 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Rule Ensembles: Encoding Sparse Feature Interactions into Neural Networks
Feb 11, 2020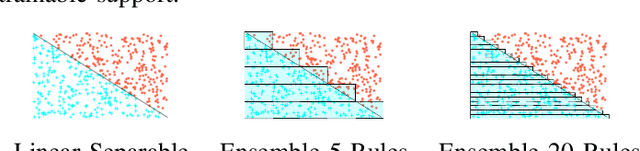
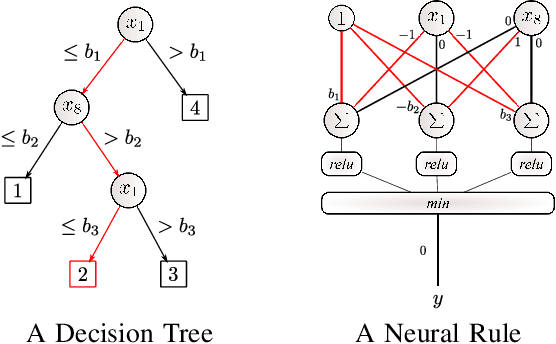
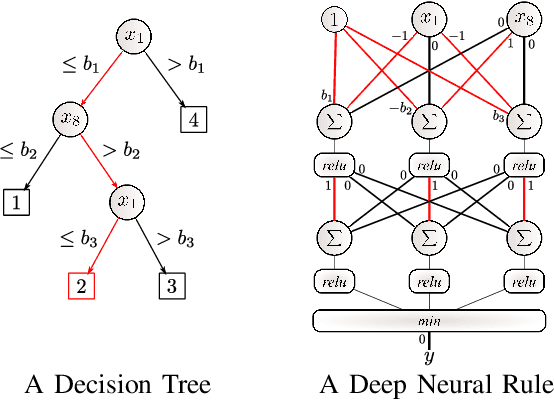

Artificial Neural Networks form the basis of very powerful learning methods. It has been observed that a naive application of fully connected neural networks to data with many irrelevant variables often leads to overfitting. In an attempt to circumvent this issue, a prior knowledge pertaining to what features are relevant and their possible feature interactions can be encoded into these networks. In this work, we use decision trees to capture such relevant features and their interactions and define a mapping to encode extracted relationships into a neural network. This addresses the initialization related concern of fully connected neural networks. At the same time through feature selection it enables learning of compact representations compared to state of the art tree-based approaches. Empirical evaluations and simulation studies show the superiority of such an approach over fully connected neural networks and tree-based approaches
Training Efficient Network Architecture and Weights via Direct Sparsity Control
Feb 11, 2020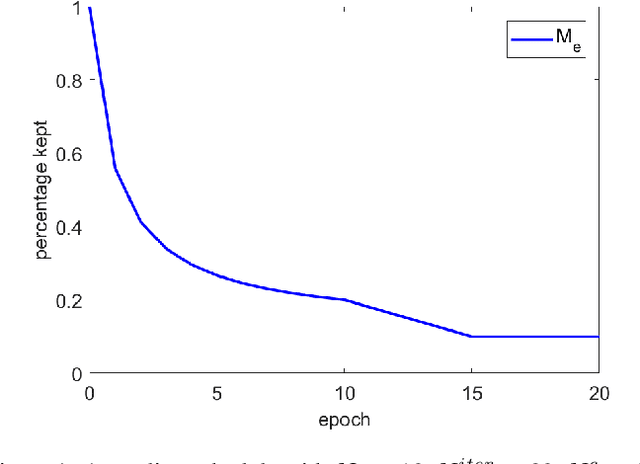
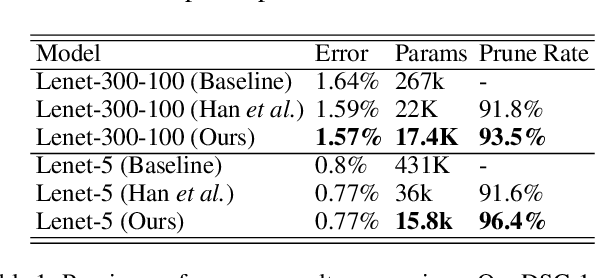
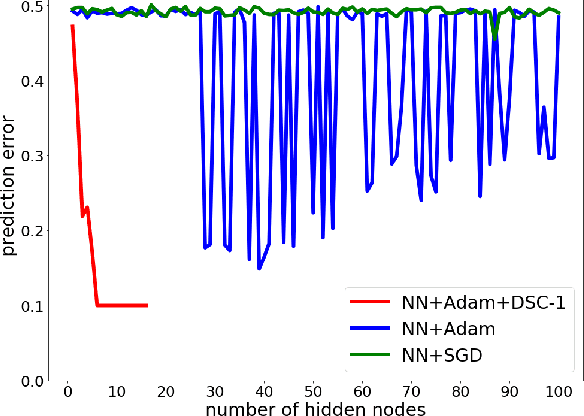
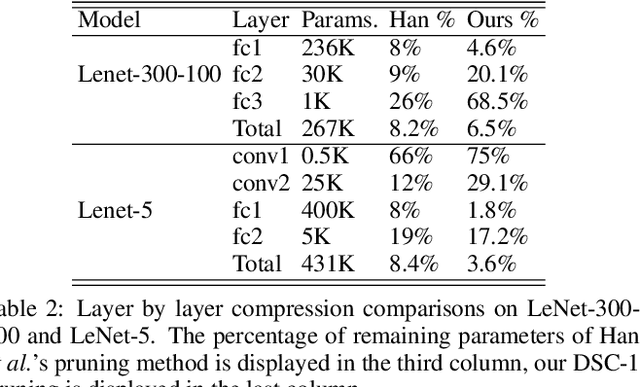
Artificial neural networks (ANNs) especially deep convolutional networks are very popular these days and have been proved to successfully offer quite reliable solutions to many vision problems. However, the use of deep neural networks is widely impeded by their intensive computational and memory cost. In this paper, we