 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercomplete Independent Component Analysis via SDP
Jan 24, 2019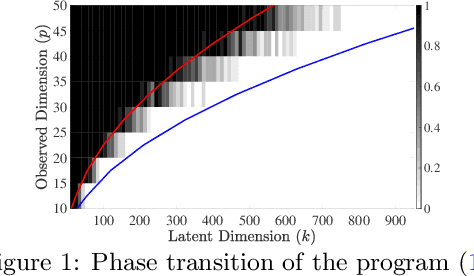
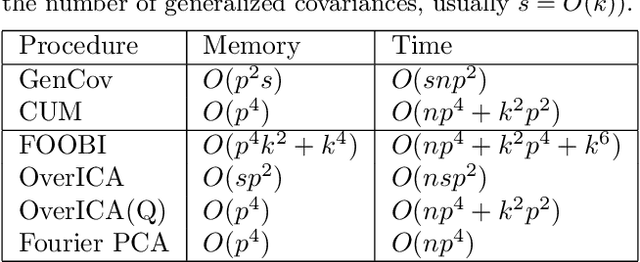
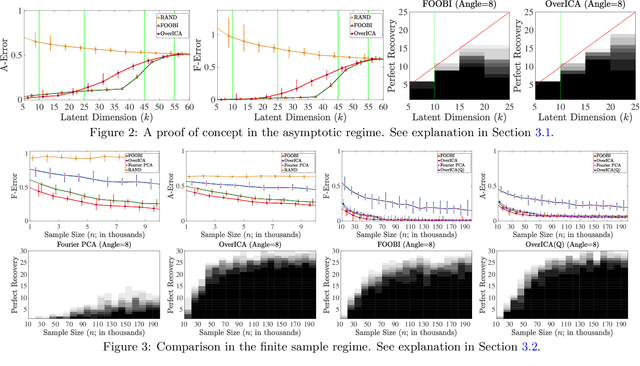

We present a novel algorithm for overcomplete independent components analysis (ICA), where the number of latent sources k exceeds the dimension p of observed variables. Previous algorithms either suffer from high computational complexity or make strong assumptions about the form of the mixing matrix. Our algorithm does not make any sparsity assumption yet enjoys favorable computational and theoretical properties. Our algorithm consists of two main steps: (a) estimation of the Hessians of the cumulant generating function (as opposed to the fourth and higher order cumulants used by most algorithms) and (b) a novel semi-definite programming (SDP) relaxation for recovering a mixing component. We show that this relaxation can be efficiently solved with a projected accelerated gradient descent method, which makes the whole algorithm computationally practical. Moreover, we conjecture that the proposed program recovers a mixing component at the rate k < p^2/4 and prove that a mixing component can be recovered with high probability when k < (2 - epsilon) p log p when the original components are sampled uniformly at random on the hyper sphere. Experiments are provided on synthetic data and the CIFAR-10 dataset of real images.
Nonlinear Acceleration of CNNs
Jun 01, 2018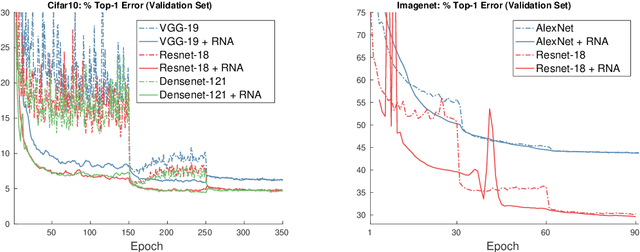
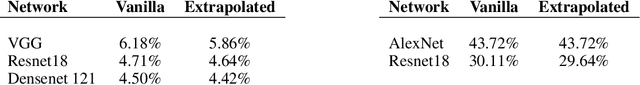
The Regularized Nonlinear Acceleration (RNA) algorithm is an acceleration method capable of improving the rate of convergence of many optimization schemes such as gradient descend, SAGA or SVRG. Until now, its analysis is limited to convex problems, but empirical observations shows that RNA may be extended to wider settings. In this paper, we investigate further the benefits of RNA when applied to neural networks, in particular for the task of image recognition on CIFAR10 and ImageNet. With very few modifications of exiting frameworks, RNA improves slightly the optimization process of CNNs, after training.
