 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactor Analysis, Probabilistic Principal Component Analysis, Variational Inference, and Variational Autoencoder: Tutorial and Survey
Jan 04, 2021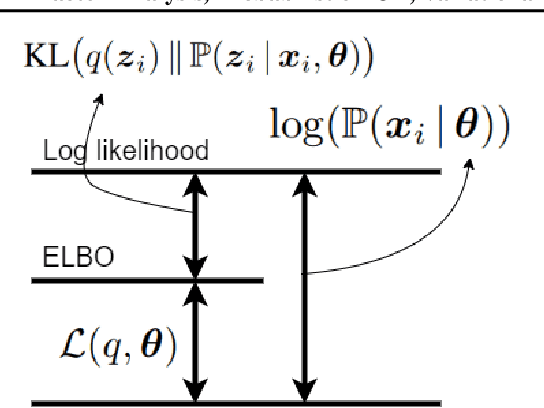
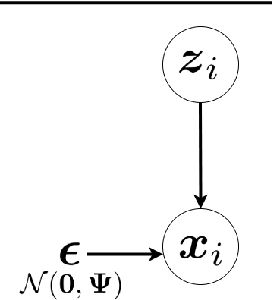
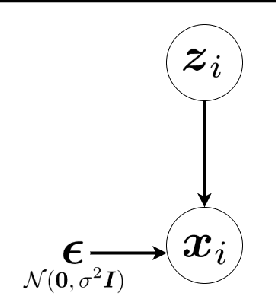
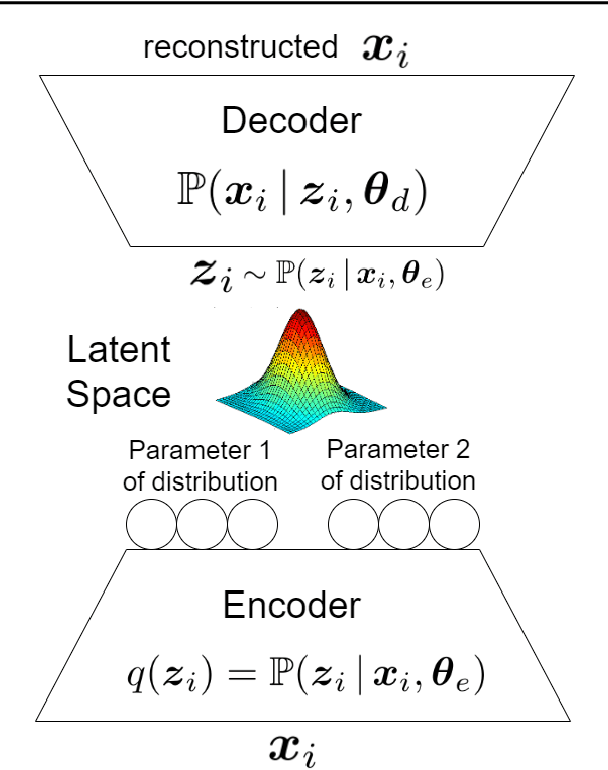
This is a tutorial and survey paper on factor analysis, probabilistic Principal Component Analysis (PCA), variational inference, and Variational Autoencoder (VAE). These methods, which are tightly related, are dimensionality reduction and generative models. They asssume that every data point is generated from or caused by a low-dimensional latent factor. By learning the parameters of distribution of latent space, the corresponding low-dimensional factors are found for the sake of dimensionality reduction. For their stochastic and generative behaviour, these models can also be used for generation of new data points in the data space. In this paper, we first start with variational inference where we derive the Evidence Lower Bound (ELBO) and Expectation Maximization (EM) for learning the parameters. Then, we introduce factor analysis, derive its joint and marginal distributions, and work out its EM steps. Probabilistic PCA is then explained, as a special case of factor analysis, and its closed-form solutions are derived. Finally, VAE is explained where the encoder, decoder and sampling from the latent space are introduced. Training VAE using both EM and backpropagation are explained.