propose a novel efficient network pruning method that is suitable for both non-structured and structured channel-level pruning. Our proposed method tightens a sparsity constraint by gradually removing network parameters or filter channels based on a criterion and a schedule. The attractive fact that the network size keeps dropping throughout the iterations makes it suitable for the pruning of any untrained or pre-trained network. Because our method uses a L0 constraint instead of the L1 penalty, it does not introduce any bias in the training parameters or filter channels. Furthermore, the L0 constraint makes it easy to directly specify the desired sparsity level during the network pruning process. Finally, experimental validation on synthetic and real datasets both show that the proposed method obtains better or competitive performance compared to other states of art network pruning methods.
Playing Atari Ball Games with Hierarchical Reinforcement Learning
Sep 27, 2019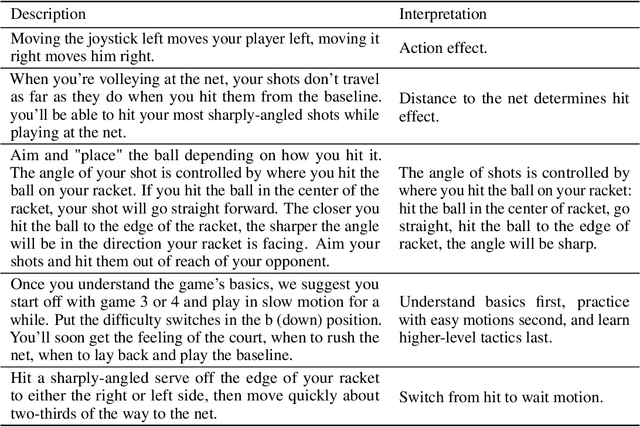
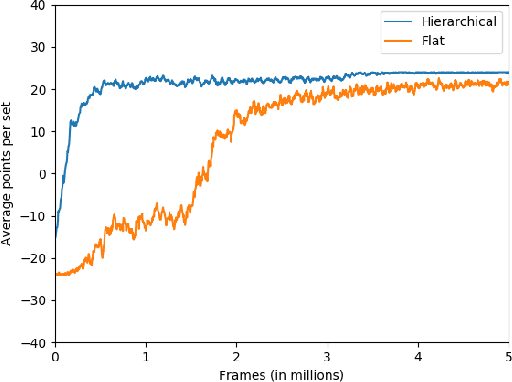
Human beings are particularly good at reasoning and inference from just a few examples. When facing new tasks, humans will leverage knowledge and skills learned before, and quickly integrate them with the new task. In addition to learning by experimentation, human also learn socio-culturally through instructions and learning by example. In this way humans can learn much faster compared with most current artificial intelligence algorithms in many tasks. In this paper, we test the idea of speeding up machine learning through social learning. We argue that in solving real-world problems, especially when the task is designed by humans, and/or for humans, there are typically instructions from user manuals and/or