 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Extraction with Fine-Tuned Large Language Models in Retrieval Augmented Generation Frameworks
Jun 24, 2024



Information Extraction (IE) is crucial for converting unstructured data into structured formats like Knowledge Graphs (KGs). A key task within IE is Relation Extraction (RE), which identifies relationships between entities in text. Various RE methods exist, including supervised, unsupervised, weakly supervised, and rule-based approaches. Recent studies leveraging pre-trained language models (PLMs) have shown significant success in this area. In the current era dominated by Large Language Models (LLMs), fine-tuning these models can overcome limitations associated with zero-shot LLM prompting-based RE methods, especially regarding domain adaptation challenges and identifying implicit relations between entities in sentences. These implicit relations, which cannot be easily extracted from a sentence's dependency tree, require logical inference for accurate identification. This work explores the performance of fine-tuned LLMs and their integration into the Retrieval Augmented-based (RAG) RE approach to address the challenges of identifying implicit relations at the sentence level, particularly when LLMs act as generators within the RAG framework. Empirical evaluations on the TACRED, TACRED-Revisited (TACREV), Re-TACRED, and SemEVAL datasets show significant performance improvements with fine-tuned LLMs, including Llama2-7B, Mistral-7B, and T5 (Large). Notably, our approach achieves substantial gains on SemEVAL, where implicit relations are common, surpassing previous results on this dataset. Additionally, our method outperforms previous works on TACRED, TACREV, and Re-TACRED, demonstrating exceptional performance across diverse evaluation scenarios.
Quantum Architecture Search: A Survey
Jun 10, 2024



Quantum computing has made significant progress in recent years, attracting immense interest not only in research laboratories but also in various industries. However, the application of quantum computing to solve real-world problems is still hampered by a number of challenges, including hardware limitations and a relatively under-explored landscape of quantum algorithms, especially when compared to the extensive development of classical computing. The design of quantum circuits, in particular parameterized quantum circuits (PQCs), which contain learnable parameters optimized by classical methods, is a non-trivial and time-consuming task requiring expert knowledge. As a result, research on the automated generation of PQCs, known as quantum architecture search (QAS), has gained considerable interest. QAS focuses on the use of machine learning and optimization-driven techniques to generate PQCs tailored to specific problems and characteristics of quantum hardware. In this paper, we provide an overview of QAS methods by examining relevant research studies in the field. We discuss main challenges in designing and performing an automated search for an optimal PQC, and survey ways to address them to ease future research.
TR2MTL: LLM based framework for Metric Temporal Logic Formalization of Traffic Rules
Jun 09, 2024



Traffic rules formalization is crucial for verifying the compliance and safety of autonomous vehicles (AVs). However, manual translation of natural language traffic rules as formal specification requires domain knowledge and logic expertise, which limits its adaptation. This paper introduces TR2MTL, a framework that employs large language models (LLMs) to automatically translate traffic rules (TR) into metric temporal logic (MTL). It is envisioned as a human-in-loop system for AV rule formalization. It utilizes a chain-of-thought in-context learning approach to guide the LLM in step-by-step translation and generating valid and grammatically correct MTL formulas. It can be extended to various forms of temporal logic and rules. We evaluated the framework on a challenging dataset of traffic rules we created from various sources and compared it against LLMs using different in-context learning methods. Results show that TR2MTL is domain-agnostic, achieving high accuracy and generalization capability even with a small dataset. Moreover, the method effectively predicts formulas with varying degrees of logical and semantic structure in unstructured traffic rules.
Fine-Grained Named Entities for Corona News
Apr 20, 2024Information resources such as newspapers have produced unstructured text data in various languages related to the corona outbreak since December 2019. Analyzing these unstructured texts is time-consuming without representing them in a structured format; therefore, representing them in a structured format is crucial. An information extraction pipeline with essential tasks -- named entity tagging and relation extraction -- to accomplish this goal might be applied to these texts. This study proposes a data annotation pipeline to generate training data from corona news articles, including generic and domain-specific entities. Named entity recognition models are trained on this annotated corpus and then evaluated on test sentences manually annotated by domain experts evaluating the performance of a trained model. The code base and demonstration are available at https://github.com/sefeoglu/coronanews-ner.git.
* Published at SWAT4HCLS 2023: The 14th International Conference on Semantic Web Applications and Tools for Health Care and Life Sciences
Retrieval-Augmented Generation-based Relation Extraction
Apr 20, 2024



