 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Audio Narrations to Strengthen Domain Generalization in Multimodal First-Person Action Recognition
Sep 15, 2024



First-person activity recognition is rapidly growing due to the widespread use of wearable cameras but faces challenges from domain shifts across different environments, such as varying objects or background scenes. We propose a multimodal framework that improves domain generalization by integrating motion, audio, and appearance features. Key contributions include analyzing the resilience of audio and motion features to domain shifts, using audio narrations for enhanced audio-text alignment, and applying consistency ratings between audio and visual narrations to optimize the impact of audio in recognition during training. Our approach achieves state-of-the-art performance on the ARGO1M dataset, effectively generalizing across unseen scenarios and locations.
What metrics of participation balance predict outcomes of collaborative learning with a robot?
May 17, 2024



One of the keys to the success of collaborative learning is balanced participation by all learners, but this does not always happen naturally. Pedagogical robots have the potential to facilitate balance. However, it remains unclear what participation balance robots should aim at; various metrics have been proposed, but it is still an open question whether we should balance human participation in human-human interactions (HHI) or human-robot interactions (HRI) and whether we should consider robots' participation in collaborative learning involving multiple humans and a robot. This paper examines collaborative learning between a pair of students and a teachable robot that acts as a peer tutee to answer the aforementioned question. Through an exploratory study, we hypothesize which balance metrics in the literature and which portions of dialogues (including vs. excluding robots' participation and human participation in HHI vs. HRI) will better predict learning as a group. We test the hypotheses with another study and replicate them with automatically obtained units of participation to simulate the information available to robots when they adaptively fix imbalances in real-time. Finally, we discuss recommendations on which metrics learning science researchers should choose when trying to understand how to facilitate collaboration.
Incorporating Geo-Diverse Knowledge into Prompting for Increased Geographical Robustness in Object Recognition
Jan 03, 2024



Existing object recognition models have been shown to lack robustness in diverse geographical scenarios due to significant domain shifts in design and context. Class representations need to be adapted to more accurately reflect an object concept under these shifts. In the absence of training data from target geographies, we hypothesize that geography-specific descriptive knowledge of object categories can be leveraged to enhance robustness. For this purpose, we explore the feasibility of probing a large-language model for geography-specific object knowledge, and we investigate integrating knowledge in zero-shot and learnable soft prompting with the CLIP vision-language model. In particular, we propose a geography knowledge regularization method to ensure that soft prompts trained on a source set of geographies generalize to an unseen target set of geographies. Our gains on DollarStreet when generalizing from a model trained only on data from Europe are as large as +2.8 on countries from Africa, and +4.6 on the hardest classes. We further show competitive performance vs. few-shot target training, and provide insights into how descriptive knowledge captures geographical differences.
Semi-Supervised Domain Generalization for Object Detection via Language-Guided Feature Alignment
Sep 24, 2023



Existing domain adaptation (DA) and generalization (DG) methods in object detection enforce feature alignment in the visual space but face challenges like object appearance variability and scene complexity, which make it difficult to distinguish between objects and achieve accurate detection. In this paper, we are the first to address the problem of semi-supervised domain generalization by exploring vision-language pre-training and enforcing feature alignment through the language space. We employ a novel Cross-Domain Descriptive Multi-Scale Learning (CDDMSL) aiming to maximize the agreement between descriptions of an image presented with different domain-specific characteristics in the embedding space. CDDMSL significantly outperforms existing methods, achieving 11.7% and 7.5% improvement in DG and DA settings, respectively. Comprehensive analysis and ablation studies confirm the effectiveness of our method, positioning CDDMSL as a promising approach for domain generalization in object detection tasks.
Impact of Experiencing Misrecognition by Teachable Agents on Learning and Rapport
Jun 11, 2023

