 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary IoU: Improving Object-Centric Image Segmentation Evaluation
Mar 30, 2021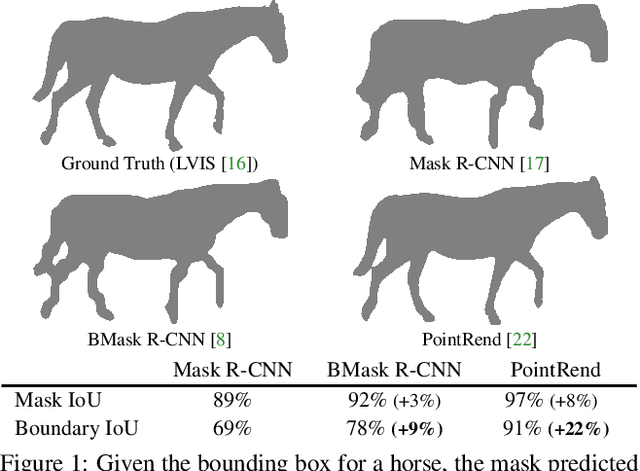
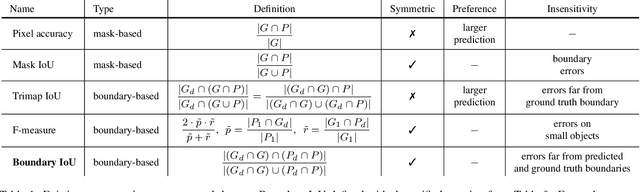

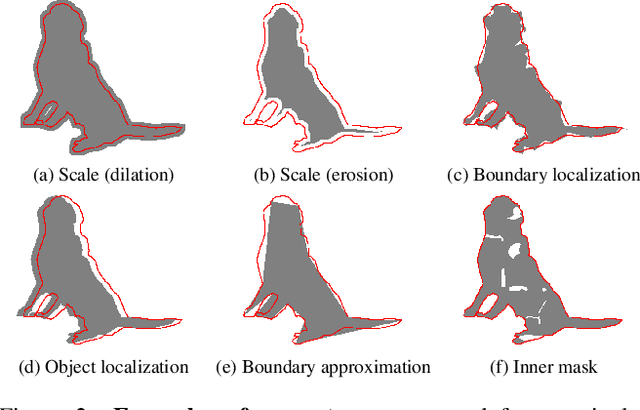
We present Boundary IoU (Intersection-over-Union), a new segmentation evaluation measure focused on boundary quality. We perform an extensive analysis across different error types and object sizes and show that Boundary IoU is significantly more sensitive than the standard Mask IoU measure to boundary errors for large objects and does not over-penalize errors on smaller objects. The new quality measure displays several desirable characteristics like symmetry w.r.t. prediction/ground truth pairs and balanced responsiveness across scales, which makes it more suitable for segmentation evaluation than other boundary-focused measures like Trimap IoU and F-measure. Based on Boundary IoU, we update the standard evaluation protocols for instance and panoptic segmentation tasks by proposing the Boundary AP (Average Precision) and Boundary PQ (Panoptic Quality) metrics, respectively. Our experiments show that the new evaluation metrics track boundary quality improvements that are generally overlooked by current Mask IoU-based evaluation metrics. We hope that the adoption of the new boundary-sensitive evaluation metrics will lead to rapid progress in segmentation methods that improve boundary quality.
