 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell and Predict: Kernel Classifier Prediction for Unseen Visual Classes from Unstructured Text Descriptions
Jun 29, 2015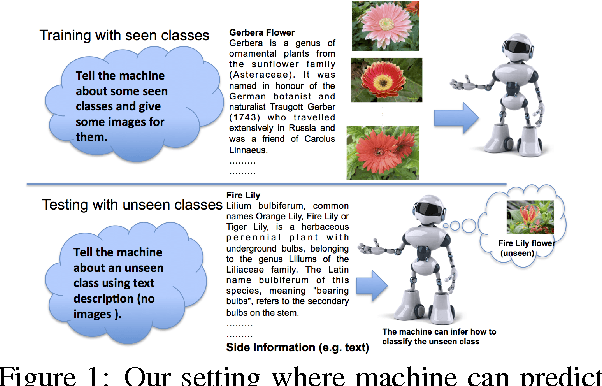
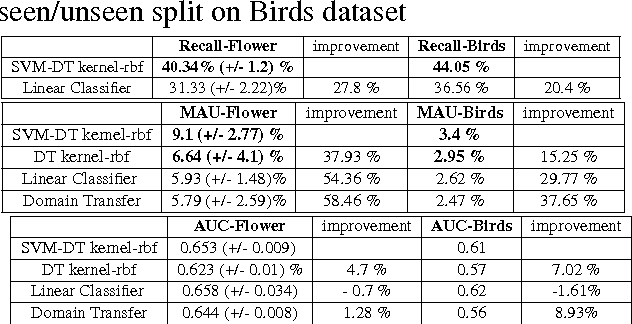
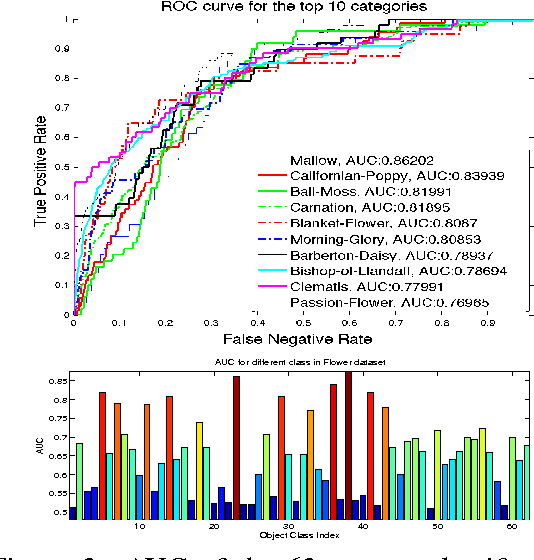

In this paper we propose a framework for predicting kernelized classifiers in the visual domain for categories with no training images where the knowledge comes from textual description about these categories. Through our optimization framework, the proposed approach is capable of embedding the class-level knowledge from the text domain as kernel classifiers in the visual domain. We also proposed a distributional semantic kernel between text descriptions which is shown to be effective in our setting. The proposed framework is not restricted to textual descriptions, and can also be applied to other forms knowledge representations. Our approach was applied for the challenging task of zero-shot learning of fine-grained categories from text descriptions of these categories.
