 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContemplating real-world object classification
Mar 27, 2021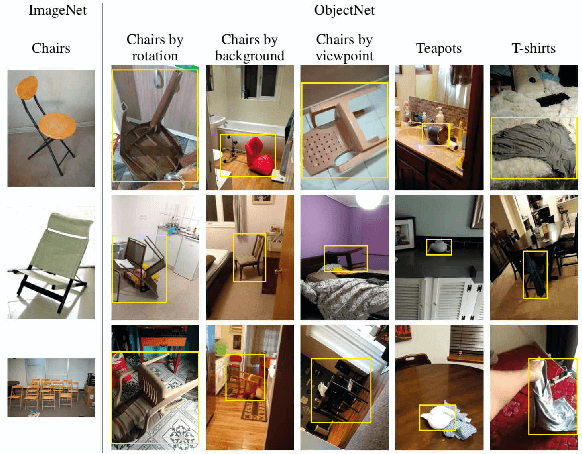

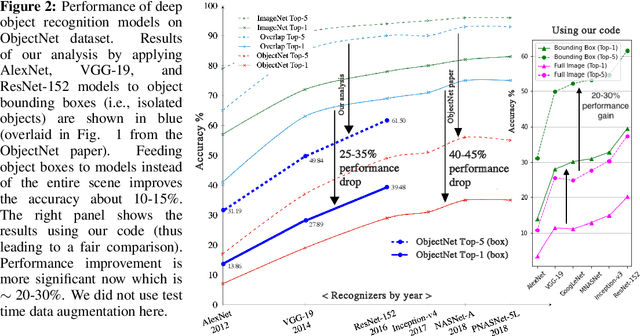
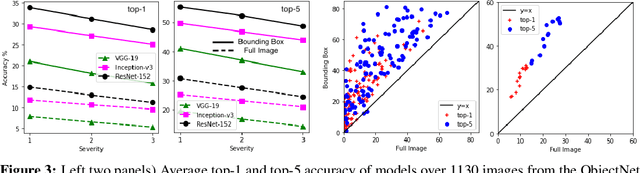
Deep object recognition models have been very successful over benchmark datasets such as ImageNet. How accurate and robust are they to distribution shifts arising from natural and synthetic variations in datasets? Prior research on this problem has primarily focused on ImageNet variations (e.g., ImageNetV2, ImageNet-A). To avoid potential inherited biases in these studies, we take a different approach. Specifically, we reanalyze the ObjectNet dataset recently proposed by Barbu et al. containing objects in daily life situations. They showed a dramatic performance drop of the state of the art object recognition models on this dataset. Due to the importance and implications of their results regarding the generalization ability of deep models, we take a second look at their analysis. We find that applying deep models to the isolated objects, rather than the entire scene as is done in the original paper, results in around 20-30% performance improvement. Relative to the numbers reported in Barbu et al., around 10-15% of the performance loss is recovered, without any test time data augmentation. Despite this gain, however, we conclude that deep models still suffer drastically on the ObjectNet dataset. We also investigate the robustness of models against synthetic image perturbations such as geometric transformations (e.g., scale, rotation, translation), natural image distortions (e.g., impulse noise, blur) as well as adversarial attacks (e.g., FGSM and PGD-5). Our results indicate that limiting the object area as much as possible (i.e., from the entire image to the bounding box to the segmentation mask) leads to consistent improvement in accuracy and robustness.
Pros and Cons of GAN Evaluation Measures: New Developments
Mar 17, 2021



This work is an update of a previous paper on the same topic published a few years ago. With the dramatic progress in generative modeling, a suite of new quantitative and qualitative techniques to evaluate models has emerged. Although some measures such as Inception Score, Fr\'echet Inception Distance, Precision-Recall, and Perceptual Path Length are relatively more popular, GAN evaluation is not a settled issue and there is still room for improvement. For example, in addition to quality and diversity of synthesized images, generative models should be evaluated in terms of bias and fairness. I describe new dimensions that are becoming important in assessing models, and discuss the connection between GAN evaluation and deepfakes.
