 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA game-theoretic analysis of networked system control for common-pool resource management using multi-agent reinforcement learning
Oct 15, 2020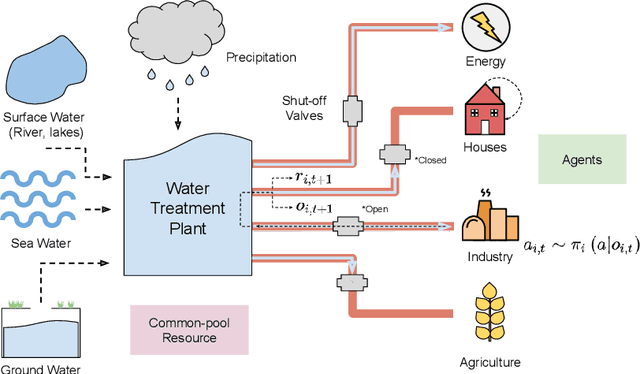
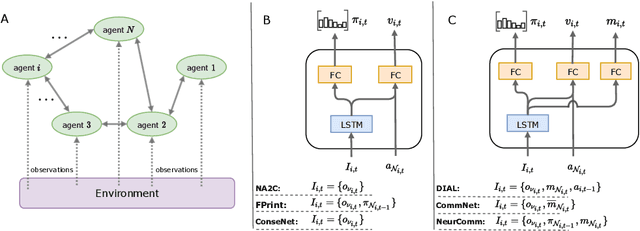
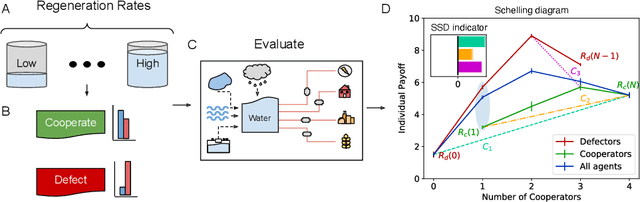
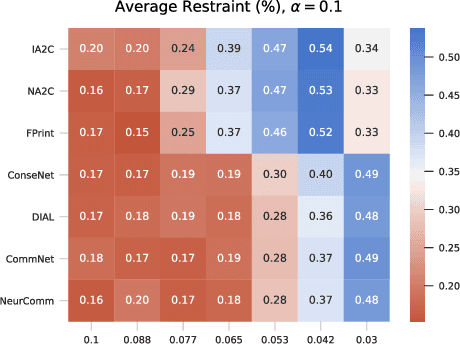
Multi-agent reinforcement learning has recently shown great promise as an approach to networked system control. Arguably, one of the most difficult and important tasks for which large scale networked system control is applicable is common-pool resource management. Crucial common-pool resources include arable land, fresh water, wetlands, wildlife, fish stock, forests and the atmosphere, of which proper management is related to some of society's greatest challenges such as food security, inequality and climate change. Here we take inspiration from a recent research program investigating the game-theoretic incentives of humans in social dilemma situations such as the well-known tragedy of the commons. However, instead of focusing on biologically evolved human-like agents, our concern is rather to better understand the learning and operating behaviour of engineered networked systems comprising general-purpose reinforcement learning agents, subject only to nonbiological constraints such as memory, computation and communication bandwidth. Harnessing tools from empirical game-theoretic analysis, we analyse the differences in resulting solution concepts that stem from employing different information structures in the design of networked multi-agent systems. These information structures pertain to the type of information shared between agents as well as the employed communication protocol and network topology. Our analysis contributes new insights into the consequences associated with certain design choices and provides an additional dimension of comparison between systems beyond efficiency, robustness, scalability and mean control performance.