Nonlinear Acceleration of Deep Neural Networks
May 24, 2018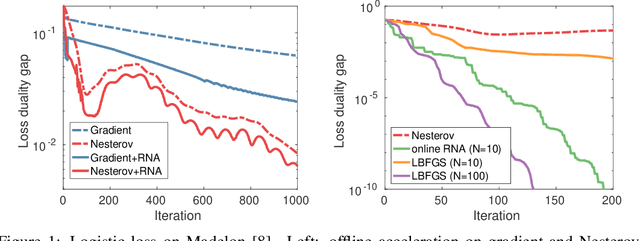
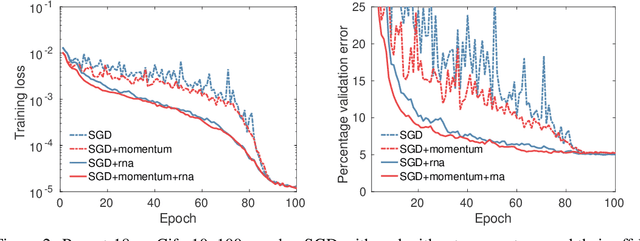

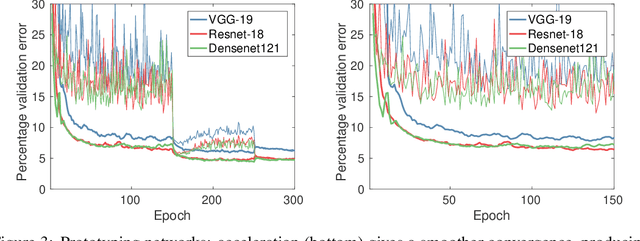
Regularized nonlinear acceleration (RNA) is a generic extrapolation scheme for optimization methods, with marginal computational overhead. It aims to improve convergence using only the iterates of simple iterative algorithms. However, so far its application to optimization was theoretically limited to gradient descent and other single-step algorithms. Here, we adapt RNA to a much broader setting including stochastic gradient with momentum and Nesterov's fast gradient. We use it to train deep neural networks, and empirically observe that extrapolated networks are more accurate, especially in the early iterations. A straightforward application of our algorithm when training ResNet-152 on ImageNet produces a top-1 test error of 20.88%, improving by 0.8% the reference classification pipeline. Furthermore, the code runs offline in this case, so it never negatively affects performance.
Frank-Wolfe with Subsampling Oracle
Mar 20, 2018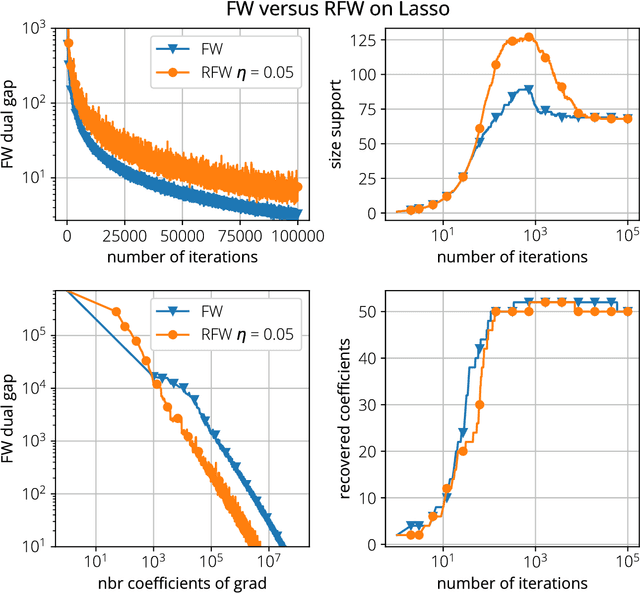
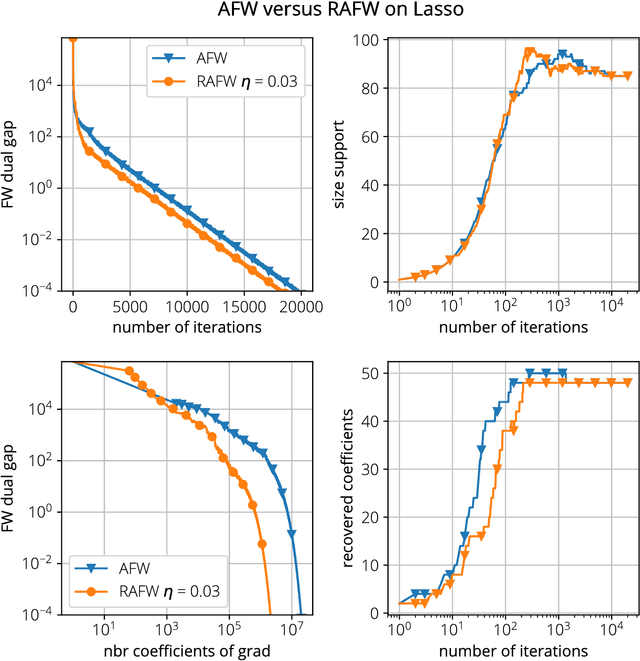
