 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Error: a New Performance Measure for Adversarial Robustness
Jun 18, 2021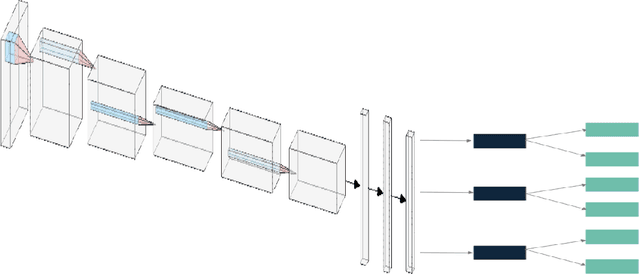
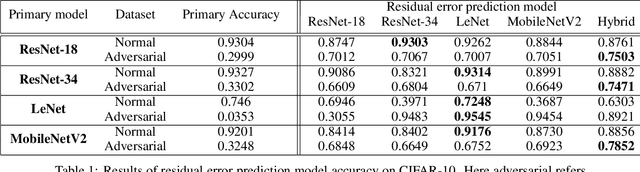
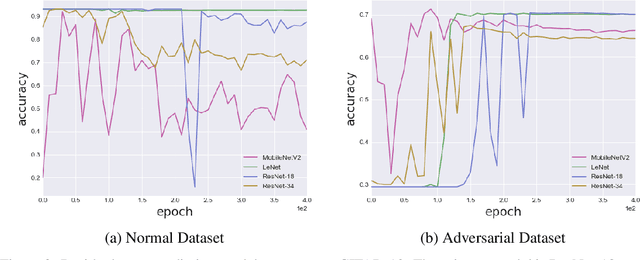
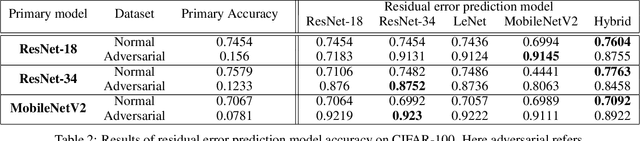
Despite the significant advances in deep learning over the past decade, a major challenge that limits the wide-spread adoption of deep learning has been their fragility to adversarial attacks. This sensitivity to making erroneous predictions in the presence of adversarially perturbed data makes deep neural networks difficult to adopt for certain real-world, mission-critical applications. While much of the research focus has revolved around adversarial example creation and adversarial hardening, the area of performance measures for assessing adversarial robustness is not well explored. Motivated by this, this study presents the concept of residual error, a new performance measure for not only assessing the adversarial robustness of a deep neural network at the individual sample level, but also can be used to differentiate between adversarial and non-adversarial examples to facilitate for adversarial example detection. Furthermore, we introduce a hybrid model for approximating the residual error in a tractable manner. Experimental results using the case of image classification demonstrates the effectiveness and efficacy of the proposed residual error metric for assessing several well-known deep neural network architectures. These results thus illustrate that the proposed measure could be a useful tool for not only assessing the robustness of deep neural networks used in mission-critical scenarios, but also in the design of adversarially robust models.
