 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargum -- A Multilingual New Testament Translation Corpus
Feb 10, 2026Many European languages possess rich biblical translation histories, yet existing corpora - in prioritizing linguistic breadth - often fail to capture this depth. To address this gap, we introduce a multilingual corpus of 657 New Testament translations, of which 352 are unique, with unprecedented depth in five languages: English (208 unique versions from 396 total), French (41 from 78), Italian (18 from 33), Polish (30 from 48), and Spanish (55 from 102). Aggregated from 12 online biblical libraries and one preexisting corpus, each translation is manually annotated with metadata that maps the text to a standardized identifier for the work, its specific edition, and its year of revision. This canonicalization empowers researchers to define "uniqueness" for their own needs: they can perform micro-level analyses on translation families, such as the KJV lineage, or conduct macro-level studies by deduplicating closely related texts. By providing the first resource designed for such flexible, multilevel analysis, our corpus establishes a new benchmark for the quantitative study of translation history.
LLM-as-a-Judge is Bad, Based on AI Attempting the Exam Qualifying for the Member of the Polish National Board of Appeal
Nov 06, 2025



This study provides an empirical assessment of whether current large language models (LLMs) can pass the official qualifying examination for membership in Poland's National Appeal Chamber (Krajowa Izba Odwoławcza). The authors examine two related ideas: using LLM as actual exam candidates and applying the 'LLM-as-a-judge' approach, in which model-generated answers are automatically evaluated by other models. The paper describes the structure of the exam, which includes a multiple-choice knowledge test on public procurement law and a written judgment, and presents the hybrid information recovery and extraction pipeline built to support the models. Several LLMs (including GPT-4.1, Claude 4 Sonnet and Bielik-11B-v2.6) were tested in closed-book and various Retrieval-Augmented Generation settings. The results show that although the models achieved satisfactory scores in the knowledge test, none met the passing threshold in the practical written part, and the evaluations of the 'LLM-as-a-judge' often diverged from the judgments of the official examining committee. The authors highlight key limitations: susceptibility to hallucinations, incorrect citation of legal provisions, weaknesses in logical argumentation, and the need for close collaboration between legal experts and technical teams. The findings indicate that, despite rapid technological progress, current LLMs cannot yet replace human judges or independent examiners in Polish public procurement adjudication.
eFontes. Part of Speech Tagging and Lemmatization of Medieval Latin Texts.A Cross-Genre Survey
Jun 29, 2024



This study introduces the eFontes models for automatic linguistic annotation of Medieval Latin texts, focusing on lemmatization, part-of-speech tagging, and morphological feature determination. Using the Transformers library, these models were trained on Universal Dependencies (UD) corpora and the newly developed eFontes corpus of Polish Medieval Latin. The research evaluates the models' performance, addressing challenges such as orthographic variations and the integration of Latinized vernacular terms. The models achieved high accuracy rates: lemmatization at 92.60%, part-of-speech tagging at 83.29%, and morphological feature determination at 88.57%. The findings underscore the importance of high-quality annotated corpora and propose future enhancements, including extending the models to Named Entity Recognition.