Learning Compositional Neural Programs for Continuous Control
Jul 27, 2020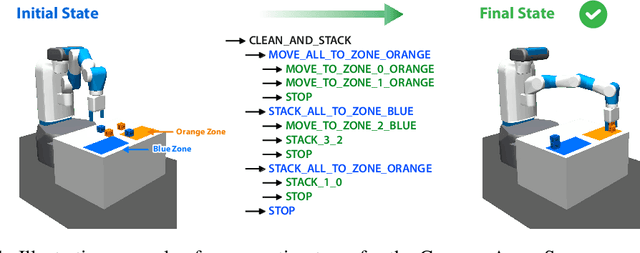

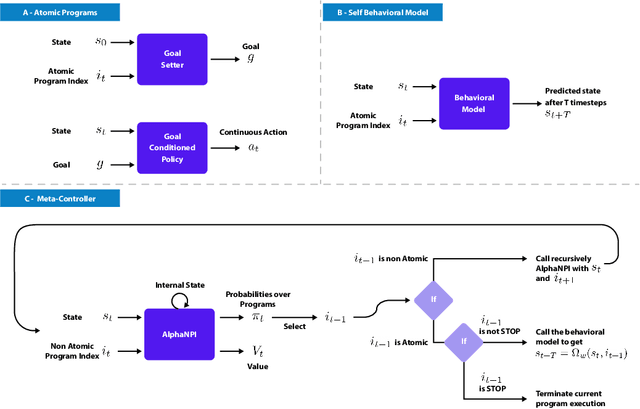
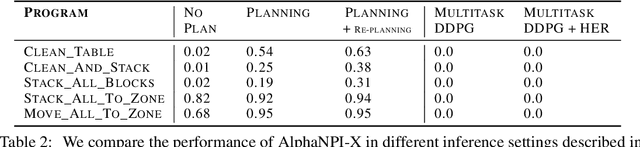
We propose a novel solution to challenging sparse-reward, continuous control problems that require hierarchical planning at multiple levels of abstraction. Our solution, dubbed AlphaNPI-X, involves three separate stages of learning. First, we use off-policy reinforcement learning algorithms with experience replay to learn a set of atomic goal-conditioned policies, which can be easily repurposed for many tasks. Second, we learn self-models describing the effect of the atomic policies on the environment. Third, the self-models are harnessed to learn recursive compositional programs with multiple levels of abstraction. The key insight is that the self-models enable planning by imagination, obviating the need for interaction with the world when learning higher-level compositional programs. To accomplish the third stage of learning, we extend the AlphaNPI algorithm, which applies AlphaZero to learn recursive neural programmer-interpreters. We empirically show that AlphaNPI-X can effectively learn to tackle challenging sparse manipulation tasks, such as stacking multiple blocks, where powerful model-free baselines fail.
Learning Compositional Neural Programs with Recursive Tree Search and Planning
May 30, 2019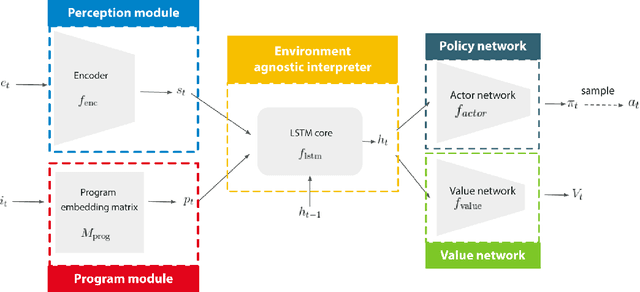
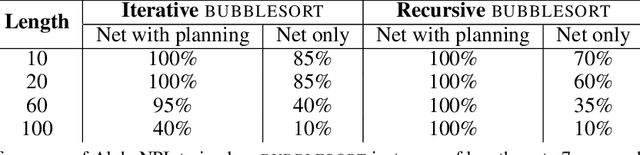
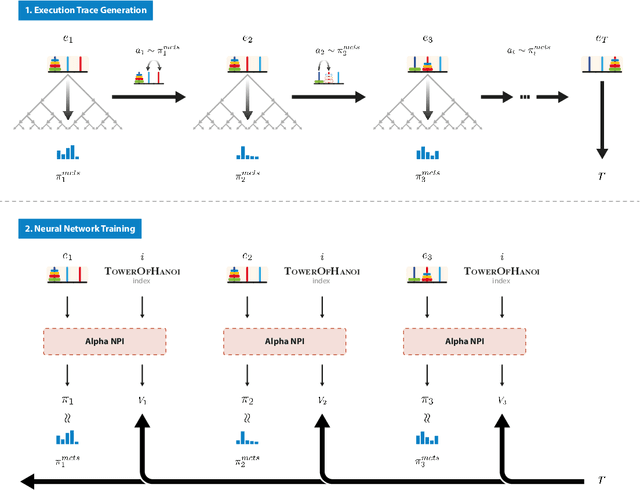

We propose a novel reinforcement learning algorithm, AlphaNPI, that incorporates the strengths of Neural Programmer-Interpreters (NPI) and AlphaZero. NPI contributes structural biases in the form of modularity, hierarchy and recursion, which are helpful to reduce sample complexity, improve generalization and increase interpretability. AlphaZero contributes powerful neural network guided search algorithms, which we augment