 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2S100K: Road-Region Segmentation Dataset For Semi-Supervised Autonomous Driving in the Wild
Aug 11, 2023



Semantic understanding of roadways is a key enabling factor for safe autonomous driving. However, existing autonomous driving datasets provide well-structured urban roads while ignoring unstructured roadways containing distress, potholes, water puddles, and various kinds of road patches i.e., earthen, gravel etc. To this end, we introduce Road Region Segmentation dataset (R2S100K) -- a large-scale dataset and benchmark for training and evaluation of road segmentation in aforementioned challenging unstructured roadways. R2S100K comprises 100K images extracted from a large and diverse set of video sequences covering more than 1000 KM of roadways. Out of these 100K privacy respecting images, 14,000 images have fine pixel-labeling of road regions, with 86,000 unlabeled images that can be leveraged through semi-supervised learning methods. Alongside, we present an Efficient Data Sampling (EDS) based self-training framework to improve learning by leveraging unlabeled data. Our experimental results demonstrate that the proposed method significantly improves learning methods in generalizability and reduces the labeling cost for semantic segmentation tasks. Our benchmark will be publicly available to facilitate future research at https://r2s100k.github.io/.
Membership Inference Attacks on DNNs using Adversarial Perturbations
Jul 11, 2023Several membership inference (MI) attacks have been proposed to audit a target DNN. Given a set of subjects, MI attacks tell which subjects the target DNN has seen during training. This work focuses on the post-training MI attacks emphasizing high confidence membership detection -- True Positive Rates (TPR) at low False Positive Rates (FPR). Current works in this category -- likelihood ratio attack (LiRA) and enhanced MI attack (EMIA) -- only perform well on complex datasets (e.g., CIFAR-10 and Imagenet) where the target DNN overfits its train set, but perform poorly on simpler datasets (0% TPR by both attacks on Fashion-MNIST, 2% and 0% TPR respectively by LiRA and EMIA on MNIST at 1% FPR). To address this, firstly, we unify current MI attacks by presenting a framework divided into three stages -- preparation, indication and decision. Secondly, we utilize the framework to propose two novel attacks: (1) Adversarial Membership Inference Attack (AMIA) efficiently utilizes the membership and the non-membership information of the subjects while adversarially minimizing a novel loss function, achieving 6% TPR on both Fashion-MNIST and MNIST datasets; and (2) Enhanced AMIA (E-AMIA) combines EMIA and AMIA to achieve 8% and 4% TPRs on Fashion-MNIST and MNIST datasets respectively, at 1% FPR. Thirdly, we introduce two novel augmented indicators that positively leverage the loss information in the Gaussian neighborhood of a subject. This improves TPR of all four attacks on average by 2.5% and 0.25% respectively on Fashion-MNIST and MNIST datasets at 1% FPR. Finally, we propose simple, yet novel, evaluation metric, the running TPR average (RTA) at a given FPR, that better distinguishes different MI attacks in the low FPR region. We also show that AMIA and E-AMIA are more transferable to the unknown DNNs (other than the target DNN) and are more robust to DP-SGD training as compared to LiRA and EMIA.
Motion Comfort Optimization for Autonomous Vehicles: Concepts, Methods, and Techniques
Jun 15, 2023



This article outlines the architecture of autonomous driving and related complementary frameworks from the perspective of human comfort. The technical elements for measuring Autonomous Vehicle (AV) user comfort and psychoanalysis are listed here. At the same time, this article introduces the technology related to the structure of automatic driving and the reaction time of automatic driving. We also discuss the technical details related to the automatic driving comfort system, the response time of the AV driver, the comfort level of the AV, motion sickness, and related optimization technologies. The function of the sensor is affected by various factors. Since the sensor of automatic driving mainly senses the environment around a vehicle, including "the weather" which introduces the challenges and limitations of second-hand sensors in autonomous vehicles under different weather conditions. The comfort and safety of autonomous driving are also factors that affect the development of autonomous driving technologies. This article further analyzes the impact of autonomous driving on the user's physical and psychological states and how the comfort factors of autonomous vehicles affect the automotive market. Also, part of our focus is on the benefits and shortcomings of autonomous driving. The goal is to present an exhaustive overview of the most relevant technical matters to help researchers and application developers comprehend the different comfort factors and systems of autonomous driving. Finally, we provide detailed automated driving comfort use cases to illustrate the comfort-related issues of autonomous driving. Then, we provide implications and insights for the future of autonomous driving.
Can We Revitalize Interventional Healthcare with AI-XR Surgical Metaverses?
Mar 25, 2023