human experts which give guidelines on how to better accomplish the tasks. We argue that these instructions have tremendous value in designing a reinforcement learning system which can learn in human fashion, and we test the idea by playing the Atari games Tennis and Pong. We experimentally demonstrate that the instructions provide key information about the task, which can be used to decompose the learning task into sub-systems and construct options for the temporally extended planning, and dramatically accelerate the learning process.
The Generalization-Stability Tradeoff in Neural Network Pruning
Jun 09, 2019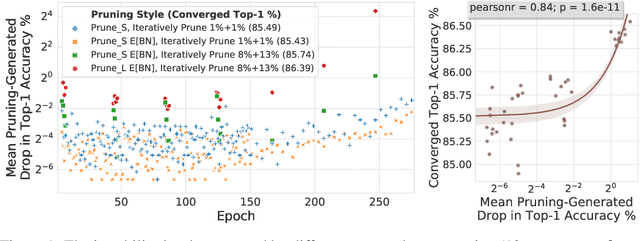
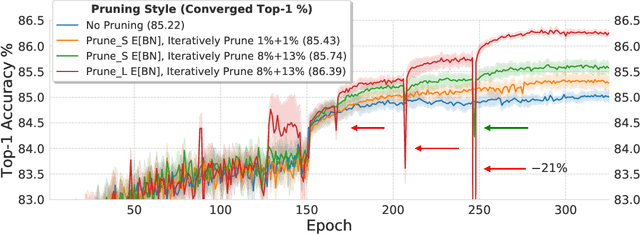
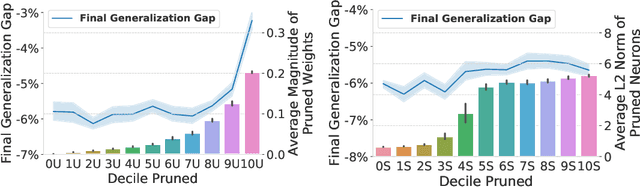
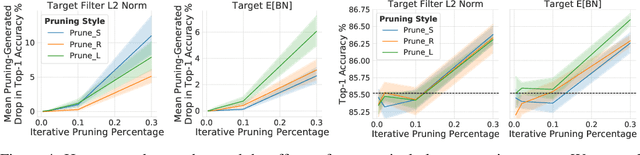
Pruning neural network parameters to reduce model size is an area of much interest, but the original motivation for pruning was the prevention of overfitting rather than the improvement of computational efficiency. This motivation is particularly relevant given the perhaps surprising observation that a wide variety of pruning approaches confer increases in test accuracy, even when parameter counts are drastically reduced. To better understand this phenomenon, we analyze the behavior of pruning over the course of training, finding that pruning's effect on generalization relies more on the instability generated by pruning than the final size of the pruned model. We demonstrate that even pruning of seemingly unimportant parameters can lead to such instability, allowing our finding to account for the generalization benefits of modern pruning techniques. Our results ultimately suggest that, counter-intuitively, pruning regularizes through instability and mechanisms unrelated to parameter counts.
