 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA lightweight and accurate YOLO-like network for small target detection in Aerial Imagery
Apr 05, 2022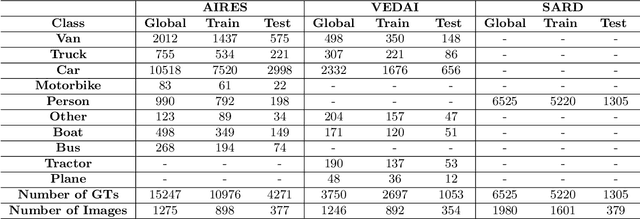

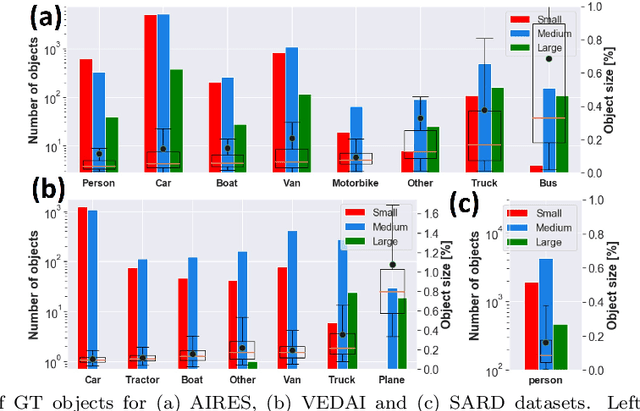
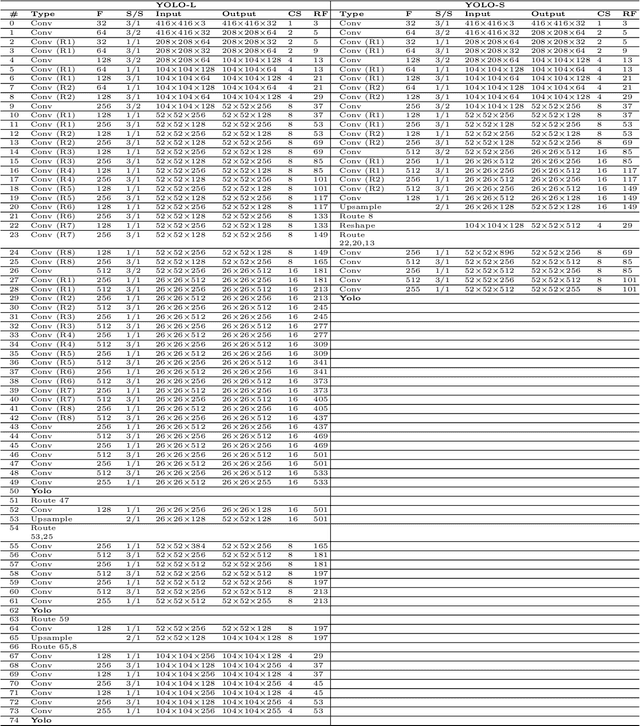
Despite the breakthrough deep learning performances achieved for automatic object detection, small target detection is still a challenging problem, especially when looking at fast and accurate solutions suitable for mobile or edge applications. In this work we present YOLO-S, a simple, fast and efficient network for small target detection. The architecture exploits a small feature extractor based on Darknet20, as well as skip connection, via both bypass and concatenation, and reshape-passthrough layer to alleviate the vanishing gradient problem, promote feature reuse across network and combine low-level positional information with more meaningful high-level information. To verify the performances of YOLO-S, we build "AIRES", a novel dataset for cAr detectIon fRom hElicopter imageS acquired in Europe, and set up experiments on both AIRES and VEDAI datasets, benchmarking this architecture with four baseline detectors. Furthermore, in order to handle efficiently the issue of data insufficiency and domain gap when dealing with a transfer learning strategy, we introduce a transitional learning task over a combined dataset based on DOTAv2 and VEDAI and demonstrate that can enhance the overall accuracy with respect to more general features transferred from COCO data. YOLO-S is from 25% to 50% faster than YOLOv3 and only 15-25% slower than Tiny-YOLOv3, outperforming also YOLOv3 in terms of accuracy in a wide range of experiments. Further simulations performed on SARD dataset demonstrate also its applicability to different scenarios such as for search and rescue operations. Besides, YOLO-S has an 87% decrease of parameter size and almost one half FLOPs of YOLOv3, making practical the deployment for low-power industrial applications.