Enhancing sensor resolution improves CNN accuracy given the same number of parameters or FLOPS
Mar 09, 2021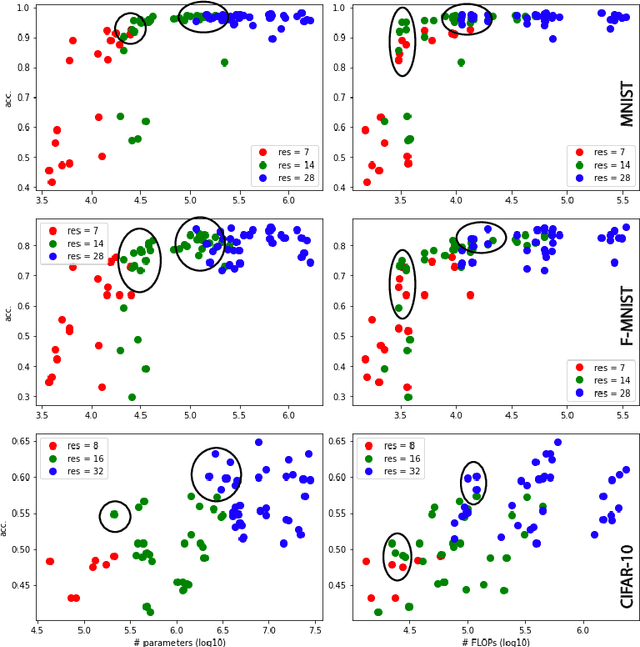
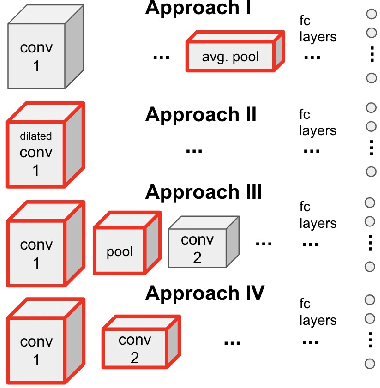
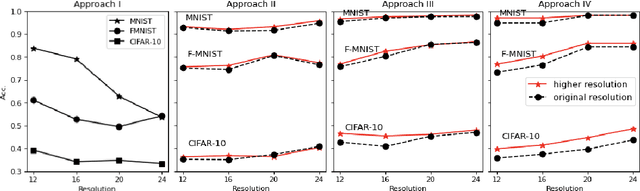
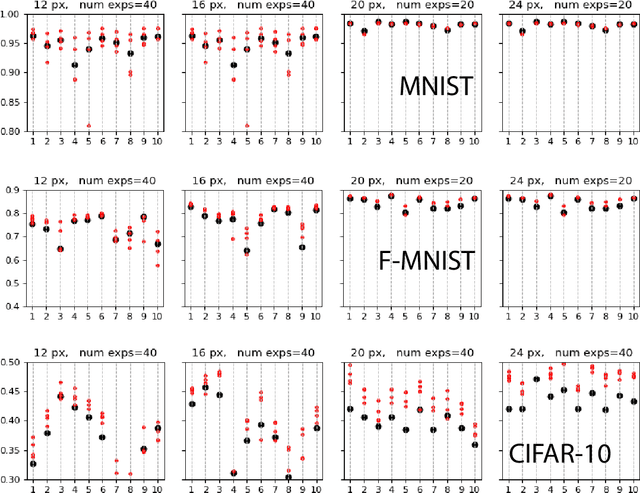
High image resolution is critical to obtain a good performance in many computer vision applications. Computational complexity of CNNs, however, grows significantly with the increase in input image size. Here, we show that it is almost always possible to modify a network such that it achieves higher accuracy at a higher input resolution while having the same number of parameters or/and FLOPS. The idea is similar to the EfficientNet paper but instead of optimizing network width, depth and resolution simultaneously, here we focus only on input resolution. This makes the search space much smaller which is more suitable for low computational budget regimes. More importantly, by controlling for the number of model parameters (and hence model capacity), we show that the additional benefit in accuracy is indeed due to the higher input resolution. Preliminary empirical investigation over MNIST, Fashion MNIST, and CIFAR10 datasets demonstrates the efficiency of the proposed approach.