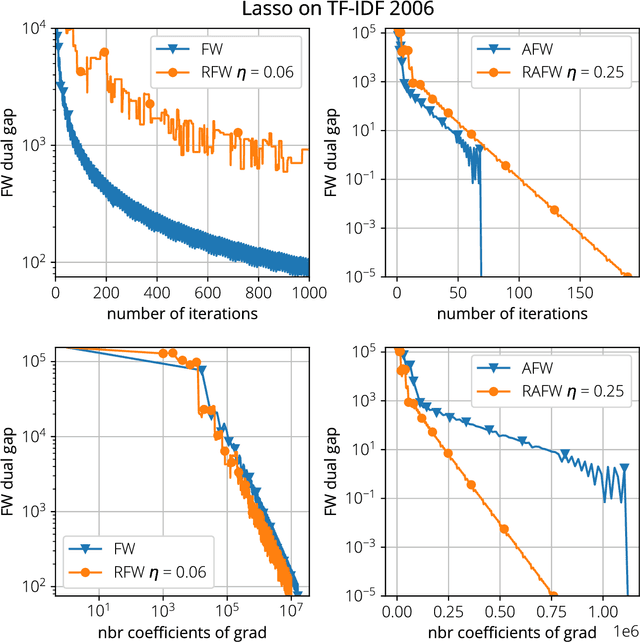
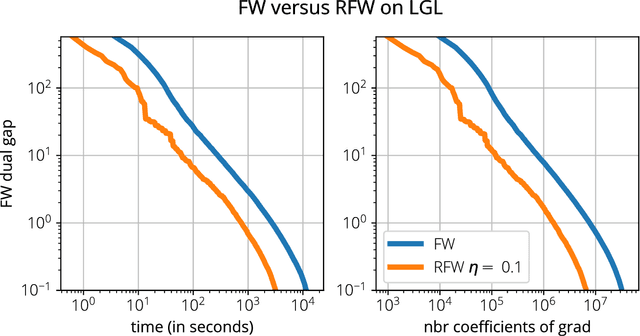
We analyze two novel randomized variants of the Frank-Wolfe (FW) or conditional gradient algorithm. While classical FW algorithms require solving a linear minimization problem over the domain at each iteration, the proposed method only requires to solve a linear minimization problem over a small \emph{subset} of the original domain. The first algorithm that we propose is a randomized variant of the original FW algorithm and achieves a $\mathcal{O}(1/t)$ sublinear convergence rate as in the deterministic counterpart. The second algorithm is a randomized variant of the Away-step FW algorithm, and again as its deterministic counterpart, reaches linear (i.e., exponential) convergence rate making it the first provably convergent randomized variant of Away-step FW. In both cases, while subsampling reduces the convergence rate by a constant factor, the linear minimization step can be a fraction of the cost of that of the deterministic versions, especially when the data is streamed. We illustrate computational gains of the algorithms on regression problems, involving both $\ell_1$ and latent group lasso penalties.