A Multi-Stage model based on YOLOv3 for defect detection in PV panels based on IR and Visible Imaging by Unmanned Aerial Vehicle
Nov 23, 2021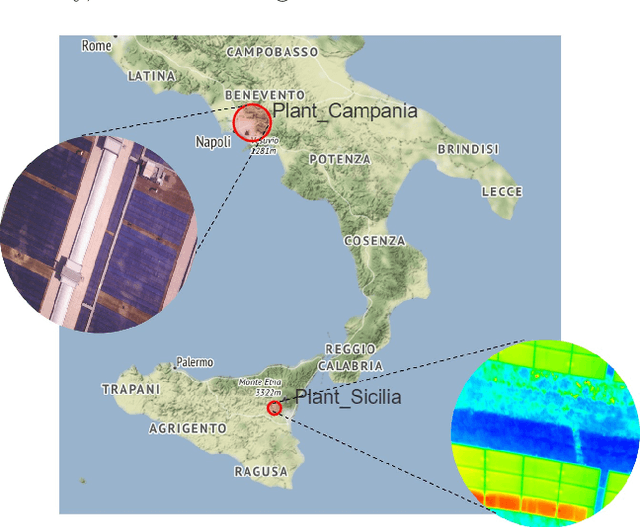
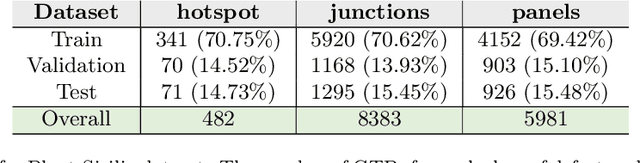
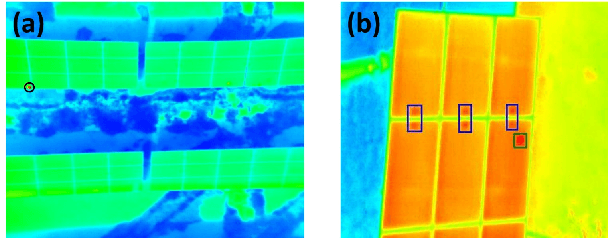
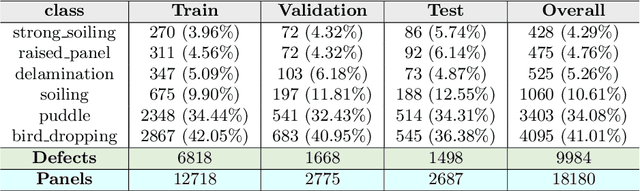
As solar capacity installed worldwide continues to grow, there is an increasing awareness that advanced inspection systems are becoming of utmost importance to schedule smart interventions and minimize downtime likelihood. In this work we propose a novel automatic multi-stage model to detect panel defects on aerial images captured by unmanned aerial vehicle by using the YOLOv3 network and Computer Vision techniques. The model combines detections of panels and defects to refine its accuracy. The main novelties are represented by its versatility to process either thermographic or visible images and detect a large variety of defects and its portability to both rooftop and ground-mounted PV systems and different panel types. The proposed model has been validated on two big PV plants in the south of Italy with an outstanding AP@0.5 exceeding 98% for panel detection, a remarkable AP@0.4 (AP@0.5) of roughly 88.3% (66.95%) for hotspots by means of infrared thermography and a mAP@0.5 of almost 70% in the visible spectrum for detection of anomalies including panel shading induced by soiling and bird dropping, delamination, presence of puddles and raised rooftop panels. An estimation of the soiling coverage is also predicted. Finally an analysis of the influence of the different YOLOv3's output scales on the detection is discussed.
Can machines learn to see without visual databases?