Online Regression with Feature Selection in Stochastic Data Streams
Sep 24, 2018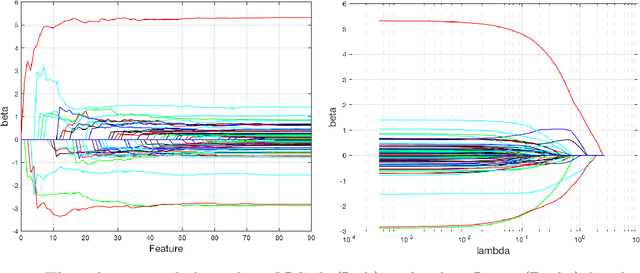
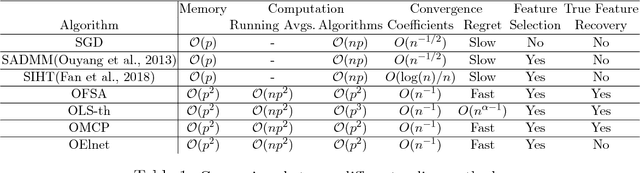
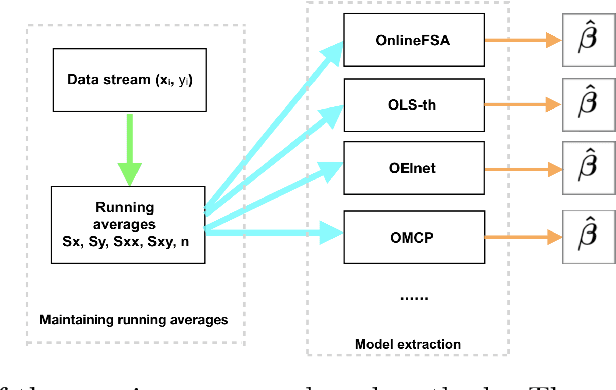
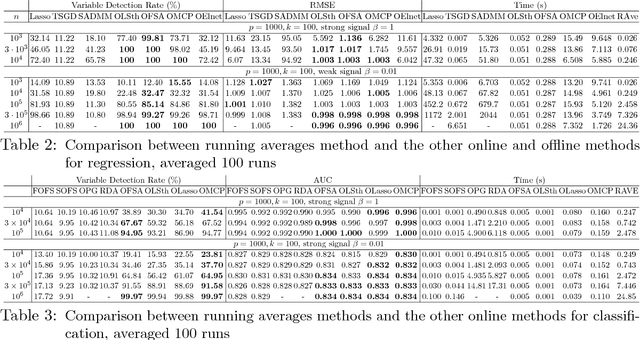
Online learning algorithms have a wide variety of applications in large scale machine learning problems because users can know the performance of current models trained by existing data and they also can update the new models rapidly after data changes. However, the standard online learning methods still suffer some issues such as lower convergence rates and limited capability to select features or to recover the true features. In this paper, we present a novel framework for online learning based on running averages and introduce a series of online versions of some popular existing offline algorithms such as Elastic Net, Minimax Concave Penalty and Feature Selection with Annealing. We prove the equivalence between our online methods and their offline counterparts and give theoretical feature selection and convergence guarantees for some of them. In contrast to the existing online methods, the proposed methods can extract models with any desired sparsity level at any time. Numerical experiments indicate that our new methods enjoy high feature selection accuracy and a fast convergence rate, compared with standard stochastic algorithms and offline learning algorithms. We also present some applications to large datasets where again the proposed framework shows competitive results compared to popular online and offline algorithms.
