 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThreshold-Based Data Exclusion Approach for Energy-Efficient Federated Edge Learning
Mar 30, 2021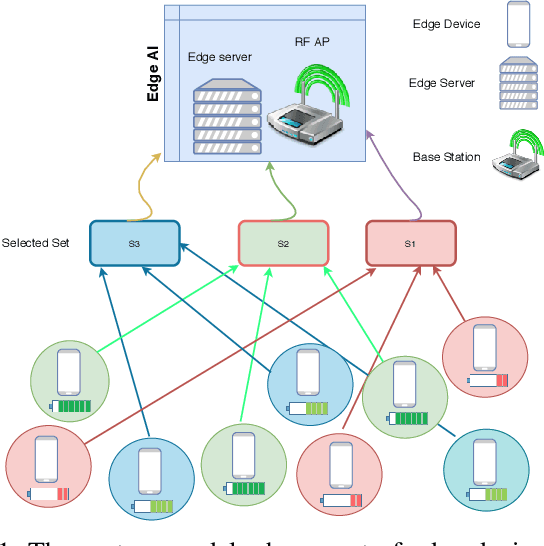
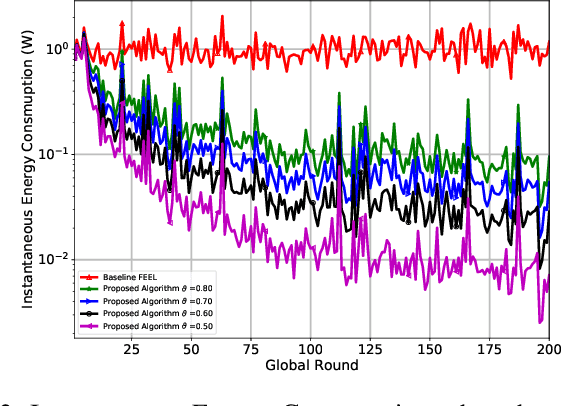
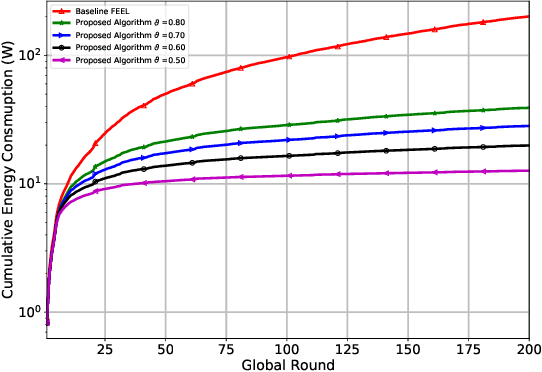
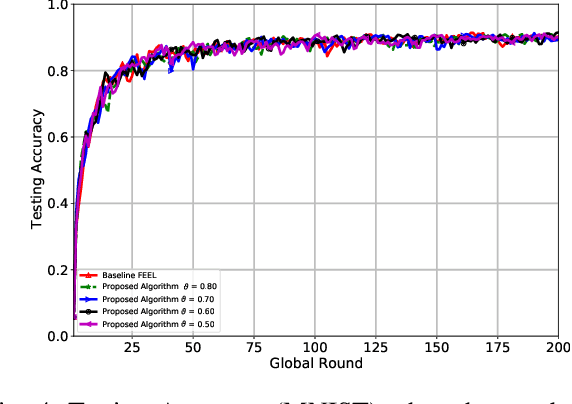
Federated edge learning (FEEL) is a promising distributed learning technique for next-generation wireless networks. FEEL preserves the user's privacy, reduces the communication costs, and exploits the unprecedented capabilities of edge devices to train a shared global model by leveraging a massive amount of data generated at the network edge. However, FEEL might significantly shorten energy-constrained participating devices' lifetime due to the power consumed during the model training round. This paper proposes a novel approach that endeavors to minimize computation and communication energy consumption during FEEL rounds to address this issue. First, we introduce a modified local training algorithm that intelligently selects only the samples that enhance the model's quality based on a predetermined threshold probability. Then, the problem is formulated as joint energy minimization and resource allocation optimization problem to obtain the optimal local computation time and the optimal transmission time that minimize the total energy consumption considering the worker's energy budget, available bandwidth, channel states, beamforming, and local CPU speed. After that, we introduce a tractable solution to the formulated problem that ensures the robustness of FEEL. Our simulation results show that our solution substantially outperforms the baseline FEEL algorithm as it reduces the local consumed energy by up to 79%.