Quantifying Creativity in Art Networks
Jun 02, 2015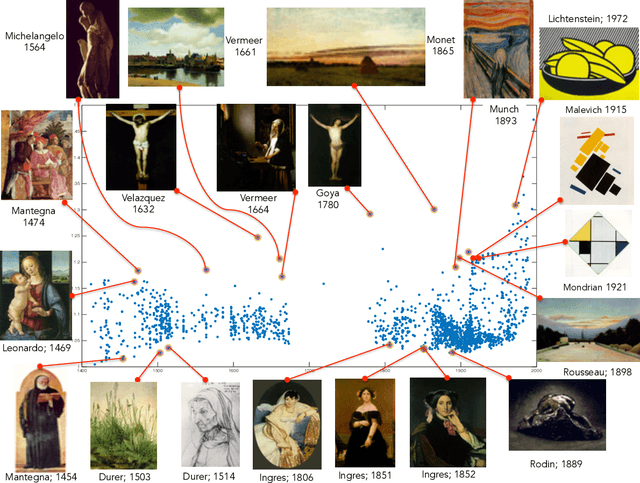
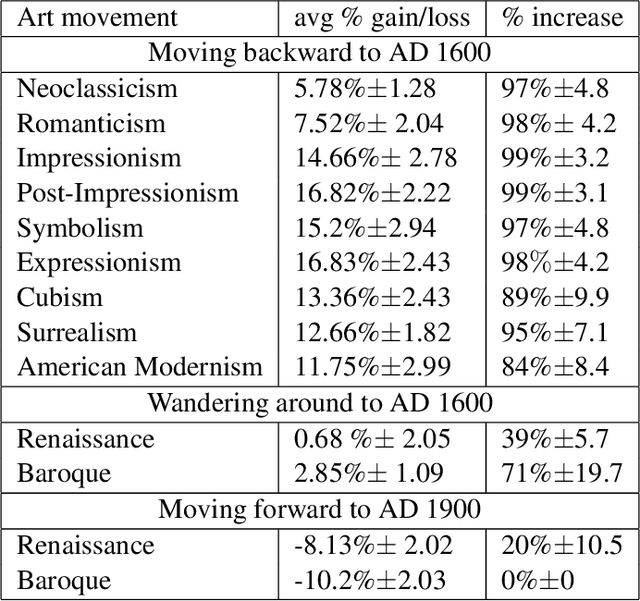
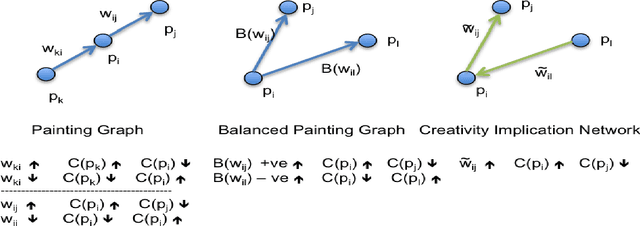
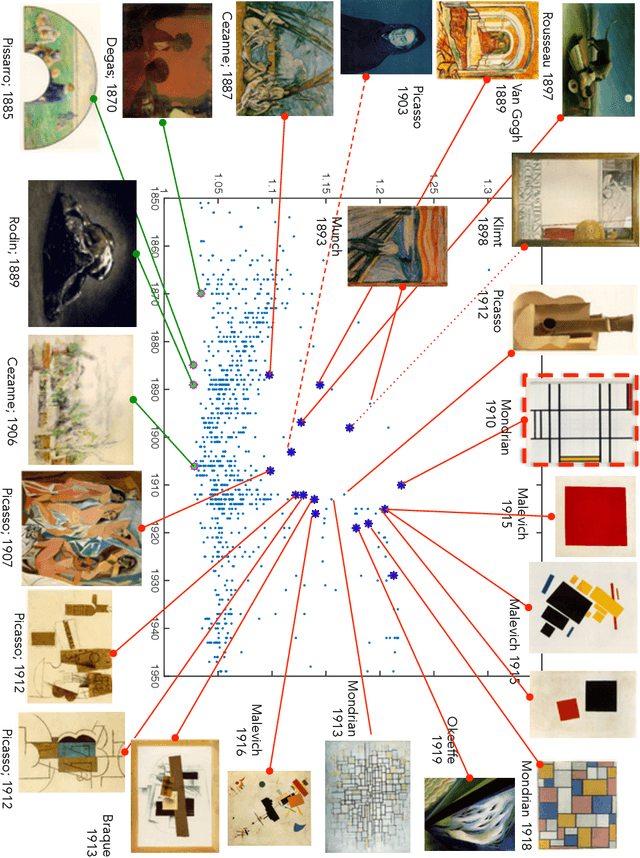
Can we develop a computer algorithm that assesses the creativity of a painting given its context within art history? This paper proposes a novel computational framework for assessing the creativity of creative products, such as paintings, sculptures, poetry, etc. We use the most common definition of creativity, which emphasizes the originality of the product and its influential value. The proposed computational framework is based on constructing a network between creative products and using this network to infer about the originality and influence of its nodes. Through a series of transformations, we construct a Creativity Implication Network. We show that inference about creativity in this network reduces to a variant of network centrality problems which can be solved efficiently. We apply the proposed framework to the task of quantifying creativity of paintings (and sculptures). We experimented on two datasets with over 62K paintings to illustrate the behavior of the proposed framework. We also propose a methodology for quantitatively validating the results of the proposed algorithm, which we call the "time machine experiment".