Insights into Data through Model Behaviour: An Explainability-driven Strategy for Data Auditing for Responsible Computer Vision Applications
Jun 16, 2021
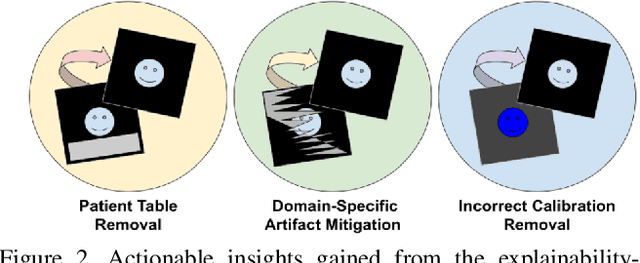
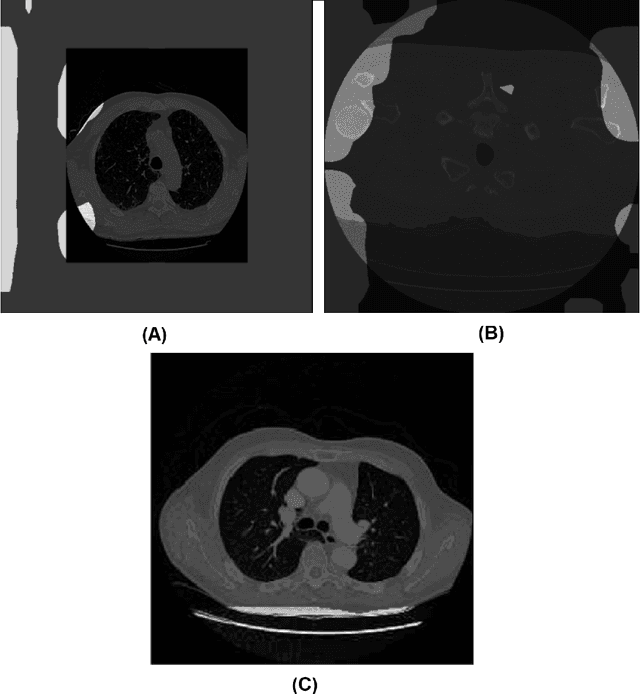
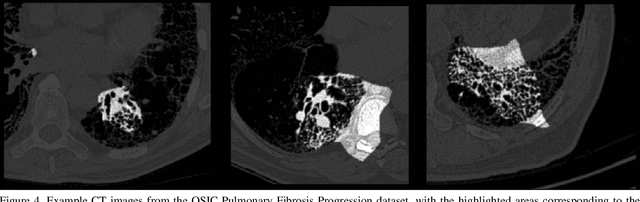
In this study, we take a departure and explore an explainability-driven strategy to data auditing, where actionable insights into the data at hand are discovered through the eyes of quantitative explainability on the behaviour of a dummy model prototype when exposed to data. We demonstrate this strategy by auditing two popular medical benchmark datasets, and discover hidden data quality issues that lead deep learning models to make predictions for the wrong reasons. The actionable insights gained from this explainability driven data auditing strategy is then leveraged to address the discovered issues to enable the creation of high-performing deep learning models with appropriate prediction behaviour. The hope is that such an explainability-driven strategy can be complimentary to data-driven strategies to facilitate for more responsible development of machine learning algorithms for computer vision applications.
DeepDarts: Modeling Keypoints as Objects for Automatic Scorekeeping in Darts using a Single Camera
May 20, 2021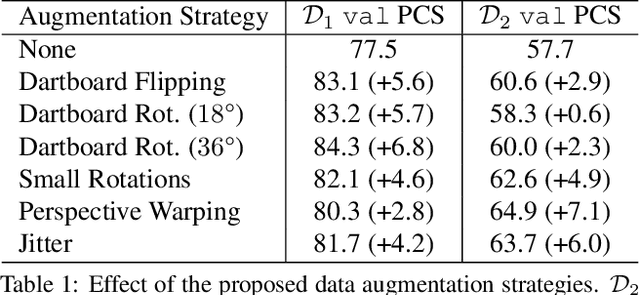


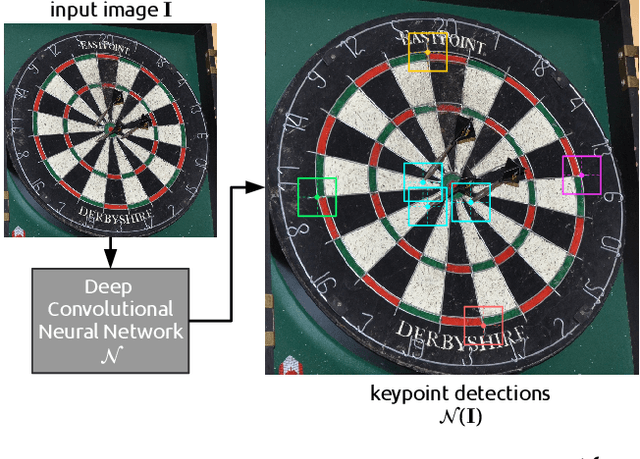
Existing multi-camera solutions for automatic scorekeeping in steel-tip darts are very expensive and thus inaccessible to most players. Motivated to develop a more accessible low-cost solution, we present a new approach to keypoint detection and apply it to predict dart scores from a single image taken from any camera angle. This problem involves detecting multiple keypoints that may be of the same class and positioned in close proximity to one another. The widely adopted framework for regressing keypoints using heatmaps is not well-suited for this task. To address this issue, we instead propose to model keypoints as objects. We develop a deep convolutional neural network around this idea and use it to predict dart locations and dartboard