 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroduction to optimization methods for training SciML models
Jan 15, 2026Optimization is central to both modern machine learning (ML) and scientific machine learning (SciML), yet the structure of the underlying optimization problems differs substantially across these domains. Classical ML typically relies on stochastic, sample-separable objectives that favor first-order and adaptive gradient methods. In contrast, SciML often involves physics-informed or operator-constrained formulations in which differential operators induce global coupling, stiffness, and strong anisotropy in the loss landscape. As a result, optimization behavior in SciML is governed by the spectral properties of the underlying physical models rather than by data statistics, frequently limiting the effectiveness of standard stochastic methods and motivating deterministic or curvature-aware approaches. This document provides a unified introduction to optimization methods in ML and SciML, emphasizing how problem structure shapes algorithmic choices. We review first- and second-order optimization techniques in both deterministic and stochastic settings, discuss their adaptation to physics-constrained and data-driven SciML models, and illustrate practical strategies through tutorial examples, while highlighting open research directions at the interface of scientific computing and scientific machine learning.
Layer-Parallel Training for Transformers
Jan 13, 2026We present a new training methodology for transformers using a multilevel, layer-parallel approach. Through a neural ODE formulation of transformers, our application of a multilevel parallel-in-time algorithm for the forward and backpropagation phases of training achieves parallel acceleration over the layer dimension. This dramatically enhances parallel scalability as the network depth increases, which is particularly useful for increasingly large foundational models. However, achieving this introduces errors that cause systematic bias in the gradients, which in turn reduces convergence when closer to the minima. We develop an algorithm to detect this critical transition and either switch to serial training or systematically increase the accuracy of layer-parallel training. Results, including BERT, GPT2, ViT, and machine translation architectures, demonstrate parallel-acceleration as well as accuracy commensurate with serial pre-training while fine-tuning is unaffected.
Multi-Preconditioned LBFGS for Training Finite-Basis PINNs
Jan 13, 2026A multi-preconditioned LBFGS (MP-LBFGS) algorithm is introduced for training finite-basis physics-informed neural networks (FBPINNs). The algorithm is motivated by the nonlinear additive Schwarz method and exploits the domain-decomposition-inspired additive architecture of FBPINNs, in which local neural networks are defined on subdomains, thereby localizing the network representation. Parallel, subdomain-local quasi-Newton corrections are then constructed on the corresponding local parts of the architecture. A key feature is a novel nonlinear multi-preconditioning mechanism, in which subdomain corrections are optimally combined through the solution of a low-dimensional subspace minimization problem. Numerical experiments indicate that MP-LBFGS can improve convergence speed, as well as model accuracy over standard LBFGS while incurring lower communication overhead.
Leveraging Operator Learning to Accelerate Convergence of the Preconditioned Conjugate Gradient Method
Jul 31, 2025We propose a new deflation strategy to accelerate the convergence of the preconditioned conjugate gradient(PCG) method for solving parametric large-scale linear systems of equations. Unlike traditional deflation techniques that rely on eigenvector approximations or recycled Krylov subspaces, we generate the deflation subspaces using operator learning, specifically the Deep Operator Network~(DeepONet). To this aim, we introduce two complementary approaches for assembling the deflation operators. The first approach approximates near-null space vectors of the discrete PDE operator using the basis functions learned by the DeepONet. The second approach directly leverages solutions predicted by the DeepONet. To further enhance convergence, we also propose several strategies for prescribing the sparsity pattern of the deflation operator. A comprehensive set of numerical experiments encompassing steady-state, time-dependent, scalar, and vector-valued problems posed on both structured and unstructured geometries is presented and demonstrates the effectiveness of the proposed DeepONet-based deflated PCG method, as well as its generalization across a wide range of model parameters and problem resolutions.
Recursive Bound-Constrained AdaGrad with Applications to Multilevel and Domain Decomposition Minimization
Jul 15, 2025Two OFFO (Objective-Function Free Optimization) noise tolerant algorithms are presented that handle bound constraints, inexact gradients and use second-order information when available.The first is a multi-level method exploiting a hierarchical description of the problem and the second is a domain-decomposition method covering the standard addditive Schwarz decompositions. Both are generalizations of the first-order AdaGrad algorithm for unconstrained optimization. Because these algorithms share a common theoretical framework, a single convergence/complexity theory is provided which covers them both. Its main result is that, with high probability, both methods need at most $O(\epsilon^{-2})$ iterations and noisy gradient evaluations to compute an $\epsilon$-approximate first-order critical point of the bound-constrained problem. Extensive numerical experiments are discussed on applications ranging from PDE-based problems to deep neural network training, illustrating their remarkable computational efficiency.
Data-Parallel Neural Network Training via Nonlinearly Preconditioned Trust-Region Method
Feb 07, 2025