Generalized Twin Gaussian Processes using Sharma-Mittal Divergence
Jun 01, 2015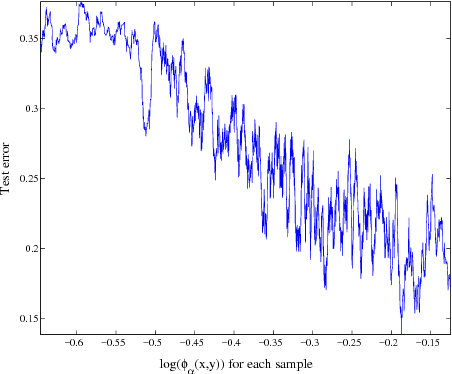
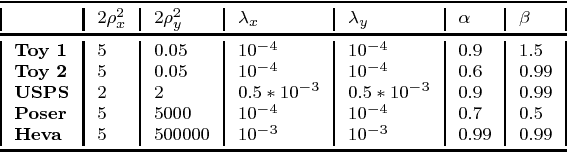

There has been a growing interest in mutual information measures due to their wide range of applications in Machine Learning and Computer Vision. In this paper, we present a generalized structured regression framework based on Shama-Mittal divergence, a relative entropy measure, which is introduced to the Machine Learning community in this work. Sharma-Mittal (SM) divergence is a generalized mutual information measure for the widely used R\'enyi, Tsallis, Bhattacharyya, and Kullback-Leibler (KL) relative entropies. Specifically, we study Sharma-Mittal divergence as a cost function in the context of the Twin Gaussian Processes (TGP)~\citep{Bo:2010}, which generalizes over the KL-divergence without computational penalty. We show interesting properties of Sharma-Mittal TGP (SMTGP) through a theoretical analysis, which covers missing insights in the traditional TGP formulation. However, we generalize this theory based on SM-divergence instead of KL-divergence which is a special case. Experimentally, we evaluated the proposed SMTGP framework on several datasets. The results show that SMTGP reaches better predictions than KL-based TGP, since it offers a bigger class of models through its parameters that we learn from the data.
Large-scale Classification of Fine-Art Paintings: Learning The Right Metric on The Right Feature
May 05, 2015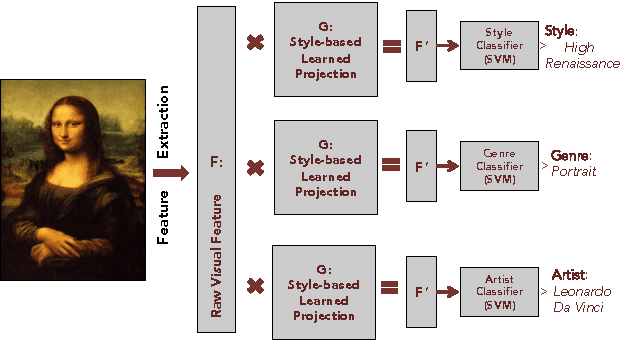
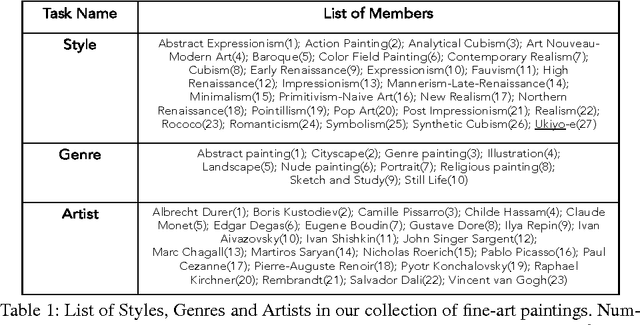
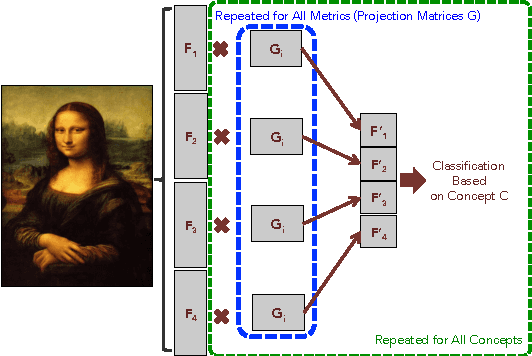
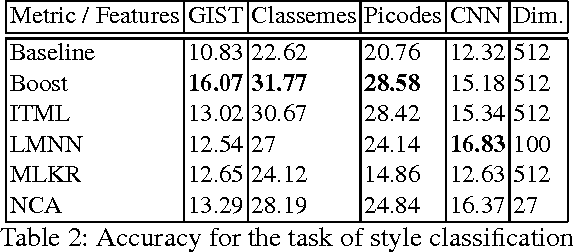
In the past few years, the number of fine-art collections that are digitized and publicly available has been growing rapidly. With the availability of such large collections of digitized artworks comes the need to develop multimedia systems to archive and retrieve this pool of data. Measuring the visual similarity between artistic items is an essential step for such multimedia systems, which can benefit more high-level multimedia tasks. In order to