Learning with Clustering Structure
Sep 19, 2016
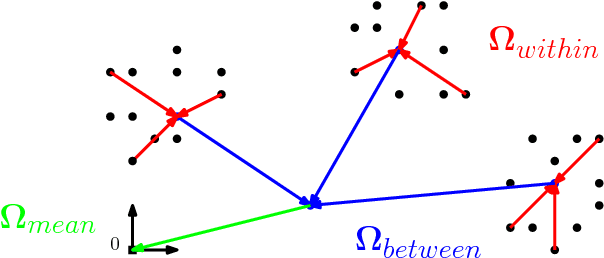
We study supervised learning problems using clustering constraints to impose structure on either features or samples, seeking to help both prediction and interpretation. The problem of clustering features arises naturally in text classification for instance, to reduce dimensionality by grouping words together and identify synonyms. The sample clustering problem on the other hand, applies to multiclass problems where we are allowed to make multiple predictions and the performance of the best answer is recorded. We derive a unified optimization formulation highlighting the common structure of these problems and produce algorithms whose core iteration complexity amounts to a k-means clustering step, which can be approximated efficiently. We extend these results to combine sparsity and clustering constraints, and develop a new projection algorithm on the set of clustered sparse vectors. We prove convergence of our algorithms on random instances, based on a union of subspaces interpretation of the clustering structure. Finally, we test the robustness of our methods on artificial data sets as well as real data extracted from movie reviews.
Spectral Ranking using Seriation
Mar 10, 2016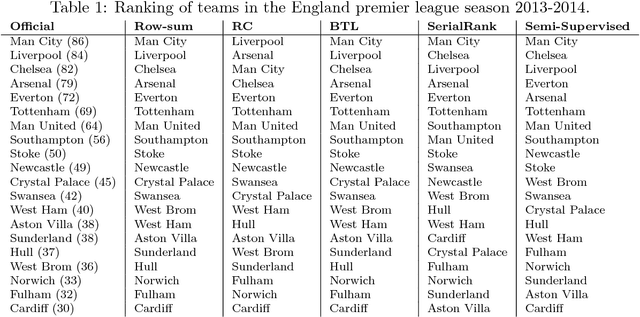

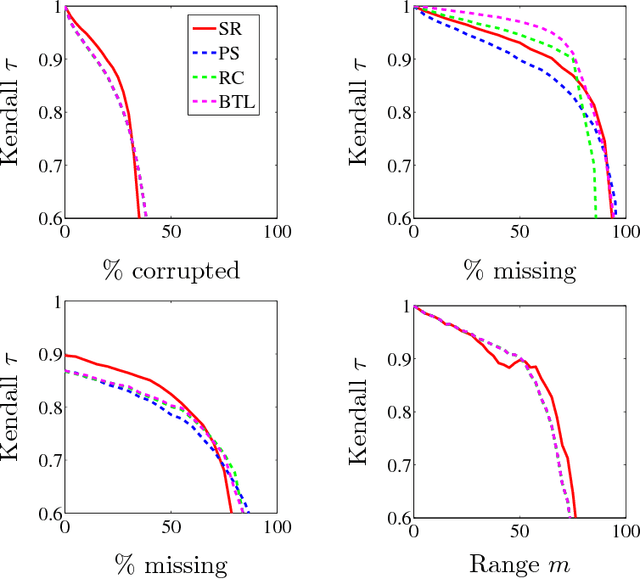
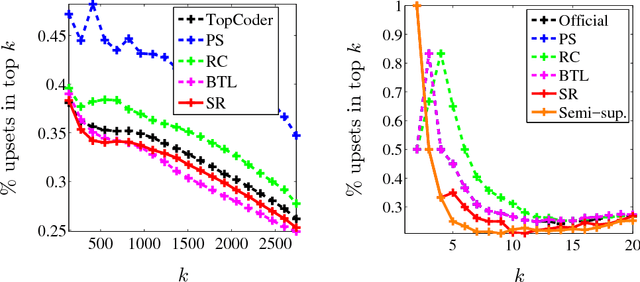
We describe a seriation algorithm for ranking a set of items given pairwise comparisons between these items. Intuitively, the algorithm assigns similar rankings to items that compare similarly with all others. It does so by constructing a similarity matrix from pairwise comparisons, using seriation methods to reorder this matrix and construct a ranking. We first show that this spectral seriation algorithm recovers the true ranking when all pairwise comparisons are observed and consistent with a total order. We then show that ranking reconstruction is still exact when some pairwise comparisons are corrupted or missing, and that seriation based spectral ranking is more robust to noise than classical scoring methods. Finally, we bound the ranking error when only a random subset of the comparions are observed. An additional benefit of the seriation formulation is that it allows us to solve semi-supervised ranking problems. Experiments on both synthetic and real datasets demonstrate that seriation based spectral ranking achieves competitive and in some cases superior performance compared to classical ranking methods.
