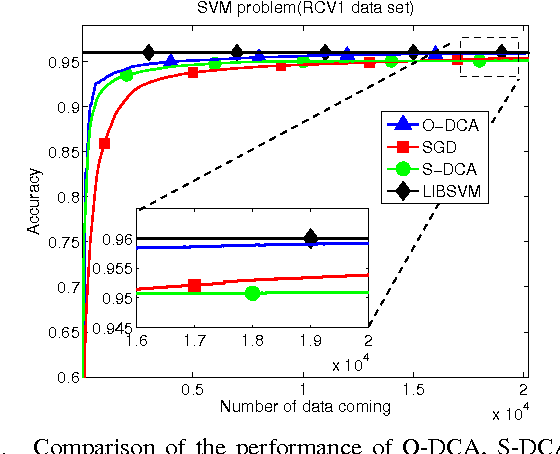
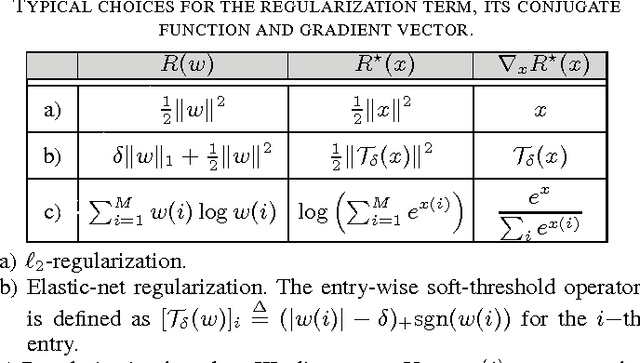
The stochastic dual coordinate-ascent (S-DCA) technique is a useful alternative to the traditional stochastic gradient-descent algorithm for solving large-scale optimization problems due to its scalability to large data sets and strong theoretical guarantees. However, the available S-DCA formulation is limited to finite sample sizes and relies on performing multiple passes over the same data. This formulation is not well-suited for online implementations where data keep streaming in. In this work, we develop an {\em online} dual coordinate-ascent (O-DCA) algorithm that is able to respond to streaming data and does not need to revisit the past data. This feature embeds the resulting construction with continuous adaptation, learning, and tracking abilities, which are particularly attractive for online learning scenarios.