While speech-enabled teachable agents have some advantages over typing-based ones, they are vulnerable to errors stemming from misrecognition by automatic speech recognition (ASR). These errors may propagate, resulting in unexpected changes in the flow of conversation. We analyzed how such changes are linked with learning gains and learners' rapport with the agents. Our results show they are not related to learning gains or rapport, regardless of the types of responses the agents should have returned given the correct input from learners without ASR errors. We also discuss the implications for optimal error-recovery policies for teachable agents that can be drawn from these findings.
Hypernymization of named entity-rich captions for grounding-based multi-modal pretraining
Apr 25, 2023Named entities are ubiquitous in text that naturally accompanies images, especially in domains such as news or Wikipedia articles. In previous work, named entities have been identified as a likely reason for low performance of image-text retrieval models pretrained on Wikipedia and evaluated on named entities-free benchmark datasets. Because they are rarely mentioned, named entities could be challenging to model. They also represent missed learning opportunities for self-supervised models: the link between named entity and object in the image may be missed by the model, but it would not be if the object were mentioned using a more common term. In this work, we investigate hypernymization as a way to deal with named entities for pretraining grounding-based multi-modal models and for fine-tuning on open-vocabulary detection. We propose two ways to perform hypernymization: (1) a ``manual'' pipeline relying on a comprehensive ontology of concepts, and (2) a ``learned'' approach where we train a language model to learn to perform hypernymization. We run experiments on data from Wikipedia and from The New York Times. We report improved pretraining performance on objects of interest following hypernymization, and we show the promise of hypernymization on open-vocabulary detection, specifically on classes not seen during training.
Boosting Weakly Supervised Object Detection using Fusion and Priors from Hallucinated Depth
Mar 20, 2023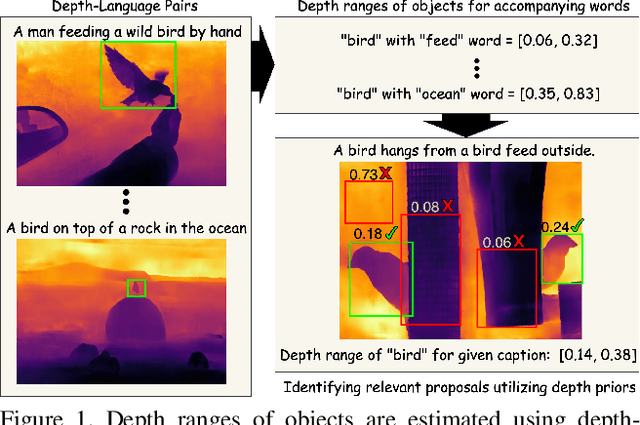
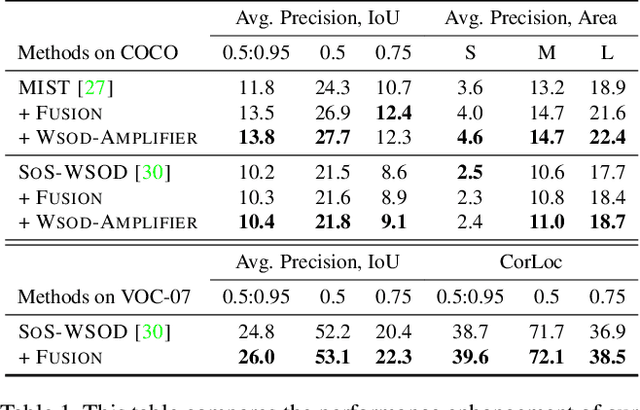
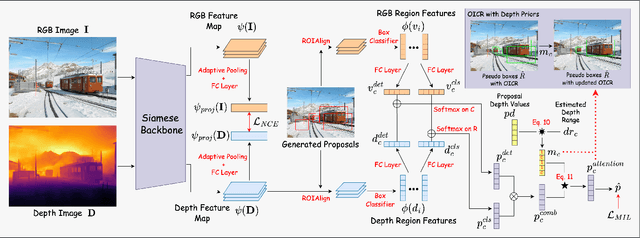
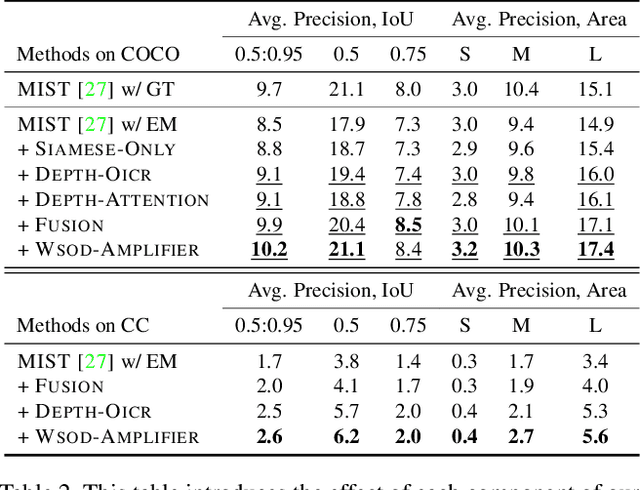
Despite recent attention and exploration of depth for various tasks, it is still an unexplored modality for weakly-supervised object detection (WSOD). We propose an amplifier method for enhancing the performance of WSOD by integrating depth information. Our approach can be applied to any WSOD method based on multiple-instance learning, without necessitating additional annotations or inducing large computational expenses. Our proposed method employs a monocular depth estimation technique to obtain hallucinated depth information, which is then incorporated into a Siamese WSOD network using contrastive loss and fusion. By analyzing the relationship between language context and depth, we calculate depth priors to identify the bounding box proposals that may contain an object of interest. These depth priors are then utilized to update the list of pseudo ground-truth boxes, or adjust the confidence of per-box predictions. Our proposed method is evaluated on six datasets (COCO, PASCAL VOC, Conceptual Captions, Clipart1k, Watercolor2k, and Comic2k) by implementing it on top of two state-of-the-art WSOD methods, and we demonstrate a substantial enhancement in performance.
Enhancing the Role of Context in Region-Word Alignment for Object Detection
Mar 17, 2023