model this similarity between paintings, we should extract the appropriate visual features for paintings and find out the best approach to learn the similarity metric based on these features. We investigate a comprehensive list of visual features and metric learning approaches to learn an optimized similarity measure between paintings. We develop a machine that is able to make aesthetic-related semantic-level judgments, such as predicting a painting's style, genre, and artist, as well as providing similarity measures optimized based on the knowledge available in the domain of art historical interpretation. Our experiments show the value of using this similarity measure for the aforementioned prediction tasks.
Factorization of View-Object Manifolds for Joint Object Recognition and Pose Estimation
Apr 13, 2015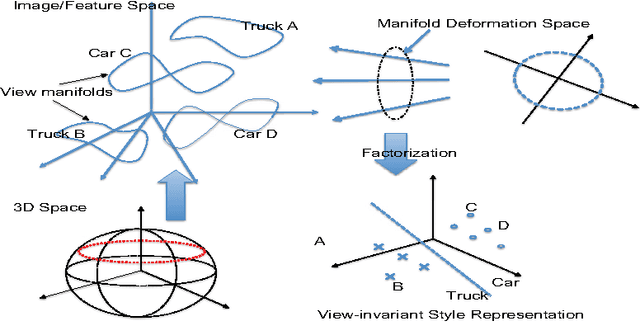
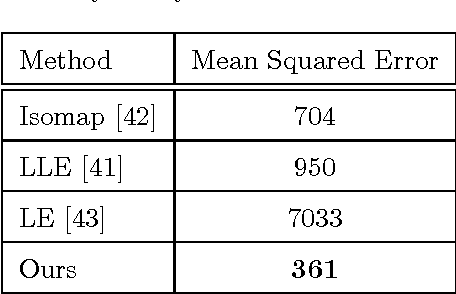

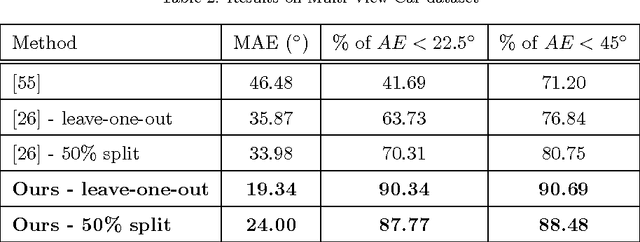
Due to large variations in shape, appearance, and viewing conditions, object recognition is a key precursory challenge in the fields of object manipulation and robotic/AI visual reasoning in general. Recognizing object categories, particular instances of objects and viewpoints/poses of objects are three critical subproblems robots must solve in order to accurately grasp/manipulate objects and reason about their environments. Multi-view images of the same object lie on intrinsic low-dimensional manifolds in descriptor spaces (e.g. visual/depth descriptor spaces). These object manifolds share the same topology despite being geometrically different. Each object manifold can be represented as a deformed version of a unified manifold. The object manifolds can thus be parameterized by its homeomorphic mapping/reconstruction from the unified manifold. In this work, we develop a novel framework to jointly solve the three challenging recognition sub-problems, by explicitly modeling the deformations of object manifolds and factorizing it in a view-invariant space for recognition. We perform extensive experiments on several challenging datasets and achieve state-of-the-art results.
