 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Informational Space Based Semantic Analysis for Scientific Texts
May 31, 2022
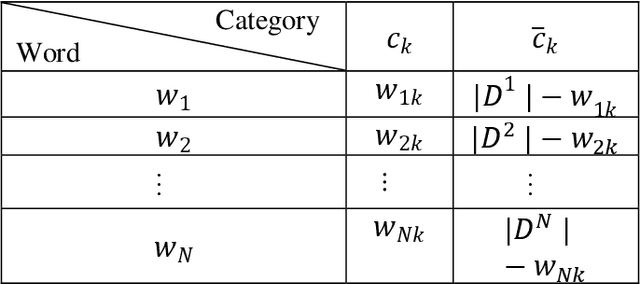
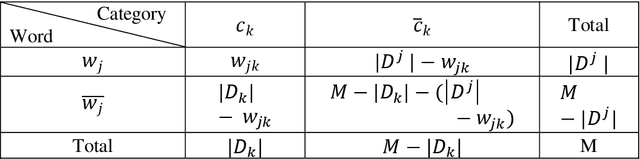
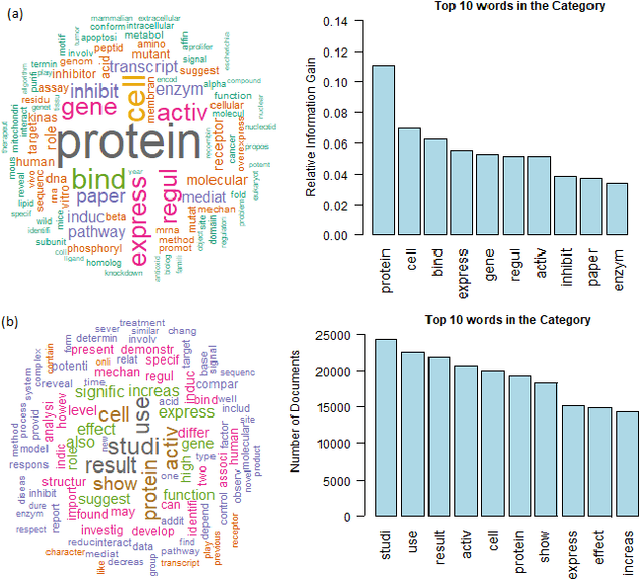
One major problem in Natural Language Processing is the automatic analysis and representation of human language. Human language is ambiguous and deeper understanding of semantics and creating human-to-machine interaction have required an effort in creating the schemes for act of communication and building common-sense knowledge bases for the 'meaning' in texts. This paper introduces computational methods for semantic analysis and the quantifying the meaning of short scientific texts. Computational methods extracting semantic feature are used to analyse the relations between texts of messages and 'representations of situations' for a newly created large collection of scientific texts, Leicester Scientific Corpus. The representation of scientific-specific meaning is standardised by replacing the situation representations, rather than psychological properties, with the vectors of some attributes: a list of scientific subject categories that the text belongs to. First, this paper introduces 'Meaning Space' in which the informational representation of the meaning is extracted from the occurrence of the word in texts across the scientific categories, i.e., the meaning of a word is represented by a vector of Relative Information Gain about the subject categories. Then, the meaning space is statistically analysed for Leicester Scientific Dictionary-Core and we investigate 'Principal Components of the Meaning' to describe the adequate dimensions of the meaning. The research in this paper conducts the base for the geometric representation of the meaning of texts.