Recent advancements in technology, particularly in machine learning (ML), deep learning (DL), and the metaverse, offer great potential for revolutionizing surgical science. The combination of artificial intelligence and extended reality (AI-XR) technologies has the potential to create a surgical metaverse, a virtual environment where surgeries can be planned and performed. This paper aims to provide insight into the various potential applications of an AI-XR surgical metaverse and the challenges that must be addressed to bring its full potential to fruition. It is important for the community to focus on these challenges to fully realize the potential of the AI-XR surgical metaverses. Furthermore, to emphasize the need for secure and robust AI-XR surgical metaverses and to demonstrate the real-world implications of security threats to the AI-XR surgical metaverses, we present a case study in which the ``an immersive surgical attack'' on incision point localization is performed in the context of preoperative planning in a surgical metaverse.
Consistent Valid Physically-Realizable Adversarial Attack against Crowd-flow Prediction Models
Mar 05, 2023



Recent works have shown that deep learning (DL) models can effectively learn city-wide crowd-flow patterns, which can be used for more effective urban planning and smart city management. However, DL models have been known to perform poorly on inconspicuous adversarial perturbations. Although many works have studied these adversarial perturbations in general, the adversarial vulnerabilities of deep crowd-flow prediction models in particular have remained largely unexplored. In this paper, we perform a rigorous analysis of the adversarial vulnerabilities of DL-based crowd-flow prediction models under multiple threat settings, making three-fold contributions. (1) We propose CaV-detect by formally identifying two novel properties - Consistency and Validity - of the crowd-flow prediction inputs that enable the detection of standard adversarial inputs with 0% false acceptance rate (FAR). (2) We leverage universal adversarial perturbations and an adaptive adversarial loss to present adaptive adversarial attacks to evade CaV-detect defense. (3) We propose CVPR, a Consistent, Valid and Physically-Realizable adversarial attack, that explicitly inducts the consistency and validity priors in the perturbation generation mechanism. We find out that although the crowd-flow models are vulnerable to adversarial perturbations, it is extremely challenging to simulate these perturbations in physical settings, notably when CaV-detect is in place. We also show that CVPR attack considerably outperforms the adaptively modified standard attacks in FAR and adversarial loss metrics. We conclude with useful insights emerging from our work and highlight promising future research directions.
Topic Modeling Based on Two-Step Flow Theory: Application to Tweets about Bitcoin
Mar 03, 2023Digital cryptocurrencies such as Bitcoin have exploded in recent years in both popularity and value. By their novelty, cryptocurrencies tend to be both volatile and highly speculative. The capricious nature of these coins is helped facilitated by social media networks such as Twitter. However, not everyone's opinion matters equally, with most posts garnering little to no attention. Additionally, the majority of tweets are retweeted from popular posts. We must determine whose opinion matters and the difference between influential and non-influential users. This study separates these two groups and analyzes the differences between them. It uses Hypertext-induced Topic Selection (HITS) algorithm, which segregates the dataset based on influence. Topic modeling is then employed to uncover differences in each group's speech types and what group may best represent the entire community. We found differences in language and interest between these two groups regarding Bitcoin and that the opinion leaders of Twitter are not aligned with the majority of users. There were 2559 opinion leaders (0.72% of users) who accounted for 80% of the authority and the majority (99.28%) users for the remaining 20% out of a total of 355,139 users.
Continual Conscious Active Fine-Tuning to Robustify Online Machine Learning Models Against Data Distribution Shifts
Nov 02, 2022