Improving Classifier Training Efficiency for Automatic Cyberbullying Detection with Feature Density
Nov 03, 2021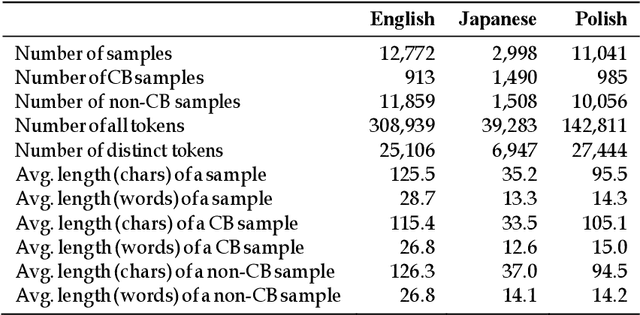
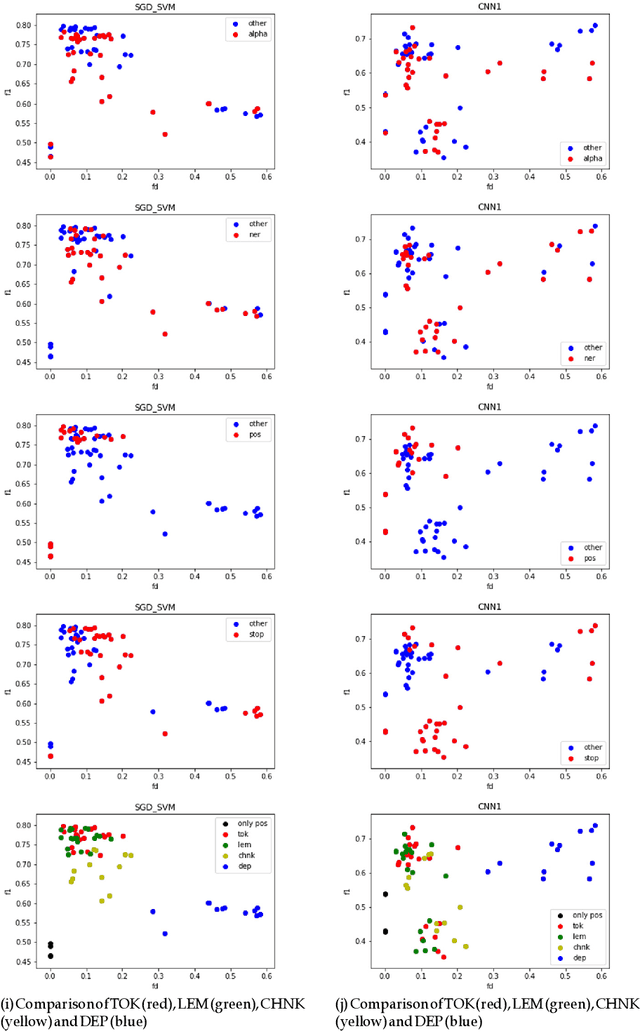
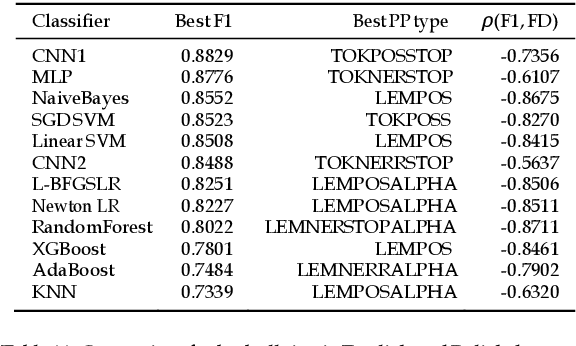
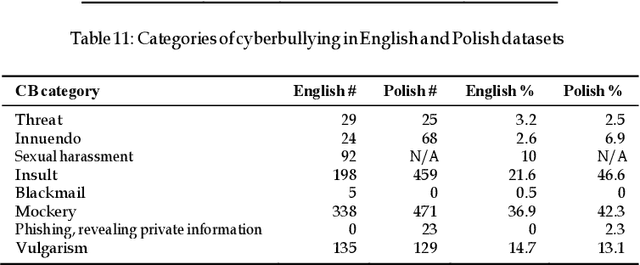
We study the effectiveness of Feature Density (FD) using different linguistically-backed feature preprocessing methods in order to estimate dataset complexity, which in turn is used to comparatively estimate the potential performance of machine learning (ML) classifiers prior to any training. We hypothesise that estimating dataset complexity allows for the reduction of the number of required experiments iterations. This way we can optimize the resource-intensive training of ML models which is becoming a serious issue due to the increases in available dataset sizes and the ever rising popularity of models based on Deep Neural Networks (DNN). The problem of constantly increasing needs for more powerful computational resources is also affecting the environment due to alarmingly-growing amount of CO2 emissions caused by training of large-scale ML models. The research was conducted on multiple datasets, including popular datasets, such as Yelp business review dataset used for training typical sentiment analysis models, as well as more recent datasets trying to tackle the problem of cyberbullying, which, being a serious social problem, is also a much more sophisticated problem form the point of view of linguistic representation. We use cyberbullying datasets collected for multiple languages, namely English, Japanese and Polish. The difference in linguistic complexity of datasets allows us to additionally discuss the efficacy of linguistically-backed word preprocessing.