Information Extraction (IE) is a transformative process that converts unstructured text data into a structured format by employing entity and relation extraction (RE) methodologies. The identification of the relation between a pair of entities plays a crucial role within this framework. Despite the existence of various techniques for relation extraction, their efficacy heavily relies on access to labeled data and substantial computational resources. In addressing these challenges, Large Language Models (LLMs) emerge as promising solutions; however, they might return hallucinating responses due to their own training data. To overcome these limitations, Retrieved-Augmented Generation-based Relation Extraction (RAG4RE) in this work is proposed, offering a pathway to enhance the performance of relation extraction tasks. This work evaluated the effectiveness of our RAG4RE approach utilizing different LLMs. Through the utilization of established benchmarks, such as TACRED, TACREV, Re-TACRED, and SemEval RE datasets, our aim is to comprehensively evaluate the efficacy of our RAG4RE approach. In particularly, we leverage prominent LLMs including Flan T5, Llama2, and Mistral in our investigation. The results of our study demonstrate that our RAG4RE approach surpasses performance of traditional RE approaches based solely on LLMs, particularly evident in the TACRED dataset and its variations. Furthermore, our approach exhibits remarkable performance compared to previous RE methodologies across both TACRED and TACREV datasets, underscoring its efficacy and potential for advancing RE tasks in natural language processing.
Hybrid Quantum Machine Learning Assisted Classification of COVID-19 from Computed Tomography Scans
Oct 04, 2023



Practical quantum computing (QC) is still in its infancy and problems considered are usually fairly small, especially in quantum machine learning when compared to its classical counterpart. Image processing applications in particular require models that are able to handle a large amount of features, and while classical approaches can easily tackle this, it is a major challenge and a cause for harsh restrictions in contemporary QC. In this paper, we apply a hybrid quantum machine learning approach to a practically relevant problem with real world-data. That is, we apply hybrid quantum transfer learning to an image processing task in the field of medical image processing. More specifically, we classify large CT-scans of the lung into COVID-19, CAP, or Normal. We discuss quantum image embedding as well as hybrid quantum machine learning and evaluate several approaches to quantum transfer learning with various quantum circuits and embedding techniques.
Hateful Messages: A Conversational Data Set of Hate Speech produced by Adolescents on Discord
Sep 04, 2023With the rise of social media, a rise of hateful content can be observed. Even though the understanding and definitions of hate speech varies, platforms, communities, and legislature all acknowledge the problem. Therefore, adolescents are a new and active group of social media users. The majority of adolescents experience or witness online hate speech. Research in the field of automated hate speech classification has been on the rise and focuses on aspects such as bias, generalizability, and performance. To increase generalizability and performance, it is important to understand biases within the data. This research addresses the bias of youth language within hate speech classification and contributes by providing a modern and anonymized hate speech youth language data set consisting of 88.395 annotated chat messages. The data set consists of publicly available online messages from the chat platform Discord. ~6,42% of the messages were classified by a self-developed annotation schema as hate speech. For 35.553 messages, the user profiles provided age annotations setting the average author age to under 20 years old.
EDSA-Ensemble: an Event Detection Sentiment Analysis Ensemble Architecture
Jan 30, 2023As global digitization continues to grow, technology becomes more affordable and easier to use, and social media platforms thrive, becoming the new means of spreading information and news. Communities are built around sharing and discussing current events. Within these communities, users are enabled to share their opinions about each event. Using Sentiment Analysis to understand the polarity of each message belonging to an event, as well as the entire event, can help to better understand the general and individual feelings of significant trends and the dynamics on online social networks. In this context, we propose a new ensemble architecture, EDSA-Ensemble (Event Detection Sentiment Analysis Ensemble), that uses Event Detection and Sentiment Analysis to improve the detection of the polarity for current events from Social Media. For Event Detection, we use techniques based on Information Diffusion taking into account both the time span and the topics. To detect the polarity of each event, we preprocess the text and employ several Machine and Deep Learning models to create an ensemble model. The preprocessing step includes several word representation models, i.e., raw frequency, TFIDF, Word2Vec, and Transformers. The proposed EDSA-Ensemble architecture improves the event sentiment classification over the individual Machine and Deep Learning models.
ContCommRTD: A Distributed Content-based Misinformation-aware Community Detection System for Real-Time Disaster Reporting
Jan 30, 2023



