 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Parallel Cross-Lingual Learning in Low-Resource Target Language Translation
Aug 25, 2018
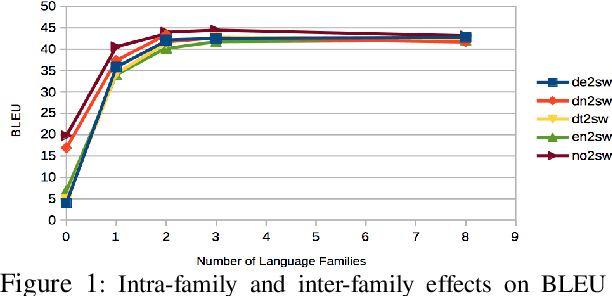
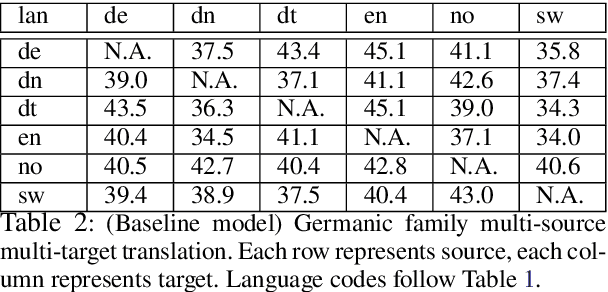
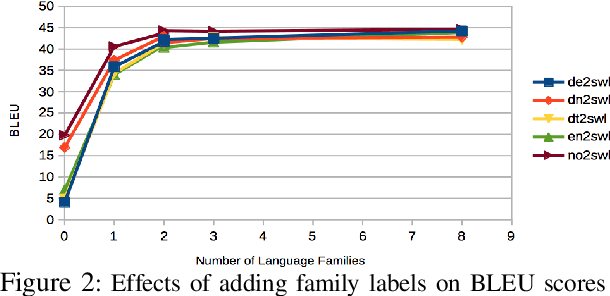
We work on translation from rich-resource languages to low-resource languages. The main challenges we identify are the lack of low-resource language data, effective methods for cross-lingual transfer, and the variable-binding problem that is common in neural systems. We build a translation system that addresses these challenges using eight European language families as our test ground. Firstly, we add the source and the target family labels and study intra-family and inter-family influences for effective cross-lingual transfer. We achieve an improvement of +9.9 in BLEU score for English-Swedish translation using eight families compared to the single-family multi-source multi-target baseline. Moreover, we find that training on two neighboring families closest to the low-resource language is often enough. Secondly, we construct an ablation study and find that reasonably good results can be achieved even with considerably less target data. Thirdly, we address the variable-binding problem by building an order-preserving named entity translation model. We obtain 60.6% accuracy in qualitative evaluation where our translations are akin to human translations in a preliminary study.
A Hierarchical Approach to Neural Context-Aware Modeling
Aug 06, 2018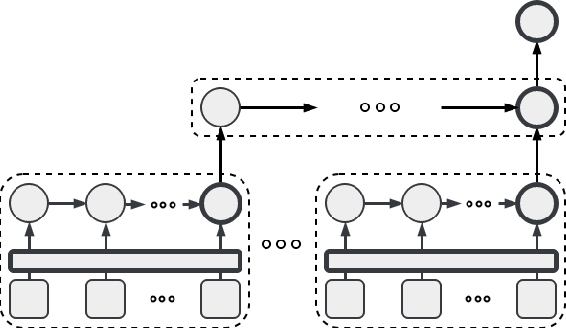
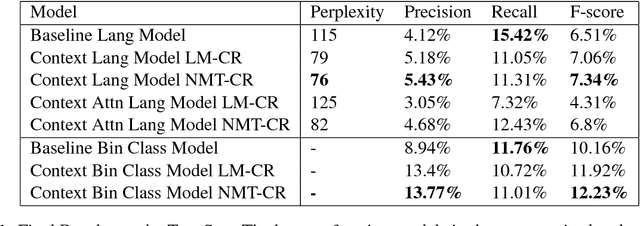
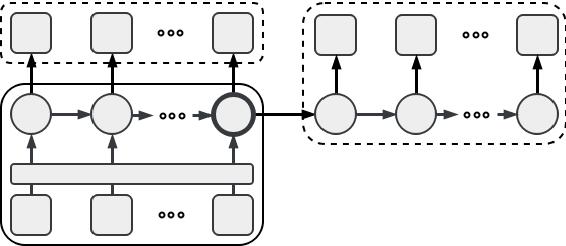
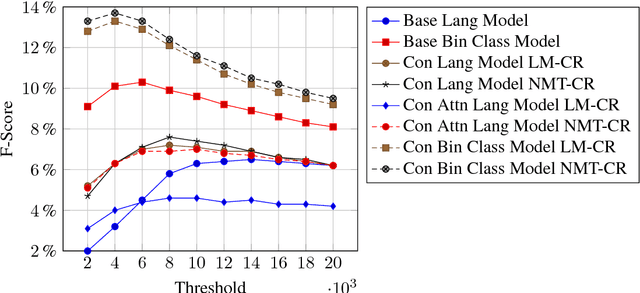
We present a new recurrent neural network topology to enhance state-of-the-art machine learning systems by incorporating a broader context. Our approach overcomes recent limitations with extended narratives through a multi-layered computational approach to generate an abstract context representation. Therefore, the developed system