calibration points within an overall pipeline for automatic dart scoring, which we call DeepDarts. Additionally, we propose several task-specific data augmentation strategies to improve the generalization of our method. As a proof of concept, two datasets comprising 16k images originating from two different dartboard setups were manually collected and annotated to evaluate the system. In the primary dataset containing 15k images captured from a face-on view of the dartboard using a smartphone, DeepDarts predicted the total score correctly in 94.7% of the test images. In a second more challenging dataset containing limited training data (830 images) and various camera angles, we utilize transfer learning and extensive data augmentation to achieve a test accuracy of 84.0%. Because DeepDarts relies only on single images, it has the potential to be deployed on edge devices, giving anyone with a smartphone access to an automatic dart scoring system for steel-tip darts. The code and datasets are available.
COVID-Net CXR-2: An Enhanced Deep Convolutional Neural Network Design for Detection of COVID-19 Cases from Chest X-ray Images
May 14, 2021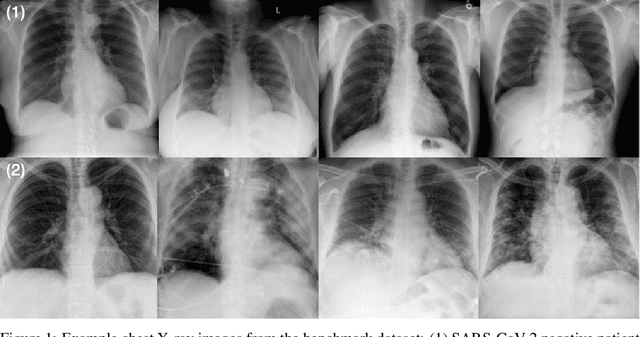
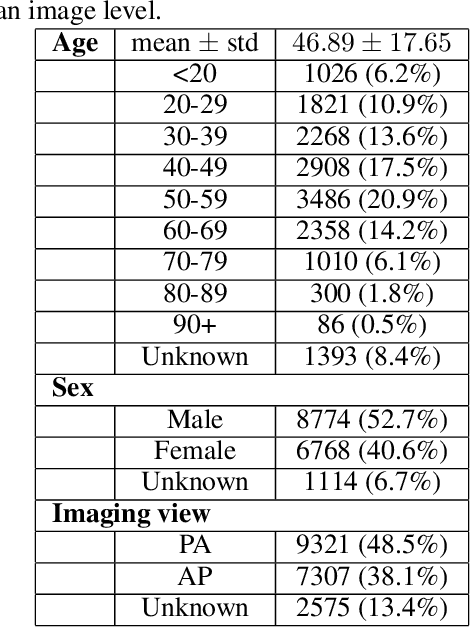
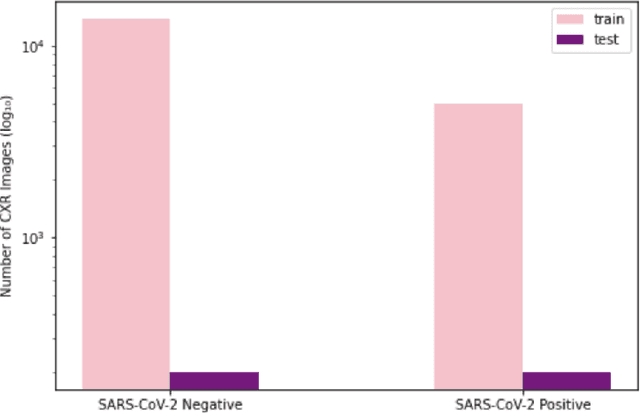
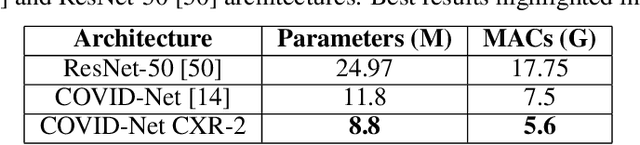
As the COVID-19 pandemic continues to devastate globally, the use of chest X-ray (CXR) imaging as a complimentary screening strategy to RT-PCR testing continues to grow given its routine clinical use for respiratory complaint. As part of the COVID-Net open source initiative, we introduce COVID-Net CXR-2, an enhanced deep convolutional neural network design for COVID-19 detection from CXR images built using a greater quantity and diversity of patients than the original COVID-Net. To facilitate this, we also introduce a new benchmark dataset composed of 19,203 CXR images from a multinational cohort of 16,656 patients from at least 51 countries, making it the largest, most diverse COVID-19 CXR dataset in open access form. The COVID-Net CXR-2 network achieves sensitivity and positive predictive value of 95.5%/97.0%, respectively, and