 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICA Lens: Interpreting Language Models Without Training Another Dictionary
Jun 10, 2026Finding interpretable directions in language-model representations is critical for understanding and controlling model behavior. Sparse autoencoders (SAEs) have become the standard tool for this purpose, but using them as the default first lens often requires training, storing, and evaluating large overcomplete dictionaries. This bottleneck limits rapid exploration and raises a fundamental question: how much interpretable structure is already visible from activation geometry before training another neural dictionary? Our intuition is simple: many interpretable directions are selective on tokens, and these directions should look less Gaussian than random directions. We therefore revisit independent component analysis (ICA), a classical method for finding non-Gaussian directions, as a compact lens for language-model interpretability. We find that ICA has been underestimated for LLM interpretability, because prior uses often relied on off-the-shelf ICA implementations that are brittle on LLM activations and lacked systematic tools for inspecting and evaluating the recovered directions. To bridge these gaps, we introduce ICALens, the first practical workflow for stable, efficient, and auditable ICA analysis of LLM representations. It combines an optimized GPU-parallel FastICA pipeline with LLM-specific stability recipes and better fitting diagnostics, enabling efficient and reliable layer-wise analysis. Across GPT-2 Small, Gemma 2 2B, and Qwen 3.5 2B Base, ICALens efficiently recovers compact, human-interpretable directions without per-layer gradient-based dictionary training. On SAEBench, ICA is competitive with public SAEs in sparse probing and outperforms them in targeted probe perturbation under small-to-medium budgets. These results suggest that ICA should not be viewed as a weak baseline, but as an efficient and complementary first lens for exploring language-model representations.
Joint Representation Learning and Clustering via Gradient-Based Manifold Optimization
Apr 15, 2026Clustering and dimensionality reduction have been crucial topics in machine learning and computer vision. Clustering high-dimensional data has been challenging for a long time due to the curse of dimensionality. For that reason, a more promising direction is the joint learning of dimension reduction and clustering. In this work, we propose a Manifold Learning Framework that learns dimensionality reduction and clustering simultaneously. The proposed framework is able to jointly learn the parameters of a dimension reduction technique (e.g. linear projection or a neural network) and cluster the data based on the resulting features (e.g. under a Gaussian Mixture Model framework). The framework searches for the dimension reduction parameters and the optimal clusters by traversing a manifold,using Gradient Manifold Optimization. The obtained The proposed framework is exemplified with a Gaussian Mixture Model as one simple but efficient example, in a process that is somehow similar to unsupervised Linear Discriminant Analysis (LDA). We apply the proposed method to the unsupervised training of simulated data as well as a benchmark image dataset (i.e. MNIST). The experimental results indicate that our algorithm has better performance than popular clustering algorithms from the literature.
Exploring Neural Network Pruning with Screening Methods
Feb 11, 2025