Oct 12, 2021This paper sustains the position that the time has come for thinking of learning machines that conquer visual skills in a truly human-like context, where a few human-like object supervisions are given by vocal interactions and pointing aids only. This likely requires new foundations on computational processes of vision with the final purpose of involving machines in tasks of visual description by living in their own visual environment under simple man-machine linguistic interactions. The challenge consists of developing machines that learn to see without needing to handle visual databases. This might open the doors to a truly orthogonal competitive track concerning deep learning technologies for vision which does not rely on the accumulation of huge visual databases.
Evaluating Continual Learning Algorithms by Generating 3D Virtual Environments
Sep 16, 2021



Continual learning refers to the ability of humans and animals to incrementally learn over time in a given environment. Trying to simulate this learning process in machines is a challenging task, also due to the inherent difficulty in creating conditions for designing continuously evolving dynamics that are typical of the real-world. Many existing research works usually involve training and testing of virtual agents on datasets of static images or short videos, considering sequences of distinct learning tasks. However, in order to devise continual learning algorithms that operate in more realistic conditions, it is fundamental to gain access to rich, fully customizable and controlled experimental playgrounds. Focussing on the specific case of vision, we thus propose to leverage recent advances in 3D virtual environments in order to approach the automatic generation of potentially life-long dynamic scenes with photo-realistic appearance. Scenes are composed of objects that move along variable routes with different and fully customizable timings, and randomness can also be included in their evolution. A novel element of this paper is that scenes are described in a parametric way, thus allowing the user to fully control the visual complexity of the input stream the agent perceives. These general principles are concretely implemented exploiting a recently published 3D virtual environment. The user can generate scenes without the need of having strong skills in computer graphics, since all the generation facilities are exposed through a simple high-level Python interface. We publicly share the proposed generator.
An Optimal Control Approach to Learning in SIDARTHE Epidemic model
Oct 28, 2020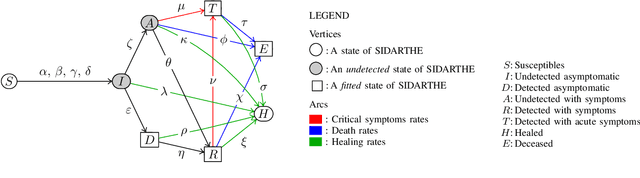
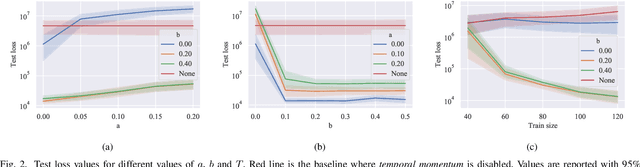
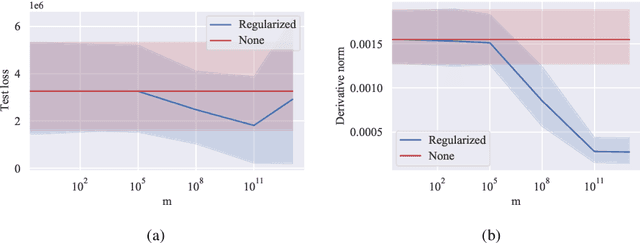
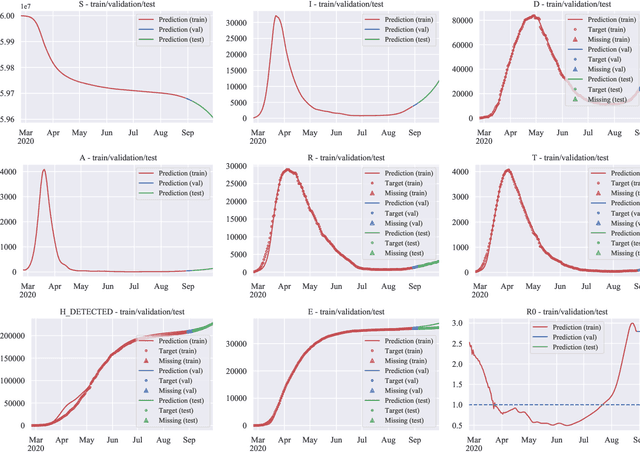
The COVID-19 outbreak has stimulated the interest in the proposal of novel epidemiological models to predict the course of the epidemic so as to help planning effective control strategies. In particular, in order to properly interpret the available data, it has become clear that one must go beyond most classic epidemiological models and consider models that, like the recently proposed SIDARTHE, offer a richer description of the stages of infection. The problem of learning the parameters of these models is of crucial importance especially when assuming that they are time-variant, which further enriches their effectiveness. In this paper we propose a general approach for learning time-variant parameters of dynamic compartmental models from epidemic data. We formulate the problem in terms of a functional risk that depends on the learning variables through the solutions of a dynamic system. The resulting variational problem is then solved by using a gradient flow on a suitable, regularized functional. We forecast the epidemic evolution in Italy and France. Results indicate that the model provides reliable and challenging predictions over all available data as well as the fundamental role of the chosen strategy on the time-variant parameters.