Locally Linear Embedding and its Variants: Tutorial and Survey
Nov 22, 2020
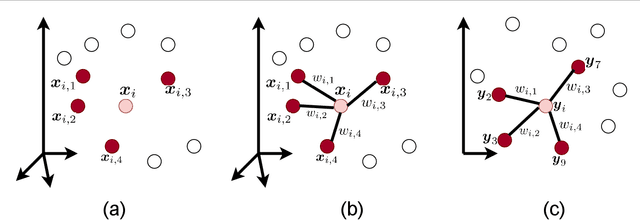
This is a tutorial and survey paper for Locally Linear Embedding (LLE) and its variants. The idea of LLE is fitting the local structure of manifold in the embedding space. In this paper, we first cover LLE, kernel LLE, inverse LLE, and feature fusion with LLE. Then, we cover out-of-sample embedding using linear reconstruction, eigenfunctions, and kernel mapping. Incremental LLE is explained for embedding streaming data. Landmark LLE methods using the Nystrom approximation and locally linear landmarks are explained for big data embedding. We introduce the methods for parameter selection of number of neighbors using residual variance, Procrustes statistics, preservation neighborhood error, and local neighborhood selection. Afterwards, Supervised LLE (SLLE), enhanced SLLE, SLLE projection, probabilistic SLLE, supervised guided LLE (using Hilbert-Schmidt independence criterion), and semi-supervised LLE are explained for supervised and semi-supervised embedding. Robust LLE methods using least squares problem and penalty functions are also introduced for embedding in the presence of outliers and noise. Then, we introduce fusion of LLE with other manifold learning methods including Isomap (i.e., ISOLLE), principal component analysis, Fisher discriminant analysis, discriminant LLE, and Isotop. Finally, we explain weighted LLE in which the distances, reconstruction weights, or the embeddings are adjusted for better embedding; we cover weighted LLE for deformed distributed data, weighted LLE using probability of occurrence, SLLE by adjusting weights, modified LLE, and iterative LLE.
Symbolically Solving Partial Differential Equations using Deep Learning
Nov 12, 2020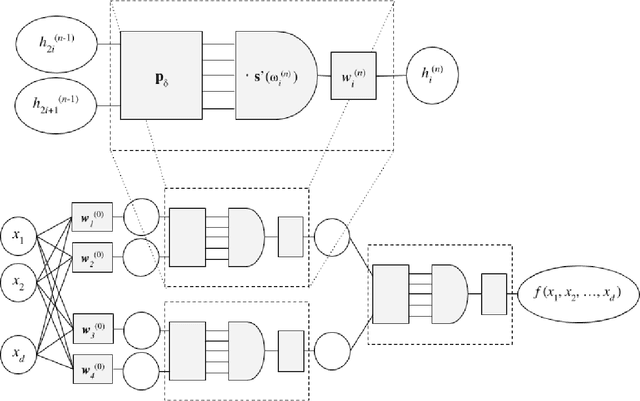
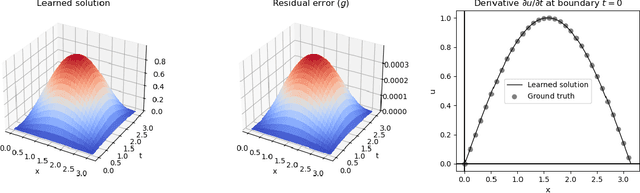
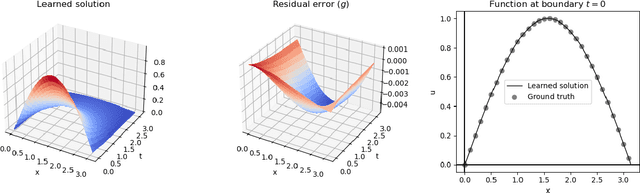
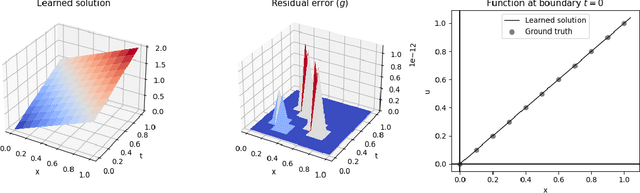
We describe a neural-based method for generating exact or approximate solutions to differential equations in the form of mathematical expressions. Unlike other neural methods, our system returns symbolic expressions that can be interpreted directly. Our method uses a neural architecture for learning mathematical expressions to optimize a customizable objective, and is scalable, compact, and easily adaptable for a variety of tasks and configurations. The system has been shown to effectively find exact or approximate symbolic solutions to various differential equations with applications in natural sciences. In this work, we highlight how our method applies to partial differential equations over multiple variables and more complex boundary and initial value conditions.