captures the narrative on word-level, sentence-level, and context-level. Through the hierarchical set-up, our proposed model summarizes the most salient information on each level and creates an abstract representation of the extended context. We subsequently use this representation to enhance neural language processing systems on the task of semantic error detection. To show the potential of the newly introduced topology, we compare the approach against a context-agnostic set-up including a standard neural language model and a supervised binary classification network. The performance measures on the error detection task show the advantage of the hierarchical context-aware topologies, improving the baseline by 12.75% relative for unsupervised models and 20.37% relative for supervised models.
Low-Latency Neural Speech Translation
Aug 01, 2018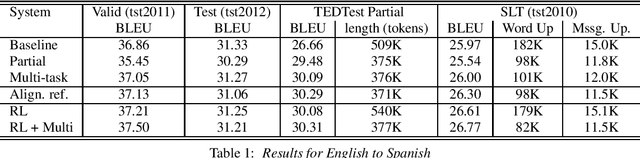
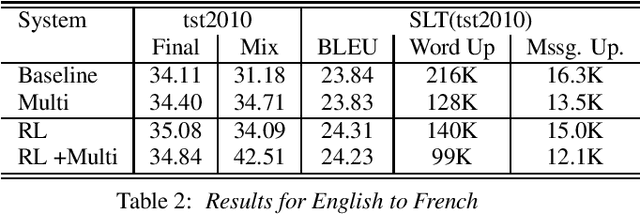
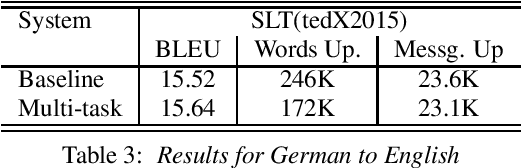
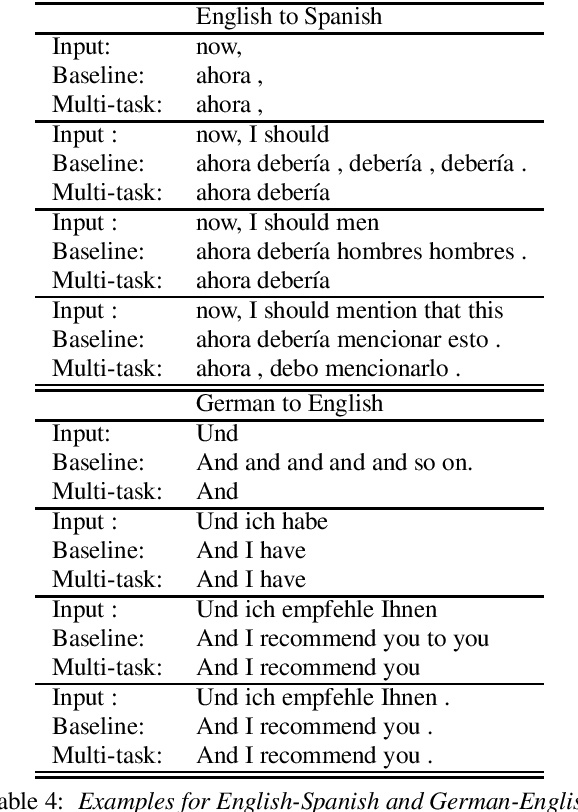
Through the development of neural machine translation, the quality of machine translation systems has been improved significantly. By exploiting advancements in deep learning, systems are now able to better approximate the complex mapping from source sentences to target sentences. But with this ability, new challenges also arise. An example is the translation of partial sentences in low-latency speech translation. Since the model has only seen complete sentences in training, it will always try to generate a complete sentence, though the input may only be a partial sentence. We show that NMT systems can be adapted to scenarios where no task-specific training data is available. Furthermore, this is possible without losing performance on the original training data. We achieve this by creating artificial data and by using multi-task learning. After adaptation, we are able to reduce the number of corrections displayed during incremental output construction by 45%, without a decrease in translation quality.