Sentiment Analysis of Users' Reviews on COVID-19 Contact Tracing Apps with a Benchmark Dataset
Mar 01, 2021
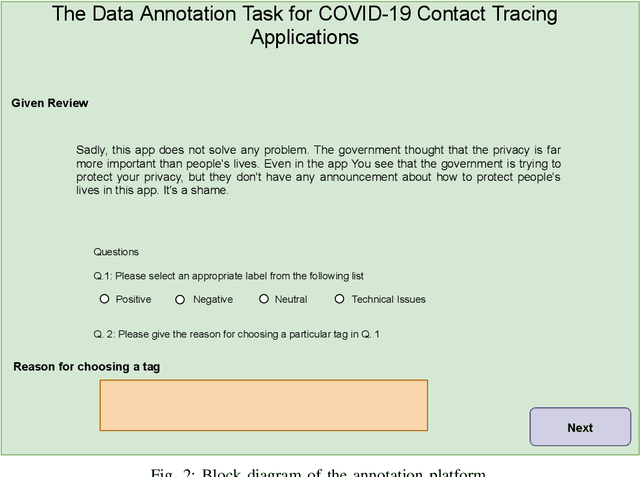
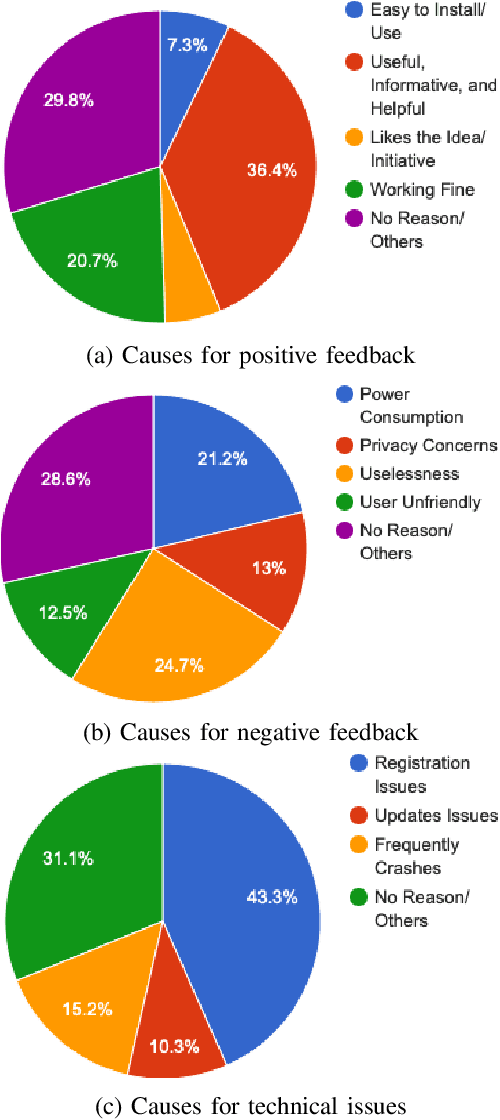
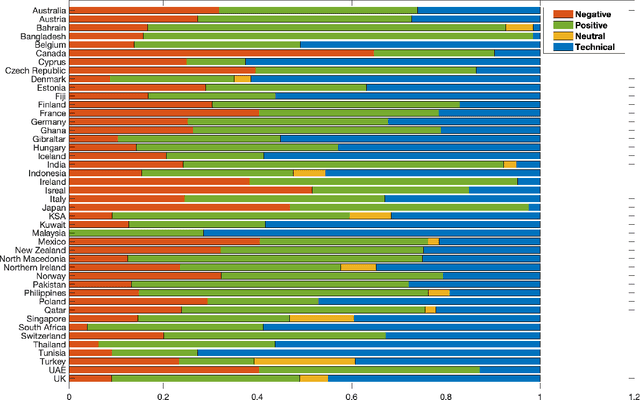
Contact tracing has been globally adopted in the fight to control the infection rate of COVID-19. Thanks to digital technologies, such as smartphones and wearable devices, contacts of COVID-19 patients can be easily traced and informed about their potential exposure to the virus. To this aim, several interesting mobile applications have been developed. However, there are ever-growing concerns over the working mechanism and performance of these applications. The literature already provides some interesting exploratory studies on the community's response to the applications by analyzing information from different sources, such as news and users' reviews of the applications. However, to the best of our knowledge, there is no existing solution that automatically analyzes users' reviews and extracts the evoked sentiments. In this work, we propose a pipeline starting from manual annotation via a crowd-sourcing study and concluding on the development and training of AI models for automatic sentiment analysis of users' reviews. In total, we employ eight different methods achieving up to an average F1-Scores 94.8% indicating the feasibility of automatic sentiment analysis of users' reviews on the COVID-19 contact tracing applications. We also highlight the key advantages, drawbacks, and users' concerns over the applications. Moreover, we also collect and annotate a large-scale dataset composed of 34,534 reviews manually annotated from the contract tracing applications of 46 distinct countries. The presented analysis and the dataset are expected to provide a baseline/benchmark for future research in the domain.
