 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Semi-Supervised Adaptive Resonance Theory Model with Explanation Capability for Pattern Classification
May 19, 2023Most semi-supervised learning (SSL) models entail complex structures and iterative training processes as well as face difficulties in interpreting their predictions to users. To address these issues, this paper proposes a new interpretable SSL model using the supervised and unsupervised Adaptive Resonance Theory (ART) family of networks, which is denoted as SSL-ART. Firstly, SSL-ART adopts an unsupervised fuzzy ART network to create a number of prototype nodes using unlabeled samples. Then, it leverages a supervised fuzzy ARTMAP structure to map the established prototype nodes to the target classes using labeled samples. Specifically, a one-to-many (OtM) mapping scheme is devised to associate a prototype node with more than one class label. The main advantages of SSL-ART include the capability of: (i) performing online learning, (ii) reducing the number of redundant prototype nodes through the OtM mapping scheme and minimizing the effects of noisy samples, and (iii) providing an explanation facility for users to interpret the predicted outcomes. In addition, a weighted voting strategy is introduced to form an ensemble SSL-ART model, which is denoted as WESSL-ART. Every ensemble member, i.e., SSL-ART, assigns {\color{black}a different weight} to each class based on its performance pertaining to the corresponding class. The aim is to mitigate the effects of training data sequences on all SSL-ART members and improve the overall performance of WESSL-ART. The experimental results on eighteen benchmark data sets, three artificially generated data sets, and a real-world case study indicate the benefits of the proposed SSL-ART and WESSL-ART models for tackling pattern classification problems.
In-Distribution and Out-of-Distribution Self-supervised ECG Representation Learning for Arrhythmia Detection
Apr 13, 2023



This paper presents a systematic investigation into the effectiveness of Self-Supervised Learning (SSL) methods for Electrocardiogram (ECG) arrhythmia detection. We begin by conducting a novel distribution analysis on three popular ECG-based arrhythmia datasets: PTB-XL, Chapman, and Ribeiro. To the best of our knowledge, our study is the first to quantify these distributions in this area. We then perform a comprehensive set of experiments using different augmentations and parameters to evaluate the effectiveness of various SSL methods, namely SimCRL, BYOL, and SwAV, for ECG representation learning, where we observe the best performance achieved by SwAV. Furthermore, our analysis shows that SSL methods achieve highly competitive results to those achieved by supervised state-of-the-art methods. To further assess the performance of these methods on both In-Distribution (ID) and Out-of-Distribution (OOD) ECG data, we conduct cross-dataset training and testing experiments. Our comprehensive experiments show almost identical results when comparing ID and OOD schemes, indicating that SSL techniques can learn highly effective representations that generalize well across different OOD datasets. This finding can have major implications for ECG-based arrhythmia detection. Lastly, to further analyze our results, we perform detailed per-disease studies on the performance of the SSL methods on the three datasets.
Multimodal Brain-Computer Interface for In-Vehicle Driver Cognitive Load Measurement: Dataset and Baselines
Apr 09, 2023



Through this paper, we introduce a novel driver cognitive load assessment dataset, CL-Drive, which contains Electroencephalogram (EEG) signals along with other physiological signals such as Electrocardiography (ECG) and Electrodermal Activity (EDA) as well as eye tracking data. The data was collected from 21 subjects while driving in an immersive vehicle simulator, in various driving conditions, to induce different levels of cognitive load in the subjects. The tasks consisted of 9 complexity levels for 3 minutes each. Each driver reported their subjective cognitive load every 10 seconds throughout the experiment. The dataset contains the subjective cognitive load recorded as ground truth. In this paper, we also provide benchmark classification results for different machine learning and deep learning models for both binary and ternary label distributions. We followed 2 evaluation criteria namely 10-fold and leave-one-subject-out (LOSO). We have trained our models on both hand-crafted features as well as on raw data.
A Study on Bias and Fairness In Deep Speaker Recognition
Mar 14, 2023



With the ubiquity of smart devices that use speaker recognition (SR) systems as a means of authenticating individuals and personalizing their services, fairness of SR systems has becomes an important point of focus. In this paper we study the notion of fairness in recent SR systems based on 3 popular and relevant definitions, namely Statistical Parity, Equalized Odds, and Equal Opportunity. We examine 5 popular neural architectures and 5 commonly used loss functions in training SR systems, while evaluating their fairness against gender and nationality groups. Our detailed experiments shed light on this concept and demonstrate that more sophisticated encoder architectures better align with the definitions of fairness. Additionally, we find that the choice of loss functions can significantly impact the bias of SR models.
Human Pose Estimation from Ambiguous Pressure Recordings with Spatio-temporal Masked Transformers
Mar 10, 2023