A Neuro-Symbolic Method for Solving Differential and Functional Equations
Nov 04, 2020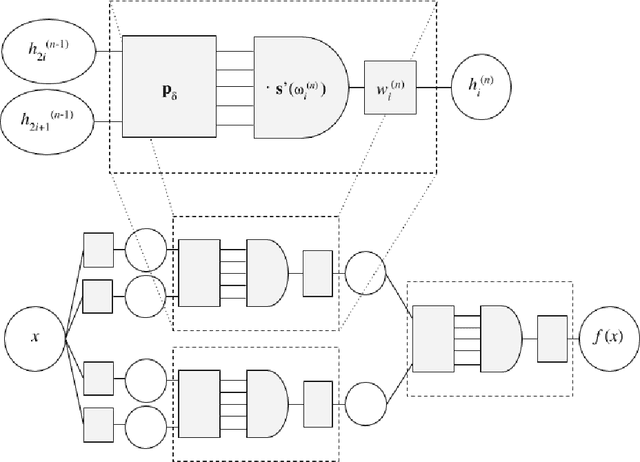

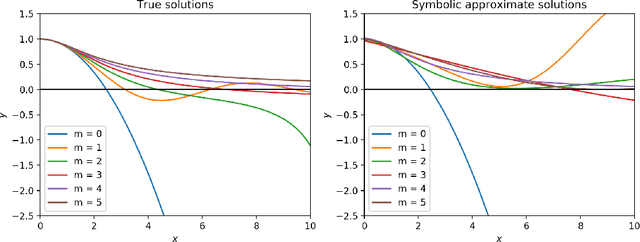

When neural networks are used to solve differential equations, they usually produce solutions in the form of black-box functions that are not directly mathematically interpretable. We introduce a method for generating symbolic expressions to solve differential equations while leveraging deep learning training methods. Unlike existing methods, our system does not require learning a language model over symbolic mathematics, making it scalable, compact, and easily adaptable for a variety of tasks and configurations. As part of the method, we propose a novel neural architecture for learning mathematical expressions to optimize a customizable objective. The system is designed to always return a valid symbolic formula, generating a useful approximation when an exact analytic solution to a differential equation is not or cannot be found. We demonstrate through examples how our method can be applied on a number of differential equations, often obtaining symbolic approximations that are useful or insightful. Furthermore, we show how the system can be effortlessly generalized to find symbolic solutions to other mathematical tasks, including integration and functional equations.
Stochastic Neighbor Embedding with Gaussian and Student-t Distributions: Tutorial and Survey
Sep 22, 2020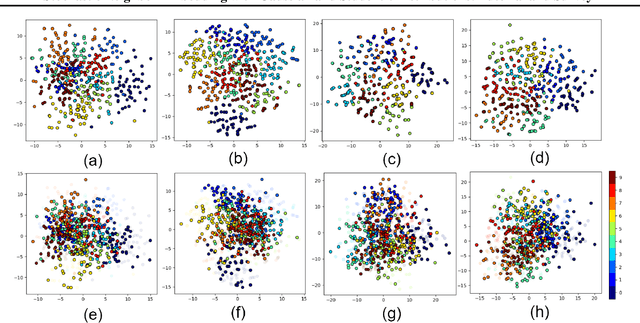
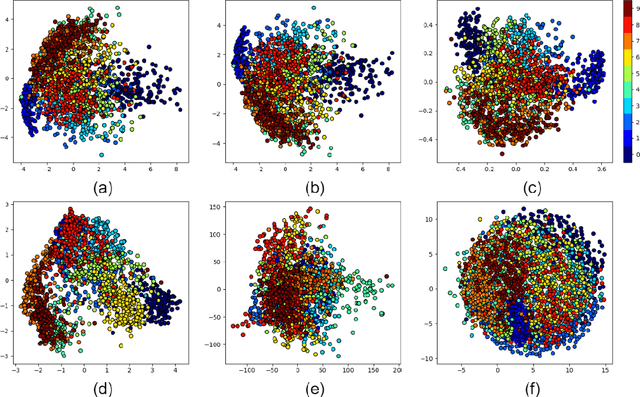
Stochastic Neighbor Embedding (SNE) is a manifold learning and dimensionality reduction method with a probabilistic approach. In SNE, every point is consider to be the neighbor of all other points with some probability and this probability is tried to be preserved in the embedding space. SNE considers Gaussian distribution for the probability in both the input and embedding spaces. However, t-SNE uses the Student-t and Gaussian distributions in these spaces, respectively. In this tutorial and survey paper, we explain SNE, symmetric SNE, t-SNE (or Cauchy-SNE), and t-SNE with general degrees of freedom. We also cover the out-of-sample extension and acceleration for these methods. Some simulations to visualize the embeddings are also provided.