Collaborative Federated Learning For Healthcare: Multi-Modal COVID-19 Diagnosis at the Edge
Jan 19, 2021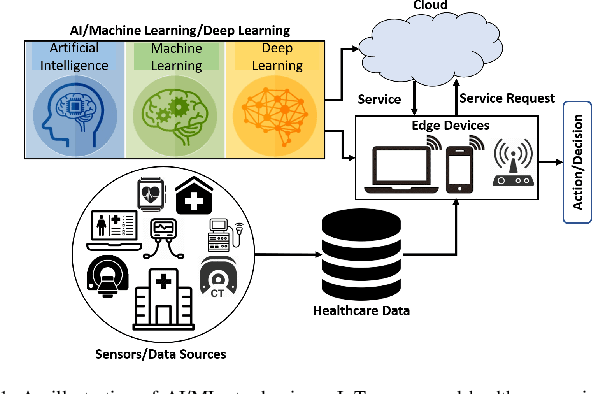
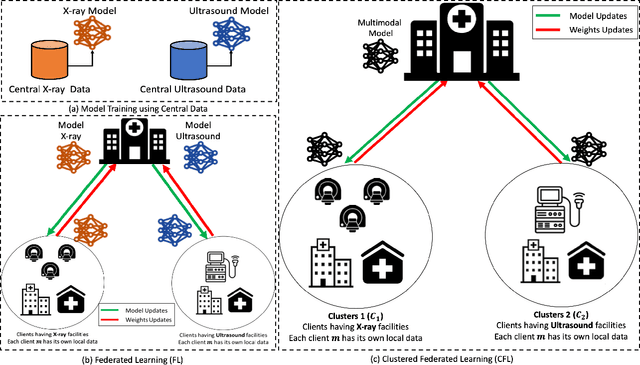
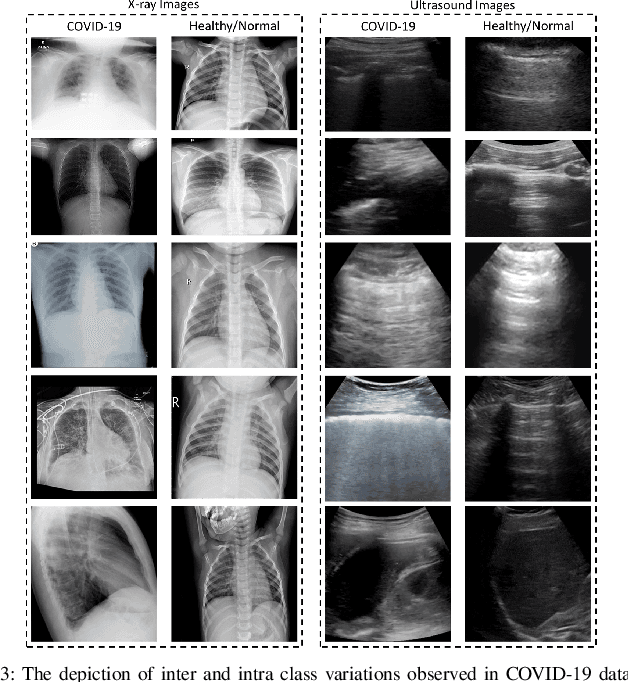
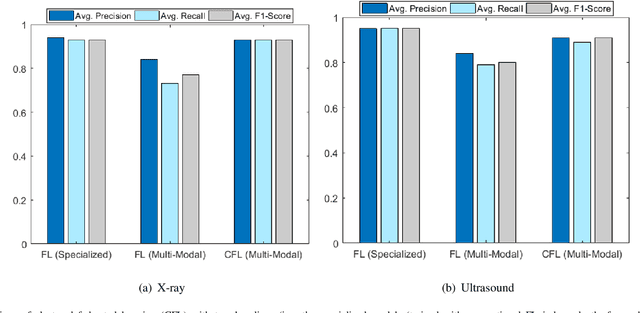
Despite significant improvements over the last few years, cloud-based healthcare applications continue to suffer from poor adoption due to their limitations in meeting stringent security, privacy, and quality of service requirements (such as low latency). The edge computing trend, along with techniques for distributed machine learning such as federated learning, have gained popularity as a viable solution in such settings. In this paper, we leverage the capabilities of edge computing in medicine by analyzing and evaluating the potential of intelligent processing of clinical visual data at the edge allowing the remote healthcare centers, lacking advanced diagnostic facilities, to benefit from the multi-modal data securely. To this aim, we utilize the emerging concept of clustered federated learning (CFL) for an automatic diagnosis of COVID-19. Such an automated system can help reduce the burden on healthcare systems across the world that has been under a lot of stress since the COVID-19 pandemic emerged in late 2019. We evaluate the performance of the proposed framework under different experimental setups on two benchmark datasets. Promising results are obtained on both datasets resulting in comparable results against the central baseline where the specialized models (i.e., each on a specific type of COVID-19 imagery) are trained with central data, and improvements of 16\% and 11\% in overall F1-Scores have been achieved over the multi-modal model trained in the conventional Federated Learning setup on X-ray and Ultrasound datasets, respectively. We also discuss in detail the associated challenges, technologies, tools, and techniques available for deploying ML at the edge in such privacy and delay-sensitive applications.
