 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Synthetic Data definitions: A privacy driven approach
Mar 05, 2025

Synthetic data is gaining traction as a cost-effective solution for the increasing data demands of AI development and can be generated either from existing knowledge or derived data captured from real-world events. The source of the synthetic data generation and the technique used significantly impacts its residual privacy risk and therefore its opportunity for sharing. Traditional classification of synthetic data types no longer fit the newer generation techniques and there is a need to better align the classification with practical needs. We suggest a new way of grouping synthetic data types that better supports privacy evaluations to aid regulatory policymaking. Our novel classification provides flexibility to new advancements like deep generative methods and offers a more practical framework for future applications.
Artificial intelligence to improve clinical coding practice in Scandinavia: a crossover randomized controlled trial
Oct 31, 2024



\textbf{Trial design} Crossover randomized controlled trial. \textbf{Methods} An AI tool, Easy-ICD, was developed to assist clinical coders and was tested for improving both accuracy and time in a user study in Norway and Sweden. Participants were randomly assigned to two groups, and crossed over between coding complex (longer) texts versus simple (shorter) texts, while using our tool versus not using our tool. \textbf{Results} Based on Mann-Whitney U test, the median coding time difference for complex clinical text sequences was 123 seconds (\emph{P}\textless.001, 95\% CI: 81 to 164), representing a 46\% reduction in median coding time when our tool is used. There was no significant time difference for simpler text sequences. For coding accuracy, the improvement we noted for both complex and simple texts was not significant. \textbf{Conclusions} This study demonstrates the potential of AI to transform common tasks in clinical workflows, with ostensible positive impacts on work efficiencies for complex clinical coding tasks. Further studies within hospital workflows are required before these presumed impacts can be more clearly understood.
Implementing a Nordic-Baltic Federated Health Data Network: a case report
Sep 26, 2024

Background: Centralized collection and processing of healthcare data across national borders pose significant challenges, including privacy concerns, data heterogeneity and legal barriers. To address some of these challenges, we formed an interdisciplinary consortium to develop a feder-ated health data network, comprised of six institutions across five countries, to facilitate Nordic-Baltic cooperation on secondary use of health data. The objective of this report is to offer early insights into our experiences developing this network. Methods: We used a mixed-method ap-proach, combining both experimental design and implementation science to evaluate the factors affecting the implementation of our network. Results: Technically, our experiments indicate that the network functions without significant performance degradation compared to centralized simu-lation. Conclusion: While use of interdisciplinary approaches holds a potential to solve challeng-es associated with establishing such collaborative networks, our findings turn the spotlight on the uncertain regulatory landscape playing catch up and the significant operational costs.
Can I trust my fake data -- A comprehensive quality assessment framework for synthetic tabular data in healthcare
Jan 24, 2024



Ensuring safe adoption of AI tools in healthcare hinges on access to sufficient data for training, testing and validation. In response to privacy concerns and regulatory requirements, using synthetic data has been suggested. Synthetic data is created by training a generator on real data to produce a dataset with similar statistical properties. Competing metrics with differing taxonomies for quality evaluation have been suggested, resulting in a complex landscape. Optimising quality entails balancing considerations that make the data fit for use, yet relevant dimensions are left out of existing frameworks. We performed a comprehensive literature review on the use of quality evaluation metrics on SD within the scope of tabular healthcare data and SD made using deep generative methods. Based on this and the collective team experiences, we developed a conceptual framework for quality assurance. The applicability was benchmarked against a practical case from the Dutch National Cancer Registry. We present a conceptual framework for quality assurance of SD for AI applications in healthcare that aligns diverging taxonomies, expands on common quality dimensions to include the dimensions of Fairness and Carbon footprint, and proposes stages necessary to support real-life applications. Building trust in synthetic data by increasing transparency and reducing the safety risk will accelerate the development and uptake of trustworthy AI tools for the benefit of patients. Despite the growing emphasis on algorithmic fairness and carbon footprint, these metrics were scarce in the literature review. The overwhelming focus was on statistical similarity using distance metrics while sequential logic detection was scarce. A consensus-backed framework that includes all relevant quality dimensions can provide assurance for safe and responsible real-life applications of SD.
Unpacking Human-AI Interaction in Safety-Critical Industries: A Systematic Literature Review
Oct 05, 2023



