 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint ML-Bayesian Approach to Adaptive Radar Detection in the presence of Gaussian Interference
Mar 04, 2025



This paper addresses the adaptive radar target detection problem in the presence of Gaussian interference with unknown statistical properties. To this end, the problem is first formulated as a binary hypothesis test, and then we derive a detection architecture grounded on the hybrid of Maximum Likelihood (ML) and Maximum A Posterior (MAP) approach. Specifically, we resort to the hidden discrete latent variables in conjunction with the Expectation-Maximization (EM) algorithms which cyclically updates the estimates of the unknowns. In this framework, the estimates of the a posteriori probabilities under each hypothesis are representative of the inherent nature of data and used to decide for the presence of a potential target. In addition, we prove that the developed detection scheme ensures the desired Constant False Alarm Rate property with respect to the unknown interference covariance matrix. Numerical examples obtained through synthetic and real recorded data corroborate the effectiveness of the proposed architecture and show that the MAP-based approach ensures evident improvement with respect to the conventional generalized likelihood ratio test at least for the considered scenarios and parameter setting.
Improved PCRLB for radar tracking in clutter with geometry-dependent target measurement uncertainty and application to radar trajectory control
Oct 08, 2024



In realistic radar tracking, target measurement uncertainty (TMU) in terms of both detection probability and measurement error covariance is significantly affected by the target-to-radar (T2R) geometry. However, existing posterior Cramer-Rao Lower Bounds (PCRLBs) rarely investigate the fundamental impact of T2R geometry on target measurement uncertainty and eventually on mean square error (MSE) of state estimate, inevitably resulting in over-conservative lower bound. To address this issue, this paper firstly derives the generalized model of target measurement error covariance for bistatic radar with moving receiver and transmitter illuminating any type of signal, along with its approximated solution to specify the impact of T2R geometry on error covariance. Based upon formulated TMU model, an improved PCRLB (IPCRLB) fully accounting for both measurement origin uncertainty and geometry-dependent TMU is then re-derived, both detection probability and measurement error covariance are treated as state-dependent parameters when differentiating log-likelihood with respect to target state. Compared to existing PCRLBs that partially or completely ignore the dependence of target measurement uncertainty on T2R geometry, proposed IPCRLB provides a much accurate (less-conservative) lower bound for radar tracking in clutter with geometry-dependent TMU. The new bound is then applied to radar trajectory control to effectively optimize T2R geometry and exhibits least uncertainty of acquired target measurement and more accurate state estimate for bistatic radar tracking in clutter, compared to state-of-the-art trajectory control methods.
Classification Schemes for the Radar Reference Window: Design and Comparisons
Feb 16, 2023



In this paper, we address the problem of classifying data within the radar reference window in terms of statistical properties. Specifically, we partition these data into statistically homogeneous subsets by identifying possible clutter power variations with respect to the cells under test (accounting for possible range-spread targets) and/or clutter edges. To this end, we consider different situations of practical interest and formulate the classification problem as multiple hypothesis tests comprising several models for the operating scenario. Then, we solve the hypothesis testing problems by resorting to suitable approximations of the model order selection rules due to the intractable mathematics associated with the maximum likelihood estimation of some parameters. Remarkably, the classification results provided by the proposed architectures represent an advanced clutter map since, besides the estimation of the clutter parameters, they contain a clustering of the range bins in terms of homogeneous subsets. In fact, such information can drive the conventional detectors towards more reliable estimates of the clutter covariance matrix according to the position of the cells under test. The performance analysis confirms that the conceived architectures represent a viable means to recognize the scenario wherein the radar is operating at least for the considered simulation parameters.
Pseudo-Zernike Based Multi-Pass Automatic Target Recognition From Multi-Channel SAR
Aug 06, 2014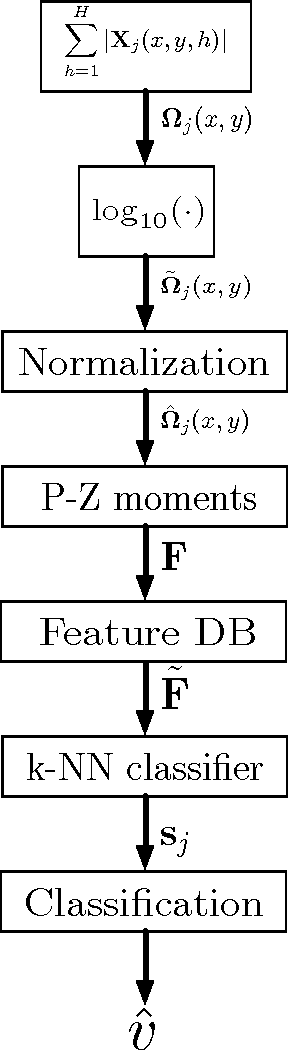
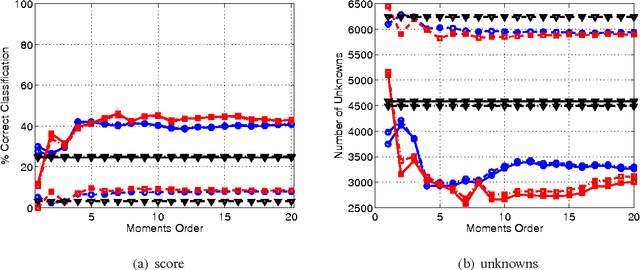


The capability to exploit multiple sources of information is of fundamental importance in a battlefield scenario. Information obtained from different sources, and separated in space and time, provide the opportunity to exploit diversities in order to mitigate uncertainty. For the specific challenge of Automatic Target Recognition (ATR) from radar platforms, both channel (e.g. polarization) and spatial diversity can provide useful information for such a specific and critical task. In this paper the use of pseudo-Zernike moments applied to multi-channel multi-pass data is presented exploiting diversities and invariant properties leading to high confidence ATR, small computational complexity and data transfer requirements. The effectiveness of the proposed approach, in different configurations and data source availability is demonstrated using real data.