* 19 pages. arXiv admin note: substantial text overlap with arXiv:2009.08859, arXiv:2004.13717
Learning from few examples with nonlinear feature maps
Mar 31, 2022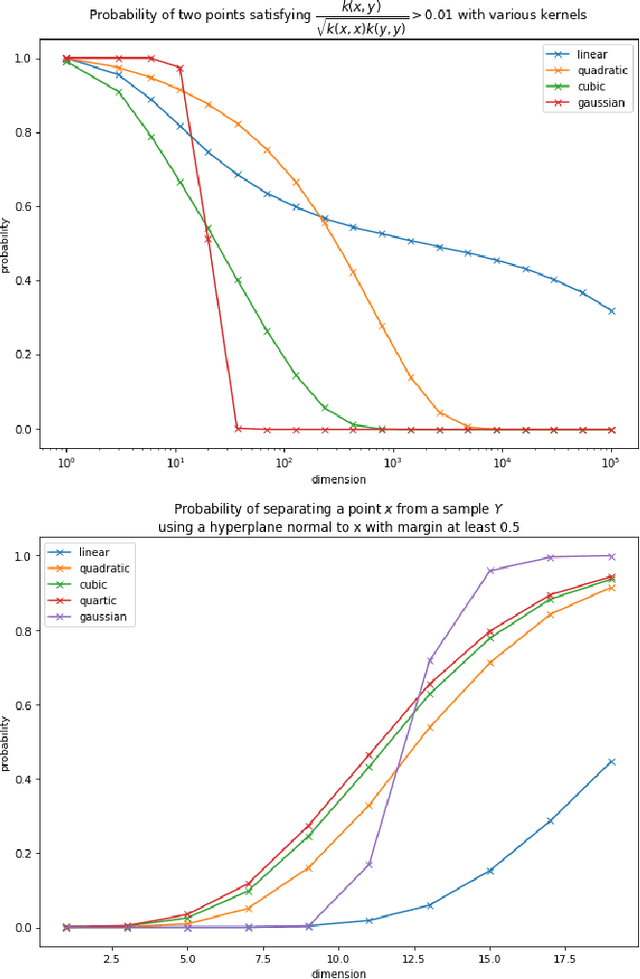
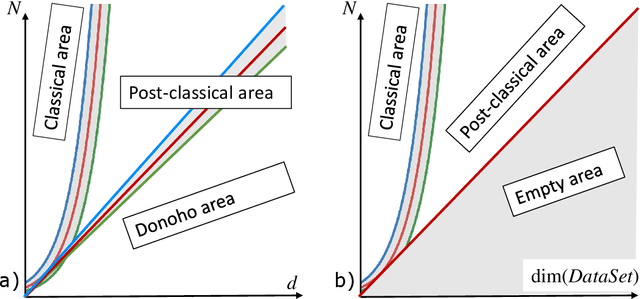
In this work we consider the problem of data classification in post-classical settings were the number of training examples consists of mere few data points. We explore the phenomenon and reveal key relationships between dimensionality of AI model's feature space, non-degeneracy of data distributions, and the model's generalisation capabilities. The main thrust of our present analysis is on the influence of nonlinear feature transformations mapping original data into higher- and possibly infinite-dimensional spaces on the resulting model's generalisation capabilities. Subject to appropriate assumptions, we establish new relationships between intrinsic dimensions of the transformed data and the probabilities to learn successfully from few presentations.
Quasi-orthogonality and intrinsic dimensions as measures of learning and generalisation
Mar 30, 2022
Finding best architectures of learning machines, such as deep neural networks, is a well-known technical and theoretical challenge. Recent work by Mellor et al (2021) showed that there may exist correlations between the accuracies of trained networks and the values of some easily computable measures defined on randomly initialised networks which may enable to search tens of thousands of neural architectures without training. Mellor et al used the Hamming distance evaluated over all ReLU neurons as such a measure. Motivated by these findings, in our work, we ask the question of the existence of other and perhaps more principled measures which could be used as determinants of success of a given neural architecture. In particular, we examine, if the dimensionality and quasi-orthogonality of neural networks' feature space could be correlated with the network's performance after training. We showed, using the setup as in Mellor et al, that dimensionality and quasi-orthogonality may jointly serve as network's performance discriminants. In addition to offering new opportunities to accelerate neural architecture search, our findings suggest important relationships between the networks' final performance and properties of their randomly initialised feature spaces: data dimension and quasi-orthogonality.