Learning Hypergraph-regularized Attribute Predictors
Mar 19, 2015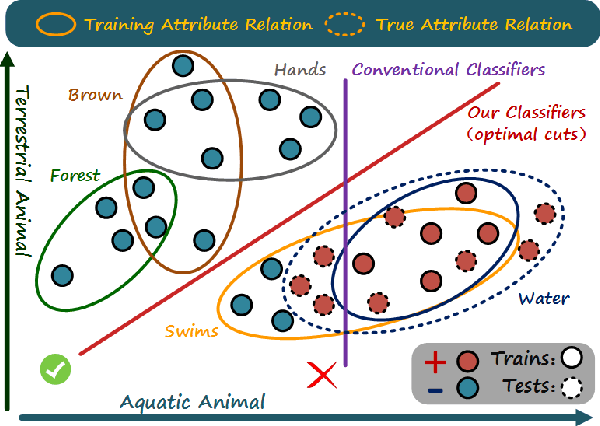
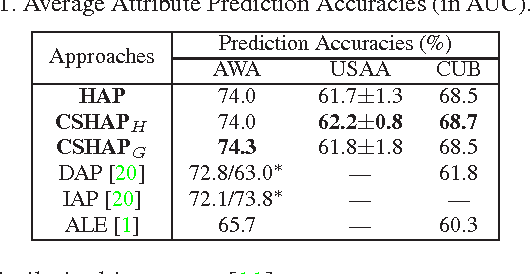
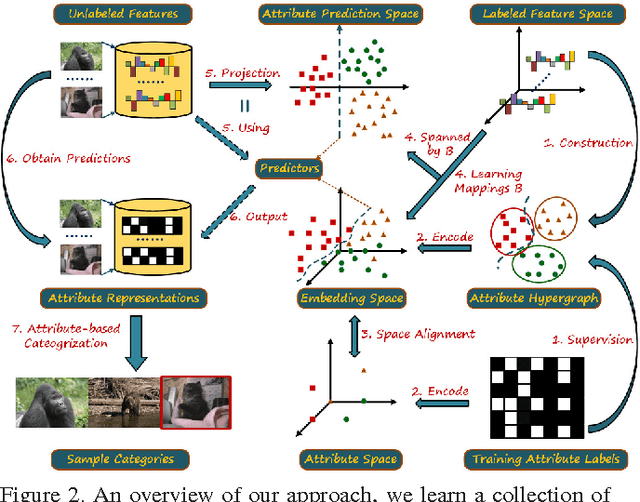
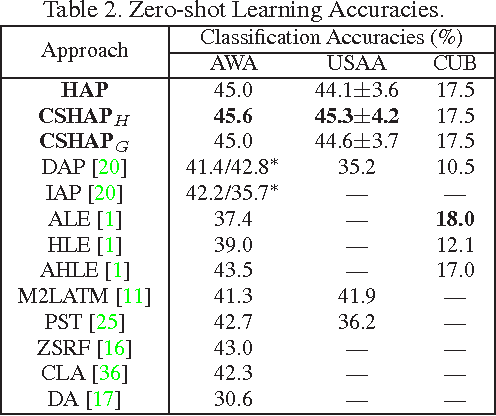
We present a novel attribute learning framework named Hypergraph-based Attribute Predictor (HAP). In HAP, a hypergraph is leveraged to depict the attribute relations in the data. Then the attribute prediction problem is casted as a regularized hypergraph cut problem in which HAP jointly learns a collection of attribute projections from the feature space to a hypergraph embedding space aligned with the attribute space. The learned projections directly act as attribute classifiers (linear and kernelized). This formulation leads to a very efficient approach. By considering our model as a multi-graph cut task, our framework can flexibly incorporate other available information, in particular class label. We apply our approach to attribute prediction, Zero-shot and $N$-shot learning tasks. The results on AWA, USAA and CUB databases demonstrate the value of our methods in comparison with the state-of-the-art approaches.