with recursion. AlphaNPI only assumes a hierarchical program specification with sparse rewards: 1 when the program execution satisfies the specification, and 0 otherwise. Using this specification, AlphaNPI is able to train NPI models effectively with RL for the first time, completely eliminating the need for strong supervision in the form of execution traces. The experiments show that AlphaNPI can sort as well as previous strongly supervised NPI variants. The AlphaNPI agent is also trained on a Tower of Hanoi puzzle with two disks and is shown to generalize to puzzles with an arbitrary number of disk
Ranked Reward: Enabling Self-Play Reinforcement Learning for Combinatorial Optimization
Jul 06, 2018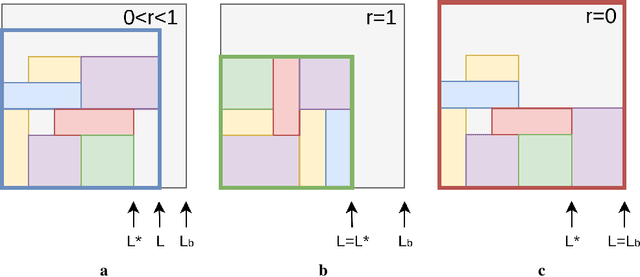
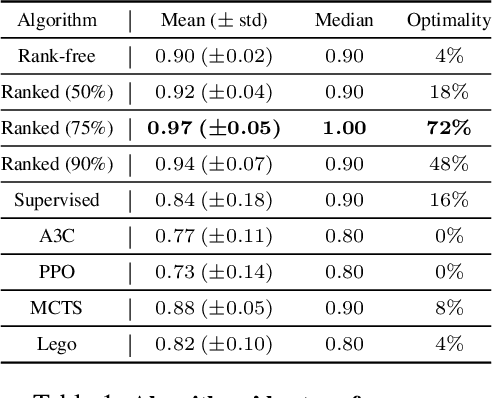
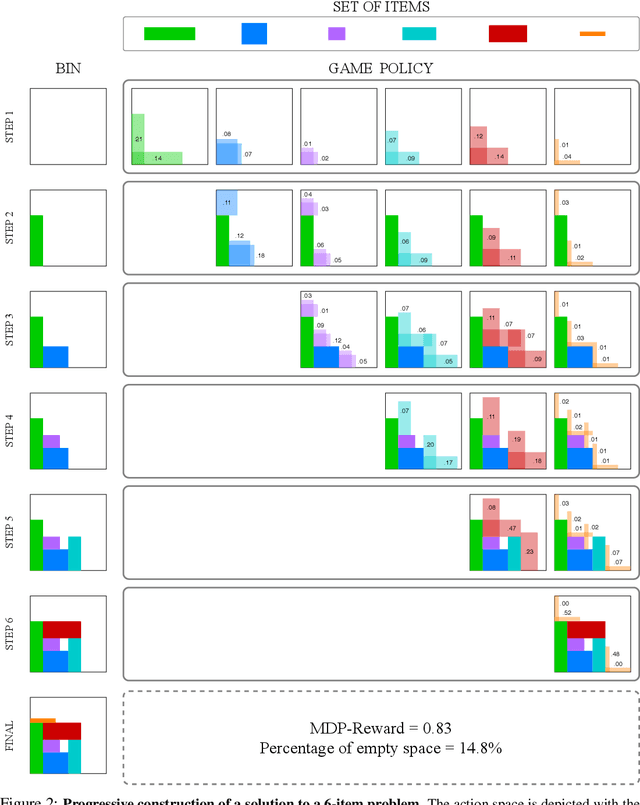
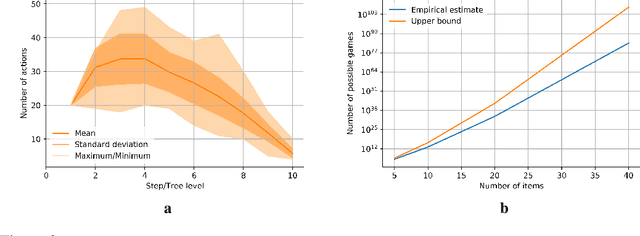
Adversarial self-play in two-player games has delivered impressive results when used with reinforcement learning algorithms that combine deep neural networks and tree search. Algorithms like AlphaZero and Expert Iteration learn tabula-rasa, producing highly informative training data on the fly. However, the self-play training strategy is not directly applicable to single-player games. Recently, several practically important combinatorial optimization problems, such as the traveling salesman problem and the bin packing problem, have been reformulated as reinforcement learning problems, increasing the importance of enabling the benefits of self-play beyond two-player games. We present the Ranked Reward (R2) algorithm which accomplishes this by ranking the rewards obtained by a single agent over multiple games to create a relative performance metric. Results from applying the R2 algorithm to instances of a two-dimensional bin packing problem show that it outperforms generic Monte Carlo tree search, heuristic algorithms and reinforcement learning algorithms not using ranked rewards.