Robust and Scalable Differentiable Neural Computer for Question Answering
Jul 07, 2018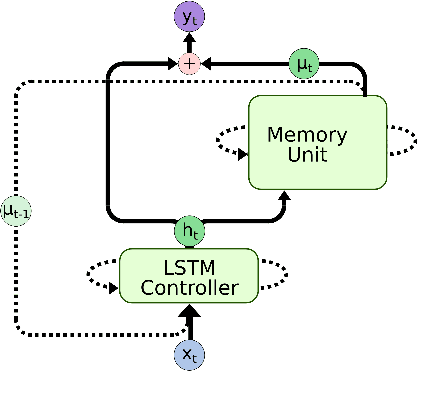
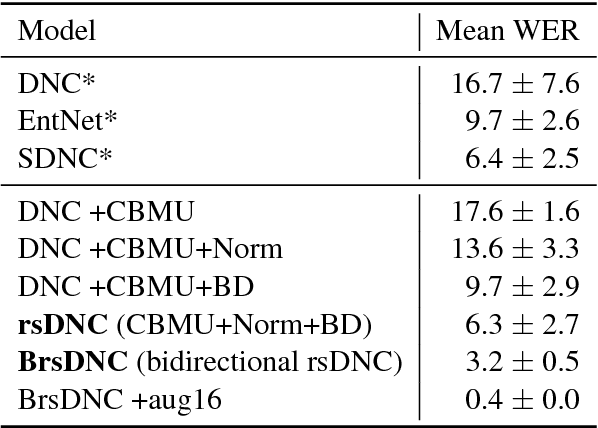
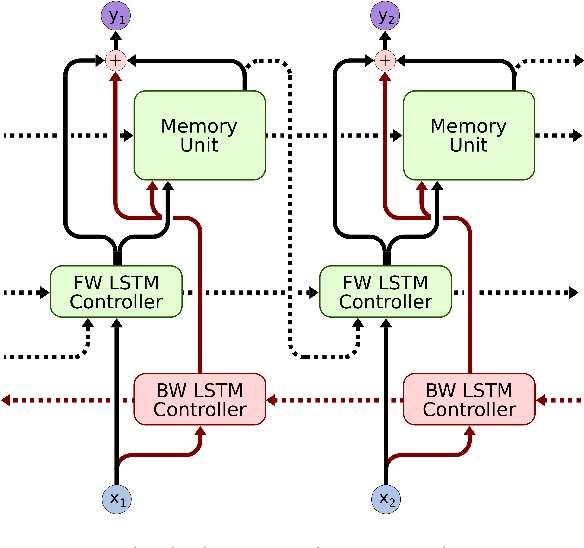
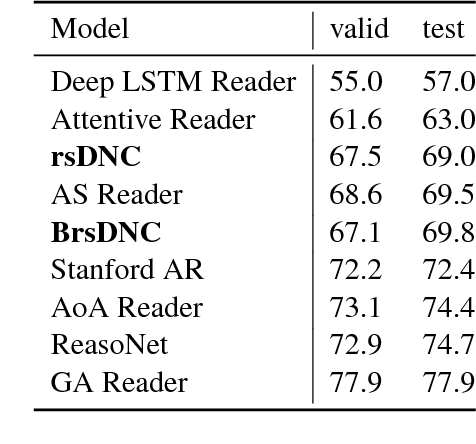
Deep learning models are often not easily adaptable to new tasks and require task-specific adjustments. The differentiable neural computer (DNC), a memory-augmented neural network, is designed as a general problem solver which can be used in a wide range of tasks. But in reality, it is hard to apply this model to new tasks. We analyze the DNC and identify possible improvements within the application of question answering. This motivates a more robust and scalable DNC (rsDNC). The objective precondition is to keep the general character of this model intact while making its application more reliable and speeding up its required training time. The rsDNC is distinguished by a more robust training, a slim memory unit and a bidirectional architecture. We not only achieve new state-of-the-art performance on the bAbI task, but also minimize the performance variance between different initializations. Furthermore, we demonstrate the simplified applicability of the rsDNC to new tasks with passable results on the CNN RC task without adaptions.