Developing Future Human-Centered Smart Cities: Critical Analysis of Smart City Security, Interpretability, and Ethical Challenges
Dec 14, 2020
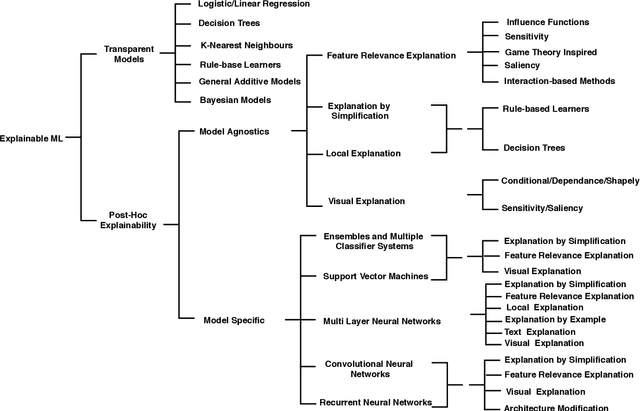
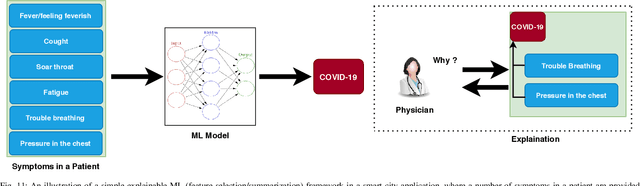
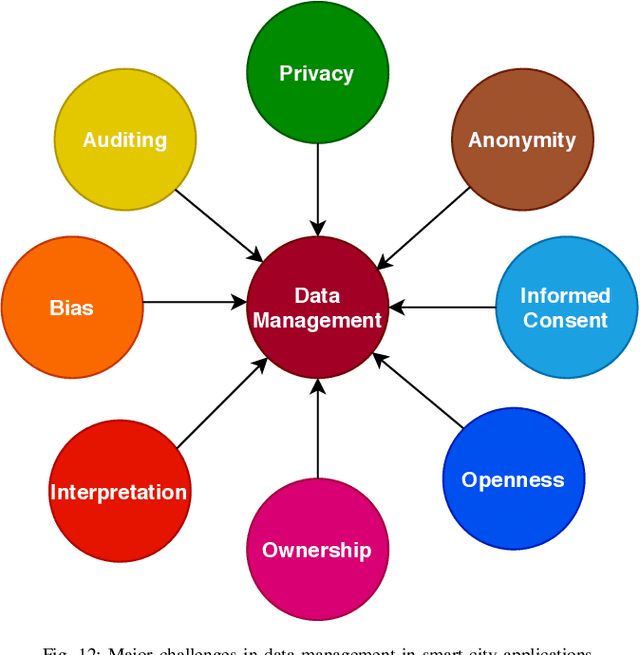
As we make tremendous advances in machine learning and artificial intelligence technosciences, there is a renewed understanding in the AI community that we must ensure that humans being are at the center of our deliberations so that we don't end in technology-induced dystopias. As strongly argued by Green in his book Smart Enough City, the incorporation of technology in city environs does not automatically translate into prosperity, wellbeing, urban livability, or social justice. There is a great need to deliberate on the future of the cities worth living and designing. There are philosophical and ethical questions involved along with various challenges that relate to the security, safety, and interpretability of AI algorithms that will form the technological bedrock of future cities. Several research institutes on human centered AI have been established at top international universities. Globally there are calls for technology to be made more humane and human-compatible. For example, Stuart Russell has a book called Human Compatible AI. The Center for Humane Technology advocates for regulators and technology companies to avoid business models and product features that contribute to social problems such as extremism, polarization, misinformation, and Internet addiction. In this paper, we analyze and explore key challenges including security, robustness, interpretability, and