was audited in a transparent and responsible manner. Explainability-driven performance validation was used during auditing to gain deeper insights in its decision-making behaviour and to ensure clinically relevant factors are leveraged for improving trust in its usage. Radiologist validation was also conducted, where select cases were reviewed and reported on by two board-certified radiologists with over 10 and 19 years of experience, respectively, and showed that the critical factors leveraged by COVID-Net CXR-2 are consistent with radiologist interpretations. While not a production-ready solution, we hope the open-source, open-access release of COVID-Net CXR-2 and the respective CXR benchmark dataset will encourage researchers, clinical scientists, and citizen scientists to accelerate advancements and innovations in the fight against the pandemic.
COVID-19 Detection from Chest X-ray Images using Imprinted Weights Approach
May 04, 2021
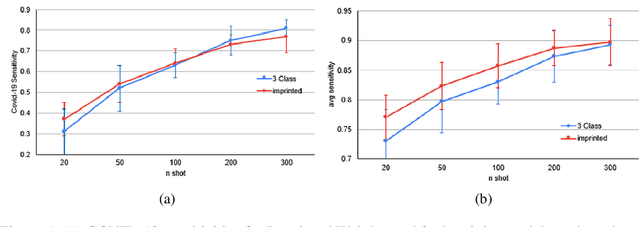
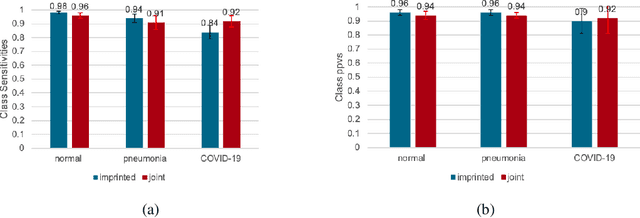
The COVID-19 pandemic has had devastating effects on the well-being of the global population. The pandemic has been so prominent partly due to the high infection rate of the virus and its variants. In response, one of the most effective ways to stop infection is rapid diagnosis. The main-stream screening method, reverse transcription-polymerase chain reaction (RT-PCR), is time-consuming, laborious and in short supply. Chest radiography is an alternative screening method for the COVID-19 and computer-aided diagnosis (CAD) has proven to be a viable solution at low cost and with fast speed; however, one of the challenges in training the CAD models is the limited number of training data, especially at the onset of the pandemic. This becomes outstanding precisely when the quick and cheap type of diagnosis is critically needed for flattening the infection curve. To address this challenge, we propose the use of a low-shot learning approach named imprinted weights, taking advantage of the abundance of samples from known illnesses such as pneumonia to improve the detection performance on COVID-19.