Neural Language Codes for Multilingual Acoustic Models
Jul 05, 2018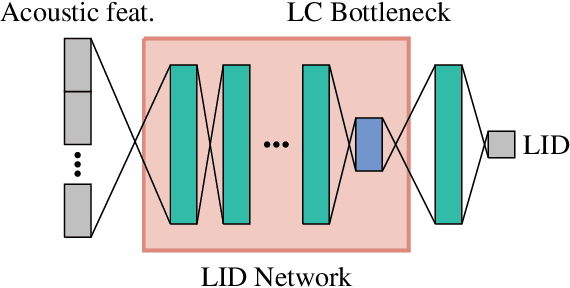
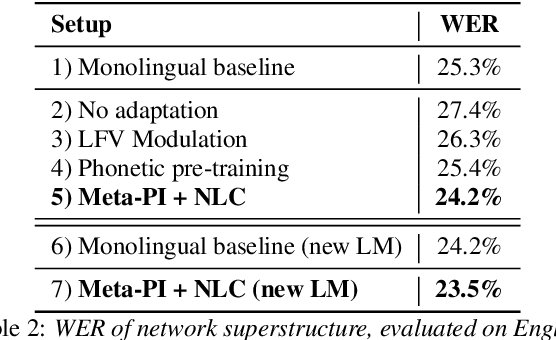
Multilingual Speech Recognition is one of the most costly AI problems, because each language (7,000+) and even different accents require their own acoustic models to obtain best recognition performance. Even though they all use the same phoneme symbols, each language and accent imposes its own coloring or "twang". Many adaptive approaches have been proposed, but they require further training, additional data and generally are inferior to monolingually trained models. In this paper, we propose a different approach that uses a large multilingual model that is \emph{modulated} by the codes generated by an ancillary network that learns to code useful differences between the "twangs" or human language. We use Meta-Pi networks to have one network (the language code net) gate the activity of neurons in another (the acoustic model nets). Our results show that during recognition multilingual Meta-Pi networks quickly adapt to the proper language coloring without retraining or new data, and perform better than monolingually trained networks. The model was evaluated by training acoustic modeling nets and modulating language code nets jointly and optimize them for best recognition performance.