Shape Defense
Aug 31, 2020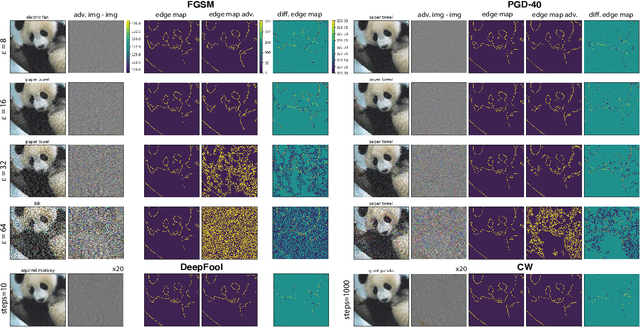
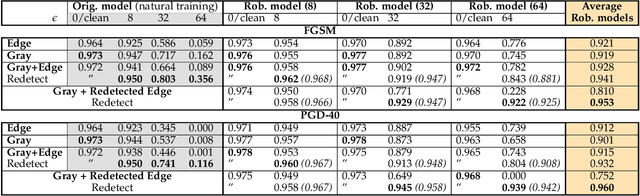
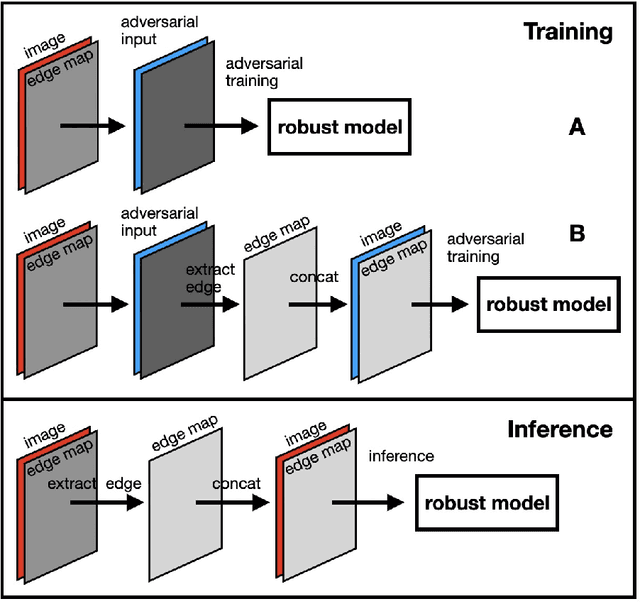
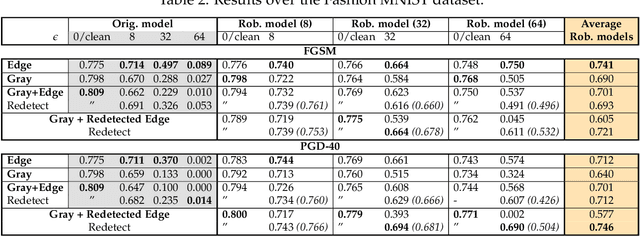
Humans rely heavily on shape information to recognize objects. Conversely, convolutional neural networks (CNNs) are biased more towards texture. This is perhaps the main reason why CNNs are vulnerable to adversarial examples. Here, we explore how shape bias can be incorporated into CNNs to improve their robustness. Two algorithms are proposed, based on the observation that edges are invariant to moderate imperceptible perturbations. In the first one, a classifier is adversarially trained on images with the edge map as an additional channel. At inference time, the edge map is recomputed and concatenated to the image. In the second algorithm, a conditional GAN is trained to translate the edge maps, from clean and/or perturbed images, into clean images. Inference is done over the generated image corresponding to the input's edge map. Extensive experiments over 10 datasets demonstrate the effectiveness of the proposed algorithms against FGSM and $\ell_\infty$ PGD-40 attacks. Further, we show that a) edge information can also benefit other adversarial training methods, and b) CNNs trained on edge-augmented inputs are more robust against natural image corruptions such as motion blur, impulse noise and JPEG compression, than CNNs trained solely on RGB images. From a broader perspective, our study suggests that CNNs do not adequately account for image structures that are crucial for robustness. Code is available at:~\url{https://github.com/aliborji/Shapedefence.git}.