COVID-Net CT-S: 3D Convolutional Neural Network Architectures for COVID-19 Severity Assessment using Chest CT Images
May 04, 2021

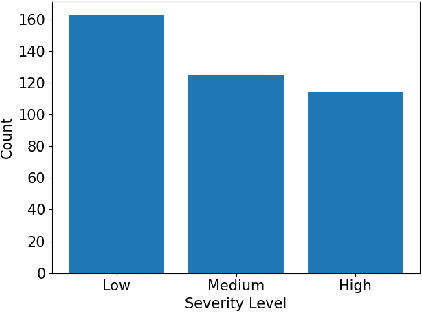
The health and socioeconomic difficulties caused by the COVID-19 pandemic continues to cause enormous tensions around the world. In particular, this extraordinary surge in the number of cases has put considerable strain on health care systems around the world. A critical step in the treatment and management of COVID-19 positive patients is severity assessment, which is challenging even for expert radiologists given the subtleties at different stages of lung disease severity. Motivated by this challenge, we introduce COVID-Net CT-S, a suite of deep convolutional neural networks for predicting lung disease severity due to COVID-19 infection. More specifically, a 3D residual architecture design is leveraged to learn volumetric visual indicators characterizing the degree of COVID-19 lung disease severity. Experimental results using the patient cohort collected by the China National Center for Bioinformation (CNCB) showed that the proposed COVID-Net CT-S networks, by leveraging volumetric features, can achieve significantly improved severity assessment performance when compared to traditional severity assessment networks that learn and leverage 2D visual features to characterize COVID-19 severity.
COVID-Net CXR-S: Deep Convolutional Neural Network for Severity Assessment of COVID-19 Cases from Chest X-ray Images
May 01, 2021
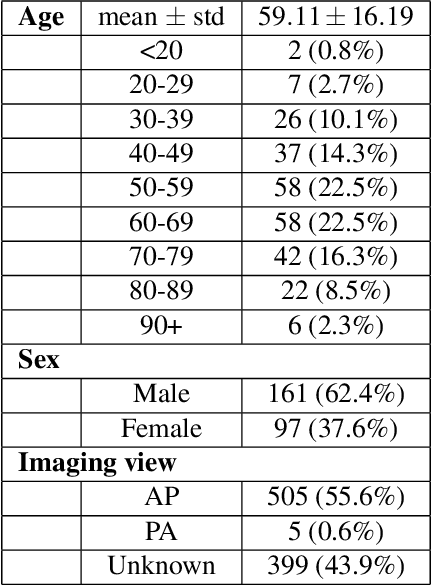
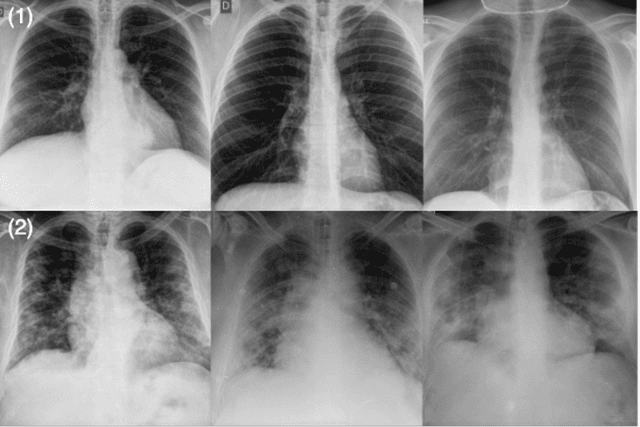
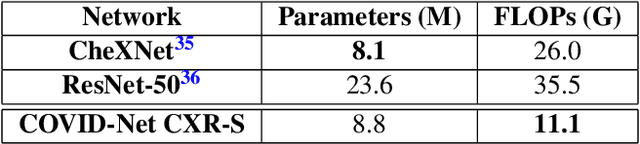
The world is still struggling in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. The medical conditions associated with SARS-CoV-2 infections have resulted in a surge in the number of patients at clinics and hospitals, leading to a significantly increased strain on healthcare resources. As such, an important part of managing and handling patients with SARS-CoV-2 infections within the clinical workflow is severity assessment, which is often conducted with the use of chest x-ray (CXR) images. In this work, we introduce COVID-Net CXR-S, a convolutional neural network for predicting the airspace severity of a SARS-CoV-2 positive patient based on a CXR image of the