 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Necessity of Learnable Sheaf Laplacians
Mar 05, 2026Sheaf Neural Networks (SNNs) were introduced as an extension of Graph Convolutional Networks to address oversmoothing on heterophilous graphs by attaching a sheaf to the input graph and replacing the adjacency-based operator with a sheaf Laplacian defined by (learnable) restriction maps. Prior work motivates this design through theoretical properties of sheaf diffusion and the kernel of the sheaf Laplacian, suggesting that suitable non-identity restriction maps can avoid representations converging to constants across connected components. Since oversmoothing can also be mitigated through residual connections and normalization, we revisit a trivial sheaf construction to ask whether the additional complexity of learning restriction maps is necessary. We introduce an Identity Sheaf Network baseline, where all restriction maps are fixed to the identity, and use it to ablate the empirical improvements reported by sheaf-learning architectures. Across five popular heterophilic benchmarks, the identity baseline achieves comparable performance to a range of SNN variants. Finally, we introduce the Rayleigh quotient as a normalized measure for comparing oversmoothing across models and show that, in trained networks, the behavior predicted by the diffusion-based analysis of SNNs is not reflected empirically. In particular, Identity Sheaf Networks do not appear to suffer more significant oversmoothing than their SNN counterparts.
Learning to Reason Over Time: Timeline Self-Reflection for Improved Temporal Reasoning in Language Models
Apr 07, 2025



Large Language Models (LLMs) have emerged as powerful tools for generating coherent text, understanding context, and performing reasoning tasks. However, they struggle with temporal reasoning, which requires processing time-related information such as event sequencing, durations, and inter-temporal relationships. These capabilities are critical for applications including question answering, scheduling, and historical analysis. In this paper, we introduce TISER, a novel framework that enhances the temporal reasoning abilities of LLMs through a multi-stage process that combines timeline construction with iterative self-reflection. Our approach leverages test-time scaling to extend the length of reasoning traces, enabling models to capture complex temporal dependencies more effectively. This strategy not only boosts reasoning accuracy but also improves the traceability of the inference process. Experimental results demonstrate state-of-the-art performance across multiple benchmarks, including out-of-distribution test sets, and reveal that TISER enables smaller open-source models to surpass larger closed-weight models on challenging temporal reasoning tasks.
FLUID-LLM: Learning Computational Fluid Dynamics with Spatiotemporal-aware Large Language Models
Jun 06, 2024



Learning computational fluid dynamics (CFD) traditionally relies on computationally intensive simulations of the Navier-Stokes equations. Recently, large language models (LLMs) have shown remarkable pattern recognition and reasoning abilities in natural language processing (NLP) and computer vision (CV). However, these models struggle with the complex geometries inherent in fluid dynamics. We introduce FLUID-LLM, a novel framework combining pre-trained LLMs with spatiotemporal-aware encoding to predict unsteady fluid dynamics. Our approach leverages the temporal autoregressive abilities of LLMs alongside spatial-aware layers, bridging the gap between previous CFD prediction methods. Evaluations on standard benchmarks reveal significant performance improvements across various fluid datasets. Our results demonstrate that FLUID-LLM effectively integrates spatiotemporal information into pre-trained LLMs, enhancing CFD task performance.
TabMDA: Tabular Manifold Data Augmentation for Any Classifier using Transformers with In-context Subsetting
Jun 03, 2024



Tabular data is prevalent in many critical domains, yet it is often challenging to acquire in large quantities. This scarcity usually results in poor performance of machine learning models on such data. Data augmentation, a common strategy for performance improvement in vision and language tasks, typically underperforms for tabular data due to the lack of explicit symmetries in the input space. To overcome this challenge, we introduce TabMDA, a novel method for manifold data augmentation on tabular data. This method utilises a pre-trained in-context model, such as TabPFN, to map the data into a manifold space. TabMDA performs label-invariant transformations by encoding the data multiple times with varied contexts. This process explores the manifold of the underlying in-context models, thereby enlarging the training dataset. TabMDA is a training-free method, making it applicable to any classifier. We evaluate TabMDA on five standard classifiers and observe significant performance improvements across various tabular datasets. Our results demonstrate that TabMDA provides an effective way to leverage information from pre-trained in-context models to enhance the performance of downstream classifiers.
HyperBERT: Mixing Hypergraph-Aware Layers with Language Models for Node Classification on Text-Attributed Hypergraphs
Feb 13, 2024



Hypergraphs are marked by complex topology, expressing higher-order interactions among multiple entities with hyperedges. Lately, hypergraph-based deep learning methods to learn informative data representations for the problem of node classification on text-attributed hypergraphs have garnered increasing research attention. However, existing methods struggle to simultaneously capture the full extent of hypergraph structural information and the rich linguistic attributes inherent in the nodes attributes, which largely hampers their effectiveness and generalizability. To overcome these challenges, we explore ways to further augment a pretrained BERT model with specialized hypergraph-aware layers for the task of node classification. Such layers introduce higher-order structural inductive bias into the language model, thus improving the model's capacity to harness both higher-order context information from the hypergraph structure and semantic information present in text. In this paper, we propose a new architecture, HyperBERT, a mixed text-hypergraph model which simultaneously models hypergraph relational structure while maintaining the high-quality text encoding capabilities of a pre-trained BERT. Notably, HyperBERT presents results that achieve a new state-of-the-art on five challenging text-attributed hypergraph node classification benchmarks.
Language Model Knowledge Distillation for Efficient Question Answering in Spanish
Dec 07, 2023