Despite the impressive performance of vision-based pose estimators, they generally fail to perform well under adverse vision conditions and often don't satisfy the privacy demands of customers. As a result, researchers have begun to study tactile sensing systems as an alternative. However, these systems suffer from noisy and ambiguous recordings. To tackle this problem, we propose a novel solution for pose estimation from ambiguous pressure data. Our method comprises a spatio-temporal vision transformer with an encoder-decoder architecture. Detailed experiments on two popular public datasets reveal that our model outperforms existing solutions in the area. Moreover, we observe that increasing the number of temporal crops in the early stages of the network positively impacts the performance while pre-training the network in a self-supervised setting using a masked auto-encoder approach also further improves the results.
Partial Label Learning for Emotion Recognition from EEG
Feb 25, 2023Fully supervised learning has recently achieved promising performance in various electroencephalography (EEG) learning tasks by training on large datasets with ground truth labels. However, labeling EEG data for affective experiments is challenging, as it can be difficult for participants to accurately distinguish between similar emotions, resulting in ambiguous labeling (reporting multiple emotions for one EEG instance). This notion could cause model performance degradation, as the ground truth is hidden within multiple candidate labels. To address this issue, Partial Label Learning (PLL) has been proposed to identify the ground truth from candidate labels during the training phase, and has shown good performance in the computer vision domain. However, PLL methods have not yet been adopted for EEG representation learning or implemented for emotion recognition tasks. In this paper, we adapt and re-implement six state-of-the-art PLL approaches for emotion recognition from EEG on a large emotion dataset (SEED-V, containing five emotion classes). We evaluate the performance of all methods in classical and real-world experiments. The results show that PLL methods can achieve strong results in affective computing from EEG and achieve comparable performance to fully supervised learning. We also investigate the effect of label disambiguation, a key step in many PLL methods. The results show that in most cases, label disambiguation would benefit the model when the candidate labels are generated based on their similarities to the ground truth rather than obeying a uniform distribution. This finding suggests the potential of using label disambiguation-based PLL methods for real-world affective tasks. We make the source code of this paper publicly available at: https://github.com/guangyizhangbci/PLL-Emotion-EEG.
Audio Representation Learning by Distilling Video as Privileged Information
Feb 06, 2023Deep audio representation learning using multi-modal audio-visual data often leads to a better performance compared to uni-modal approaches. However, in real-world scenarios both modalities are not always available at the time of inference, leading to performance degradation by models trained for multi-modal inference. In this work, we propose a novel approach for deep audio representation learning using audio-visual data when the video modality is absent at inference. For this purpose, we adopt teacher-student knowledge distillation under the framework of learning using privileged information (LUPI). While the previous methods proposed for LUPI use soft-labels generated by the teacher, in our proposed method we use embeddings learned by the teacher to train the student network. We integrate our method in two different settings: sequential data where the features are divided into multiple segments throughout time, and non-sequential data where the entire features are treated as one whole segment. In the non-sequential setting both the teacher and student networks are comprised of an encoder component and a task header. We use the embeddings produced by the encoder component of the teacher to train the encoder of the student, while the task header of the student is trained using ground-truth labels. In the sequential setting, the networks have an additional aggregation component that is placed between the encoder and task header. We use two sets of embeddings produced by the encoder and aggregation component of the teacher to train the student. Similar to the non-sequential setting, the task header of the student network is trained using ground-truth labels. We test our framework on two different audio-visual tasks, namely speaker recognition and speech emotion recognition and show considerable improvements over sole audio-based recognition as well as prior works that use LUPI.
XKD: Cross-modal Knowledge Distillation with Domain Alignment for Video Representation Learning
Dec 12, 2022We present XKD, a novel self-supervised framework to learn meaningful representations from unlabelled video clips. XKD is trained with two pseudo tasks. First, masked data reconstruction is performed to learn modality-specific representations. Next, self-supervised cross-modal knowledge distillation is performed between the two modalities through teacher-student setups to learn complementary information. To identify the most effective information to transfer and also to tackle the domain gap between audio and visual modalities which could hinder knowledge transfer, we introduce a domain alignment strategy for effective cross-modal distillation. Lastly, to develop a general-purpose solution capable of handling both audio and visual streams, a modality-agnostic variant of our proposed framework is introduced, which uses the same backbone for both audio and visual modalities. Our proposed cross-modal knowledge distillation improves linear evaluation top-1 accuracy of video action classification by 8.4% on UCF101, 8.1% on HMDB51, 13.8% on Kinetics-Sound, and 14.2% on Kinetics400. Additionally, our modality-agnostic variant shows promising results in developing a general-purpose network capable of handling different data streams. The code is released on the project website.
Impact of Labelled Set Selection and Supervision Policies on Semi-supervised Learning
Nov 27, 2022