Parallel training methods are increasingly relevant in machine learning (ML) due to the continuing growth in model and dataset sizes. We propose a variant of the Additively Preconditioned Trust-Region Strategy (APTS) for training deep neural networks (DNNs). The proposed APTS method utilizes a data-parallel approach to construct a nonlinear preconditioner employed in the nonlinear optimization strategy. In contrast to the common employment of Stochastic Gradient Descent (SGD) and Adaptive Moment Estimation (Adam), which are both variants of gradient descent (GD) algorithms, the APTS method implicitly adjusts the step sizes in each iteration, thereby removing the need for costly hyperparameter tuning. We demonstrate the performance of the proposed APTS variant using the MNIST and CIFAR-10 datasets. The results obtained indicate that the APTS variant proposed here achieves comparable validation accuracy to SGD and Adam, all while allowing for parallel training and obviating the need for expensive hyperparameter tuning.
Two-level overlapping additive Schwarz preconditioner for training scientific machine learning applications
Jun 16, 2024



We introduce a novel two-level overlapping additive Schwarz preconditioner for accelerating the training of scientific machine learning applications. The design of the proposed preconditioner is motivated by the nonlinear two-level overlapping additive Schwarz preconditioner. The neural network parameters are decomposed into groups (subdomains) with overlapping regions. In addition, the network's feed-forward structure is indirectly imposed through a novel subdomain-wise synchronization strategy and a coarse-level training step. Through a series of numerical experiments, which consider physics-informed neural networks and operator learning approaches, we demonstrate that the proposed two-level preconditioner significantly speeds up the convergence of the standard (LBFGS) optimizer while also yielding more accurate machine learning models. Moreover, the devised preconditioner is designed to take advantage of model-parallel computations, which can further reduce the training time.
Parallel Trust-Region Approaches in Neural Network Training: Beyond Traditional Methods
Dec 21, 2023

We propose to train neural networks (NNs) using a novel variant of the ``Additively Preconditioned Trust-region Strategy'' (APTS). The proposed method is based on a parallelizable additive domain decomposition approach applied to the neural network's parameters. Built upon the TR framework, the APTS method ensures global convergence towards a minimizer. Moreover, it eliminates the need for computationally expensive hyper-parameter tuning, as the TR algorithm automatically determines the step size in each iteration. We demonstrate the capabilities, strengths, and limitations of the proposed APTS training method by performing a series of numerical experiments. The presented numerical study includes a comparison with widely used training methods such as SGD, Adam, LBFGS, and the standard TR method.
Enhancing training of physics-informed neural networks using domain-decomposition based preconditioning strategies
Jun 30, 2023



We propose to enhance the training of physics-informed neural networks (PINNs). To this aim, we introduce nonlinear additive and multiplicative preconditioning strategies for the widely used L-BFGS optimizer. The nonlinear preconditioners are constructed by utilizing the Schwarz domain-decomposition framework, where the parameters of the network are decomposed in a layer-wise manner. Through a series of numerical experiments, we demonstrate that both, additive and multiplicative preconditioners significantly improve the convergence of the standard L-BFGS optimizer, while providing more accurate solutions of the underlying partial differential equations. Moreover, the additive preconditioner is inherently parallel, thus giving rise to a novel approach to model parallelism.
Globally Convergent Multilevel Training of Deep Residual Networks
Jul 15, 2021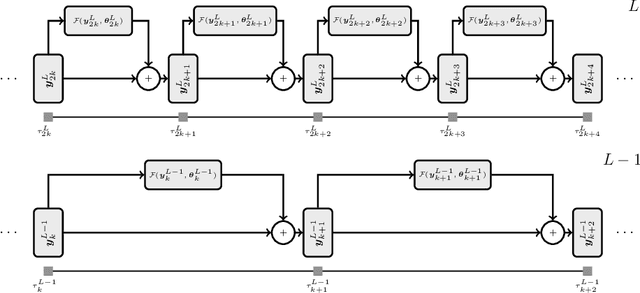


We propose a globally convergent multilevel training method for deep residual networks (ResNets). The devised method can be seen as a novel variant of the recursive multilevel trust-region (RMTR) method, which operates in hybrid (stochastic-deterministic) settings by adaptively adjusting mini-batch sizes during the training. The multilevel hierarchy and the transfer operators are constructed by exploiting a dynamical system's viewpoint, which interprets forward propagation through the ResNet as a forward Euler discretization of an initial value problem. In contrast to traditional training approaches, our novel RMTR method also incorporates curvature information on all levels of the multilevel hierarchy by means of the limited-memory SR1 method. The overall performance and the convergence properties of our multilevel training method are numerically investigated using examples from the field of classification and regression.