ethical challenges to a successful deployment of AI or ML in human-centric applications, with a particular emphasis on the convergence of these challenges. We provide a detailed review of existing literature on these key challenges and analyze how one of these challenges may lead to others or help in solving other challenges. The paper also advises on the current limitations, pitfalls, and future directions of research in these domains, and how it can fill the current gaps and lead to better solutions.
Fake News Detection in Social Media using Graph Neural Networks and NLP Techniques: A COVID-19 Use-case
Nov 30, 2020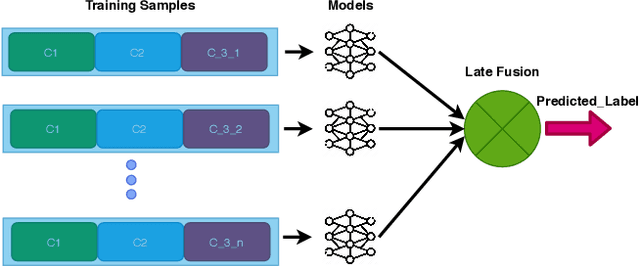
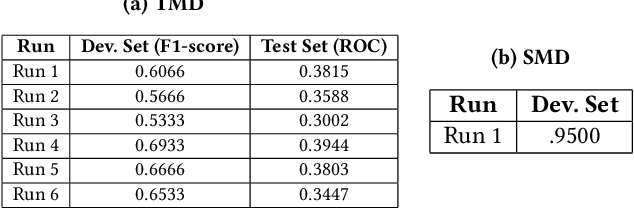
The paper presents our solutions for the MediaEval 2020 task namely FakeNews: Corona Virus and 5G Conspiracy Multimedia Twitter-Data-Based Analysis. The task aims to analyze tweets related to COVID-19 and 5G conspiracy theories to detect misinformation spreaders. The task is composed of two sub-tasks namely (i) text-based, and (ii) structure-based fake news detection. For the first task, we propose six different solutions relying on Bag of Words (BoW) and BERT embedding. Three of the methods aim at binary classification task by differentiating in 5G conspiracy and the rest of the COVID-19 related tweets while the rest of them treat the task as ternary classification problem. In the ternary classification task, our BoW and BERT based methods obtained an F1-score of .606% and .566% on the development set, respectively. On the binary classification, the BoW and BERT based solutions obtained an average F1-score of .666% and .693%, respectively. On the other hand, for structure-based fake news detection, we rely on Graph Neural Networks (GNNs) achieving an average ROC of .95% on the development set.
