 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Quantized Representation for Enhanced Reconstruction
Jul 29, 2021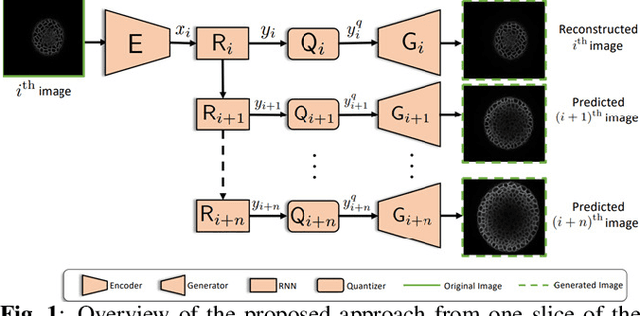
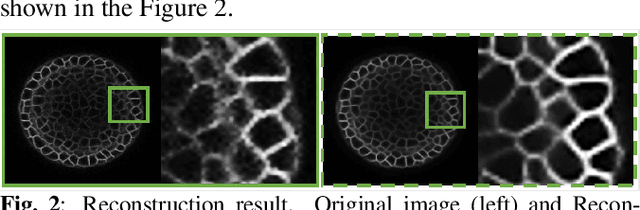
While machine learning approaches have shown remarkable performance in biomedical image analysis, most of these methods rely on high-quality and accurate imaging data. However, collecting such data requires intensive and careful manual effort. One of the major challenges in imaging the Shoot Apical Meristem (SAM) of Arabidopsis thaliana, is that the deeper slices in the z-stack suffer from different perpetual quality-related problems like poor contrast and blurring. These quality-related issues often lead to the disposal of the painstakingly collected data with little to no control on quality while collecting the data. Therefore, it becomes necessary to employ and design techniques that can enhance the images to make them more suitable for further analysis. In this paper, we propose a data-driven Deep Quantized Latent Representation (DQLR) methodology for high-quality image reconstruction in the Shoot Apical Meristem (SAM) of Arabidopsis thaliana. Our proposed framework utilizes multiple consecutive slices in the z-stack to learn a low dimensional latent space, quantize it and subsequently perform reconstruction using the quantized representation to obtain sharper images. Experiments on a publicly available dataset validate our methodology showing promising results.