On Interaction Between Augmentations and Corruptions in Natural Corruption Robustness
Feb 22, 2021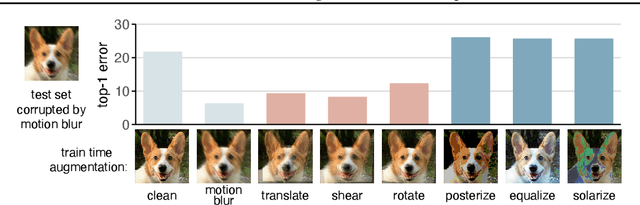
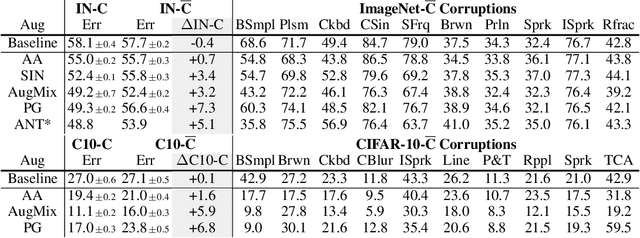
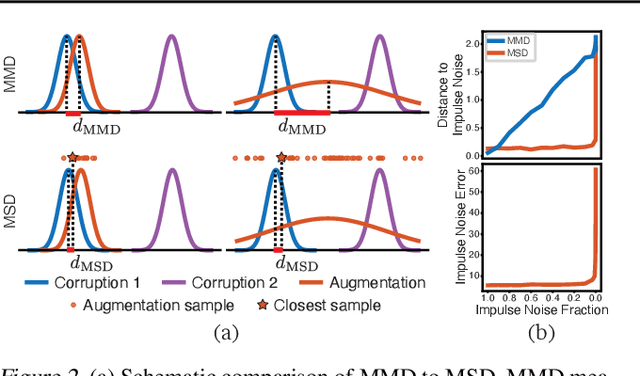
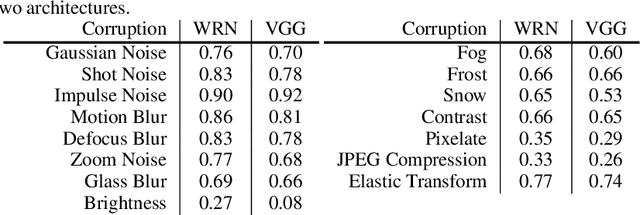
Invariance to a broad array of image corruptions, such as warping, noise, or color shifts, is an important aspect of building robust models in computer vision. Recently, several new data augmentations have been proposed that significantly improve performance on ImageNet-C, a benchmark of such corruptions. However, there is still a lack of basic understanding on the relationship between data augmentations and test-time corruptions. To this end, we develop a feature space for image transforms, and then use a new measure in this space between augmentations and corruptions called the Minimal Sample Distance to demonstrate there is a strong correlation between similarity and performance. We then investigate recent data augmentations and observe a significant degradation in corruption robustness when the test-time corruptions are sampled to be perceptually dissimilar from ImageNet-C in this feature space. Our results suggest that test error can be improved by training on perceptually similar augmentations, and data augmentations may not generalize well beyond the existing benchmark. We hope our results and tools will allow for more robust progress towards improving robustness to image corruptions.
Evaluating Large-Vocabulary Object Detectors: The Devil is in the Details
Feb 01, 2021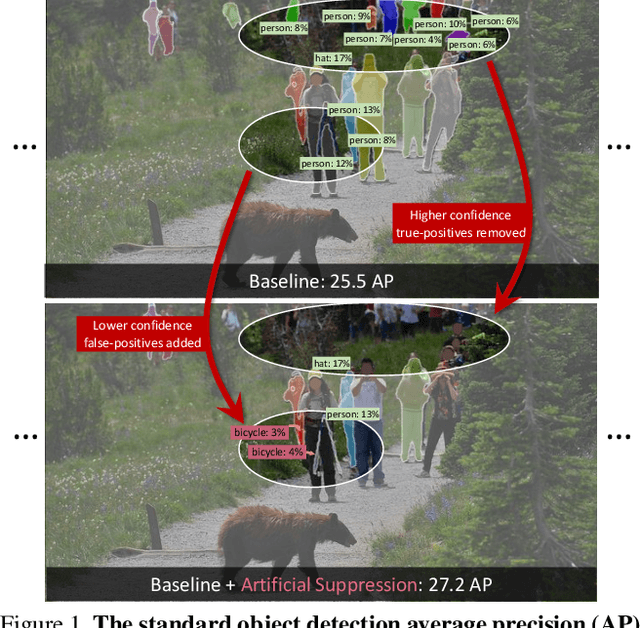