In semi-supervised representation learning frameworks, when the number of labelled data is very scarce, the quality and representativeness of these samples become increasingly important. Existing literature on semi-supervised learning randomly sample a limited number of data points for labelling. All these labelled samples are then used along with the unlabelled data throughout the training process. In this work, we ask two important questions in this context: (1) does it matter which samples are selected for labelling? (2) does it matter how the labelled samples are used throughout the training process along with the unlabelled data? To answer the first question, we explore a number of unsupervised methods for selecting specific subsets of data to label (without prior knowledge of their labels), with the goal of maximizing representativeness w.r.t. the unlabelled set. Then, for our second line of inquiry, we define a variety of different label injection strategies in the training process. Extensive experiments on four popular datasets, CIFAR-10, CIFAR-100, SVHN, and STL-10, show that unsupervised selection of samples that are more representative of the entire data improves performance by up to ~2% over the existing semi-supervised frameworks such as MixMatch, ReMixMatch, FixMatch and others with random sample labelling. We show that this boost could even increase to 7.5% for very few-labelled scenarios. However, our study shows that gradually injecting the labels throughout the training procedure does not impact the performance considerably versus when all the existing labels are used throughout the entire training.
FaceTopoNet: Facial Expression Recognition using Face Topology Learning
Sep 13, 2022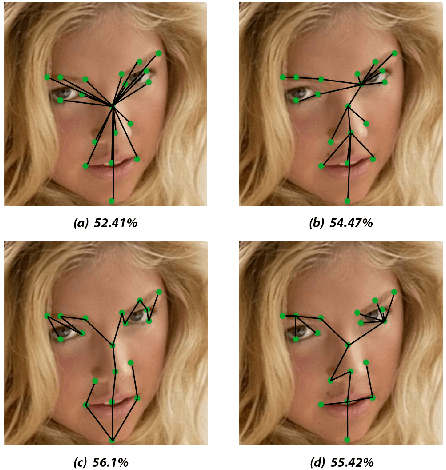

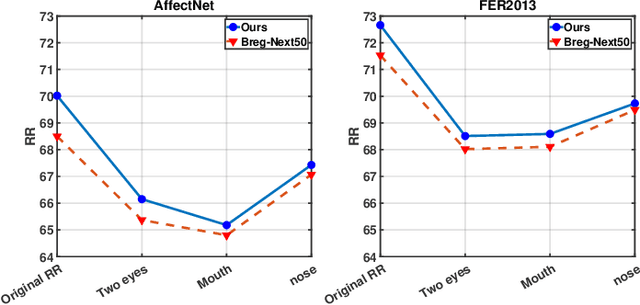
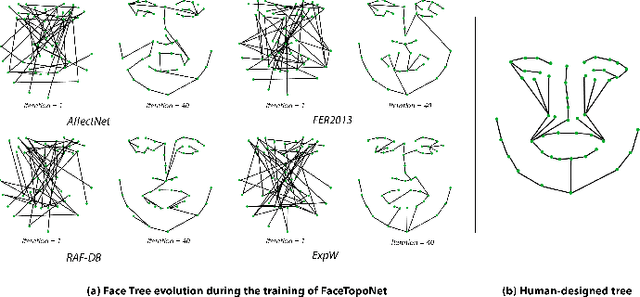
Prior work has shown that the order in which different components of the face are learned using a sequential learner can play an important role in the performance of facial expression recognition systems. We propose FaceTopoNet, an end-to-end deep model for facial expression recognition, which is capable of learning an effective tree topology of the face. Our model then traverses the learned tree to generate a sequence, which is then used to form an embedding to feed a sequential learner. The devised model adopts one stream for learning structure and one stream for learning texture. The structure stream focuses on the positions of the facial landmarks, while the main focus of the texture stream is on the patches around the landmarks to learn textural information. We then fuse the outputs of the two streams by utilizing an effective attention-based fusion strategy. We perform extensive experiments on four large-scale in-the-wild facial expression datasets - namely AffectNet, FER2013, ExpW, and RAF-DB - and one lab-controlled dataset (CK+) to evaluate our approach. FaceTopoNet achieves state-of-the-art performance on three of the five datasets and obtains competitive results on the other two datasets. We also perform rigorous ablation and sensitivity experiments to evaluate the impact of different components and parameters in our model. Lastly, we perform robustness experiments and demonstrate that FaceTopoNet is more robust against occlusions in comparison to other leading methods in the area.