patient's chest. More specifically, we leveraged transfer learning to transfer representational knowledge gained from over 16,000 CXR images from a multinational cohort of over 15,000 patient cases into a custom network architecture for severity assessment. Experimental results with a multi-national patient cohort curated by the Radiological Society of North America (RSNA) RICORD initiative showed that the proposed COVID-Net CXR-S has potential to be a powerful tool for computer-aided severity assessment of CXR images of COVID-19 positive patients. Furthermore, radiologist validation on select cases by two board-certified radiologists with over 10 and 19 years of experience, respectively, showed consistency between radiologist interpretation and critical factors leveraged by COVID-Net CXR-S for severity assessment. While not a production-ready solution, the ultimate goal for the open source release of COVID-Net CXR-S is to act as a catalyst for clinical scientists, machine learning researchers, as well as citizen scientists to develop innovative new clinical decision support solutions for helping clinicians around the world manage the continuing pandemic.
AttendSeg: A Tiny Attention Condenser Neural Network for Semantic Segmentation on the Edge
Apr 29, 2021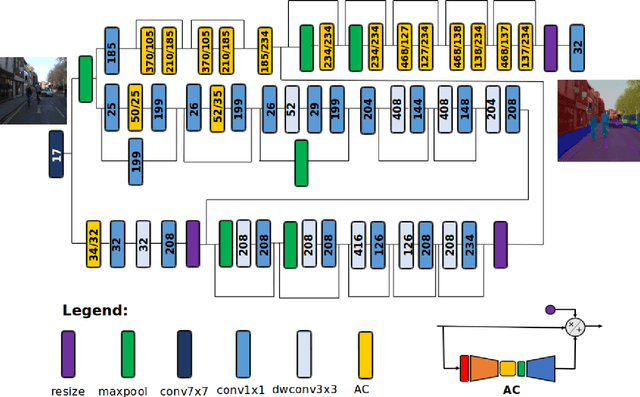


In this study, we introduce \textbf{AttendSeg}, a low-precision, highly compact deep neural network tailored for on-device semantic segmentation. AttendSeg possesses a self-attention network architecture comprising of light-weight attention condensers for improved spatial-channel selective attention at a very low complexity. The unique macro-architecture and micro-architecture design properties of AttendSeg strike a strong balance between representational power and efficiency, achieved via a machine-driven design exploration strategy tailored specifically for the task at hand. Experimental results demonstrated that the proposed AttendSeg can achieve segmentation accuracy comparable to much larger deep neural networks with greater complexity while possessing a significantly lower architecture and computational complexity (requiring as much as >27x fewer MACs, >72x fewer parameters, and >288x lower weight memory requirements), making it well-suited for TinyML applications on the edge.