A Compact Deep Architecture for Real-time Saliency Prediction
Aug 30, 2020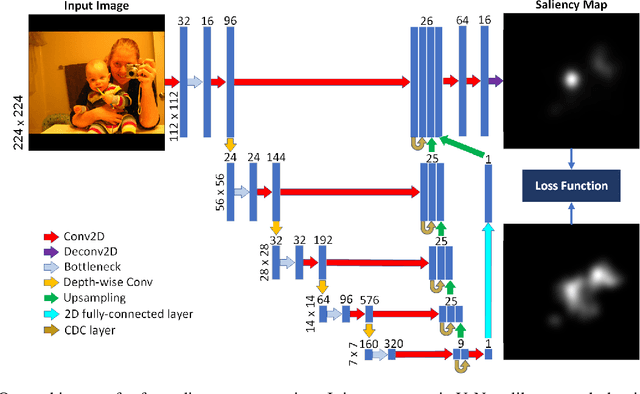

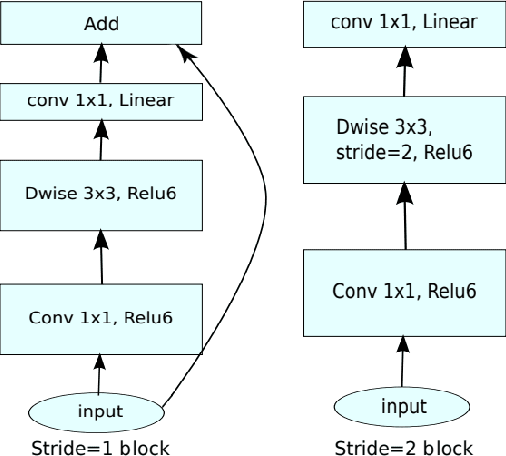
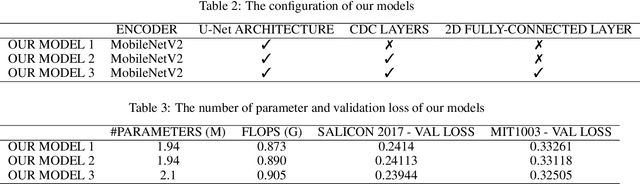
Saliency computation models aim to imitate the attention mechanism in the human visual system. The application of deep neural networks for saliency prediction has led to a drastic improvement over the last few years. However, deep models have a high number of parameters which makes them less suitable for real-time applications. Here we propose a compact yet fast model for real-time saliency prediction. Our proposed model consists of a modified U-net architecture, a novel fully connected layer, and central difference convolutional layers. The modified U-Net architecture promotes compactness and efficiency. The novel fully-connected layer facilitates the implicit capturing of the location-dependent information. Using the central difference convolutional layers at different scales enables capturing more robust and biologically motivated features. We compare our model with state of the art saliency models using