Developing Constrained Neural Units Over Time
Sep 01, 2020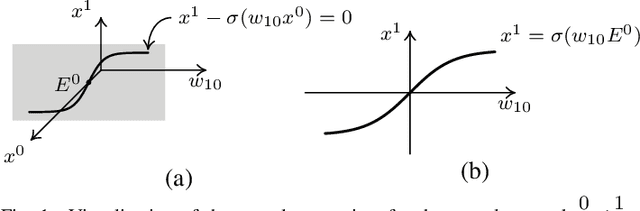
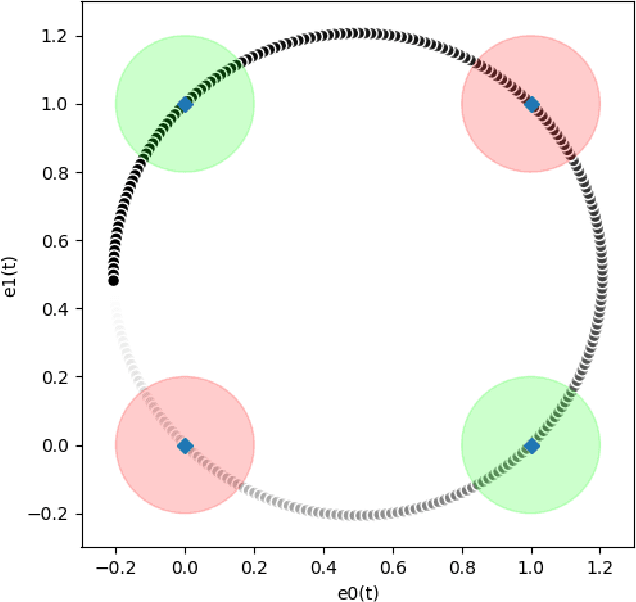
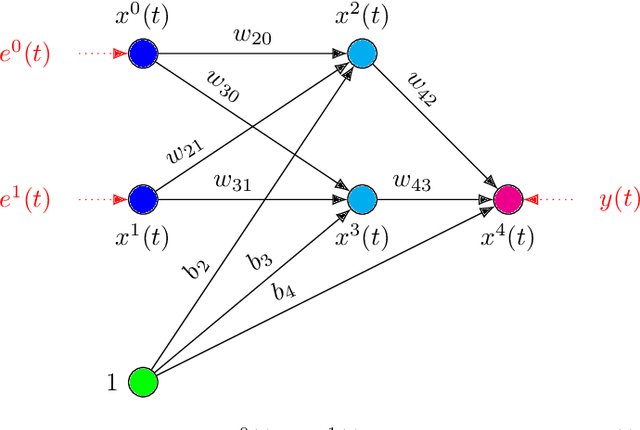
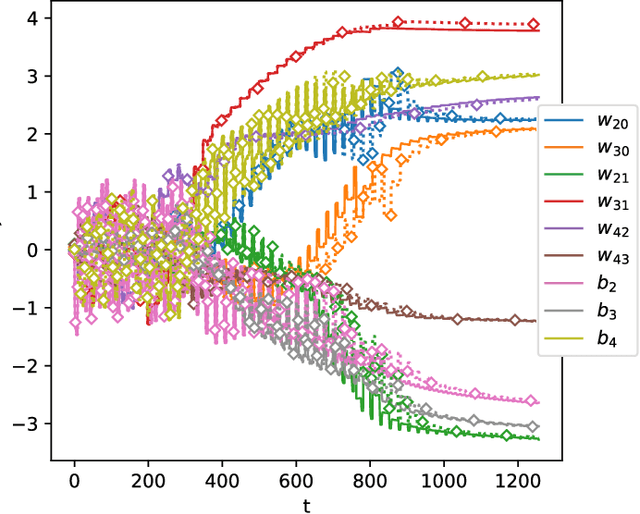
In this paper we present a foundational study on a constrained method that defines learning problems with Neural Networks in the context of the principle of least cognitive action, which very much resembles the principle of least action in mechanics. Starting from a general approach to enforce constraints into the dynamical laws of learning, this work focuses on an alternative way of defining Neural Networks, that is different from the majority of existing approaches. In particular, the structure of the neural architecture is defined by means of a special class of constraints that are extended also to the interaction with data, leading to "architectural" and "input-related" constraints, respectively. The proposed theory is cast into the time domain, in which data are presented to the network in an ordered manner, that makes this study an important step toward alternative ways of processing continuous streams of data with Neural Networks. The connection with the classic Backpropagation-based update rule of the weights of networks is discussed, showing that there are conditions under which our approach degenerates to Backpropagation. Moreover, the theory is experimentally evaluated on a simple problem that allows us to deeply study several aspects of the theory itself and to show the soundness of the model.