Support Vector Machine Classification with Indefinite Kernels
Aug 04, 2009
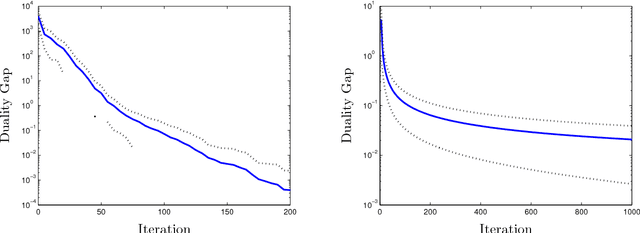
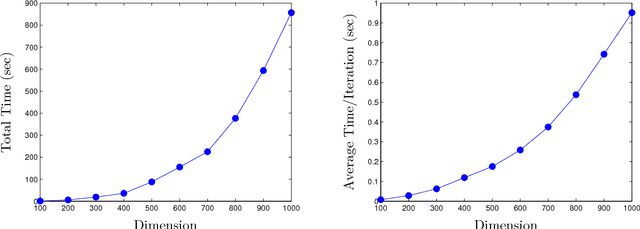
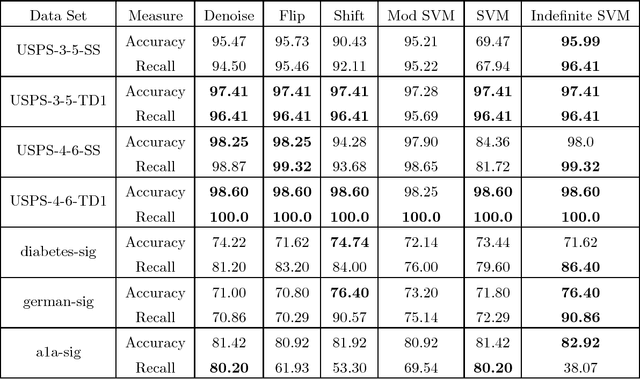
We propose a method for support vector machine classification using indefinite kernels. Instead of directly minimizing or stabilizing a nonconvex loss function, our algorithm simultaneously computes support vectors and a proxy kernel matrix used in forming the loss. This can be interpreted as a penalized kernel learning problem where indefinite kernel matrices are treated as a noisy observations of a true Mercer kernel. Our formulation keeps the problem convex and relatively large problems can be solved efficiently using the projected gradient or analytic center cutting plane methods. We compare the performance of our technique with other methods on several classic data sets.
Predicting Abnormal Returns From News Using Text Classification
Jun 24, 2009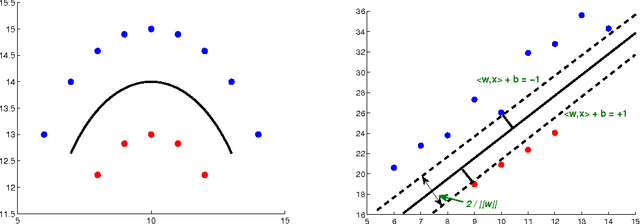

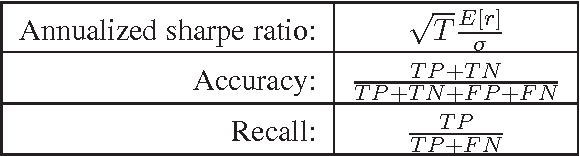
We show how text from news articles can be used to predict intraday price movements of financial assets using support vector machines. Multiple kernel learning is used to combine equity returns with text as predictive features to increase classification performance and we develop an analytic center cutting plane method to solve the kernel learning problem efficiently. We observe that while the direction of returns is not predictable using either text or returns, their size is, with text features producing significantly better performance than historical returns alone.