Scikit-dimension: a Python package for intrinsic dimension estimation
Sep 06, 2021
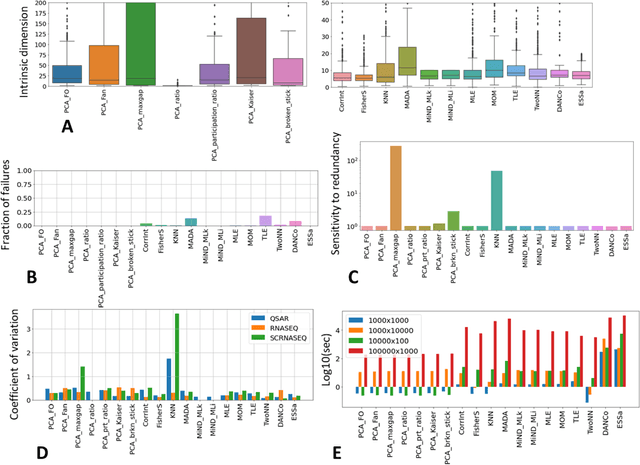
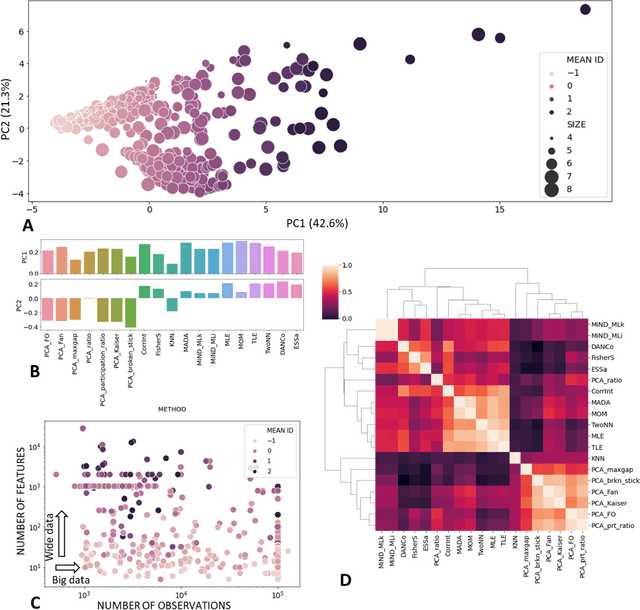
Dealing with uncertainty in applications of machine learning to real-life data critically depends on the knowledge of intrinsic dimensionality (ID). A number of methods have been suggested for the purpose of estimating ID, but no standard package to easily apply them one by one or all at once has been implemented in Python. This technical note introduces \texttt{scikit-dimension}, an open-source Python package for intrinsic dimension estimation. \texttt{scikit-dimension} package provides a uniform implementation of most of the known ID estimators based on scikit-learn application programming interface to evaluate global and local intrinsic dimension, as well as generators of synthetic toy and benchmark datasets widespread in the literature. The package is developed with tools assessing the code quality, coverage, unit testing and continuous integration. We briefly describe the package and demonstrate its use in a large-scale (more than 500 datasets) benchmarking of methods for ID estimation in real-life and synthetic data. The source code is available from https://github.com/j-bac/scikit-dimension , the documentation is available from https://scikit-dimension.readthedocs.io .
High-dimensional separability for one- and few-shot learning
Jun 28, 2021
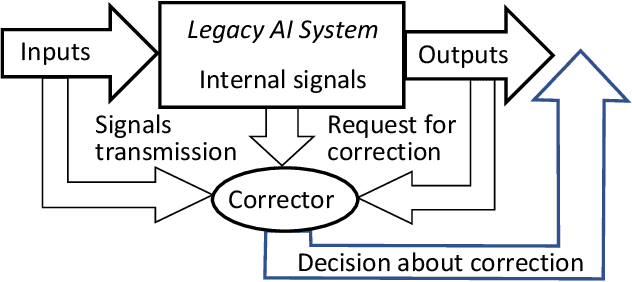
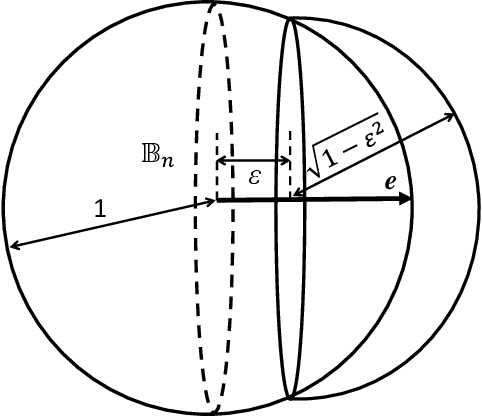
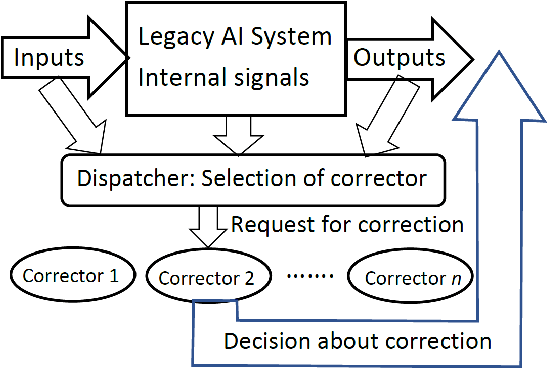
This work is driven by a practical question, corrections of Artificial Intelligence (AI) errors. Systematic re-training of a large AI system is hardly possible. To solve this problem, special external devices, correctors, are developed. They should provide quick and non-iterative system fix without modification of a legacy AI system. A common universal part of the AI corrector is a classifier that should separate undesired and erroneous behavior from normal operation. Training of such classifiers is a grand challenge at the heart of the one- and few-shot learning methods. Effectiveness of one- and few-short methods is based on either significant dimensionality reductions or the blessing of dimensionality effects. Stochastic separability is a blessing of dimensionality phenomenon that allows one-and few-shot error correction: in high-dimensional datasets under broad