Wave Propagation of Visual Stimuli in Focus of Attention
Jun 19, 2020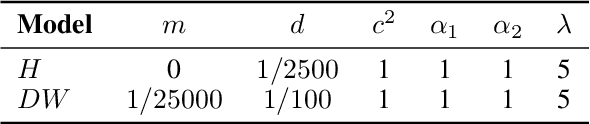

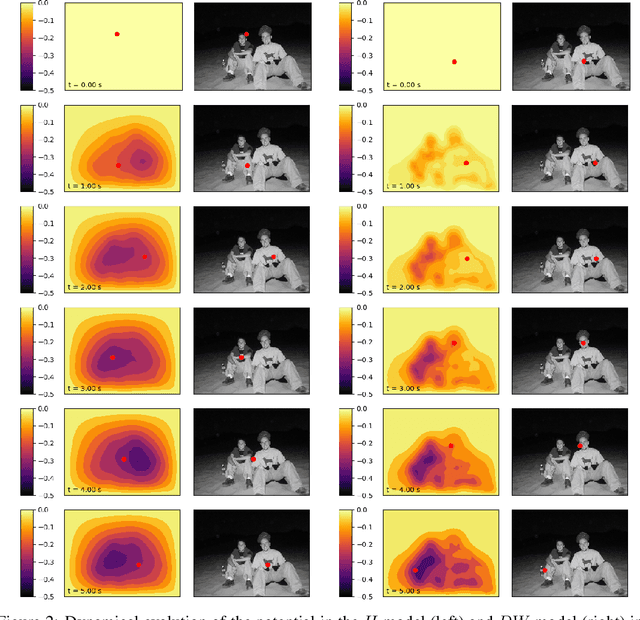
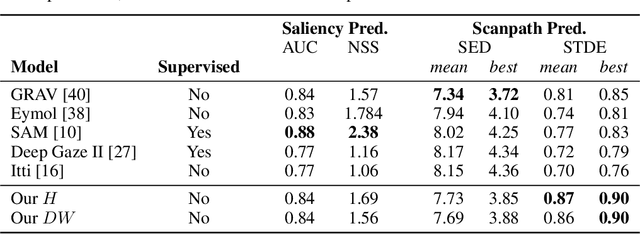
Fast reactions to changes in the surrounding visual environment require efficient attention mechanisms to reallocate computational resources to most relevant locations in the visual field. While current computational models keep improving their predictive ability thanks to the increasing availability of data, they still struggle approximating the effectiveness and efficiency exhibited by foveated animals. In this paper, we present a biologically-plausible computational model of focus of attention that exhibits spatiotemporal locality and that is very well-suited for parallel and distributed implementations. Attention emerges as a wave propagation process originated by visual stimuli corresponding to details and motion information. The resulting field obeys the principle of "inhibition of return" so as not to get stuck in potential holes. An accurate experimentation of the model shows that it achieves top level performance in scanpath prediction tasks. This can easily be understood at the light of a theoretical result that we establish in the paper, where we prove that as the velocity of wave propagation goes to infinity, the proposed model reduces to recently proposed state of the art gravitational models of focus of attention.