Multidimensional Scaling, Sammon Mapping, and Isomap: Tutorial and Survey
Sep 17, 2020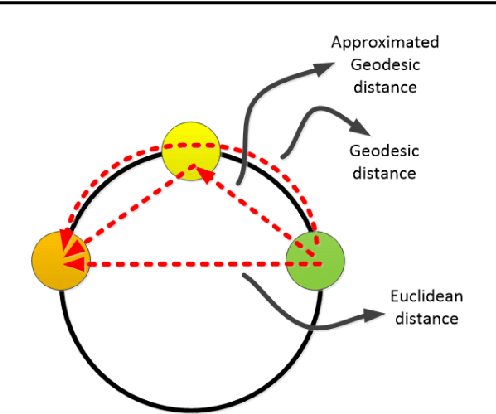
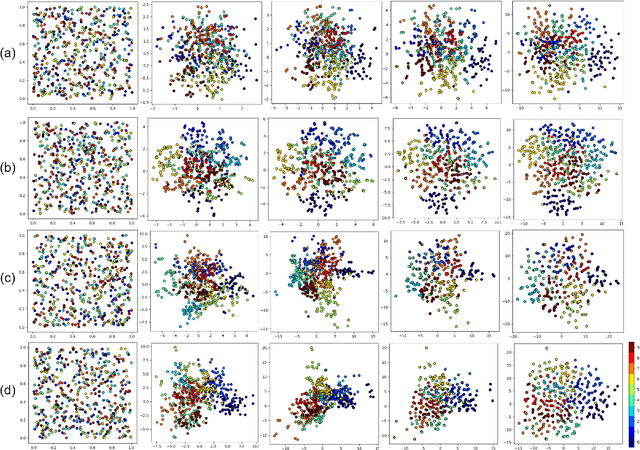
Multidimensional Scaling (MDS) is one of the first fundamental manifold learning methods. It can be categorized into several methods, i.e., classical MDS, kernel classical MDS, metric MDS, and non-metric MDS. Sammon mapping and Isomap can be considered as special cases of metric MDS and kernel classical MDS, respectively. In this tutorial and survey paper, we review the theory of MDS, Sammon mapping, and Isomap in detail. We explain all the mentioned categories of MDS. Then, Sammon mapping, Isomap, and kernel Isomap are explained. Out-of-sample embedding for MDS and Isomap using eigenfunctions and kernel mapping are introduced. Then, Nystrom approximation and its use in landmark MDS and landmark Isomap are introduced for big data embedding. We also provide some simulations for illustrating the embedding by these methods.
Segmentation Approach for Coreference Resolution Task
Jun 30, 2020

In coreference resolution, it is important to consider all members of a coreference cluster and decide about all of them at once. This technique can help to avoid losing precision and also in finding long-distance relations. The presented paper is a report of an ongoing study on an idea which proposes a new approach for coreference resolution which can resolve all coreference mentions to a given mention in the document in one pass. This has been accomplished by defining an embedding method for the position of all members of a coreference cluster in a document and resolving all of them for a given mention. In the proposed method, the BERT model has been used for encoding the documents and a head network designed to capture the relations between the embedded tokens. These are then converted to the proposed span position embedding matrix which embeds the position of all coreference mentions in the document. We tested this idea on CoNLL 2012 dataset and although the preliminary results from this method do not quite meet the state-of-the-art results, they are promising and they can capture features like long-distance relations better than the other approaches.