Are screening methods useful in feature selection? An empirical study
Sep 14, 2018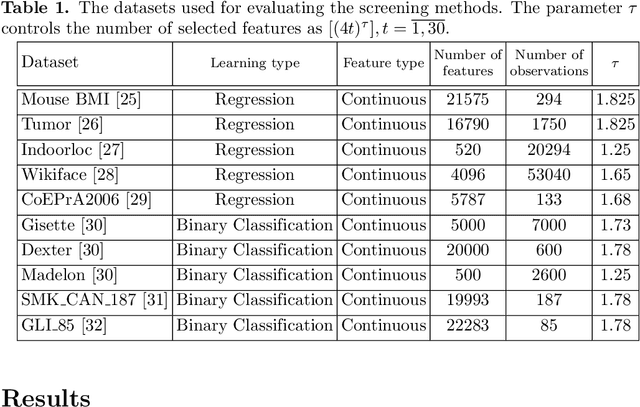
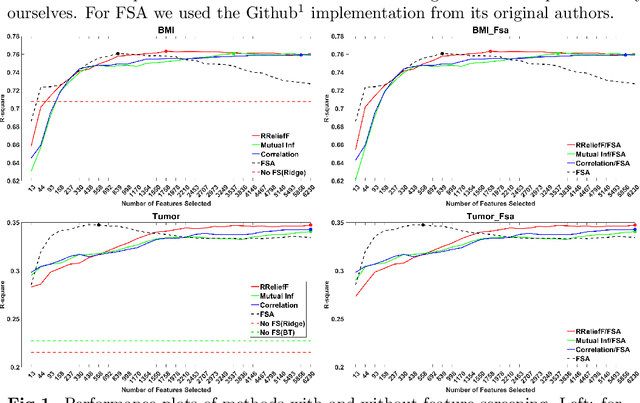
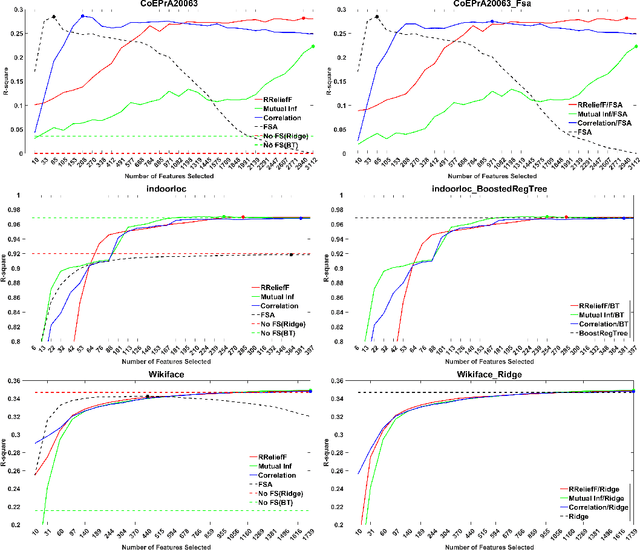
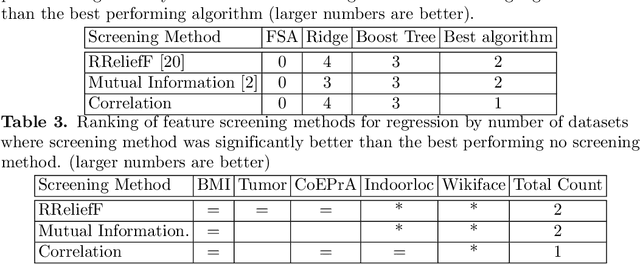
Filter or screening methods are often used as a preprocessing step for reducing the number of variables used by a learning algorithm in obtaining a classification or regression model. While there are many such filter methods, there is a need for an objective evaluation of these methods. Such an evaluation is needed to compare them with each other and also to answer whether they are at all useful, or a learning algorithm could do a better job without them. For this purpose, many popular screening methods are partnered in this paper with three regression learners and five classification learners and evaluated on ten real datasets to obtain accuracy criteria such as R-square and area under the ROC curve (AUC). The obtained results are compared through curve plots and comparison tables in order to find out whether screening methods help improve the performance of learning algorithms and how they fare with each other. Our findings revealed that the screening methods were only useful in one regression and three classification datasets out of the ten datasets evaluated.