Floods Detection in Twitter Text and Images
Nov 30, 2020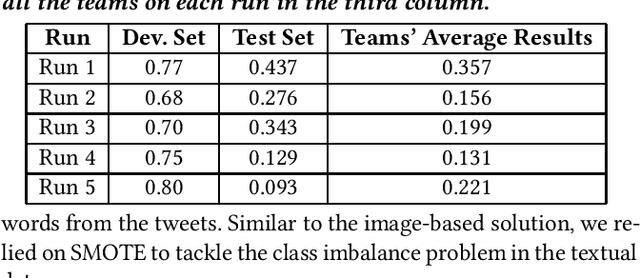
In this paper, we present our methods for the MediaEval 2020 Flood Related Multimedia task, which aims to analyze and combine textual and visual content from social media for the detection of real-world flooding events. The task mainly focuses on identifying floods related tweets relevant to a specific area. We propose several schemes to address the challenge. For text-based flood events detection, we use three different methods, relying on Bog of Words (BOW) and an Italian Version of Bert individually and in combination, achieving an F1-score of 0.77%, 0.68%, and 0.70% on the development set, respectively. For the visual analysis, we rely on features extracted via multiple state-of-the-art deep models pre-trained on ImageNet. The extracted features are then used to train multiple individual classifiers whose scores are then combined in a late fusion manner achieving an F1-score of 0.75%. For our mandatory multi-modal run, we combine the classification scores obtained with the best textual and visual schemes in a late fusion manner. Overall, better results are obtained with the multimodal scheme achieving an F1-score of 0.80% on the development set.
Budgeted Online Selection of Candidate IoT Clients to Participate in Federated Learning
Nov 16, 2020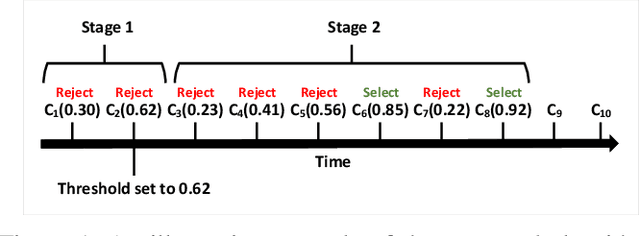
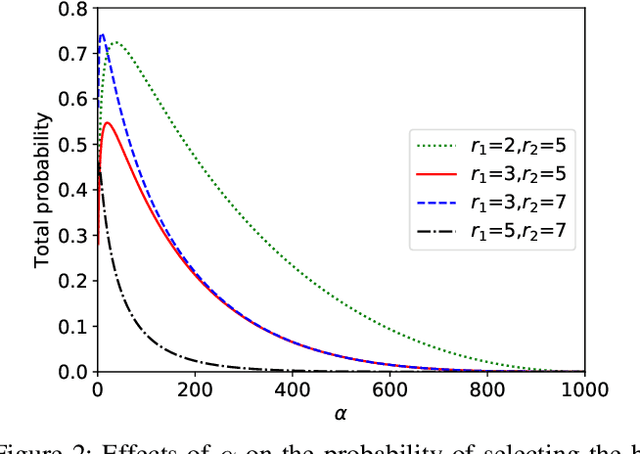
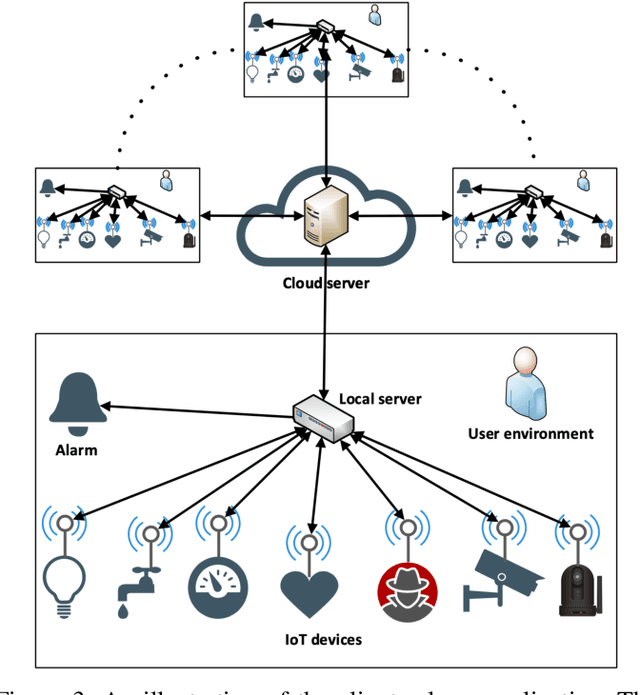

Machine Learning (ML), and Deep Learning (DL) in particular, play a vital role in providing smart services to the industry. These techniques however suffer from privacy and security concerns since data is collected from clients and then stored and processed at a central location. Federated Learning (FL), an architecture in which model parameters are exchanged instead of client data, has been proposed as a solution to these concerns. Nevertheless, FL trains a global model by communicating with clients over communication rounds, which introduces more traffic on the network and increases the convergence time to the target accuracy. In this work, we solve the problem of optimizing accuracy in stateful FL with a budgeted number of candidate clients by selecting the best candidate clients in terms of test accuracy to participate in the training process. Next, we propose an online stateful FL heuristic to find the best candidate clients. Additionally, we propose an IoT client alarm application that utilizes