Optimal Sepsis Patient Treatment using Human-in-the-loop Artificial Intelligence
Sep 16, 2020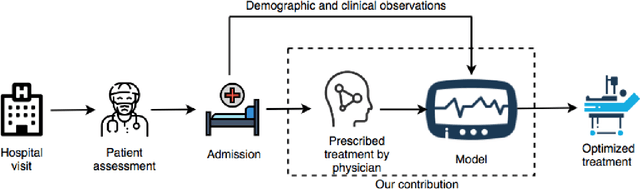
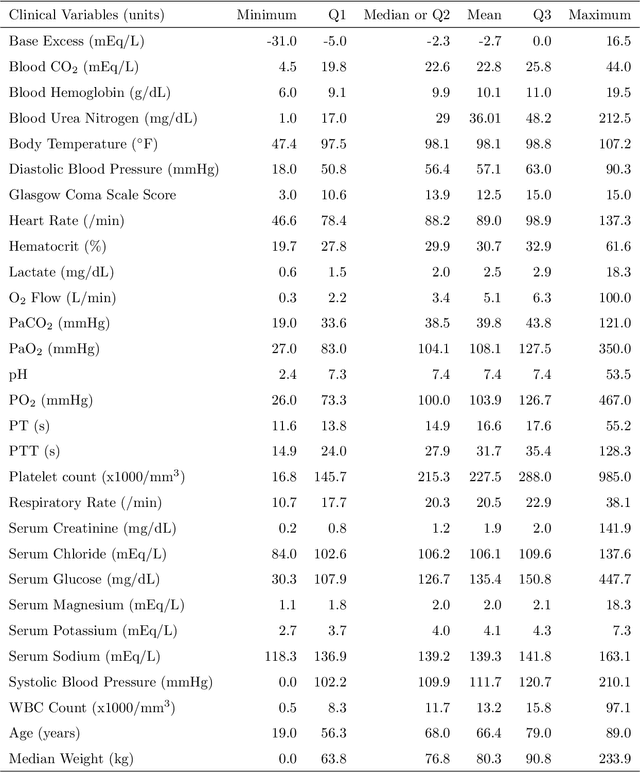
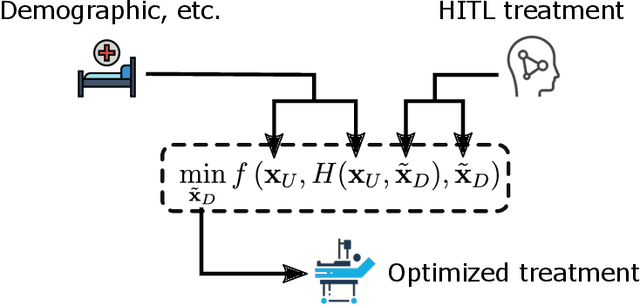
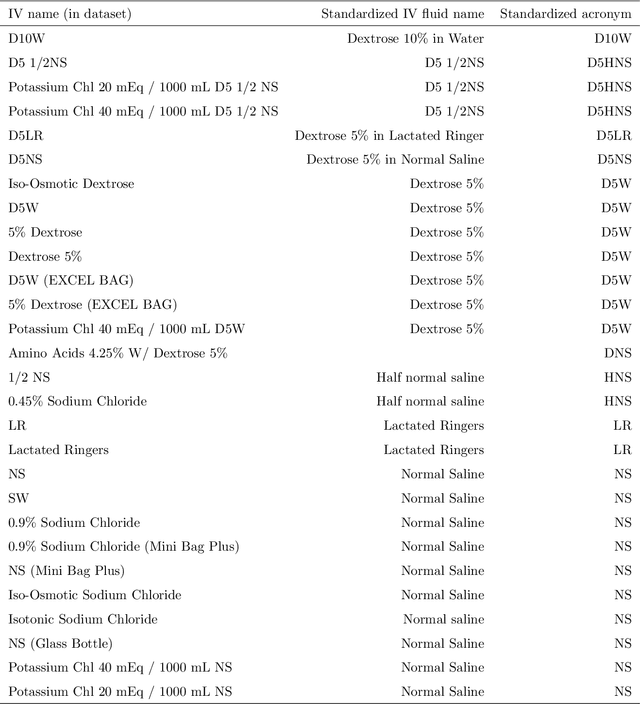
Sepsis is one of the leading causes of death in Intensive Care Units (ICU). The strategy for treating sepsis involves the infusion of intravenous (IV) fluids and administration of antibiotics. Determining the optimal quantity of IV fluids is a challenging problem due to the complexity of a patient's physiology. In this study, we develop a data-driven optimization solution that derives the optimal quantity of IV fluids for individual patients. The proposed method minimizes the probability of severe outcomes by controlling the prescribed quantity of IV fluids and utilizes human-in-the-loop artificial intelligence. We demonstrate the performance of our model on 1122 ICU patients with sepsis diagnosis extracted from the MIMIC-III dataset. The results show that, on average, our model can reduce mortality by 22%. This study has the potential to help physicians synthesize optimal, patient-specific treatment strategies.