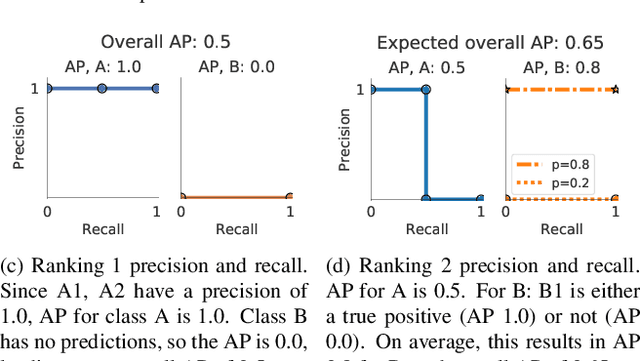
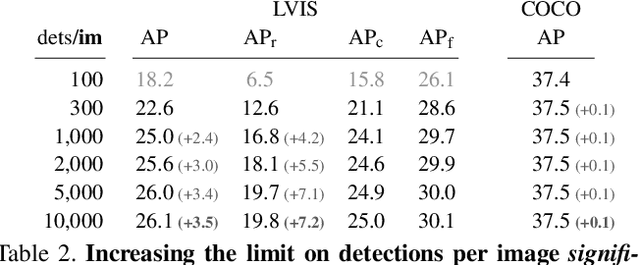
By design, average precision (AP) for object detection aims to treat all classes independently: AP is computed independently per category and averaged. On the one hand, this is desirable as it treats all classes, rare to frequent, equally. On the other hand, it ignores cross-category confidence calibration, a key property in real-world use cases. Unfortunately, we find that on imbalanced, large-vocabulary datasets, the default implementation of AP is neither category independent, nor does it directly reward properly calibrated detectors. In fact, we show that the default implementation produces a gameable metric, where a simple, nonsensical re-ranking policy can improve AP by a large margin. To address these limitations, we introduce two complementary metrics. First, we present a simple fix to the default AP implementation, ensuring that it is truly independent across categories as originally intended. We benchmark recent advances in large-vocabulary detection and find that many reported gains do not translate to improvements under our new per-class independent evaluation, suggesting recent improvements may arise from difficult to interpret changes to cross-category rankings. Given the importance of reliably benchmarking cross-category rankings, we consider a pooled version of AP (AP-pool) that rewards properly calibrated detectors by directly comparing cross-category rankings. Finally, we revisit classical approaches for calibration and find that explicitly calibrating detectors improves state-of-the-art on AP-pool by 1.7 points.