assumptions each point can be separated from the rest of the set by simple and robust linear discriminant. The hierarchical structure of data universe is introduced where each data cluster has a granular internal structure, etc. New stochastic separation theorems for the data distributions with fine-grained structure are formulated and proved. Separation theorems in infinite-dimensional limits are proven under assumptions of compact embedding of patterns into data space. New multi-correctors of AI systems are presented and illustrated with examples of predicting errors and learning new classes of objects by a deep convolutional neural network.
The Feasibility and Inevitability of Stealth Attacks
Jun 26, 2021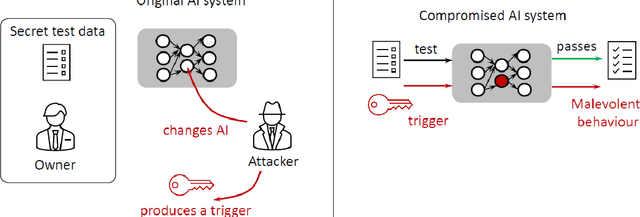
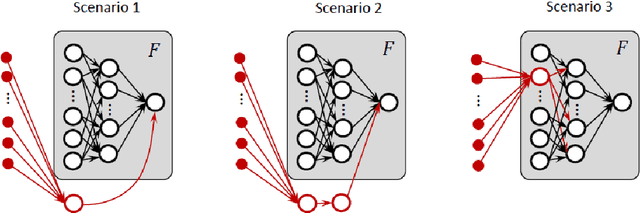
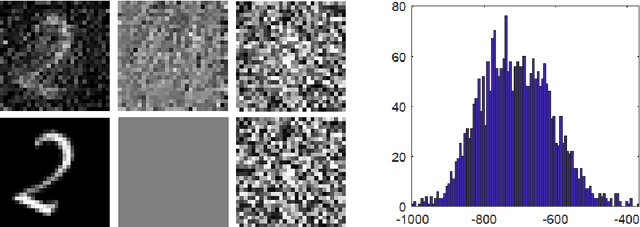
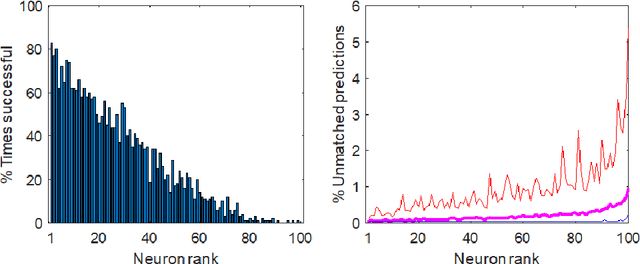
We develop and study new adversarial perturbations that enable an attacker to gain control over decisions in generic Artificial Intelligence (AI) systems including deep learning neural networks. In contrast to adversarial data modification, the attack mechanism we consider here involves alterations to the AI system itself. Such a stealth attack could be conducted by a mischievous, corrupt or disgruntled member of a software development team. It could also be made by those wishing to exploit a "democratization of AI" agenda, where network architectures and trained parameter sets are shared publicly. Building on work by [Tyukin et al., International Joint Conference on Neural Networks, 2020], we develop a range of new implementable attack strategies with accompanying analysis, showing that with high probability a stealth attack can be made transparent, in the sense that system performance is unchanged on a fixed validation set which is unknown to the attacker, while evoking any desired output on a trigger input of interest. The attacker only needs to have estimates of the size of the validation set and the spread of the AI's relevant latent space. In the case of deep learning neural networks, we show that a one neuron attack is possible - a modification to the weights and bias associated with a single neuron - revealing a vulnerability arising from over-parameterization. We illustrate these concepts in a realistic setting. Guided by the theory and computational results, we also propose strategies to guard against stealth attacks.