Subword and Crossword Units for CTC Acoustic Models
Jun 18, 2018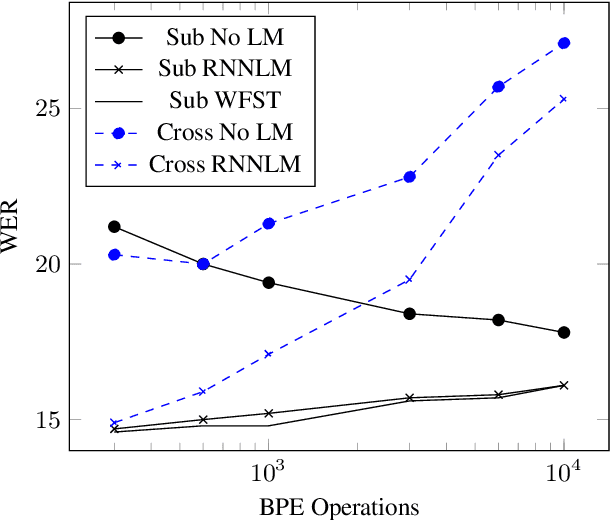
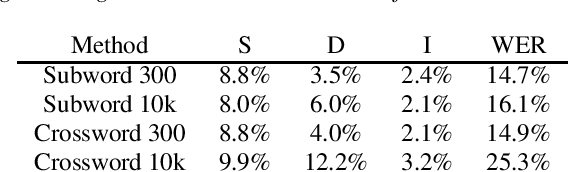
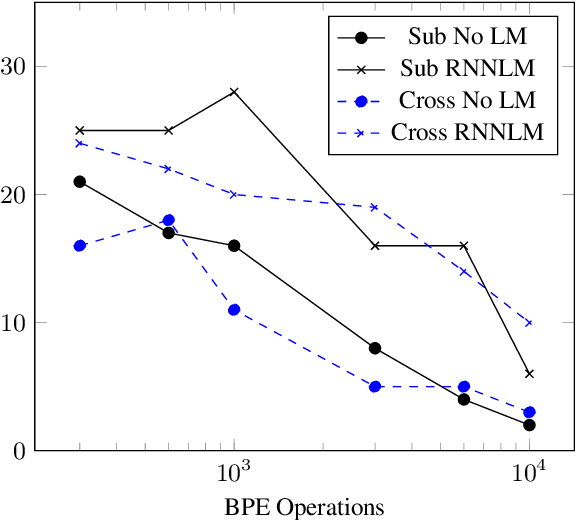

This paper proposes a novel approach to create an unit set for CTC based speech recognition systems. By using Byte Pair Encoding we learn an unit set of an arbitrary size on a given training text. In contrast to using characters or words as units this allows us to find a good trade-off between the size of our unit set and the available training data. We evaluate both Crossword units, that may span multiple word, and Subword units. By combining this approach with decoding methods using a separate language model we are able to achieve state of the art results for grapheme based CTC systems.
Self-Attentional Acoustic Models
Jun 18, 2018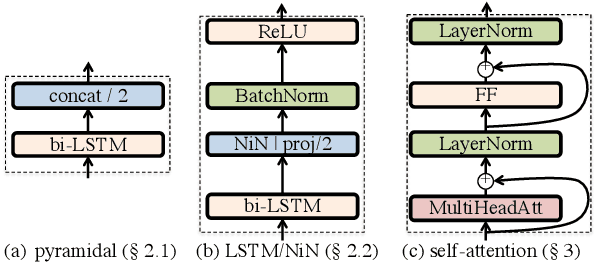
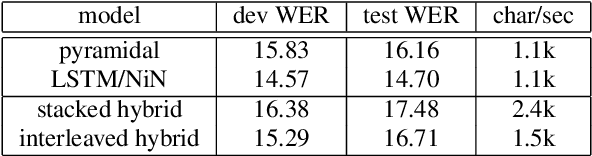
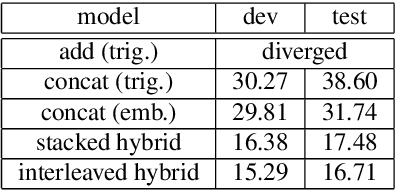
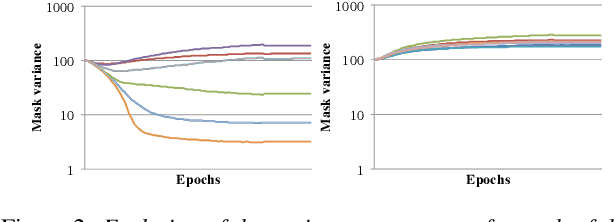
Self-attention is a method of encoding sequences of vectors by relating these vectors to each-other based on pairwise similarities. These models have recently shown promising results for modeling discrete sequences, but they are non-trivial to apply to acoustic modeling due to computational and modeling issues. In this paper, we apply self-attention to acoustic modeling, proposing several improvements to mitigate these issues: First, self-attention memory grows quadratically in the sequence length, which we address through a downsampling technique. Second, we find that previous approaches to incorporate position information into the model are unsuitable and explore other representations and hybrid models to this end. Third, to stress the importance of local context in the acoustic signal, we propose a Gaussian biasing approach that allows explicit control over the context range. Experiments find that our model approaches a strong baseline based on LSTMs with network-in-network connections while being much faster to compute. Besides speed, we find that interpretability is a strength of self-attentional acoustic models, and demonstrate that self-attention heads learn a linguistically plausible division of labor.