traditional saliency scores as well as our newly devised scheme. Experimental results over four challenging saliency benchmark datasets demonstrate the effectiveness of our approach in striking a balance between accuracy and speed. Our model can be run in real-time which makes it appealing for edge devices and video processing.
Harnessing adversarial examples with a surprisingly simple defense
Jun 03, 2020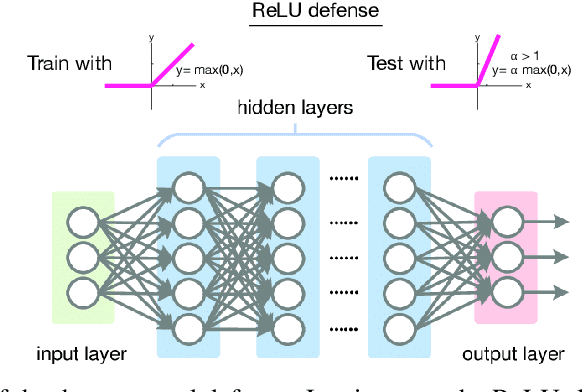
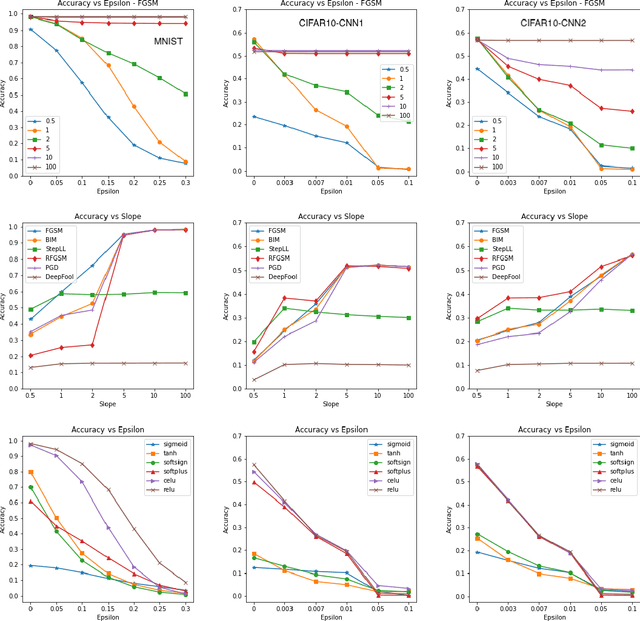
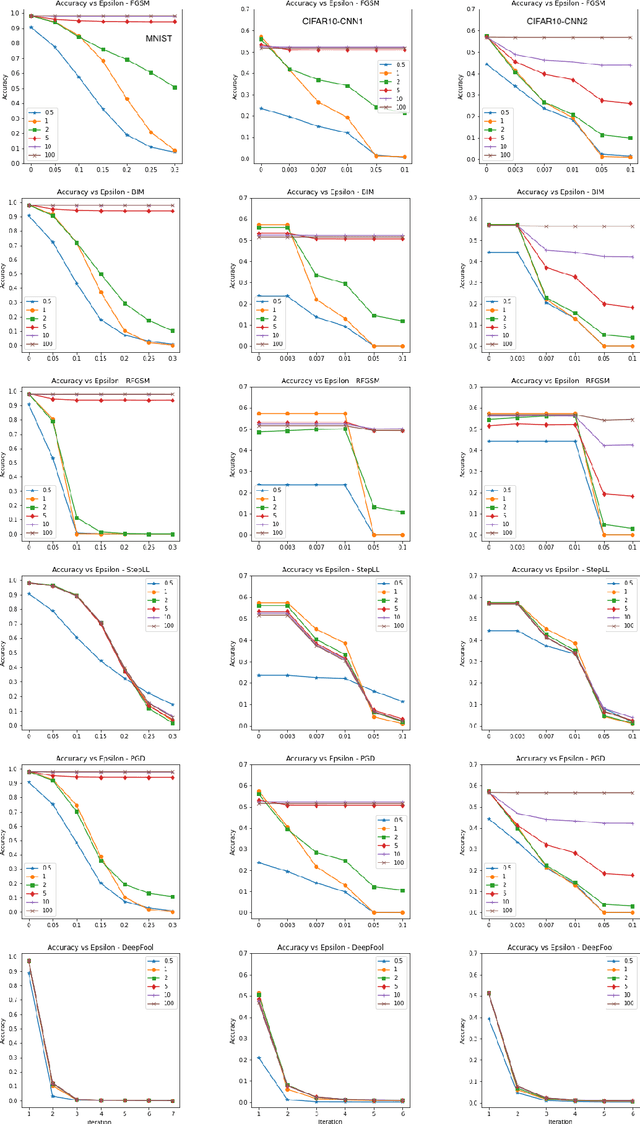
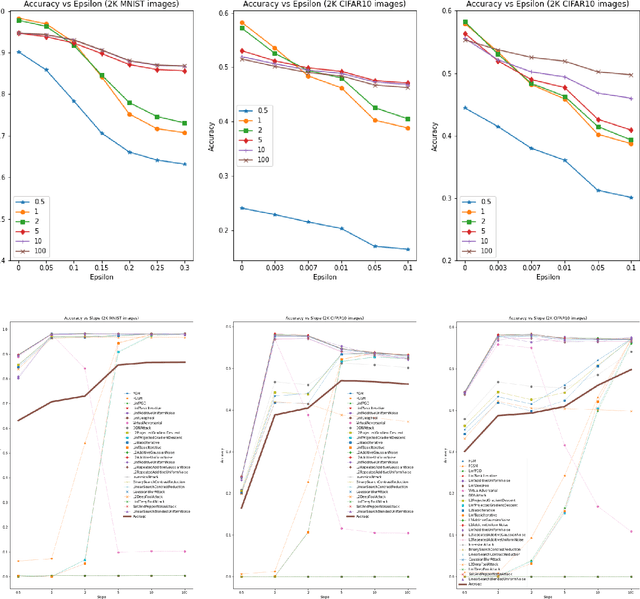
I introduce a very simple method to defend against adversarial examples. The basic idea is to raise the slope of the ReLU function at the test time. Experiments over MNIST and CIFAR-10 datasets demonstrate the effectiveness of the proposed defense against a number of strong attacks in both untargeted and targeted settings. While perhaps not as effective as the state of the art adversarial defenses, this approach can provide insights to understand and mitigate adversarial attacks. It can also be used in conjunction with other defenses.