TrackFormer: Multi-Object Tracking with Transformers
Jan 07, 2021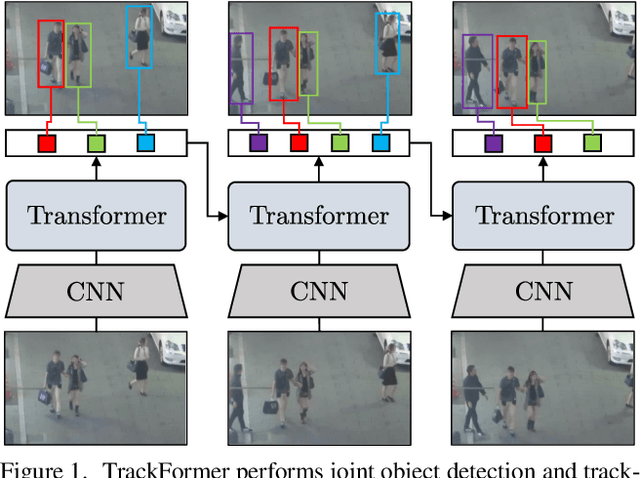
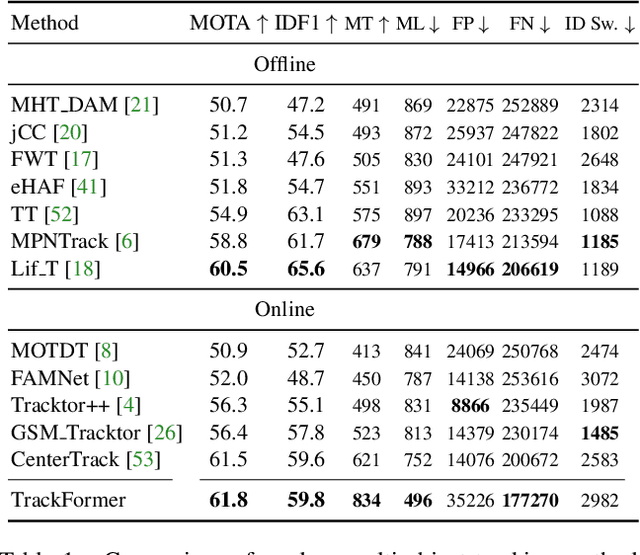
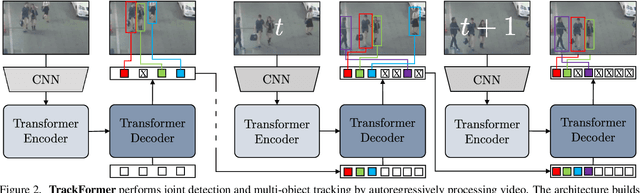
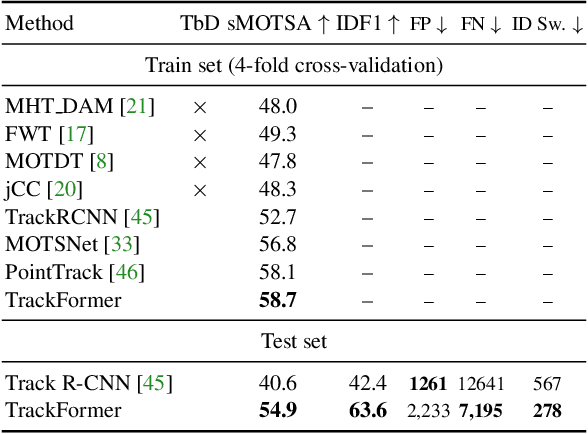
We present TrackFormer, an end-to-end multi-object tracking and segmentation model based on an encoder-decoder Transformer architecture. Our approach introduces track query embeddings which follow objects through a video sequence in an autoregressive fashion. New track queries are spawned by the DETR object detector and embed the position of their corresponding object over time. The Transformer decoder adjusts track query embeddings from frame to frame, thereby following the changing object positions. TrackFormer achieves a seamless data association between frames in a new tracking-by-attention paradigm by self- and encoder-decoder attention mechanisms which simultaneously reason about location, occlusion, and object identity. TrackFormer yields state-of-the-art performance on the tasks of multi-object tracking (MOT17) and segmentation (MOTS20). We hope our unified way of performing detection and tracking will foster future research in multi-object tracking and video understanding. Code will be made publicly available.
End-to-End Object Detection with Transformers
May 28, 2020
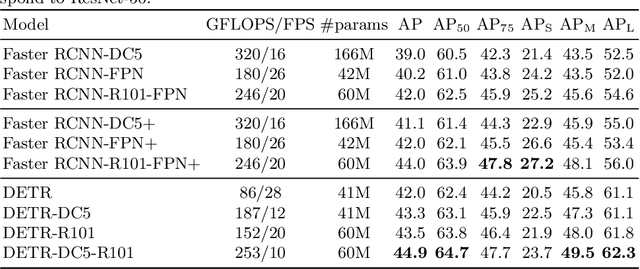
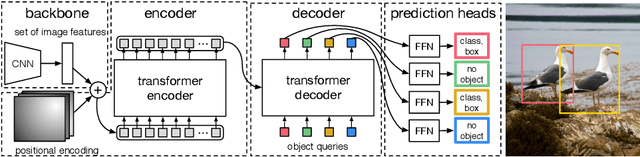
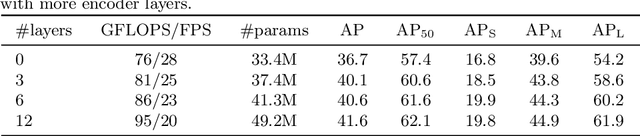
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines. Training code and pretrained models are available at https://github.com/facebookresearch/detr.