Text to Multi-level MindMaps: A Novel Method for Hierarchical Visual Abstraction of Natural Language Text
Dec 23, 2014
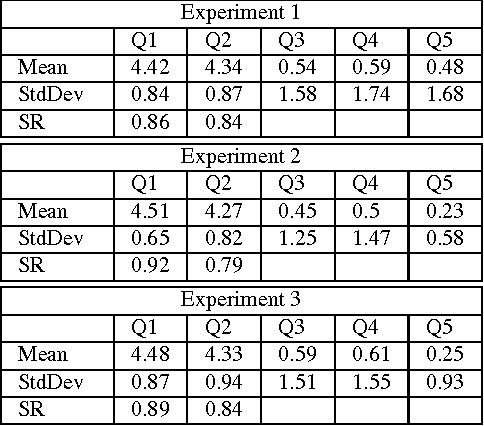
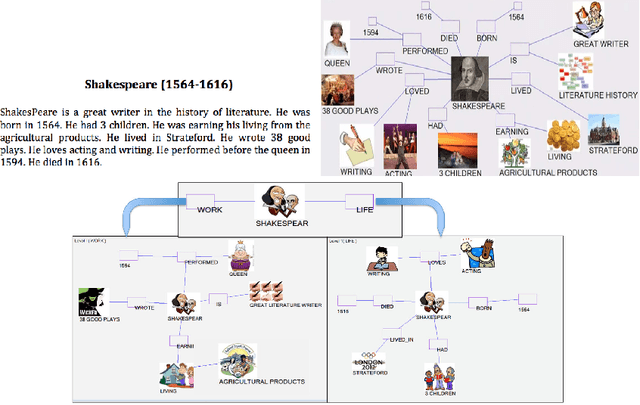
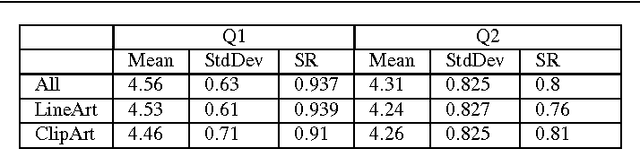
MindMapping is a well-known technique used in note taking, which encourages learning and studying. MindMapping has been manually adopted to help present knowledge and concepts in a visual form. Unfortunately, there is no reliable automated approach to generate MindMaps from Natural Language text. This work firstly introduces MindMap Multilevel Visualization concept which is to jointly visualize and summarize textual information. The visualization is achieved pictorially across multiple levels using semantic information (i.e. ontology), while the summarization is achieved by the information in the highest levels as they represent abstract information in the text. This work also presents the first automated approach that takes a text input and generates a MindMap visualization out of it. The approach could visualize text documents in multilevel MindMaps, in which a high-level MindMap node could be expanded into child MindMaps. \ignore{ As far as we know, this is the first work that view MindMapping as a new approach to jointly summarize and visualize textual information.} The proposed method involves understanding of the input text and converting it into intermediate Detailed Meaning Representation (DMR). The DMR is then visualized with two modes; Single level or Multiple levels, which is convenient for larger text. The generated MindMaps from both approaches were evaluated based on Human Subject experiments performed on Amazon Mechanical Turk with various parameter settings.
Abnormal Object Recognition: A Comprehensive Study
Nov 09, 2014
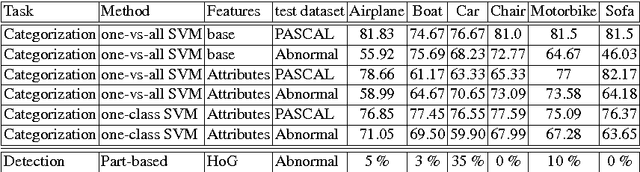

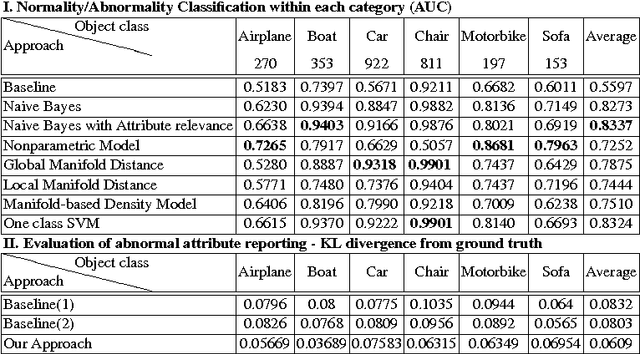
When describing images, humans tend not to talk about the obvious, but rather mention what they find interesting. We argue that abnormalities and deviations from typicalities are among the most important components that form what is worth mentioning. In this paper we introduce the abnormality detection as a recognition problem and show how to model typicalities and, consequently, meaningful deviations from prototypical properties of categories. Our model can recognize abnormalities and report the main reasons of any recognized abnormality. We introduce the abnormality detection dataset and show interesting results on how to reason about abnormalities.