Adversarial examples are useful too!
May 13, 2020
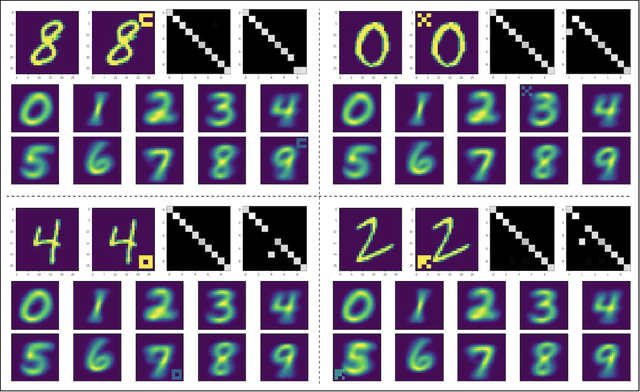
Deep learning has come a long way and has enjoyed an unprecedented success. Despite high accuracy, however, deep models are brittle and are easily fooled by imperceptible adversarial perturbations. In contrast to common inference-time attacks, Backdoor (\aka Trojan) attacks target the training phase of model construction, and are extremely difficult to combat since a) the model behaves normally on a pristine testing set and b) the augmented perturbations can be minute and may only affect few training samples. Here, I propose a new method to tell whether a model has been subject to a backdoor attack. The idea is to generate adversarial examples, targeted or untargeted, using conventional attacks such as FGSM and then feed them back to the classifier. By computing the statistics (here simply mean maps) of the images in different categories and comparing them with the statistics of a reference model, it is possible to visually locate the perturbed regions and unveil the attack.
Empirical Upper Bound, Error Diagnosis and Invariance Analysis of Modern Object Detectors
Apr 05, 2020
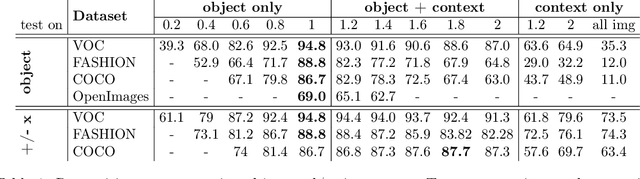
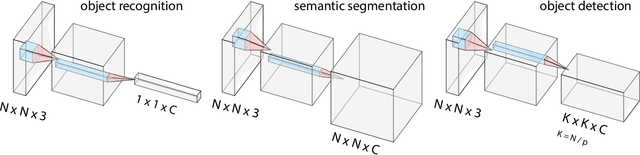
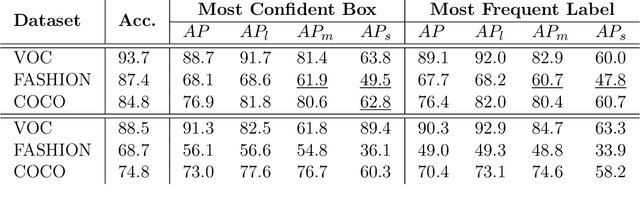
Object detection remains as one of the most notorious open problems in computer vision. Despite large strides in accuracy in recent years, modern object detectors have started to saturate on popular benchmarks raising the question of how far we can reach with deep learning tools and tricks. Here, by employing 2 state-of-the-art object detection benchmarks, and analyzing more than 15 models over 4 large scale datasets, we I) carefully determine the upper bound in AP, which is 91.6% on VOC (test2007), 78.2% on COCO (val2017), and 58.9% on OpenImages V4 (validation), regardless of the IOU threshold. These numbers are much better than the mAP of the best model (47.9% on VOC, and 46.9% on COCO; IOUs=.5:.05:.95), II) characterize the sources of errors in object detectors, in a novel and intuitive way, and find that classification error (confusion with other classes and misses) explains the largest fraction of errors and weighs more than localization and duplicate errors, and III) analyze the invariance properties of models when surrounding context of an object is removed, when an object is placed in an incongruent background, and when images are blurred or flipped vertically. We find that models generate a lot of boxes on empty regions and that context is more important for detecting small objects than larger ones. Our work taps into the tight relationship between object detection and object recognition and offers insights for building better models. Our code is publicly available at https://github.com/aliborji/Deetctionupper bound.git.