Focus of Attention Improves Information Transfer in Visual Features
Jun 16, 2020
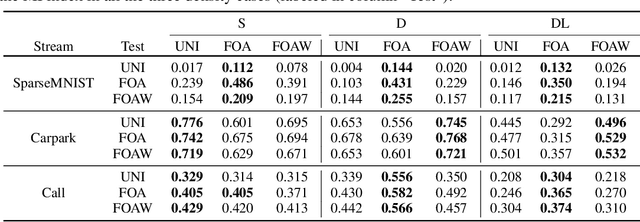

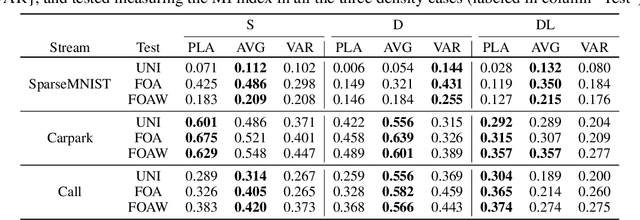
Unsupervised learning from continuous visual streams is a challenging problem that cannot be naturally and efficiently managed in the classic batch-mode setting of computation. The information stream must be carefully processed accordingly to an appropriate spatio-temporal distribution of the visual data, while most approaches of learning commonly assume uniform probability density. In this paper we focus on unsupervised learning for transferring visual information in a truly online setting by using a computational model that is inspired to the principle of least action in physics. The maximization of the mutual information is carried out by a temporal process which yields online estimation of the entropy terms. The model, which is based on second-order differential equations, maximizes the information transfer from the input to a discrete space of symbols related to the visual features of the input, whose computation is supported by hidden neurons. In order to better structure the input probability distribution, we use a human-like focus of attention model that, coherently with the information maximization model, is also based on second-order differential equations. We provide experimental results to support the theory by showing that the spatio-temporal filtering induced by the focus of attention allows the system to globally transfer more information from the input stream over the focused areas and, in some contexts, over the whole frames with respect to the unfiltered case that yields uniform probability distributions.