Automated Evaluation of Out-of-Context Errors
Mar 23, 2018
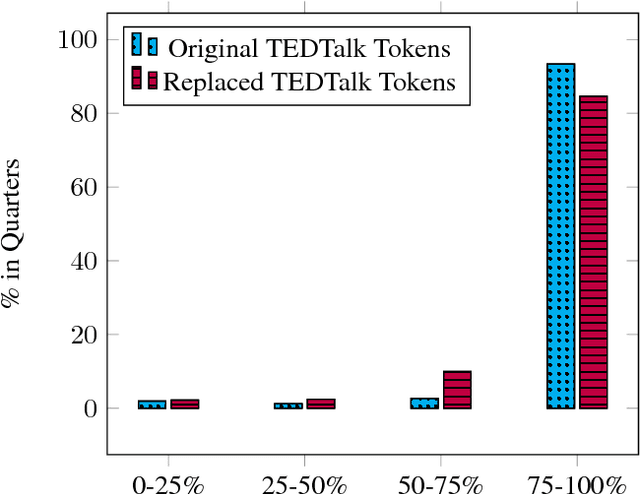
We present a new approach to evaluate computational models for the task of text understanding by the means of out-of-context error detection. Through the novel design of our automated modification process, existing large-scale data sources can be adopted for a vast number of text understanding tasks. The data is thereby altered on a semantic level, allowing models to be tested against a challenging set of modified text passages that require to comprise a broader narrative discourse. Our newly introduced task targets actual real-world problems of transcription and translation systems by inserting authentic out-of-context errors. The automated modification process is applied to the 2016 TEDTalk corpus. Entirely automating the process allows the adoption of complete datasets at low cost, facilitating supervised learning procedures and deeper networks to be trained and tested. To evaluate the quality of the modification algorithm a language model and a supervised binary classification model are trained and tested on the altered dataset. A human baseline evaluation is examined to compare the results with human performance. The outcome of the evaluation task indicates the difficulty to detect semantic errors for machine-learning algorithms and humans, showing that the errors cannot be identified when limited to a single sentence.
An End-to-End Goal-Oriented Dialog System with a Generative Natural Language Response Generation
Mar 15, 2018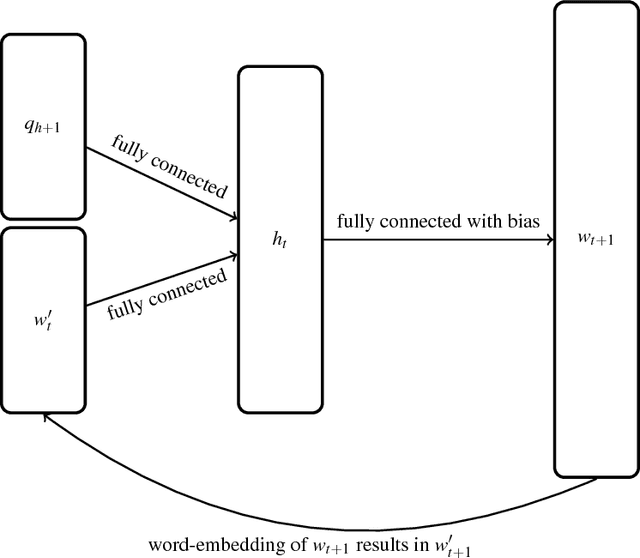
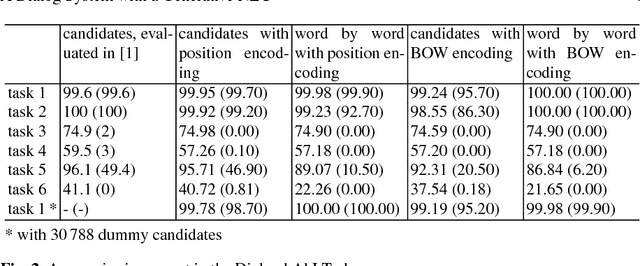

Recently advancements in deep learning allowed the development of end-to-end trained goal-oriented dialog systems. Although these systems already achieve good performance, some simplifications limit their usage in real-life scenarios. In this work, we address two of these limitations: ignoring positional information and a fixed number of possible response candidates. We propose to use positional encodings in the input to model the word order of the user utterances. Furthermore, by using a feedforward neural network, we are able to generate the output word by word and are no longer restricted to a fixed number of possible response candidates. Using the positional encoding, we were able to achieve better accuracies in the Dialog bAbI Tasks and using the feedforward neural network for generating the response, we were able to save computation time and space consumption.
