 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Visual to Multimodal: Systematic Ablation of Encoders and Fusion Strategies in Animal Identification
Feb 28, 2026Automated animal identification is a practical task for reuniting lost pets with their owners, yet current systems often struggle due to limited dataset scale and reliance on unimodal visual cues. This study introduces a multimodal verification framework that enhances visual features with semantic identity priors derived from synthetic textual descriptions. We constructed a massive training corpus of 1.9 million photographs covering 695,091~unique animals to support this investigation. Through systematic ablation studies, we identified SigLIP2-Giant and E5-Small-v2 as the optimal vision and text backbones. We further evaluated fusion strategies ranging from simple concatenation to adaptive gating to determine the best method for integrating these modalities. Our proposed approach utilizes a gated fusion mechanism and achieved a Top-1 accuracy of 84.28\% and an Equal Error Rate of 0.0422 on a comprehensive test protocol. These results represent an 11\% improvement over leading unimodal baselines and demonstrate that integrating synthesized semantic descriptions significantly refines decision boundaries in large-scale pet re-identification.
* Published at MDPI Journal of Imaging (see at https://www.mdpi.com/2313-433X/12/1/30)
LightAutoML: AutoML Solution for a Large Financial Services Ecosystem
Sep 03, 2021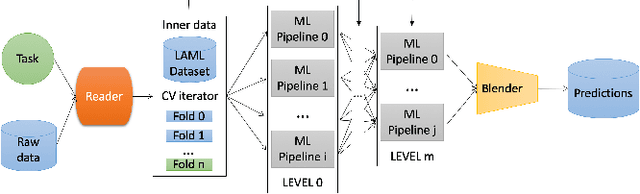


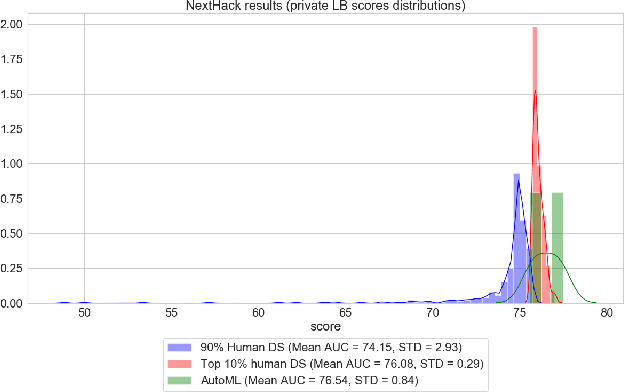
We present an AutoML system called LightAutoML developed for a large European financial services company and its ecosystem satisfying the set of idiosyncratic requirements that this ecosystem has for AutoML solutions. Our framework was piloted and deployed in numerous applications and performed at the level of the experienced data scientists while building high-quality ML models significantly faster than these data scientists. We also compare the performance of our system with various general-purpose open source AutoML solutions and show that it performs better for most of the ecosystem and OpenML problems. We also present the lessons that we learned while developing the AutoML system and moving it into production.