PointRend: Image Segmentation as Rendering
Dec 17, 2019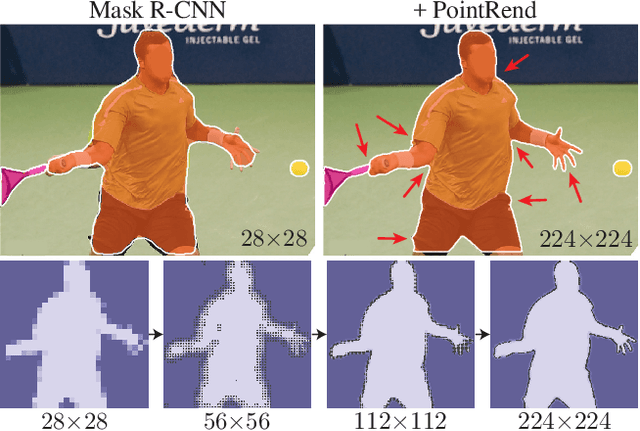
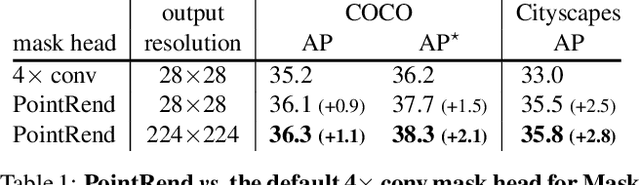


We present a new method for efficient high-quality image segmentation of objects and scenes. By analogizing classical computer graphics methods for efficient rendering with over- and undersampling challenges faced in pixel labeling tasks, we develop a unique perspective of image segmentation as a rendering problem. From this vantage, we present the PointRend (Point-based Rendering) neural network module: a module that performs point-based segmentation predictions at adaptively selected locations based on an iterative subdivision algorithm. PointRend can be flexibly applied to both instance and semantic segmentation tasks by building on top of existing state-of-the-art models. While many concrete implementations of the general idea are possible, we show that a simple design already achieves excellent results. Qualitatively, PointRend outputs crisp object boundaries in regions that are over-smoothed by previous methods. Quantitatively, PointRend yields significant gains on COCO and Cityscapes, for both instance and semantic segmentation. PointRend's efficiency enables output resolutions that are otherwise impractical in terms of memory or computation compared to existing approaches.
Exploring Randomly Wired Neural Networks for Image Recognition
Apr 08, 2019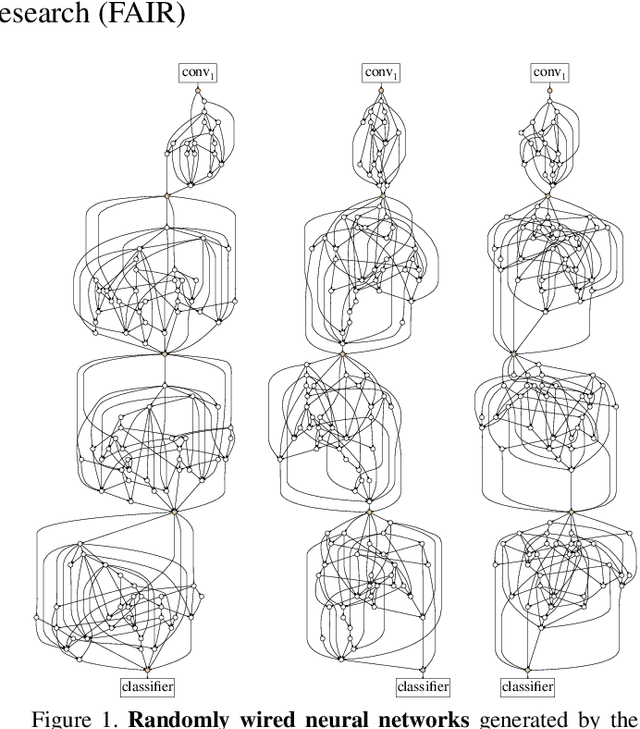


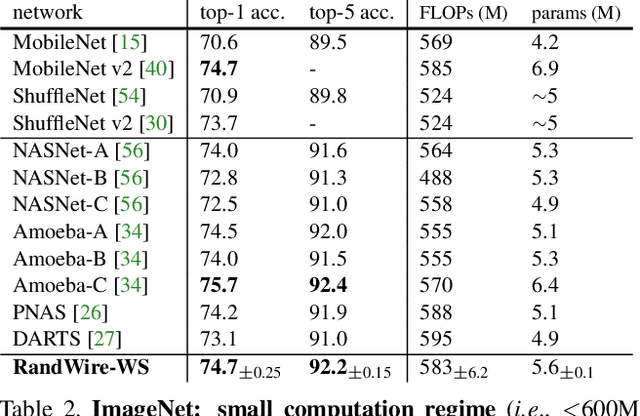
Neural networks for image recognition have evolved through extensive manual design from simple chain-like models to structures with multiple wiring paths. The success of ResNets and DenseNets is due in large part to their innovative wiring plans. Now, neural architecture search (NAS) studies are exploring the joint optimization of wiring and operation types, however, the space of possible wirings is constrained and still driven by manual design despite being searched. In this paper, we explore a more diverse set of connectivity patterns through the lens of randomly wired neural networks. To do this, we first define the concept of a stochastic network generator that encapsulates the entire network generation process. Encapsulation provides a unified view of NAS and randomly wired networks. Then, we use three classical random graph models to generate randomly wired graphs for networks. The results are surprising: several variants of these random generators yield network instances that have competitive accuracy on the ImageNet benchmark. These results suggest that new efforts focusing on designing better network generators may lead to new breakthroughs by exploring less constrained search spaces with more room for novel design.