Demystification of Few-shot and One-shot Learning
Apr 25, 2021
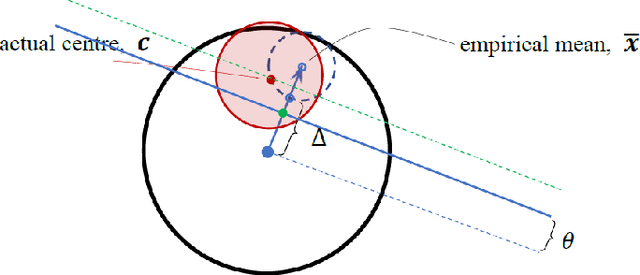
Few-shot and one-shot learning have been the subject of active and intensive research in recent years, with mounting evidence pointing to successful implementation and exploitation of few-shot learning algorithms in practice. Classical statistical learning theories do not fully explain why few- or one-shot learning is at all possible since traditional generalisation bounds normally require large training and testing samples to be meaningful. This sharply contrasts with numerous examples of successful one- and few-shot learning systems and applications. In this work we present mathematical foundations for a theory of one-shot and few-shot learning and reveal conditions specifying when such learning schemes are likely to succeed. Our theory is based on intrinsic properties of high-dimensional spaces. We show that if the ambient or latent decision space of a learning machine is sufficiently high-dimensional than a large class of objects in this space can indeed be easily learned from few examples provided that certain data non-concentration conditions are met.
General stochastic separation theorems with optimal bounds
Oct 11, 2020
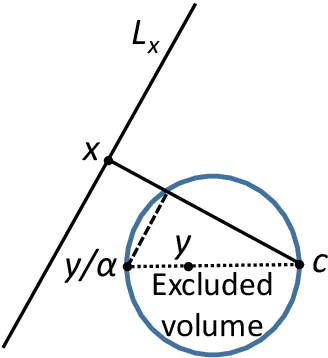
Phenomenon of stochastic separability was revealed and used in machine learning to correct errors of Artificial Intelligence (AI) systems and analyze AI instabilities. In high-dimensional datasets under broad assumptions each point can be separated from the rest of the set by simple and robust Fisher's discriminant (is Fisher separable). Errors or clusters of errors can be separated from the rest of the data. The ability to correct an AI system also opens up the possibility of an attack on it, and the high dimensionality induces vulnerabilities caused by the same stochastic separability that holds the keys to understanding the fundamentals of robustness and adaptivity in high-dimensional data-driven AI. To manage errors and analyze vulnerabilities, the stochastic separation theorems should evaluate the probability that the dataset will be Fisher separable in given dimensionality and for a given class of distributions. Explicit and optimal estimates of these separation probabilities are required, and this problem is solved in present work. The general stochastic separation theorems with optimal probability estimates are obtained for important classes of distributions: log-concave distribution, their convex combinations and product distributions. The standard i.i.d. assumption was significantly relaxed. These theorems and estimates can be used both for correction of high-dimensional data driven AI systems and for analysis of their vulnerabilities. The third area of application is the emergence of memories in ensembles of neurons, the phenomena of grandmother's cells and sparse coding in the brain, and explanation of unexpected effectiveness of small neural ensembles in high-dimensional brain.