Recent advances in the development of pre-trained Spanish language models has led to significant progress in many Natural Language Processing (NLP) tasks, such as question answering. However, the lack of efficient models imposes a barrier for the adoption of such models in resource-constrained environments. Therefore, smaller distilled models for the Spanish language could be proven to be highly scalable and facilitate their further adoption on a variety of tasks and scenarios. In this work, we take one step in this direction by developing SpanishTinyRoBERTa, a compressed language model based on RoBERTa for efficient question answering in Spanish. To achieve this, we employ knowledge distillation from a large model onto a lighter model that allows for a wider implementation, even in areas with limited computational resources, whilst attaining negligible performance sacrifice. Our experiments show that the dense distilled model can still preserve the performance of its larger counterpart, while significantly increasing inference speedup. This work serves as a starting point for further research and investigation of model compression efforts for Spanish language models across various NLP tasks.
SQLformer: Deep Auto-Regressive Query Graph Generation for Text-to-SQL Translation
Oct 27, 2023



In recent years, there has been growing interest in text-to-SQL translation, which is the task of converting natural language questions into executable SQL queries. This technology is important for its potential to democratize data extraction from databases. However, some of its key hurdles include domain generalisation, which is the ability to adapt to previously unseen databases, and alignment of natural language questions with the corresponding SQL queries. To overcome these challenges, we introduce SQLformer, a novel Transformer architecture specifically crafted to perform text-to-SQL translation tasks. Our model predicts SQL queries as abstract syntax trees (ASTs) in an autoregressive way, incorporating structural inductive bias in the encoder and decoder layers. This bias, guided by database table and column selection, aids the decoder in generating SQL query ASTs represented as graphs in a Breadth-First Search canonical order. Comprehensive experiments illustrate the state-of-the-art performance of SQLformer in the challenging text-to-SQL Spider benchmark. Our implementation is available at https://github.com/AdrianBZG/SQLformer
Unsupervised Fact Verification by Language Model Distillation
Sep 28, 2023