Do All MobileNets Quantize Poorly? Gaining Insights into the Effect of Quantization on Depthwise Separable Convolutional Networks Through the Eyes of Multi-scale Distributional Dynamics
Apr 24, 2021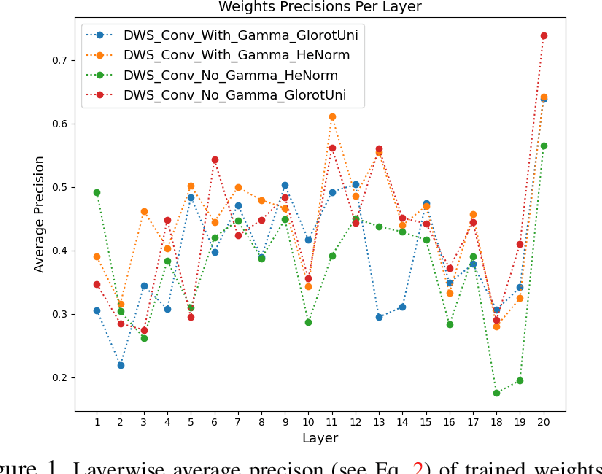
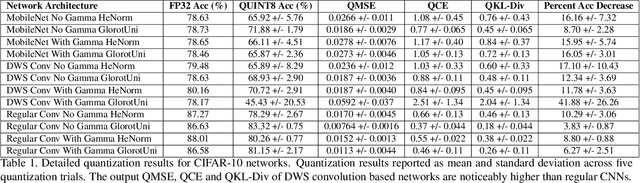
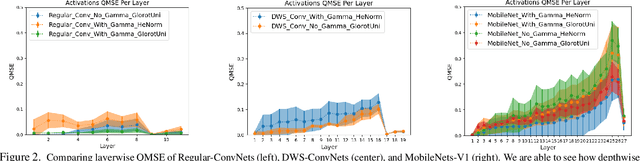

As the "Mobile AI" revolution continues to grow, so does the need to understand the behaviour of edge-deployed deep neural networks. In particular, MobileNets are the go-to family of deep convolutional neural networks (CNN) for mobile. However, they often have significant accuracy degradation under post-training quantization. While studies have introduced quantization-aware training and other methods to tackle this challenge, there is limited understanding into why MobileNets (and potentially depthwise-separable CNNs (DWSCNN) in general) quantize so poorly compared to other CNN architectures. Motivated to gain deeper insights into this phenomenon, we take a different strategy and study the multi-scale distributional dynamics of MobileNet-V1, a set of smaller DWSCNNs, and regular CNNs. Specifically, we investigate the impact of quantization on the weight and activation distributional dynamics as information propagates from layer to layer, as well as overall changes in distributional dynamics at the network level. This fine-grained analysis revealed significant dynamic range fluctuations and a "distributional mismatch" between channelwise and layerwise distributions in DWSCNNs that lead to increasing quantized degradation and distributional shift during information propagation. Furthermore, analysis of the activation quantization errors show that there is greater quantization error accumulation in DWSCNN compared to regular CNNs. The hope is that such insights can lead to innovative strategies for reducing such distributional dynamics changes and improve post-training quantization for mobile.