Trajectories, bifurcations and pseudotime in large clinical datasets: applications to myocardial infarction and diabetes data
Jul 07, 2020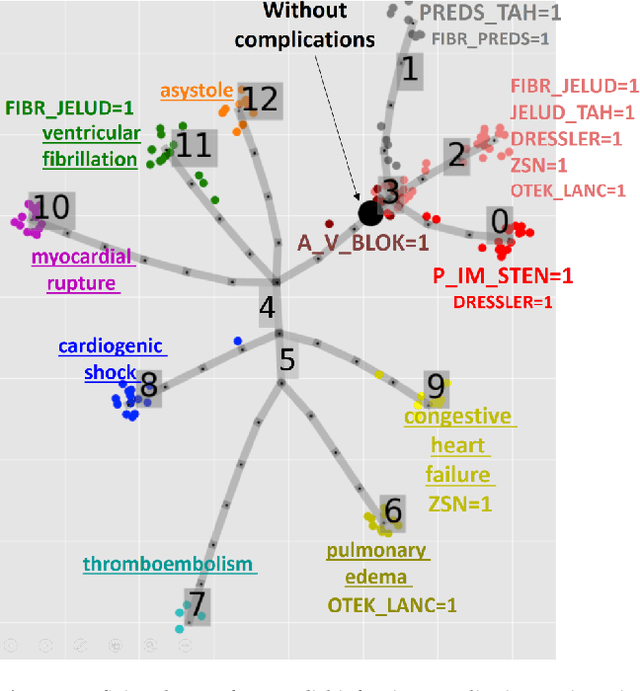
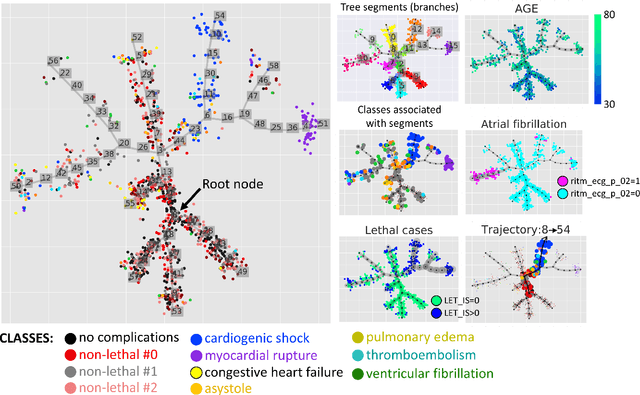
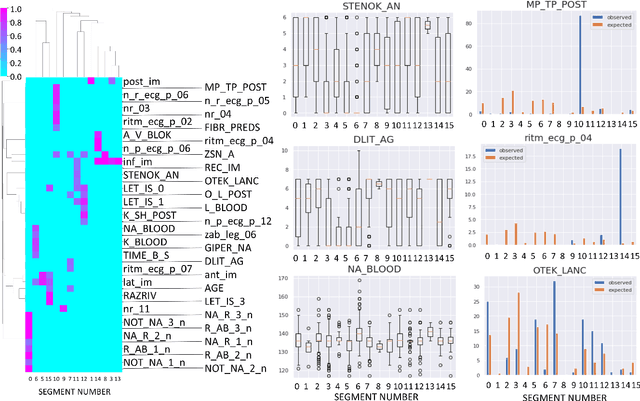
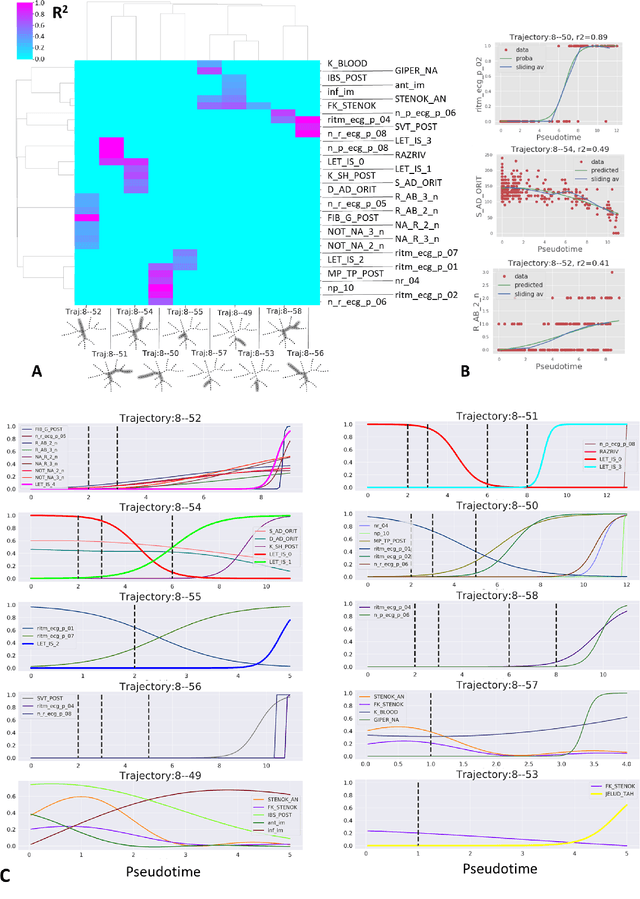
Large observational clinical datasets become increasingly available for mining associations between various disease traits and administered therapy. These datasets can be considered as representations of the landscape of all possible disease conditions, in which a concrete pathology develops through a number of stereotypical routes, characterized by `points of no return' and `final states' (such as lethal or recovery states). Extracting this information directly from the data remains challenging, especially in the case of synchronic (with a short-term follow up) observations. Here we suggest a semi-supervised methodology for the analysis of large clinical datasets, characterized by mixed data types and missing values, through modeling the geometrical data structure as a bouquet of bifurcating clinical trajectories. The methodology is based on application of elastic principal graphs which can address simultaneously the tasks of dimensionality reduction, data visualization, clustering, feature selection and quantifying the geodesic distances (pseudotime) in partially ordered sequences of observations. The methodology allows positioning a patient on a particular clinical trajectory (pathological scenario) and characterizing the degree of progression along it with a qualitative estimate of the uncertainty of the prognosis. Overall, our pseudo-time quantification-based approach gives a possibility