Panoptic Feature Pyramid Networks
Jan 08, 2019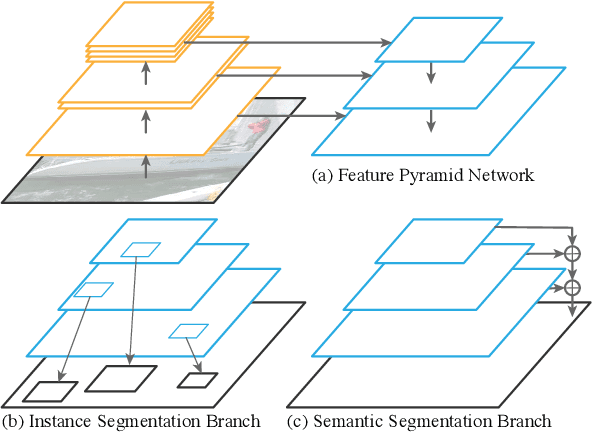


The recently introduced panoptic segmentation task has renewed our community's interest in unifying the tasks of instance segmentation (for thing classes) and semantic segmentation (for stuff classes). However, current state-of-the-art methods for this joint task use separate and dissimilar networks for instance and semantic segmentation, without performing any shared computation. In this work, we aim to unify these methods at the architectural level, designing a single network for both tasks. Our approach is to endow Mask R-CNN, a popular instance segmentation method, with a semantic segmentation branch using a shared Feature Pyramid Network (FPN) backbone. Surprisingly, this simple baseline not only remains effective for instance segmentation, but also yields a lightweight, top-performing method for semantic segmentation. In this work, we perform a detailed study of this minimally extended version of Mask R-CNN with FPN, which we refer to as Panoptic FPN, and show it is a robust and accurate baseline for both tasks. Given its effectiveness and conceptual simplicity, we hope our method can serve as a strong baseline and aid future research in panoptic segmentation.
WSD algorithm based on a new method of vector-word contexts proximity calculation via epsilon-filtration
Jun 18, 2018
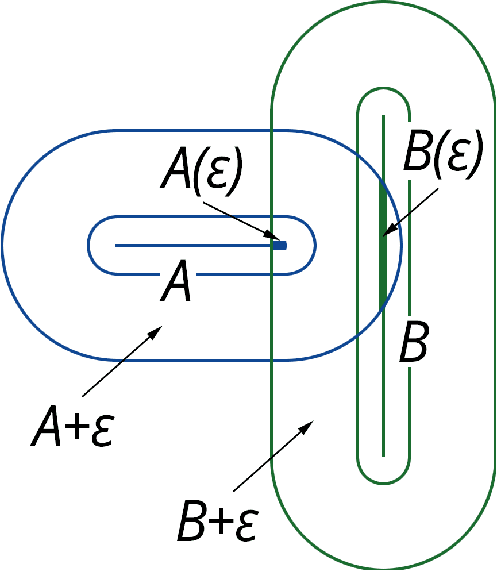
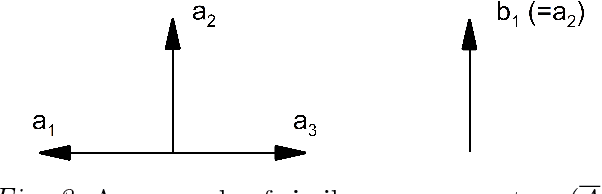

The problem of word sense disambiguation (WSD) is considered in the article. Given a set of synonyms (synsets) and sentences with these synonyms. It is necessary to select the meaning of the word in the sentence automatically. 1285 sentences were tagged by experts, namely, one of the dictionary meanings was selected by experts for target words. To solve the WSD-problem, an algorithm based on a new method of vector-word contexts proximity calculation is proposed. In order to achieve higher accuracy, a preliminary epsilon-filtering of words is performed, both in the sentence and in the set of synonyms. An extensive program of experiments was carried out. Four algorithms are implemented, including a new algorithm. Experiments have shown that in a number of cases the new algorithm shows better results. The developed software and the tagged corpus have an open license and are available online. Wiktionary and Wikisource are used. A brief description of this work can be viewed in slides (https://goo.gl/9ak6Gt). Video lecture in Russian on this research is available online (https://youtu.be/-DLmRkepf58).