the proposed heuristic in training a stateful FL global model based on IoT device type classification to alert clients about unauthorized IoT devices in their environment. To test the efficiency of the proposed online heuristic, we conduct several experiments using a real dataset and compare the results against state-of-the-art algorithms. Our results indicate that the proposed heuristic outperforms the online random algorithm with up to 27% gain in accuracy. Additionally, the performance of the proposed online heuristic is comparable to the performance of the best offline algorithm.
Particle Swarm Optimized Federated Learning For Industrial IoT and Smart City Services
Sep 05, 2020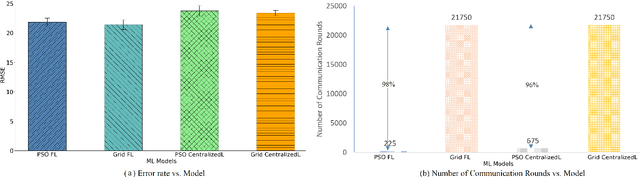
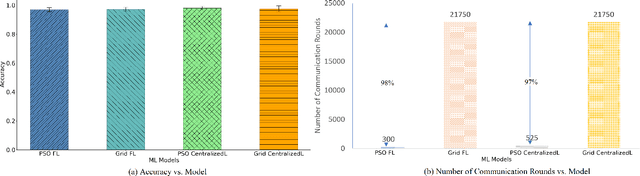
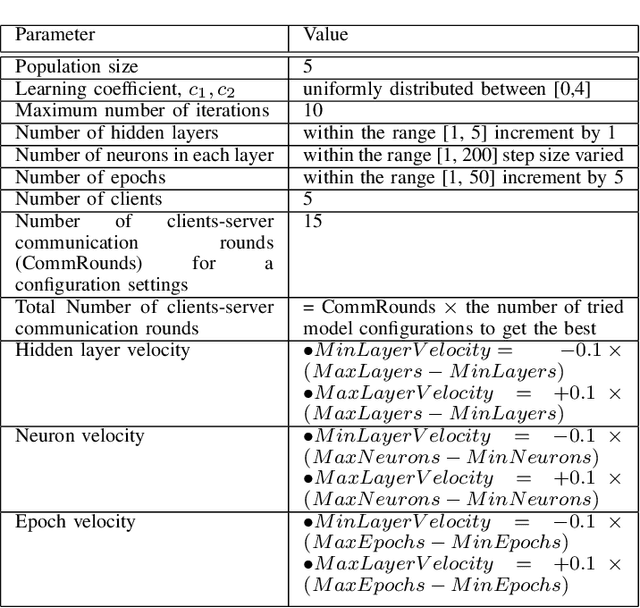
Most of the research on Federated Learning (FL) has focused on analyzing global optimization, privacy, and communication, with limited attention focusing on analyzing the critical matter of performing efficient local training and inference at the edge devices. One of the main challenges for successful and efficient training and inference on edge devices is the careful selection of parameters to build local Machine Learning (ML) models. To this aim, we propose a Particle Swarm Optimization (PSO)-based technique to optimize the hyperparameter settings for the local ML models in an FL environment. We evaluate the performance of our proposed technique using two case studies. First, we consider smart city services and use an experimental transportation dataset for traffic prediction as a proxy for this setting. Second, we consider Industrial IoT (IIoT) services and use the real-time telemetry dataset to predict the probability that a machine will fail shortly due to component failures. Our experiments indicate that PSO provides an efficient approach for tuning the hyperparameters of deep Long short-term memory (LSTM) models when compared to the grid search method. Our experiments illustrate that the number of clients-server communication rounds to explore the landscape of configurations to find the near-optimal parameters are greatly reduced (roughly by two orders of magnitude needing only 2%--4% of the rounds compared to state of the art non-PSO-based approaches). We also demonstrate that utilizing the proposed PSO-based technique to find the near-optimal configurations for FL and centralized learning models does not adversely affect the accuracy of the models.