ALANET: Adaptive Latent Attention Network forJoint Video Deblurring and Interpolation
Aug 31, 2020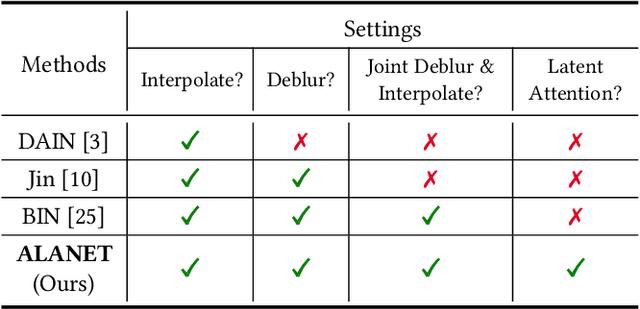
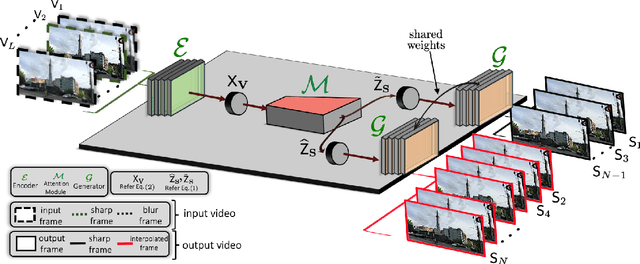
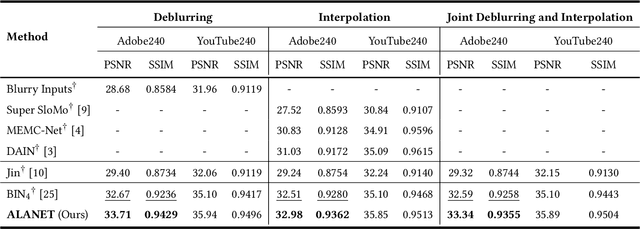
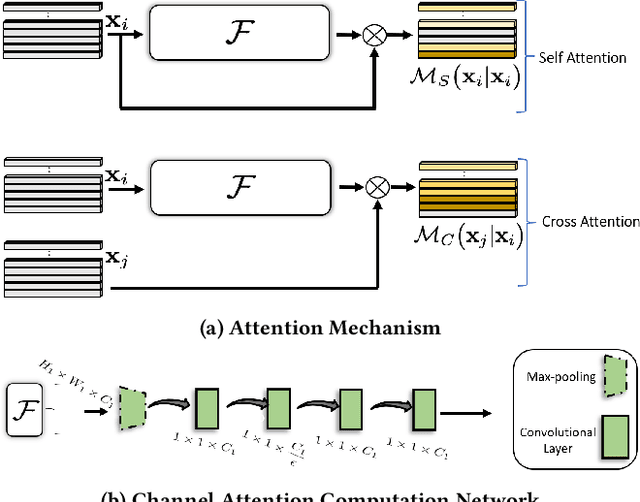
Existing works address the problem of generating high frame-rate sharp videos by separately learning the frame deblurring and frame interpolation modules. Most of these approaches have a strong prior assumption that all the input frames are blurry whereas in a real-world setting, the quality of frames varies. Moreover, such approaches are trained to perform either of the two tasks - deblurring or interpolation - in isolation, while many practical situations call for both. Different from these works, we address a more realistic problem of high frame-rate sharp video synthesis with no prior assumption that input is always blurry. We introduce a novel architecture, Adaptive Latent Attention Network (ALANET), which synthesizes sharp high frame-rate videos with no prior knowledge of input frames being blurry or not, thereby performing the task of both deblurring and interpolation. We hypothesize that information from the latent representation of the consecutive frames can be utilized to generate optimized representations for both frame deblurring and frame interpolation. Specifically, we employ combination of self-attention and cross-attention module between consecutive frames in the latent space to generate optimized representation for each frame. The optimized representation learnt using these attention modules help the model to generate and interpolate sharp frames. Extensive experiments on standard datasets demonstrate that our method performs favorably against various state-of-the-art approaches, even though we tackle a much more difficult problem.
Adversarial Knowledge Transfer from Unlabeled Data
Aug 13, 2020
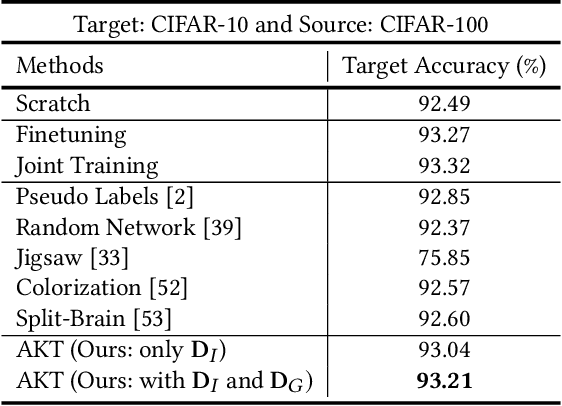
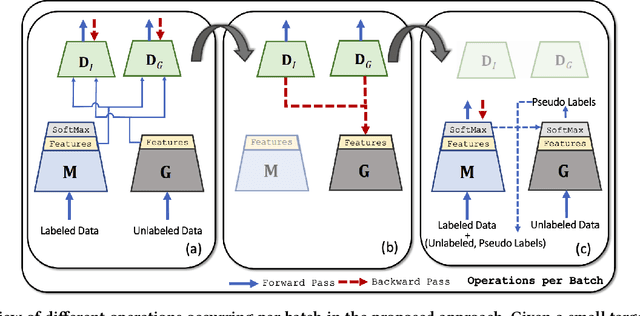
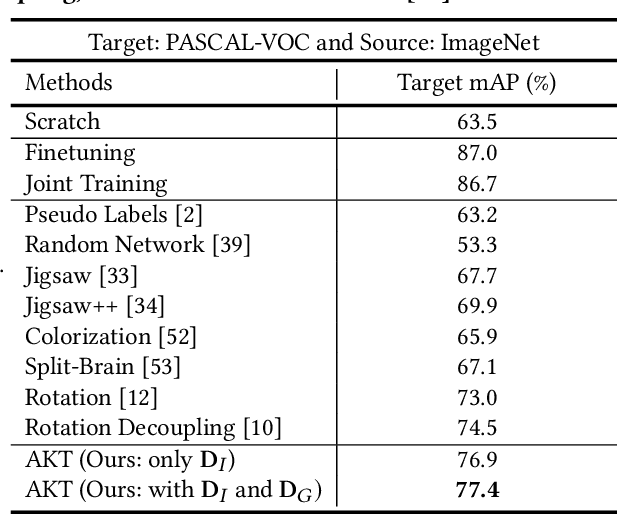