* 15 pages, 1 table, 15 figures, accepted in the journal Transactions of Karelian Research Centre of the Russian Academy of Sciences
Panoptic Segmentation
Apr 14, 2018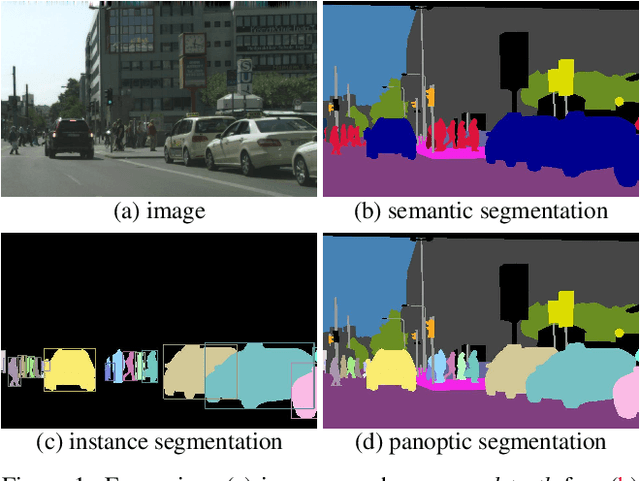
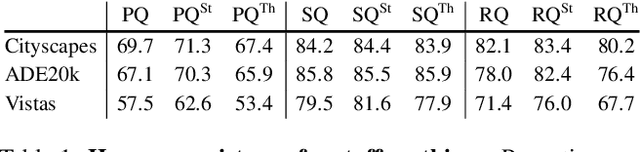
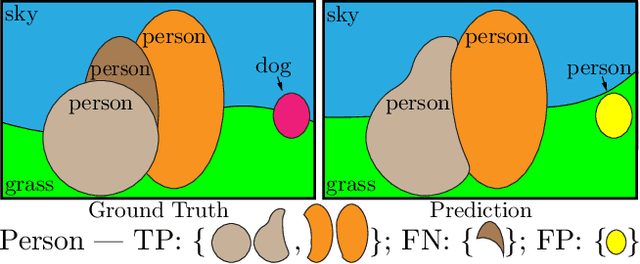

We propose and study a novel panoptic segmentation (PS) task. Panoptic segmentation unifies the typically distinct tasks of semantic segmentation (assign a class label to each pixel) and instance segmentation (detect and segment each object instance). The proposed task requires generating a coherent scene segmentation that is rich and complete, an important step toward real-world vision systems. While early work in computer vision addressed related image/scene parsing tasks, these are not currently popular, possibly due to lack of appropriate metrics or associated recognition challenges. To address this, we first propose a novel panoptic quality (PQ) metric that captures performance for all classes (stuff and things) in an interpretable and unified manner. Using the proposed metric, we perform a rigorous study of both human and machine performance for PS on three existing datasets, revealing interesting insights about the task. Second, we are working to introduce panoptic segmentation tracks at upcoming recognition challenges. The aim of our work is to revive the interest of the community in a more unified view of image segmentation.