Real-time social media data can provide useful information on evolving hazards. Alongside traditional methods of disaster detection, the integration of social media data can considerably enhance disaster management. In this paper, we investigate the problem of detecting geolocation-content communities on Twitter and propose a novel distributed system that provides in near real-time information on hazard-related events and their evolution. We show that content-based community analysis leads to better and faster dissemination of reports on hazards. Our distributed disaster reporting system analyzes the social relationship among worldwide geolocated tweets, and applies topic modeling to group tweets by topics. Considering for each tweet the following information: user, timestamp, geolocation, retweets, and replies, we create a publisher-subscriber distribution model for topics. We use content similarity and the proximity of nodes to create a new model for geolocation-content based communities. Users can subscribe to different topics in specific geographical areas or worldwide and receive real-time reports regarding these topics. As misinformation can lead to increase damage if propagated in hazards related tweets, we propose a new deep learning model to detect fake news. The misinformed tweets are then removed from display. We also show empirically the scalability capabilities of the proposed system.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022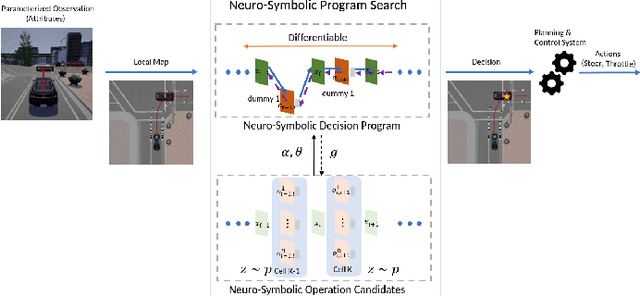
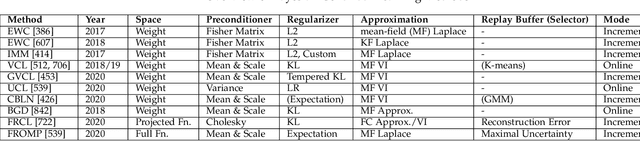
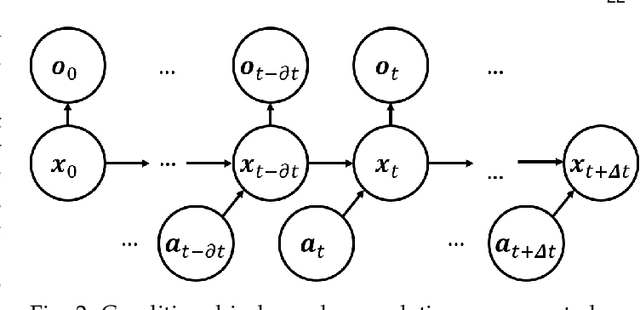
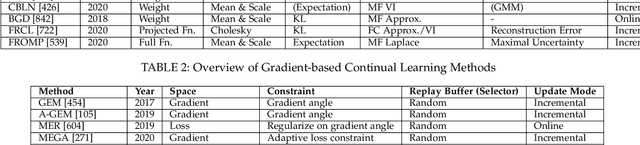
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.