Visual Sentiment Analysis from Disaster Images in Social Media
Sep 04, 2020


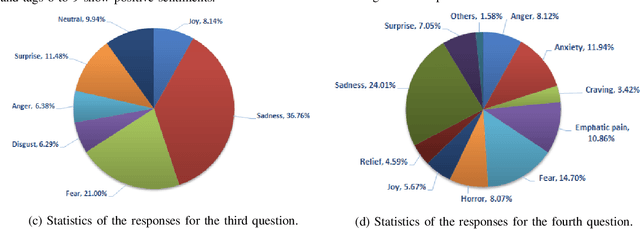
The increasing popularity of social networks and users' tendency towards sharing their feelings, expressions, and opinions in text, visual, and audio content, have opened new opportunities and challenges in sentiment analysis. While sentiment analysis of text streams has been widely explored in literature, sentiment analysis from images and videos is relatively new. This article focuses on visual sentiment analysis in a societal important domain, namely disaster analysis in social media. To this aim, we propose a deep visual sentiment analyzer for disaster related images, covering different aspects of visual sentiment analysis starting from data collection, annotation, model selection, implementation, and evaluations. For data annotation, and analyzing peoples' sentiments towards natural disasters and associated images in social media, a crowd-sourcing study has been conducted with a large number of participants worldwide. The crowd-sourcing study resulted in a large-scale benchmark dataset with four different sets of annotations, each aiming a separate task. The presented analysis and the associated dataset will provide a baseline/benchmark for future research in the domain. We believe the proposed system can contribute toward more livable communities by helping different stakeholders, such as news broadcasters, humanitarian organizations, as well as the general public.
Trust-Based Cloud Machine Learning Model Selection For Industrial IoT and Smart City Services
Aug 11, 2020With Machine Learning (ML) services now used in a number of mission-critical human-facing domains, ensuring the integrity and trustworthiness of ML models becomes all-important. In this work, we consider the paradigm where cloud service providers collect big data from resource-constrained devices for building ML-based prediction models that are then sent back to be run locally on the intermittently-connected resource-constrained devices. Our proposed solution comprises an intelligent polynomial-time heuristic that maximizes the level of trust of ML models by selecting and switching between a subset of the ML models from a superset of models in order to maximize the trustworthiness while respecting the given reconfiguration budget/rate and reducing the cloud communication overhead. We evaluate the performance of our proposed heuristic using two case studies. First, we consider Industrial IoT (IIoT) services, and as a proxy for this setting, we use the turbofan engine degradation simulation dataset to predict the remaining useful life of an engine. Our results in this setting show that the trust level of the selected models is 0.49% to 3.17% less compared to the results obtained using Integer Linear Programming (ILP). Second, we consider Smart Cities services, and as a proxy of this setting, we use an experimental transportation dataset to predict the number of cars. Our results show that the selected model's trust level is 0.7% to 2.53% less compared to the results obtained using ILP. We also show that our proposed heuristic achieves an optimal competitive ratio in a polynomial-time approximation scheme for the problem.