DeepNovoV2: Better de novo peptide sequencing with deep learning
May 22, 2019
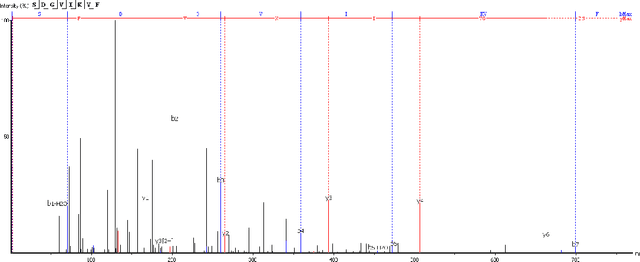
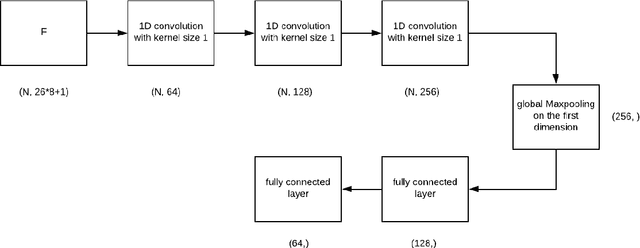
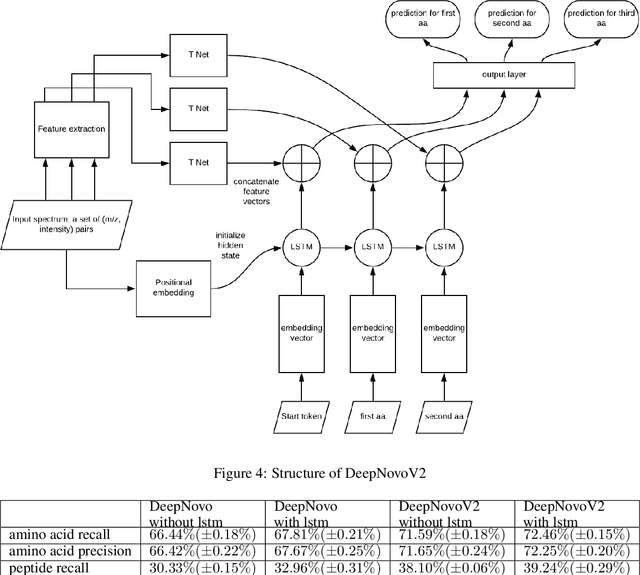
Personalized cancer vaccines are envisioned as the next generation rational cancer immunotherapy. The key step in developing personalized therapeutic cancer vaccines is to identify tumor-specific neoantigens that are on the surface of tumor cells. A promising method for this is through de novo peptide sequencing from mass spectrometry data. In this paper we introduce DeepNovoV2, the state-of-the-art model for peptide sequencing. In DeepNovoV2, a spectrum is directly represented as a set of (m/z, intensity) pairs, therefore it does not suffer from the accuracy-speed/memory trade-off problem. The model combines an order invariant network structure (T-Net) and recurrent neural networks and provides a complete end-to-end training and prediction framework to sequence patterns of peptides. Our experiments on a wide variety of data from different species show that DeepNovoV2 outperforms previous state-of-the-art methods, achieving 13.01-23.95\% higher accuracy at the peptide level.
Deep Variational Sufficient Dimensionality Reduction
Dec 18, 2018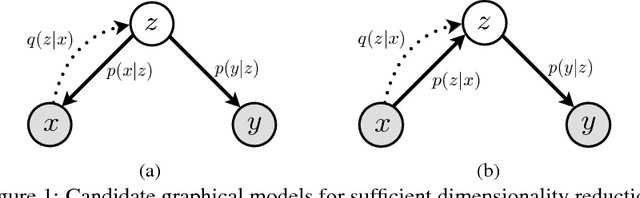



We consider the problem of sufficient dimensionality reduction (SDR), where the high-dimensional observation is transformed to a low-dimensional sub-space in which the information of the observations regarding the label variable is preserved. We propose DVSDR, a deep variational approach for sufficient dimensionality reduction. The deep structure in our model has a bottleneck that represent the low-dimensional embedding of the data. We explain the SDR problem using graphical models and use the framework of variational autoencoders to maximize the lower bound of the log-likelihood of the joint distribution of the observation and label. We show that such a maximization problem can be interpreted as solving the SDR problem. DVSDR can be easily adopted to semi-supervised learning setting. In our experiment we show that DVSDR performs competitively on classification tasks while being able to generate novel data samples.