ObjectNet Dataset: Reanalysis and Correction
Apr 04, 2020

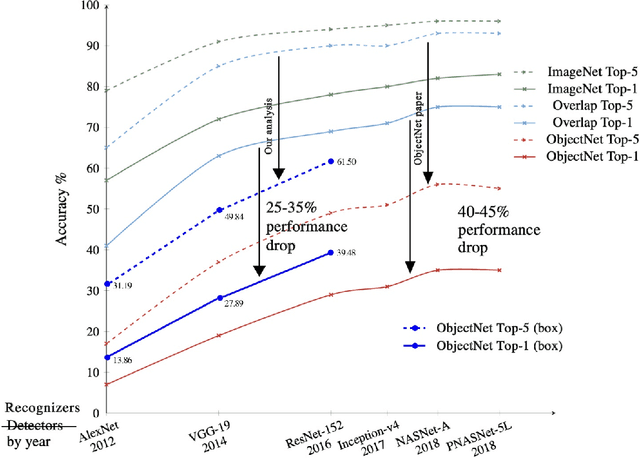
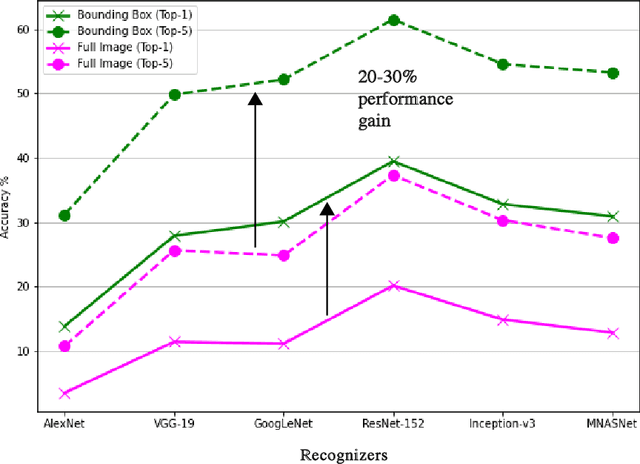
Recently, Barbu et al introduced a dataset called ObjectNet which includes objects in daily life situations. They showed a dramatic performance drop of the state of the art object recognition models on this dataset. Due to the importance and implications of their results regarding generalization ability of deep models, we take a second look at their findings. We highlight a major problem with their work which is applying object recognizers to the scenes containing multiple objects rather than isolated objects. The latter results in around 20-30% performance gain using our code. Compared with the results reported in the ObjectNet paper, we observe that around 10-15 % of the performance loss can be recovered, without any test time data augmentation. In accordance with Barbu et al.'s conclusions, however, we also conclude that deep models suffer drastically on this dataset. Thus, we believe that ObjectNet remains a challenging dataset for testing the generalization power of models beyond datasets on which they have been trained.
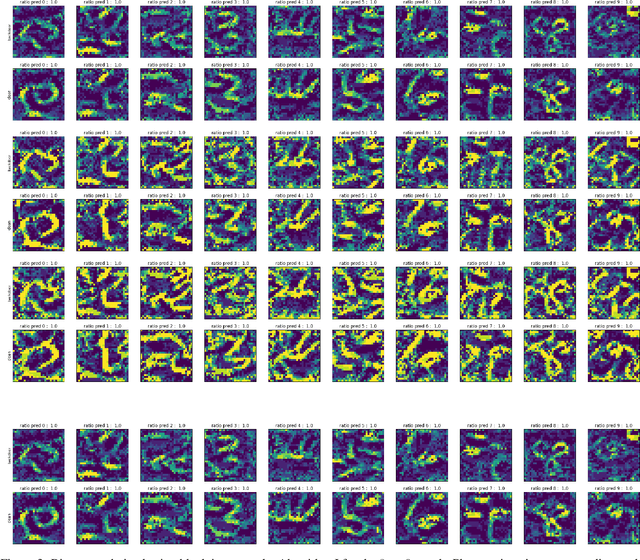
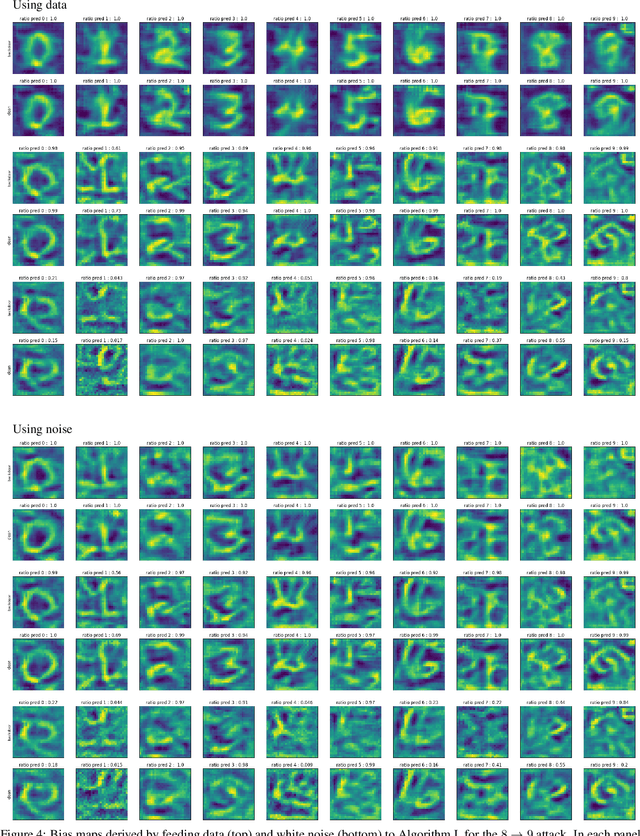
White Noise Analysis of Neural Networks
Dec 23, 2019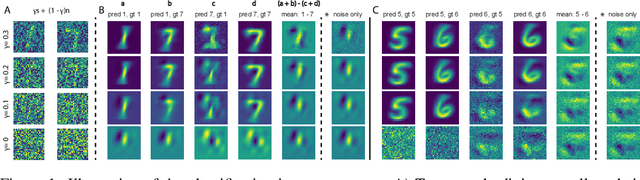
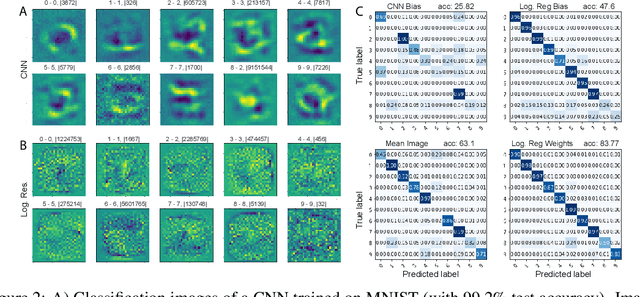

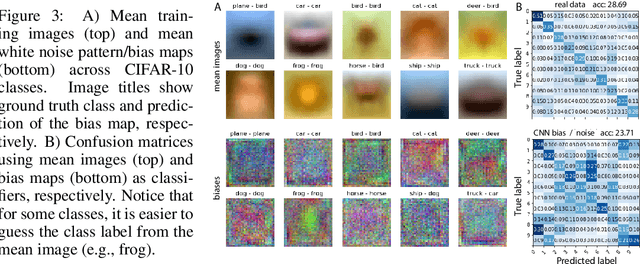
A white noise analysis of modern deep neural networks is presented to unveil their biases at the whole network level or the single neuron level. Our analysis is based on two popular and related methods in psychophysics and neurophysiology namely classification images and spike triggered analysis. These methods have been widely used to understand the underlying mechanisms of sensory systems in humans and monkeys. We leverage them to investigate the inherent biases of deep neural networks and to obtain a first-order approximation of their functionality. We emphasize on CNNs since they are currently the state of the art methods in computer vision and are a decent model of human visual processing. In addition, we study multi-layer perceptrons, logistic regression, and recurrent neural networks. Experiments over four classic datasets, MNIST, Fashion-MNIST, CIFAR-10, and ImageNet, show that the computed bias maps resemble the target classes and when used for classification lead to an over twofold performance than the chance level. Further, we show that classification images can be used to attack a black-box classifier and to detect adversarial patch attacks. Finally, we utilize spike triggered averaging to derive the filters of CNNs and explore how the behavior of a network changes when neurons in different layers are modulated. Our effort illustrates a successful example of borrowing from neurosciences to study ANNs and highlights the importance of cross-fertilization and synergy across machine learning, deep learning, and computational neuroscience.