Clustering and Feature Selection using Sparse Principal Component Analysis
Oct 08, 2008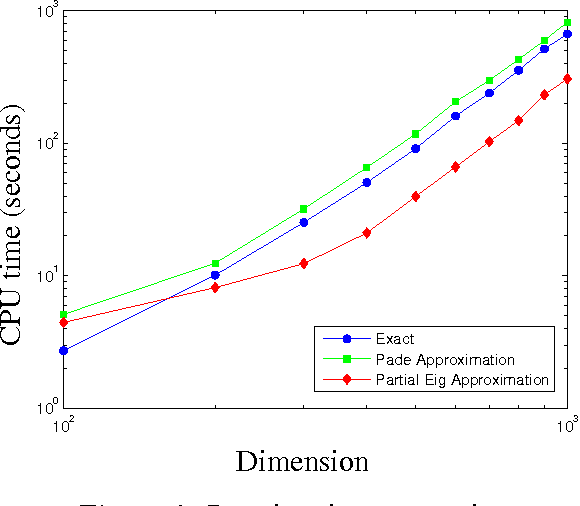

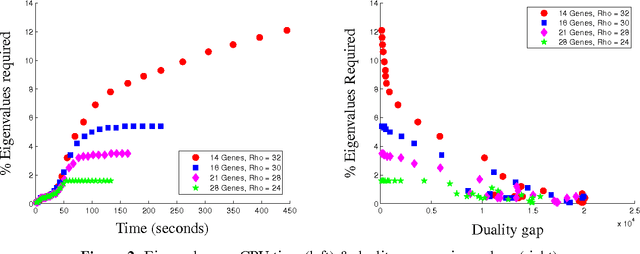
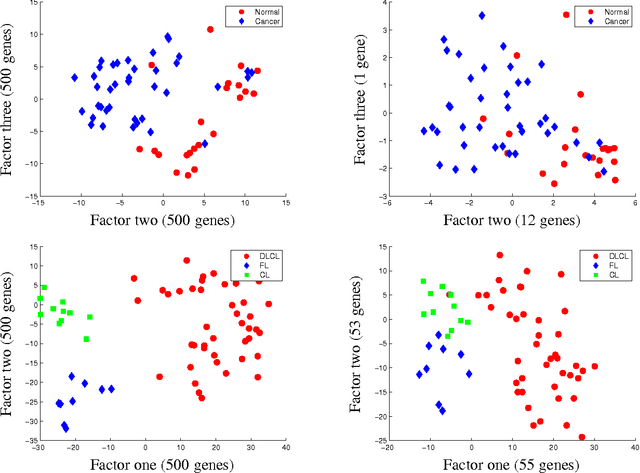
In this paper, we study the application of sparse principal component analysis (PCA) to clustering and feature selection problems. Sparse PCA seeks sparse factors, or linear combinations of the data variables, explaining a maximum amount of variance in the data while having only a limited number of nonzero coefficients. PCA is often used as a simple clustering technique and sparse factors allow us here to interpret the clusters in terms of a reduced set of variables. We begin with a brief introduction and motivation on sparse PCA and detail our implementation of the algorithm in d'Aspremont et al. (2005). We then apply these results to some classic clustering and feature selection problems arising in biology.
Optimal Solutions for Sparse Principal Component Analysis
Nov 09, 2007Given a sample covariance matrix, we examine the problem of maximizing the variance explained by a linear combination of the input variables while constraining the number of nonzero coefficients in this combination. This is known as sparse principal component analysis and has a wide array of applications in machine learning and engineering. We formulate a new semidefinite relaxation to this problem and derive a greedy algorithm that computes a full set of good solutions for all target numbers of non zero coefficients, with total complexity O(n^3), where n is the number of variables. We then use the same relaxation to derive sufficient conditions for global optimality of a solution, which can be tested in O(n^3) per pattern. We discuss applications in subset selection and sparse recovery and show on artificial examples and biological data that our algorithm does provide globally optimal solutions in many cases.