 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Privacy Risks and Mitigations in Retrieval-Augmented Generation Systems
Jan 07, 2026The continued promise of Large Language Models (LLMs), particularly in their natural language understanding and generation capabilities, has driven a rapidly increasing interest in identifying and developing LLM use cases. In an effort to complement the ingrained "knowledge" of LLMs, Retrieval-Augmented Generation (RAG) techniques have become widely popular. At its core, RAG involves the coupling of LLMs with domain-specific knowledge bases, whereby the generation of a response to a user question is augmented with contextual and up-to-date information. The proliferation of RAG has sparked concerns about data privacy, particularly with the inherent risks that arise when leveraging databases with potentially sensitive information. Numerous recent works have explored various aspects of privacy risks in RAG systems, from adversarial attacks to proposed mitigations. With the goal of surveying and unifying these works, we ask one simple question: What are the privacy risks in RAG, and how can they be measured and mitigated? To answer this question, we conduct a systematic literature review of RAG works addressing privacy, and we systematize our findings into a comprehensive set of privacy risks, mitigation techniques, and evaluation strategies. We supplement these findings with two primary artifacts: a Taxonomy of RAG Privacy Risks and a RAG Privacy Process Diagram. Our work contributes to the study of privacy in RAG not only by conducting the first systematization of risks and mitigations, but also by uncovering important considerations when mitigating privacy risks in RAG systems and assessing the current maturity of proposed mitigations.
The Double-edged Sword of LLM-based Data Reconstruction: Understanding and Mitigating Contextual Vulnerability in Word-level Differential Privacy Text Sanitization
Aug 26, 2025



Differentially private text sanitization refers to the process of privatizing texts under the framework of Differential Privacy (DP), providing provable privacy guarantees while also empirically defending against adversaries seeking to harm privacy. Despite their simplicity, DP text sanitization methods operating at the word level exhibit a number of shortcomings, among them the tendency to leave contextual clues from the original texts due to randomization during sanitization $\unicode{x2013}$ this we refer to as $\textit{contextual vulnerability}$. Given the powerful contextual understanding and inference capabilities of Large Language Models (LLMs), we explore to what extent LLMs can be leveraged to exploit the contextual vulnerability of DP-sanitized texts. We expand on previous work not only in the use of advanced LLMs, but also in testing a broader range of sanitization mechanisms at various privacy levels. Our experiments uncover a double-edged sword effect of LLM-based data reconstruction attacks on privacy and utility: while LLMs can indeed infer original semantics and sometimes degrade empirical privacy protections, they can also be used for good, to improve the quality and privacy of DP-sanitized texts. Based on our findings, we propose recommendations for using LLM data reconstruction as a post-processing step, serving to increase privacy protection by thinking adversarially.
Investigating User Perspectives on Differentially Private Text Privatization
Mar 12, 2025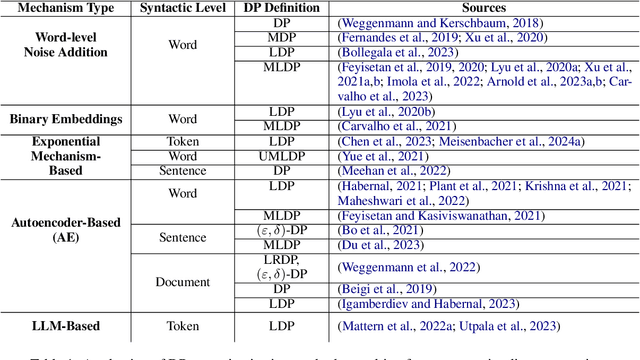
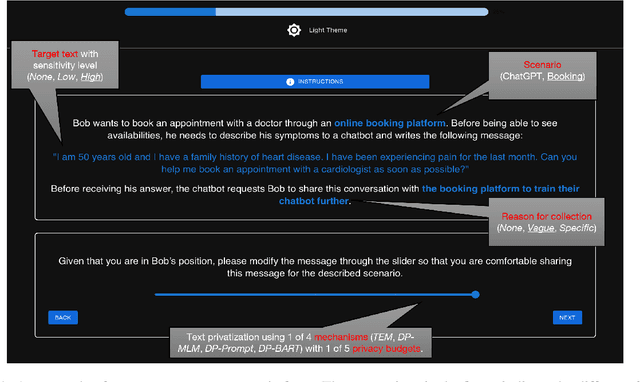


Recent literature has seen a considerable uptick in $\textit{Differentially Private Natural Language Processing}$ (DP NLP). This includes DP text privatization, where potentially sensitive input texts are transformed under DP to achieve privatized output texts that ideally mask sensitive information $\textit{and}$ maintain original semantics. Despite continued work to address the open challenges in DP text privatization, there remains a scarcity of work addressing user perceptions of this technology, a crucial aspect which serves as the final barrier to practical adoption. In this work, we conduct a survey study with 721 laypersons around the globe, investigating how the factors of $\textit{scenario}$, $\textit{data sensitivity}$, $\textit{mechanism type}$, and $\textit{reason for data collection}$ impact user preferences for text privatization. We learn that while all these factors play a role in influencing privacy decisions, users are highly sensitive to the utility and coherence of the private output texts. Our findings highlight the socio-technical factors that must be considered in the study of DP NLP, opening the door to further user-based investigations going forward.
Towards A Structured Overview of Use Cases for Natural Language Processing in the Legal Domain: A German Perspective
May 02, 2024



In recent years, the field of Legal Tech has risen in prevalence, as the Natural Language Processing (NLP) and legal disciplines have combined forces to digitalize legal processes. Amidst the steady flow of research solutions stemming from the NLP domain, the study of use cases has fallen behind, leading to a number of innovative technical methods without a place in practice. In this work, we aim to build a structured overview of Legal Tech use cases, grounded in NLP literature, but also supplemented by voices from legal practice in Germany. Based upon a Systematic Literature Review, we identify seven categories of NLP technologies for the legal domain, which are then studied in juxtaposition to 22 legal use cases. In the investigation of these use cases, we identify 15 ethical, legal, and social aspects (ELSA), shedding light on the potential concerns of digitally transforming the legal domain.
A Comparative Analysis of Word-Level Metric Differential Privacy: Benchmarking The Privacy-Utility Trade-off
Apr 04, 2024The application of Differential Privacy to Natural Language Processing techniques has emerged in relevance in recent years, with an increasing number of studies published in established NLP outlets. In particular, the adaptation of Differential Privacy for use in NLP tasks has first focused on the $\textit{word-level}$, where calibrated noise is added to word embedding vectors to achieve "noisy" representations. To this end, several implementations have appeared in the literature, each presenting an alternative method of achieving word-level Differential Privacy. Although each of these includes its own evaluation, no comparative analysis has been performed to investigate the performance of such methods relative to each other. In this work, we conduct such an analysis, comparing seven different algorithms on two NLP tasks with varying hyperparameters, including the $\textit{epsilon ($\varepsilon$)}$ parameter, or privacy budget. In addition, we provide an in-depth analysis of the results with a focus on the privacy-utility trade-off, as well as open-source our implementation code for further reproduction. As a result of our analysis, we give insight into the benefits and challenges of word-level Differential Privacy, and accordingly, we suggest concrete steps forward for the research field.