While machine learning approaches to visual recognition offer great promise, most of the existing methods rely heavily on the availability of large quantities of labeled training data. However, in the vast majority of real-world settings, manually collecting such large labeled datasets is infeasible due to the cost of labeling data or the paucity of data in a given domain. In this paper, we present a novel Adversarial Knowledge Transfer (AKT) framework for transferring knowledge from internet-scale unlabeled data to improve the performance of a classifier on a given visual recognition task. The proposed adversarial learning framework aligns the feature space of the unlabeled source data with the labeled target data such that the target classifier can be used to predict pseudo labels on the source data. An important novel aspect of our method is that the unlabeled source data can be of different classes from those of the labeled target data, and there is no need to define a separate pretext task, unlike some existing approaches. Extensive experiments well demonstrate that models learned using our approach hold a lot of promise across a variety of visual recognition tasks on multiple standard datasets.
Non-Adversarial Video Synthesis with Learned Priors
Apr 17, 2020
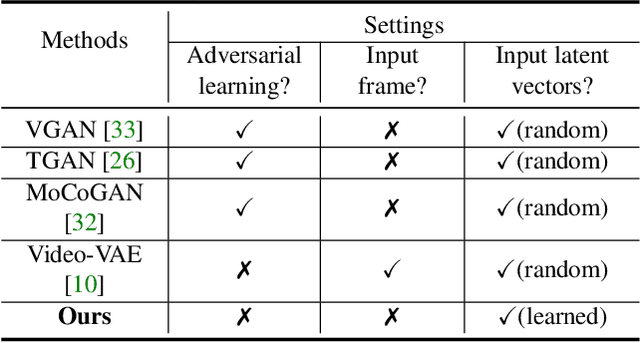
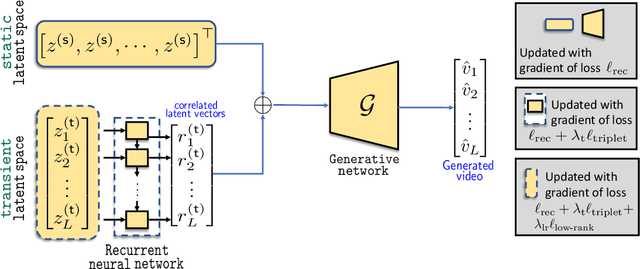

Most of the existing works in video synthesis focus on generating videos using adversarial learning. Despite their success, these methods often require input reference frame or fail to generate diverse videos from the given data distribution, with little to no uniformity in the quality of videos that can be generated. Different from these methods, we focus on the problem of generating videos from latent noise vectors, without any reference input frames. To this end, we develop a novel approach that jointly optimizes the input latent space, the weights of a recurrent neural network and a generator through non-adversarial learning. Optimizing for the input latent space along with the network weights allows us to generate videos in a controlled environment, i.e., we can faithfully generate all videos the model has seen during the learning process as well as new unseen videos. Extensive experiments on three challenging and diverse datasets well demonstrate that our approach generates superior quality videos compared to the existing state-of-the-art methods.