to apply the methods developed for dynamical disease phenotyping and illness trajectory analysis (diachronic data analysis) to synchronic observational data. We developed a tool $ClinTrajan$ for clinical trajectory analysis implemented in Python programming language. We test the methodology in two large publicly available datasets: myocardial infarction complications and readmission of diabetic patients data.
Fractional norms and quasinorms do not help to overcome the curse of dimensionality
Apr 29, 2020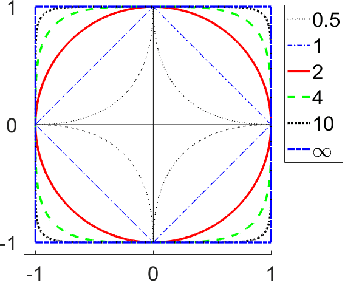
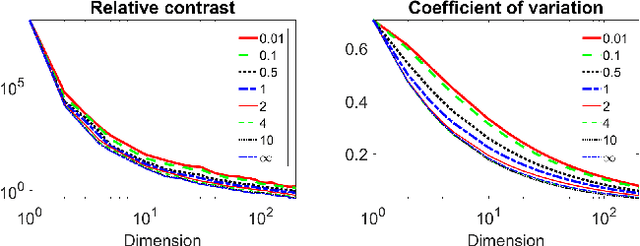
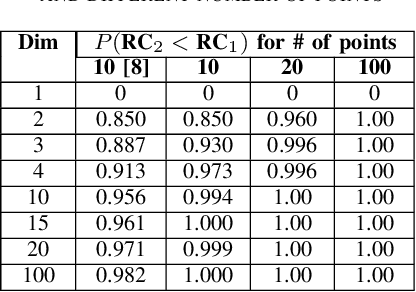
The curse of dimensionality causes the well-known and widely discussed problems for machine learning methods. There is a hypothesis that using of the Manhattan distance and even fractional quasinorms lp (for p less than 1) can help to overcome the curse of dimensionality in classification problems. In this study, we systematically test this hypothesis. We confirm that fractional quasinorms have a greater relative contrast or coefficient of variation than the Euclidean norm l2, but we also demonstrate that the distance concentration shows qualitatively the same behaviour for all tested norms and quasinorms and the difference between them decays as dimension tends to infinity. Estimation of classification quality for kNN based on different norms and quasinorms shows that a greater relative contrast does not mean better classifier performance and the worst performance for different databases was shown by different norms (quasinorms). A systematic comparison shows that the difference of the performance of kNN based on lp for p=2, 1, and 0.5 is statistically insignificant.