Localization of Ice-Rink for Broadcast Hockey Videos
Apr 22, 2021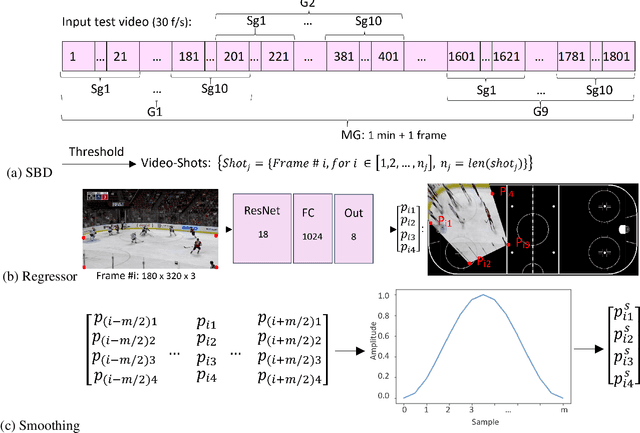
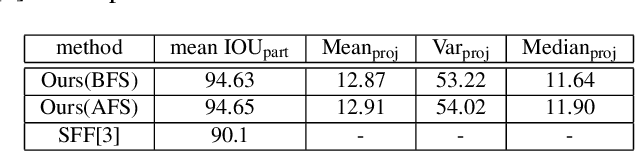
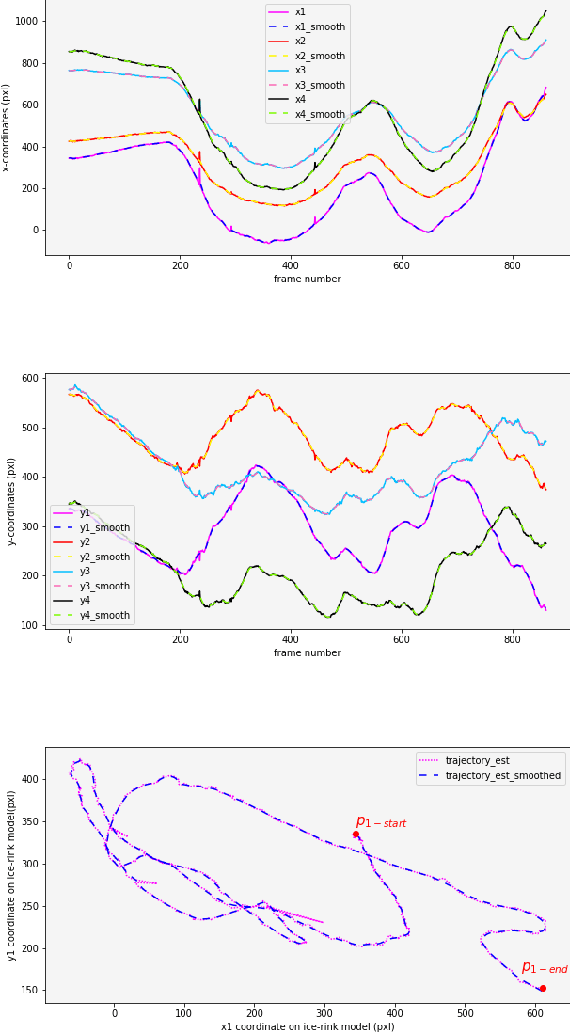
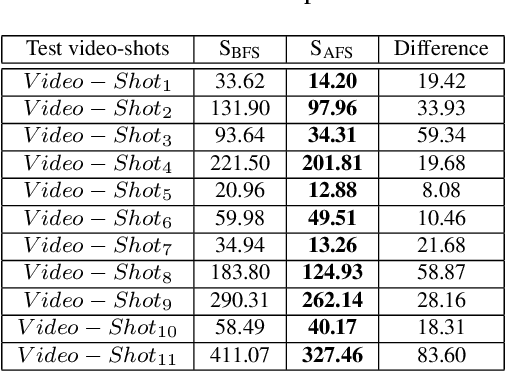
In this work, an automatic and simple framework for hockey ice-rink localization from broadcast videos is introduced. First, video is broken into video-shots by a hierarchical partitioning of the video frames, and thresholding based on their histograms. To localize the frames on the ice-rink model, a ResNet18-based regressor is implemented and trained, which regresses to four control points on the model in a frame-by-frame fashion. This leads to the projection jittering problem in the video. To overcome this, in the inference phase, the trajectory of the control points on the ice-rink model are smoothed, for all the consecutive frames of a given video-shot, by convolving a Hann window with the achieved coordinates. Finally, the smoothed homography matrix is computed by using the direct linear transform on the four pairs of corresponding points. A hockey dataset for training and testing the regressor is gathered. The results show success of this simple and comprehensive procedure for localizing the hockey ice-rink and addressing the problem of jittering without affecting the accuracy of homography estimation.