Unsupervised Learning of Mixture Models with a Uniform Background Component
May 27, 2018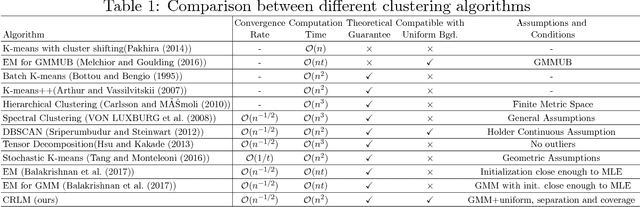


Gaussian Mixture Models are one of the most studied and mature models in unsupervised learning. However, outliers are often present in the data and could influence the cluster estimation. In this paper, we study a new model that assumes that data comes from a mixture of a number of Gaussians as well as a uniform "background" component assumed to contain outliers and other non-interesting observations. We develop a novel method based on robust loss minimization that performs well in clustering such GMM with a uniform background. We give theoretical guarantees for our clustering algorithm to obtain best clustering results with high probability. Besides, we show that the result of our algorithm does not depend on initialization or local optima, and the parameter tuning is an easy task. By numeric simulations, we demonstrate that our algorithm enjoys high accuracy and achieves the best clustering results given a large enough sample size. Finally, experimental comparisons with typical clustering methods on real datasets witness the potential of our algorithm in real applications.
Enhancing the Regularization Effect of Weight Pruning in Artificial Neural Networks
May 04, 2018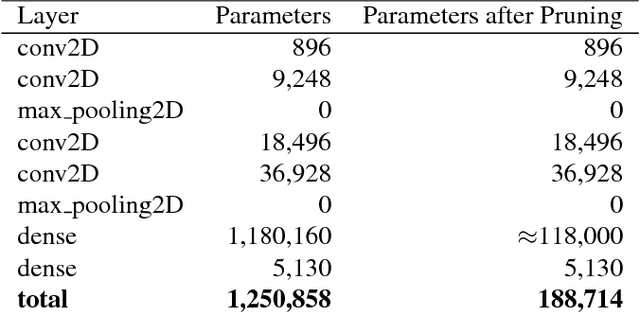
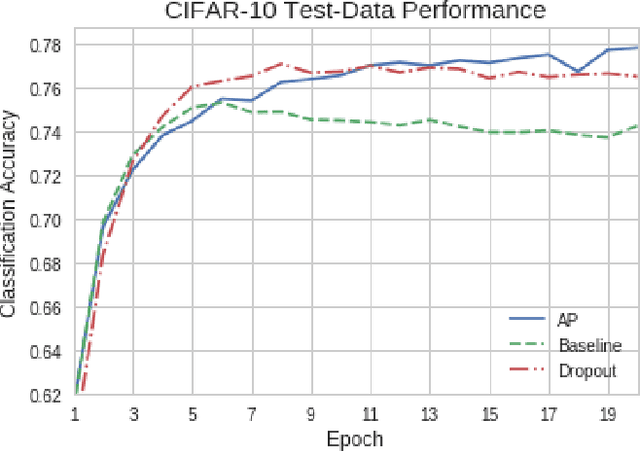
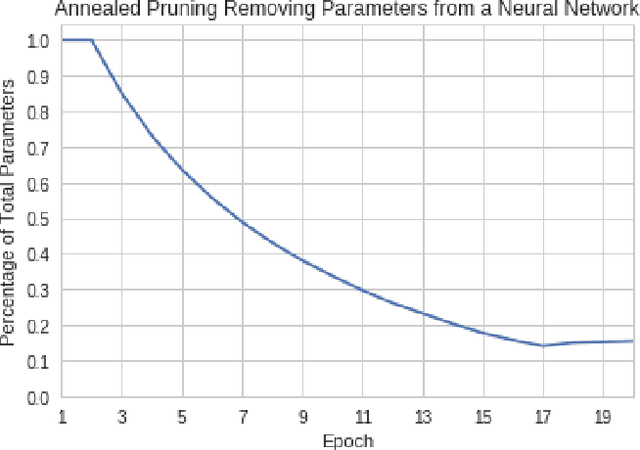
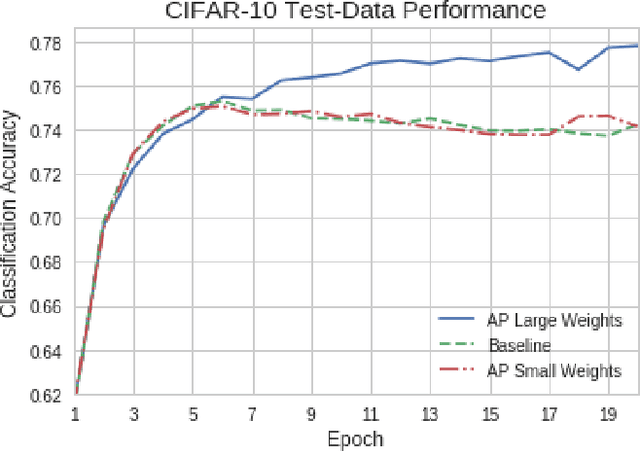
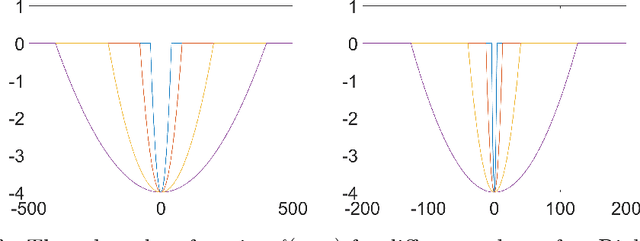