Ensuring quality human-AI interaction (HAII) in safety-critical industries is essential. Failure to do so can lead to catastrophic and deadly consequences. Despite this urgency, what little research there is on HAII is fragmented and inconsistent. We present here a survey of that literature and recommendations for research best practices that will improve the field. We divided our investigation into the following research areas: (1) terms used to describe HAII, (2) primary roles of AI-enabled systems, (3) factors that influence HAII, and (4) how HAII is measured. Additionally, we described the capabilities and maturity of the AI-enabled systems used in safety-critical industries discussed in these articles. We found that no single term is used across the literature to describe HAII and some terms have multiple meanings. According to our literature, five factors influence HAII: user characteristics and background (e.g., user personality, perceptions), AI interface and features (e.g., interactive UI design), AI output (e.g., accuracy, actionable recommendations), explainability and interpretability (e.g., level of detail, user understanding), and usage of AI (e.g., heterogeneity of environments and user needs). HAII is most commonly measured with user-related subjective metrics (e.g., user perception, trust, and attitudes), and AI-assisted decision-making is the most common primary role of AI-enabled systems. Based on this review, we conclude that there are substantial research gaps in HAII. Researchers and developers need to codify HAII terminology, involve users throughout the AI lifecycle (especially during development), and tailor HAII in safety-critical industries to the users and environments.
Doppler Spectrum Classification with CNNs via Heatmap Location Encoding and a Multi-head Output Layer
Nov 08, 2019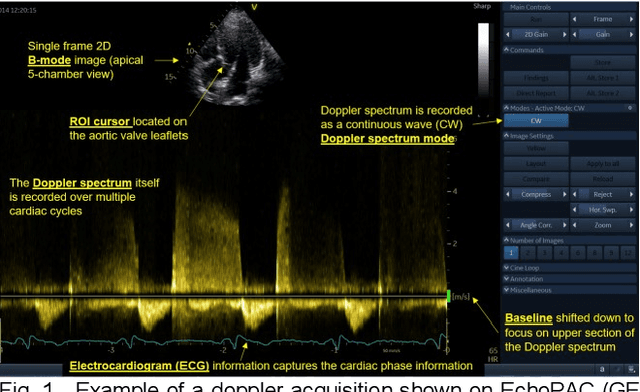
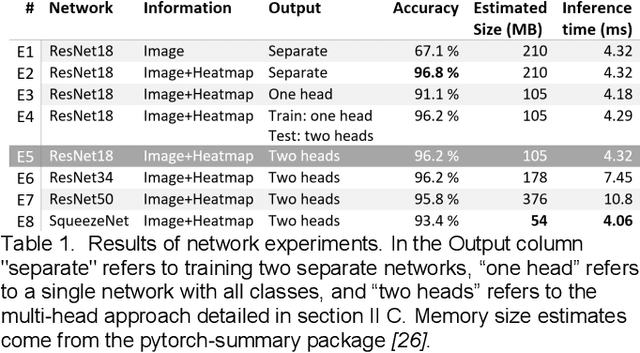
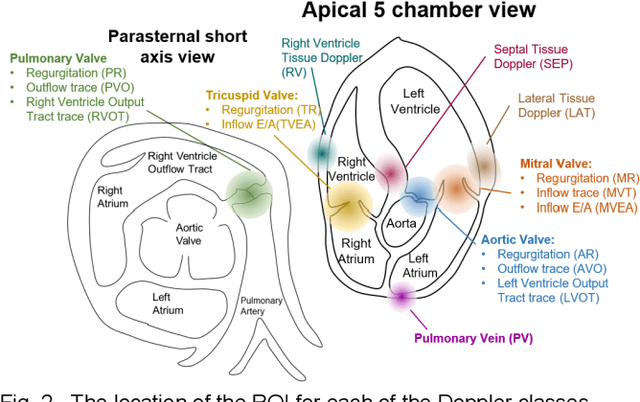

Spectral Doppler measurements are an important part of the standard echocardiographic examination. These measurements give important insight into myocardial motion and blood flow providing clinicians with parameters for diagnostic decision making. Many of these measurements can currently be performed automatically with high accuracy, increasing the efficiency of the diagnostic pipeline. However, full automation is not yet available because the user must manually select which measurement should be performed on each image. In this work we develop a convolutional neural network (CNN) to automatically classify cardiac Doppler spectra into measurement classes. We show how the multi-modal information in each spectral Doppler recording can be combined using a meta parameter post-processing mapping scheme and heatmaps to encode coordinate locations. Additionally, we experiment with several state-of-the-art network architectures to examine the tradeoff between accuracy and memory usage for resource-constrained environments. Finally, we propose a confidence metric using the values in the last fully connected layer of the network. We analyze example images that fall outside of our proposed classes to show our confidence metric can prevent many misclassifications. Our algorithm achieves 96% accuracy on a test set drawn from a separate clinical site, indicating that the proposed method is suitable for clinical adoption and enabling a fully automatic pipeline from acquisition to Doppler spectrum measurements.