On The Effect of Hyperedge Weights On Hypergraph Learning
Oct 24, 2014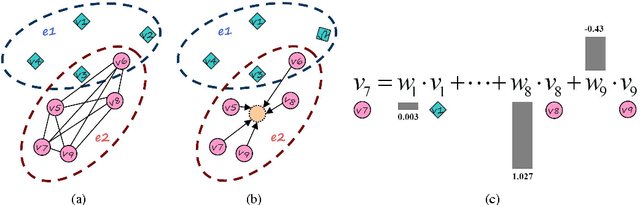
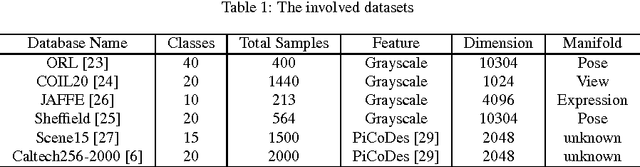
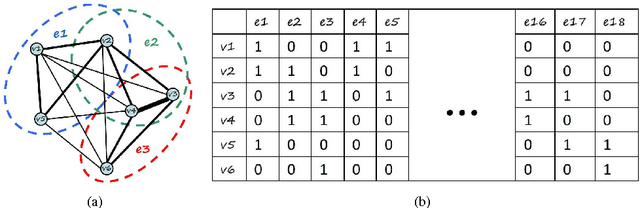
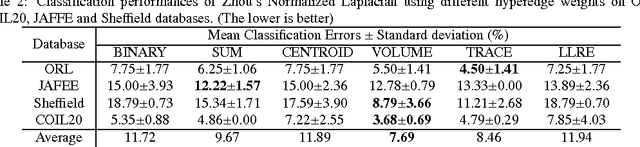
Hypergraph is a powerful representation in several computer vision, machine learning and pattern recognition problems. In the last decade, many researchers have been keen to develop different hypergraph models. In contrast, no much attention has been paid to the design of hyperedge weights. However, many studies on pairwise graphs show that the choice of edge weight can significantly influence the performances of such graph algorithms. We argue that this also applies to hypegraphs. In this paper, we empirically discuss the influence of hyperedge weight on hypegraph learning via proposing three novel hyperedge weights from the perspectives of geometry, multivariate statistical analysis and linear regression. Extensive experiments on ORL, COIL20, JAFFE, Sheffield, Scene15 and Caltech256 databases verify our hypothesis. Similar to graph learning, several representative hyperedge weighting schemes can be concluded by our experimental studies. Moreover, the experiments also demonstrate that the combinations of such weighting schemes and conventional hypergraph models can get very promising classification and clustering performances in comparison with some recent state-of-the-art algorithms.
Computational Beauty: Aesthetic Judgment at the Intersection of Art and Science
Sep 30, 2014

In part one of the Critique of Judgment, Immanuel Kant wrote that "the judgment of taste...is not a cognitive judgment, and so not logical, but is aesthetic."\cite{Kant} While the condition of aesthetic discernment has long been the subject of philosophical discourse, the role of the arbiters of that judgment has more often been assumed than questioned. The art historian, critic, connoisseur, and curator have long held the esteemed position of the aesthetic judge, their training, instinct, and eye part of the inimitable subjective processes that Kant described as occurring upon artistic evaluation. Although the concept of intangible knowledge in regard to aesthetic theory has been much explored, little discussion has arisen in response to the development of new types of artificial intelligence as a challenge to the seemingly ineffable abilities of the human observer. This paper examines the developments in the field of computer vision analysis of paintings from canonical movements with the history of Western art and the reaction of art historians to the application of this technology in the field. Through an investigation of the ethical consequences of this innovative technology, the unquestioned authority of the art expert is challenged and the subjective nature of aesthetic judgment is brought to philosophical scrutiny once again.