* 73 pages, 4 figures, 19 tables, Information Processing and Management, Vol. 58, Issue 5, September 2021, paper ID: 102616
Cyberbullying Detection -- Technical Report 2/2018, Department of Computer Science AGH, University of Science and Technology
Aug 02, 2018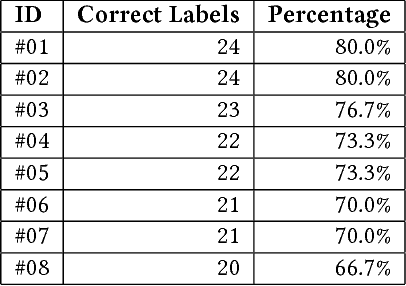
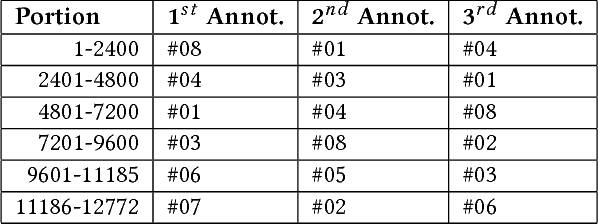
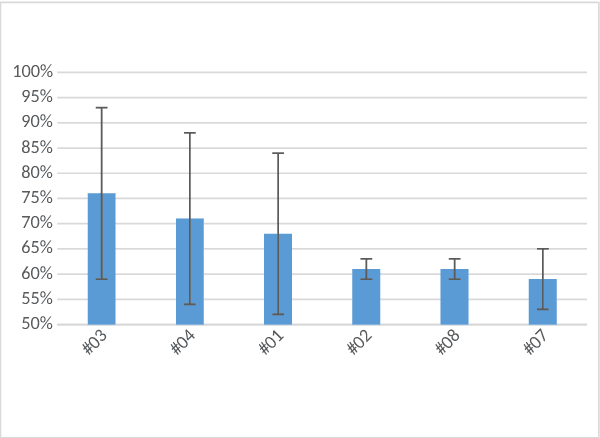
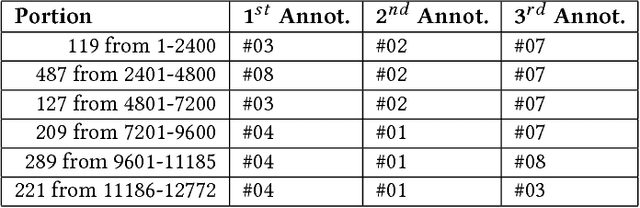
The research described in this paper concerns automatic cyberbullying detection in social media. There are two goals to achieve: building a gold standard cyberbullying detection dataset and measuring the performance of the Samurai cyberbullying detection system. The Formspring dataset provided in a Kaggle competition was re-annotated as a part of the research. The annotation procedure is described in detail and, unlike many other recent data annotation initiatives, does not use Mechanical Turk for finding people willing to perform the annotation. The new annotation compared to the old one seems to be more coherent since all tested cyberbullying detection system performed better on the former. The performance of the Samurai system is compared with 5 commercial systems and one well-known machine learning algorithm, used for classifying textual content, namely Fasttext. It turns out that Samurai scores the best in all measures (accuracy, precision and recall), while Fasttext is the second-best performing algorithm.