Unlike their offline traditional counterpart, online machine learning models are capable of handling data distribution shifts while serving at the test time. However, they have limitations in addressing this phenomenon. They are either expensive or unreliable. We propose augmenting an online learning approach called test-time adaptation with a continual conscious active fine-tuning layer to develop an enhanced variation that can handle drastic data distribution shifts reliably and cost-effectively. The proposed augmentation incorporates the following aspects: a continual aspect to confront the ever-ending data distribution shifts, a conscious aspect to imply that fine-tuning is a distribution-shift-aware process that occurs at the appropriate time to address the recently detected data distribution shifts, and an active aspect to indicate employing human-machine collaboration for the relabeling to be cost-effective and practical for diverse applications. Our empirical results show that the enhanced test-time adaptation variation outperforms the traditional variation by a factor of two.
Secure and Trustworthy Artificial Intelligence-Extended Reality (AI-XR) for Metaverses
Oct 24, 2022



Metaverse is expected to emerge as a new paradigm for the next-generation Internet, providing fully immersive and personalised experiences to socialize, work, and play in self-sustaining and hyper-spatio-temporal virtual world(s). The advancements in different technologies like augmented reality, virtual reality, extended reality (XR), artificial intelligence (AI), and 5G/6G communication will be the key enablers behind the realization of AI-XR metaverse applications. While AI itself has many potential applications in the aforementioned technologies (e.g., avatar generation, network optimization, etc.), ensuring the security of AI in critical applications like AI-XR metaverse applications is profoundly crucial to avoid undesirable actions that could undermine users' privacy and safety, consequently putting their lives in danger. To this end, we attempt to analyze the security, privacy, and trustworthiness aspects associated with the use of various AI techniques in AI-XR metaverse applications. Specifically, we discuss numerous such challenges and present a taxonomy of potential solutions that could be leveraged to develop secure, private, robust, and trustworthy AI-XR applications. To highlight the real implications of AI-associated adversarial threats, we designed a metaverse-specific case study and analyzed it through the adversarial lens. Finally, we elaborate upon various open issues that require further research interest from the community.
Exploration and Exploitation in Federated Learning to Exclude Clients with Poisoned Data
Apr 29, 2022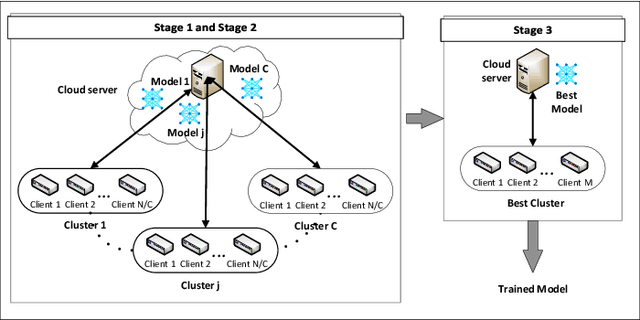
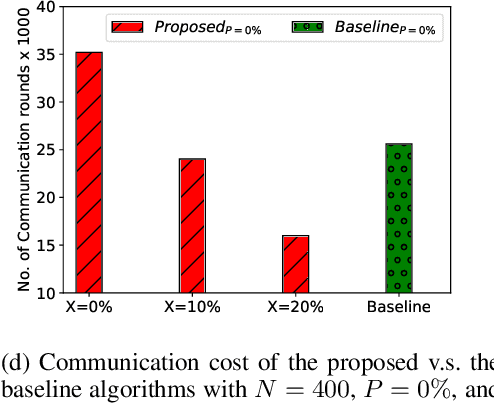
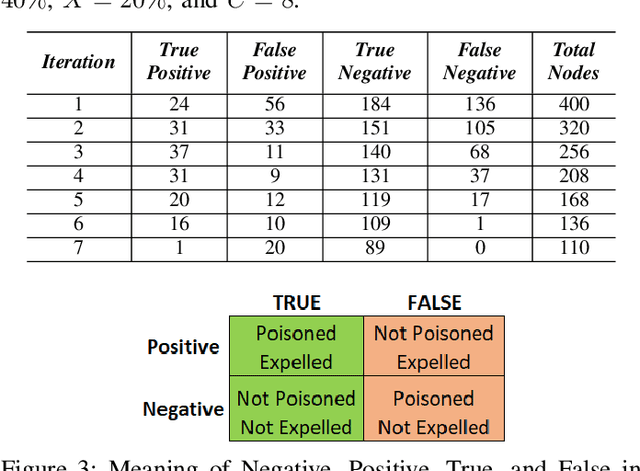
Federated Learning (FL) is one of the hot research topics, and it utilizes Machine Learning (ML) in a distributed manner without directly accessing private data on clients. However, FL faces many challenges, including the difficulty to obtain high accuracy, high communication cost between clients and the server, and security attacks related to adversarial ML. To tackle these three challenges, we propose an FL algorithm inspired by evolutionary techniques. The proposed algorithm groups clients randomly in many clusters, each with a model selected randomly to explore the performance of different models. The clusters are then trained in a repetitive process where the worst performing cluster is removed in each iteration until one cluster remains. In each iteration, some clients are expelled from clusters either due to using poisoned data or low performance. The surviving clients are exploited in the next iteration. The remaining cluster with surviving clients is then used for training the best FL model (i.e., remaining FL model). Communication cost is reduced since fewer clients are used in the final training of the FL model. To evaluate the performance of the proposed algorithm, we conduct a number of experiments using FEMNIST dataset and compare the result against the random FL algorithm. The experimental results show that the proposed algorithm outperforms the baseline algorithm in terms of accuracy, communication cost, and security.
Merit-based Fusion of NLP Techniques for Instant Feedback on Water Quality from Twitter Text
Feb 09, 2022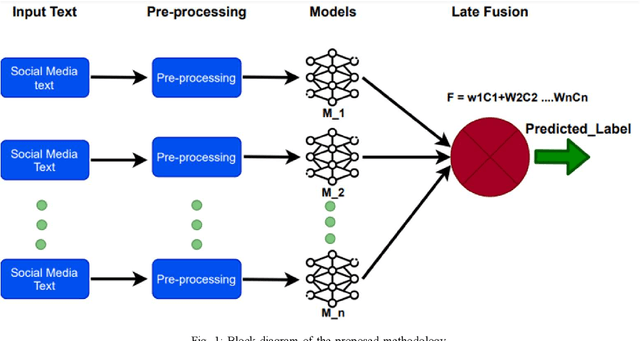