Deep neural networks (DNNs) such as convolutional neural networks (CNNs) for visual tasks, recurrent neural networks (RNNs) for sequence data, and transformer models for rich linguistic or multimodal tasks, achieved unprecedented performance on a wide range of tasks. The impressive performance of modern DNNs is partially attributed to their sheer scale. The latest deep learning models have tens to hundreds of millions of parameters which makes the inference processes resource-intensive. The high computational complexity of these networks prevents their deployment on resource-limited devices such as mobile platforms, IoT devices, and edge computing systems because these devices require energy-efficient and real-time processing capabilities. This paper proposes and evaluates a network pruning framework that eliminates non-essential parameters based on a statistical analysis of network component significance across classification categories. The proposed method uses screening methods coupled with a weighted scheme to assess connection and channel contributions for unstructured and structured pruning which allows for the elimination of unnecessary network elements without significantly degrading model performance. Extensive experimental validation on real-world vision datasets for both fully connected neural networks (FNNs) and CNNs has shown that the proposed framework produces competitive lean networks compared to the original networks. Moreover, the proposed framework outperforms state-of-art network pruning methods in two out of three cases.
Neural Rule Ensembles: Encoding Sparse Feature Interactions into Neural Networks
Feb 11, 2020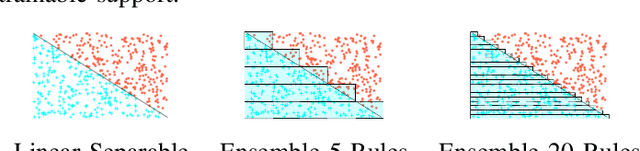
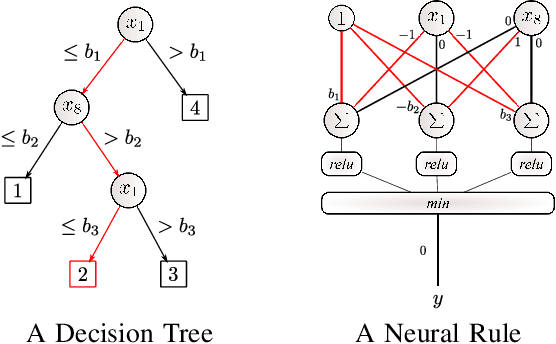
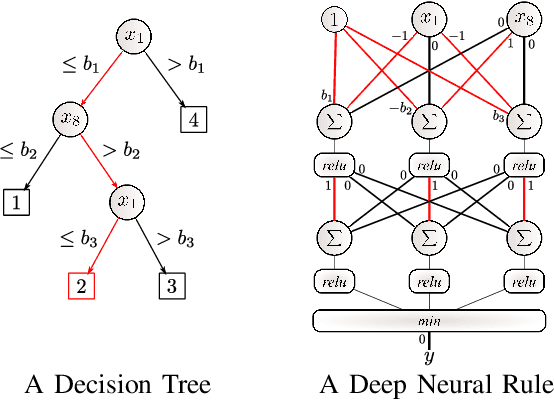

Artificial Neural Networks form the basis of very powerful learning methods. It has been observed that a naive application of fully connected neural networks to data with many irrelevant variables often leads to overfitting. In an attempt to circumvent this issue, a prior knowledge pertaining to what features are relevant and their possible feature interactions can be encoded into these networks. In this work, we use decision trees to capture such relevant features and their interactions and define a mapping to encode extracted relationships into a neural network. This addresses the initialization related concern of fully connected neural networks. At the same time through feature selection it enables learning of compact representations compared to state of the art tree-based approaches. Empirical evaluations and simulation studies show the superiority of such an approach over fully connected neural networks and tree-based approaches
Unsupervised Learning of Mixture Models with a Uniform Background Component
May 27, 2018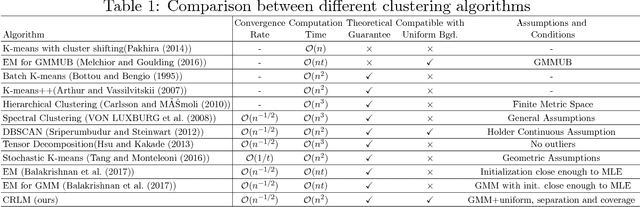


Gaussian Mixture Models are one of the most studied and mature models in unsupervised learning. However, outliers are often present in the data and could influence the cluster estimation. In this paper, we study a new model that assumes that data comes from a mixture of a number of Gaussians as well as a uniform "background" component assumed to contain outliers and other non-interesting observations. We develop a novel method based on robust loss minimization that performs well in clustering such GMM with a uniform background. We give theoretical guarantees for our clustering algorithm to obtain best clustering results with high probability. Besides, we show that the result of our algorithm does not depend on initialization or local optima, and the parameter tuning is an easy task. By numeric simulations, we demonstrate that our algorithm enjoys high accuracy and achieves the best clustering results given a large enough sample size. Finally, experimental comparisons with typical clustering methods on real datasets witness the potential of our algorithm in real applications.