Unsupervised fact verification aims to verify a claim using evidence from a trustworthy knowledge base without any kind of data annotation. To address this challenge, algorithms must produce features for every claim that are both semantically meaningful, and compact enough to find a semantic alignment with the source information. In contrast to previous work, which tackled the alignment problem by learning over annotated corpora of claims and their corresponding labels, we propose SFAVEL (Self-supervised Fact Verification via Language Model Distillation), a novel unsupervised framework that leverages pre-trained language models to distil self-supervised features into high-quality claim-fact alignments without the need for annotations. This is enabled by a novel contrastive loss function that encourages features to attain high-quality claim and evidence alignments whilst preserving the semantic relationships across the corpora. Notably, we present results that achieve a new state-of-the-art on the standard FEVER fact verification benchmark (+8% accuracy) with linear evaluation.
Translating synthetic natural language to database queries: a polyglot deep learning framework
Apr 14, 2021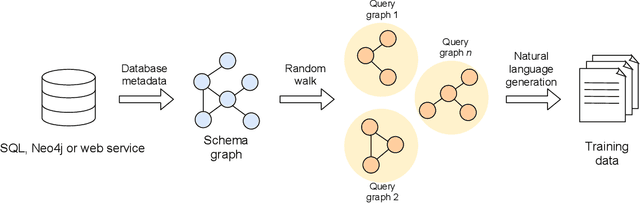
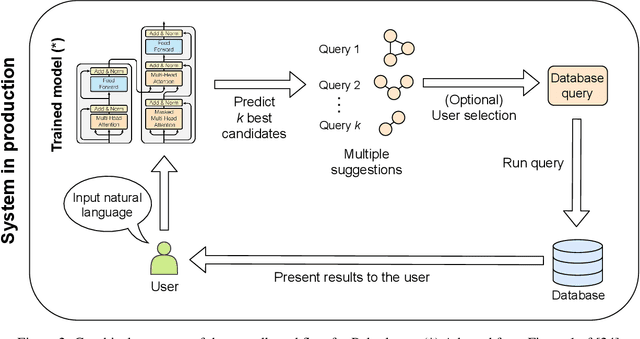
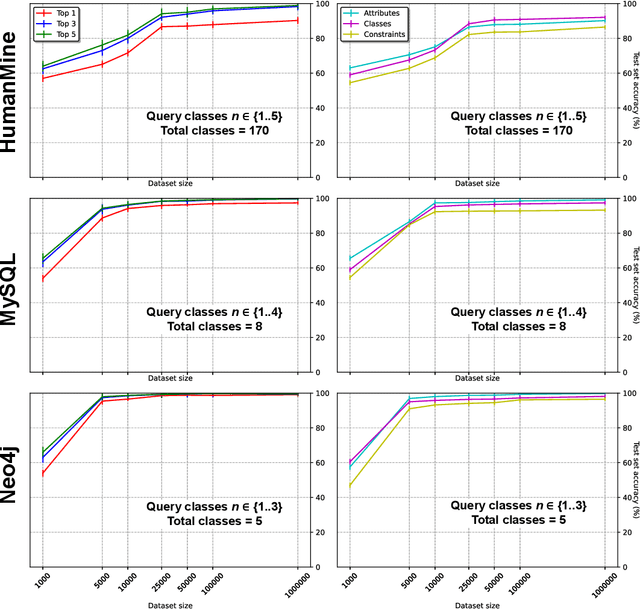
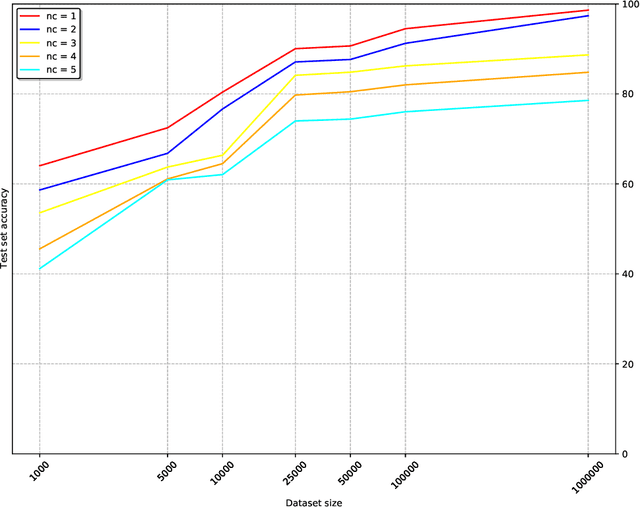
The number of databases as well as their size and complexity is increasing. This creates a barrier to use especially for non-experts, who have to come to grips with the nature of the data, the way it has been represented in the database, and the specific query languages or user interfaces by which data are accessed. These difficulties worsen in research settings, where it is common to work with many different databases. One approach to improving this situation is to allow users to pose their queries in natural language. In this work we describe a machine learning framework, Polyglotter, that in a general way supports the mapping of natural language searches to database queries. Importantly, it does not require the creation of manually annotated data for training and therefore can be applied easily to multiple domains. The framework is polyglot in the sense that it supports multiple different database engines that are accessed with a variety of query languages, including SQL and Cypher. Furthermore Polyglotter also supports multi-class queries. Our results indicate that our framework performs well on both synthetic and real databases, and may provide opportunities for database maintainers to improve accessibility to their resources.
A Convolutional Neural Network for the Automatic Diagnosis of Collagen VI related Muscular Dystrophies
Jan 30, 2019
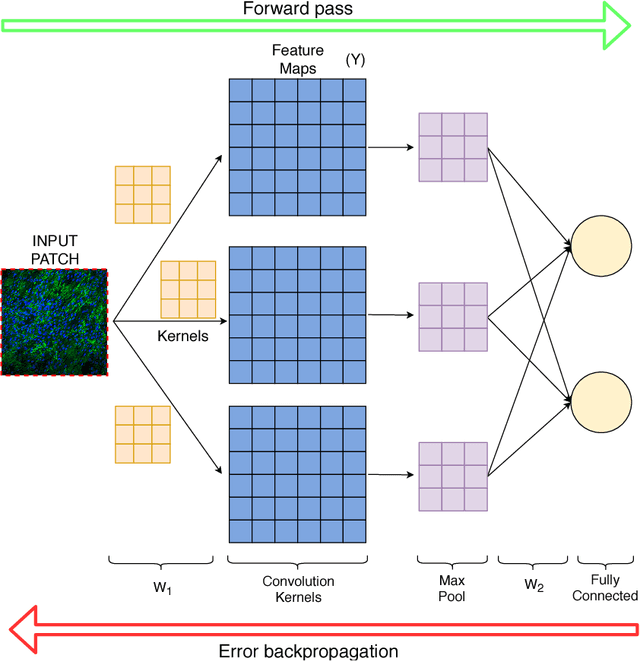


The development of machine learning systems for the diagnosis of rare diseases is challenging mainly due the lack of data to study them. Despite this challenge, this paper proposes a system for the Computer Aided Diagnosis (CAD) of low-prevalence, congenital muscular dystrophies from confocal microscopy images. The proposed CAD system relies on a Convolutional Neural Network (CNN) which performs an independent classification for non-overlapping patches tiling the input image, and generates an overall decision summarizing the individual decisions for the patches on the query image. This decision scheme points to the possibly problematic areas in the input images and provides a global quantitative evaluation of the state of the patients, which is fundamental for diagnosis and to monitor the efficiency of therapies.