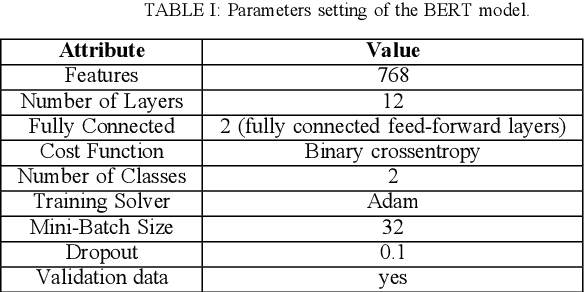
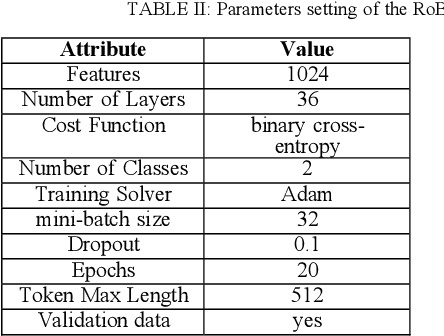
This paper focuses on an important environmental challenge; namely, water quality by analyzing the potential of social media as an immediate source of feedback. The main goal of the work is to automatically analyze and retrieve social media posts relevant to water quality with particular attention to posts describing different aspects of water quality, such as watercolor, smell, taste, and related illnesses. To this aim, we propose a novel framework incorporating different preprocessing, data augmentation, and classification techniques. In total, three different Neural Networks (NNs) architectures, namely (i) Bidirectional Encoder Representations from Transformers (BERT), (ii) Robustly Optimized BERT Pre-training Approach (XLM-RoBERTa), and (iii) custom Long short-term memory (LSTM) model, are employed in a merit-based fusion scheme. For merit-based weight assignment to the models, several optimization and search techniques are compared including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Brute Force (BF), Nelder-Mead, and Powell's optimization methods. We also provide an evaluation of the individual models where the highest F1-score of 0.81 is obtained with the BERT model. In merit-based fusion, overall better results are obtained with BF achieving an F1-score score of 0.852. We also provide comparison against existing methods, where a significant improvement for our proposed solutions is obtained. We believe such rigorous analysis of this relatively new topic will provide a baseline for future research.