Local Propagation in Constraint-based Neural Network
Feb 18, 2020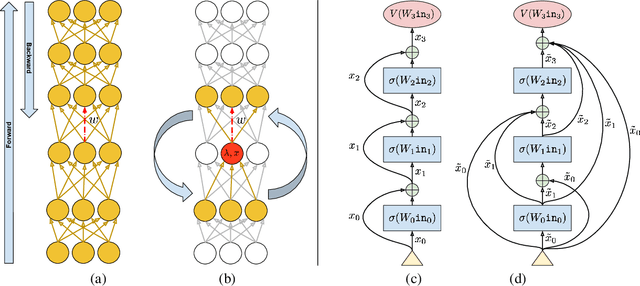
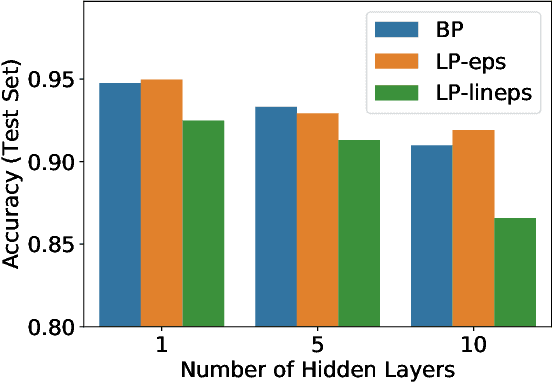
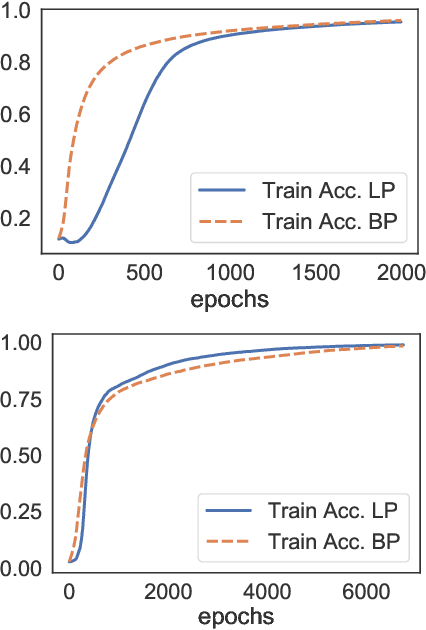
In this paper we study a constraint-based representation of neural network architectures. We cast the learning problem in the Lagrangian framework and we investigate a simple optimization procedure that is well suited to fulfil the so-called architectural constraints, learning from the available supervisions. The computational structure of the proposed Local Propagation (LP) algorithm is based on the search for saddle points in the adjoint space composed of weights, neural outputs, and Lagrange multipliers. All the updates of the model variables are locally performed, so that LP is fully parallelizable over the neural units, circumventing the classic problem of gradient vanishing in deep networks. The implementation of popular neural models is described in the context of LP, together with those conditions that trace a natural connection with Backpropagation. We also investigate the setting in which we tolerate bounded violations of the architectural constraints, and we provide experimental evidence that LP is a feasible approach to train shallow and deep networks, opening the road to further investigations on more complex architectures, easily describable by constraints.
Real-Time target detection in maritime scenarios based on YOLOv3 model
Feb 10, 2020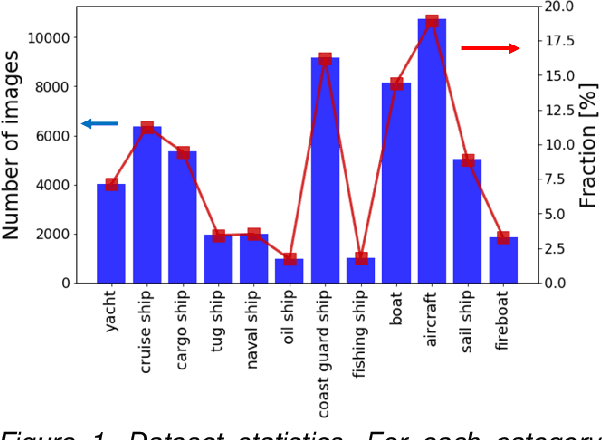

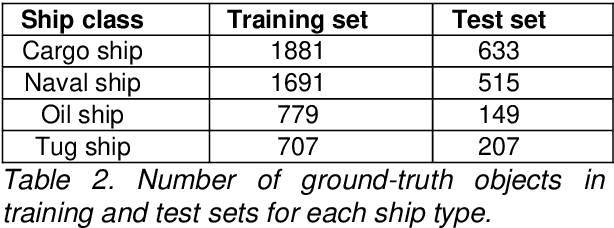

In this work a novel ships dataset is proposed consisting of more than 56k images of marine vessels collected by means of web-scraping and including 12 ship categories. A YOLOv3 single-stage detector based on Keras API is built on top of this dataset. Current results on four categories (cargo ship, naval ship, oil ship and tug ship) show Average Precision up to 96% for Intersection over Union (IoU) of 0.5 and satisfactory detection performances up to IoU of 0.8. A Data Analytics GUI service based on QT framework and Darknet-53 engine is also implemented in order to simplify the deployment process and analyse massive amount of images even for people without Data Science expertise.