Artificial neural networks (ANNs) may not be worth their computational/memory costs when used in mobile phones or embedded devices. Parameter-pruning algorithms combat these costs, with some algorithms capable of removing over 90% of an ANN's weights without harming the ANN's performance. Removing weights from an ANN is a form of regularization, but existing pruning algorithms do not significantly improve generalization error. We show that pruning ANNs can improve generalization if pruning targets large weights instead of small weights. Applying our pruning algorithm to an ANN leads to a higher image classification accuracy on CIFAR-10 data than applying the popular regularizer dropout. The pruning couples this higher accuracy with an 85% reduction of the ANN's parameter count.
Random Hinge Forest for Differentiable Learning
Mar 01, 2018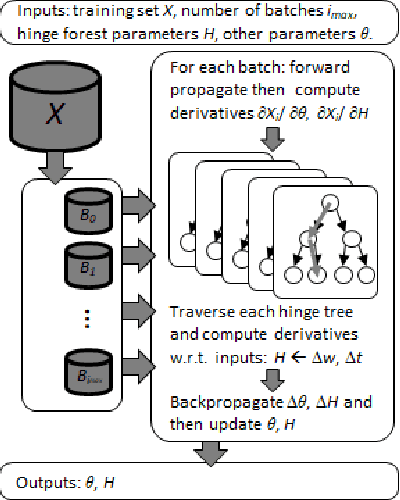
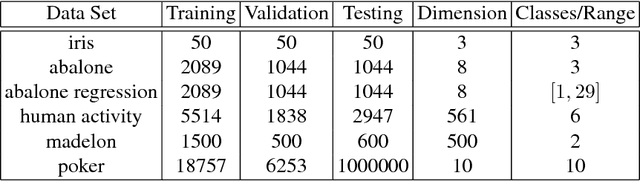
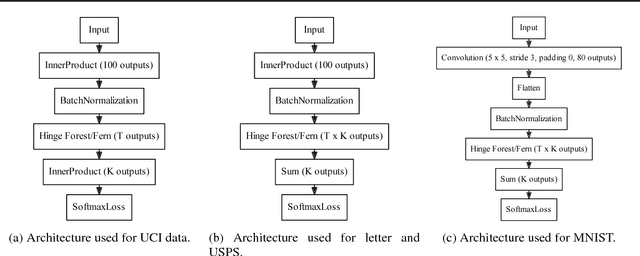
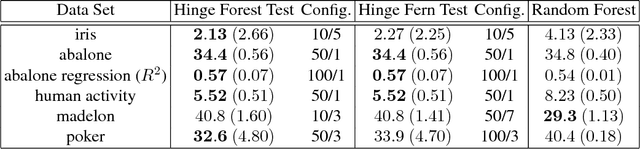
We propose random hinge forests, a simple, efficient, and novel variant of decision forests. Importantly, random hinge forests can be readily incorporated as a general component within arbitrary computation graphs that are optimized end-to-end with stochastic gradient descent or variants thereof. We derive random hinge forest and ferns, focusing on their sparse and efficient nature, their min-max margin property, strategies to initialize them for arbitrary network architectures, and the class of optimizers most suitable for optimizing random hinge forest. The performance and versatility of random hinge forests are demonstrated by experiments incorporating a variety of of small and large UCI machine learning data sets and also ones involving the MNIST, Letter, and USPS image datasets. We compare random hinge forests with random forests and the more recent backpropagating deep neural decision forests.