Improving text classification with vectors of reduced precision
Jun 20, 2017
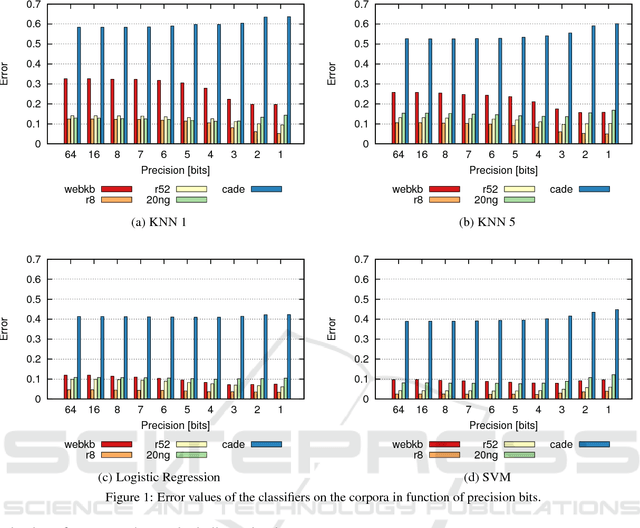
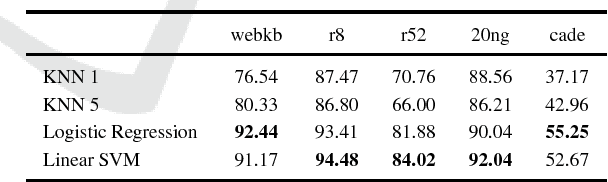
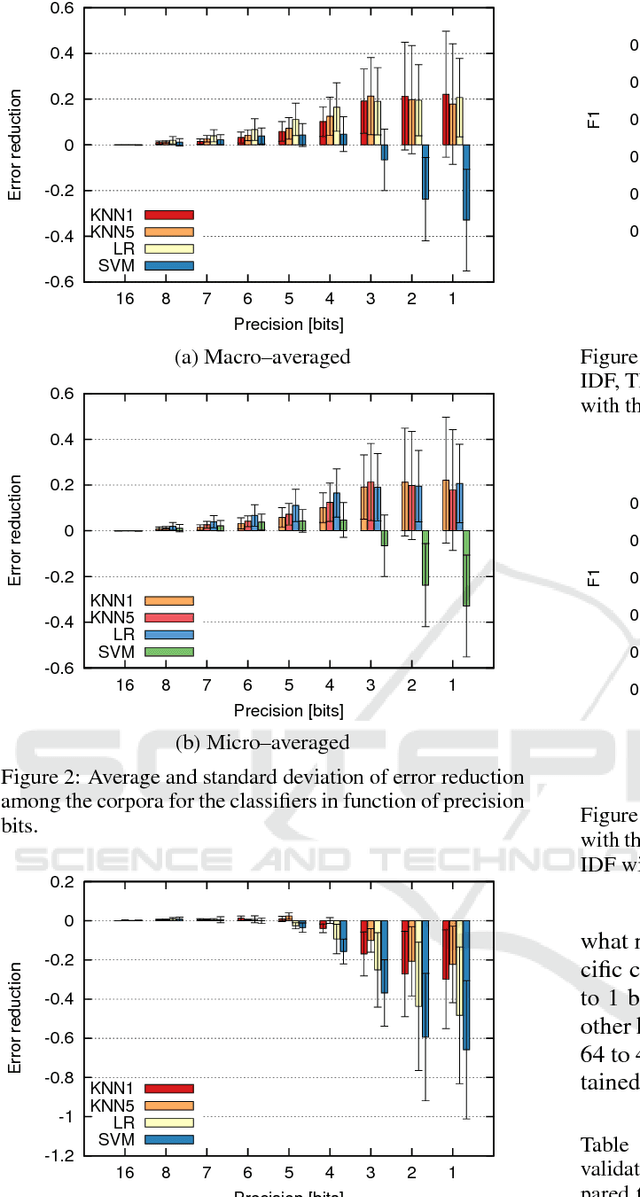
This paper presents the analysis of the impact of a floating-point number precision reduction on the quality of text classification. The precision reduction of the vectors representing the data (e.g. TF-IDF representation in our case) allows for a decrease of computing time and memory footprint on dedicated hardware platforms. The impact of precision reduction on the classification quality was performed on 5 corpora, using 4 different classifiers. Also, dimensionality reduction was taken into account. Results indicate that the precision reduction improves classification accuracy for most cases (up to 25% of error reduction). In general, the reduction from 64 to 4 bits gives the best scores and ensures that the results will not be worse than with the full floating-point representation.