Vision-language pretraining to learn a fine-grained, region-word alignment between image-caption pairs has propelled progress in open-vocabulary object detection. We observe that region-word alignment methods are typically used in detection with respect to only object nouns, and the impact of other rich context in captions, such as attributes, is unclear. In this study, we explore how language context affects downstream object detection and propose to enhance the role of context. In particular, we show how to strategically contextualize the grounding pretraining objective for improved alignment. We further hone in on attributes as especially useful object context and propose a novel adjective and noun-based negative sampling strategy for increasing their focus in contrastive learning. Overall, our methods enhance object detection when compared to the state-of-the-art in region-word pretraining. We also highlight the fine-grained utility of an attribute-sensitive model through text-region retrieval and phrase grounding analysis.
VEIL: Vetting Extracted Image Labels from In-the-Wild Captions for Weakly-Supervised Object Detection
Mar 16, 2023



The use of large-scale vision-language datasets is limited for object detection due to the negative impact of label noise on localization. Prior methods have shown how such large-scale datasets can be used for pretraining, which can provide initial signal for localization, but is insufficient without clean bounding-box data for at least some categories. We propose a technique to "vet" labels extracted from noisy captions. Our method trains a classifier that predicts if an extracted label is actually present in the image or not. Our classifier generalizes across dataset boundaries and shows promise for generalizing across categories as well. We compare the classifier to eleven baselines on five datasets, and demonstrate that it can improve weakly-supervised detection without label vetting by 80% (16.0 to 29.1 mAP when evaluated on PASCAL VOC).
Weakly-Supervised HOI Detection from Interaction Labels Only and Language/Vision-Language Priors
Mar 09, 2023



Human-object interaction (HOI) detection aims to extract interacting human-object pairs and their interaction categories from a given natural image. Even though the labeling effort required for building HOI detection datasets is inherently more extensive than for many other computer vision tasks, weakly-supervised directions in this area have not been sufficiently explored due to the difficulty of learning human-object interactions with weak supervision, rooted in the combinatorial nature of interactions over the object and predicate space. In this paper, we tackle HOI detection with the weakest supervision setting in the literature, using only image-level interaction labels, with the help of a pretrained vision-language model (VLM) and a large language model (LLM). We first propose an approach to prune non-interacting human and object proposals to increase the quality of positive pairs within the bag, exploiting the grounding capability of the vision-language model. Second, we use a large language model to query which interactions are possible between a human and a given object category, in order to force the model not to put emphasis on unlikely interactions. Lastly, we use an auxiliary weakly-supervised preposition prediction task to make our model explicitly reason about space. Extensive experiments and ablations show that all of our contributions increase HOI detection performance.