Relevant Ensemble of Trees
Feb 05, 2018
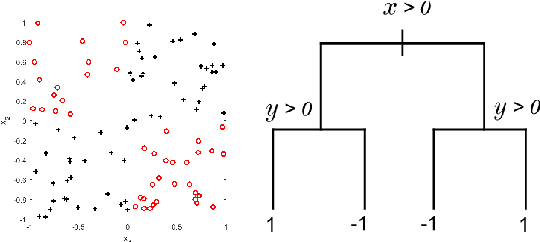
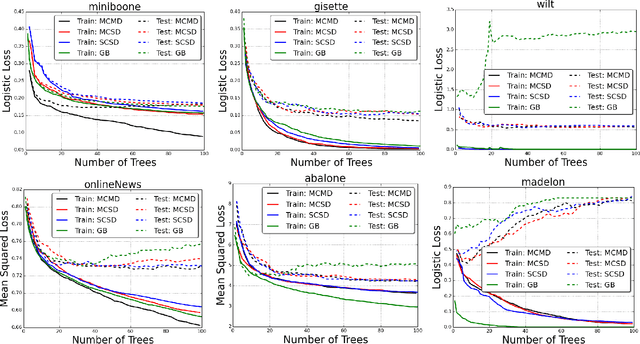
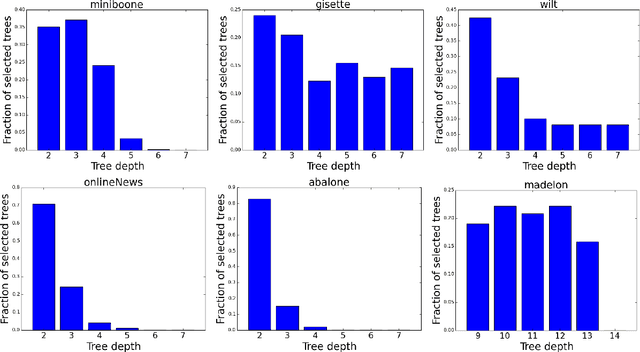
Tree ensembles are flexible predictive models that can capture relevant variables and to some extent their interactions in a compact and interpretable manner. Most algorithms for obtaining tree ensembles are based on versions of boosting or Random Forest. Previous work showed that boosting algorithms exhibit a cyclic behavior of selecting the same tree again and again due to the way the loss is optimized. At the same time, Random Forest is not based on loss optimization and obtains a more complex and less interpretable model. In this paper we present a novel method for obtaining compact tree ensembles by growing a large pool of trees in parallel with many independent boosting threads and then selecting a small subset and updating their leaf weights by loss optimization. We allow for the trees in the initial pool to have different depths which further helps with generalization. Experiments on real datasets show that the obtained model has usually a smaller loss than boosting, which is also reflected in a lower misclassification error on the test set.