Multilingual Adaptation of RNN Based ASR Systems
Feb 27, 2018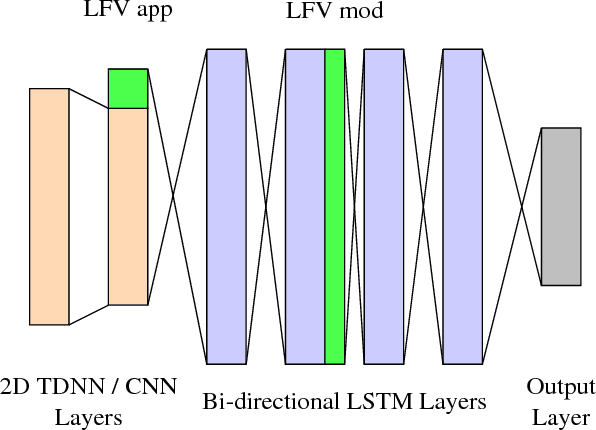
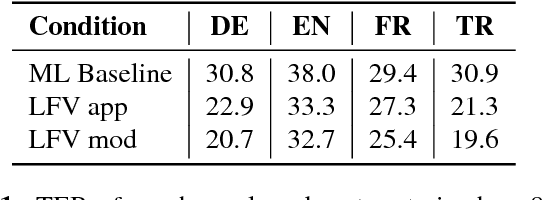
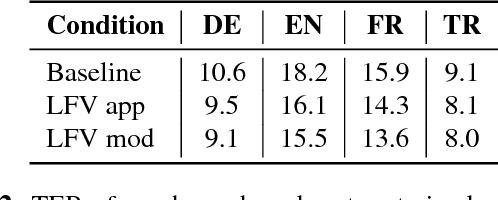
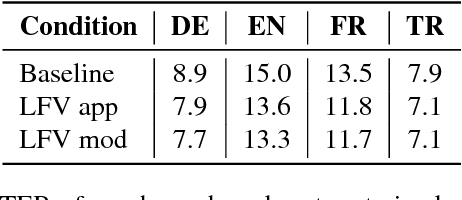
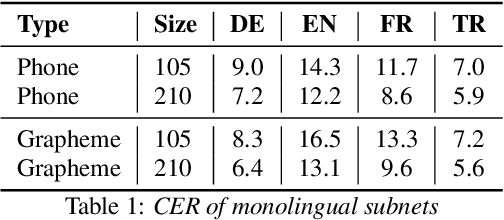
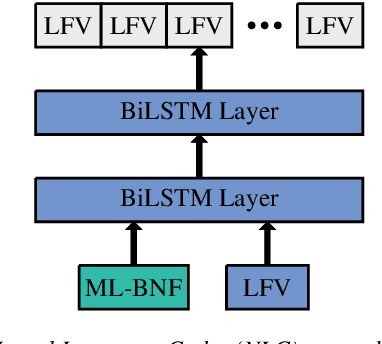
In this work, we focus on multilingual systems based on recurrent neural networks (RNNs), trained using the Connectionist Temporal Classification (CTC) loss function. Using a multilingual set of acoustic units poses difficulties. To address this issue, we proposed Language Feature Vectors (LFVs) to train language adaptive multilingual systems. Language adaptation, in contrast to speaker adaptation, needs to be applied not only on the feature level, but also to deeper layers of the network. In this work, we therefore extended our previous approach by introducing a novel technique which we call "modulation". Based on this method, we modulated the hidden layers of RNNs using LFVs. We evaluated this approach in both full and low resource conditions, as well as for grapheme and phone based systems. Lower error rates throughout the different conditions could be achieved by the use of the modulation.