SRP: Efficient class-aware embedding learning for large-scale data via supervised random projections
Nov 07, 2018
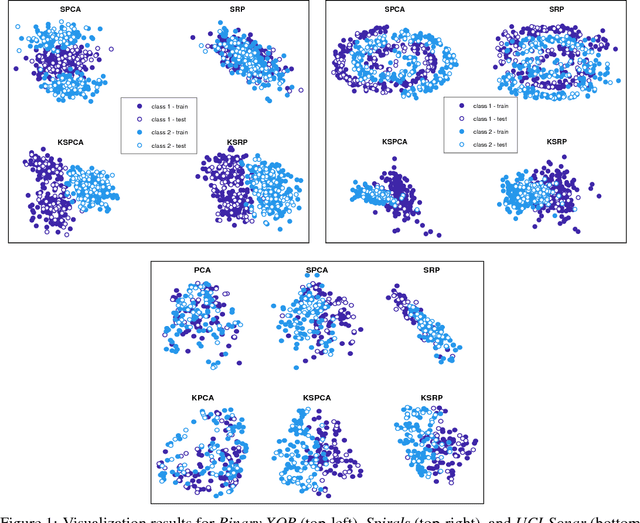
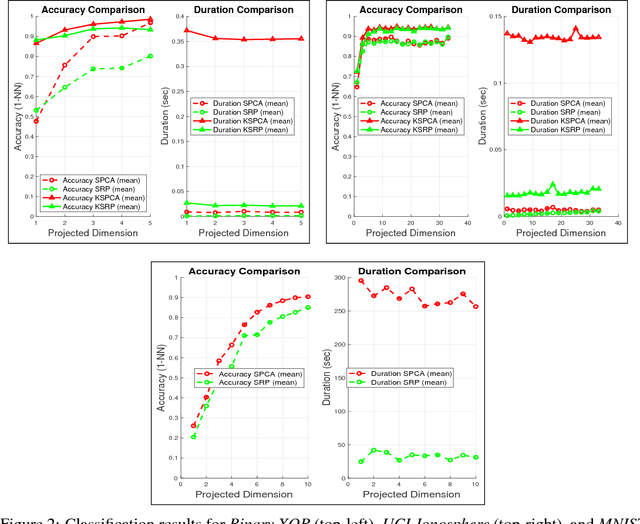
Supervised dimensionality reduction strategies have been of great interest. However, current supervised dimensionality reduction approaches are difficult to scale for situations characterized by large datasets given the high computational complexities associated with such methods. While stochastic approximation strategies have been explored for unsupervised dimensionality reduction to tackle this challenge, such approaches are not well-suited for accelerating computational speed for supervised dimensionality reduction. Motivated to tackle this challenge, in this study we explore a novel direction of directly learning optimal class-aware embeddings in a supervised manner via the notion of supervised random projections (SRP). The key idea behind SRP is that, rather than performing spectral decomposition (or approximations thereof) which are computationally prohibitive for large-scale data, we instead perform a direct decomposition by leveraging kernel approximation theory and the symmetry of the Hilbert-Schmidt Independence Criterion (HSIC) measure of dependence between the embedded data and the labels. Experimental results on five different synthetic and real-world datasets demonstrate that the proposed SRP strategy for class-aware embedding learning can be very promising in producing embeddings that are highly competitive with existing supervised dimensionality reduction methods (e.g., SPCA and KSPCA) while achieving 1-2 orders of magnitude better computational performance. As such, such an efficient approach to learning embeddings for dimensionality reduction can be a powerful tool for large-scale data analysis and visualization.