 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempGlitch: Evaluating Vision-Language Models for Temporal Glitch Detection in Gameplay Videos
May 20, 2026Vision-language models (VLMs) are increasingly being explored for video game quality assurance, especially gameplay glitch detection. Most existing evaluations, however, treat glitches as static visual anomalies, asking models to detect failures from a single frame. We argue that this framing misses a key distinction: some glitches are spatial and visible in an isolated frame, whereas others are temporal and become evident only through changes across ordered frames. A preliminary study confirms this gap, showing that temporal glitches are substantially harder for VLMs to detect than spatial ones. To enable systematic evaluation of this underexplored setting, we introduce TempGlitch, a controlled gameplay video benchmark for temporal glitch detection. TempGlitch covers five temporal glitch types with balanced per-category samples, together with paired glitch-free videos that enable reliable binary evaluation. We evaluate 12 proprietary and open-weight VLMs across multiple frame-sampling settings. Our results show that current VLMs remain near chance on TempGlitch, often collapsing into either overly conservative behavior that misses most glitches or overly sensitive behavior that flags clean videos as glitchy. Moreover, denser frame sampling and larger model size do not reliably resolve these failures. TempGlitch provides a focused testbed for temporal reasoning, robust gameplay understanding, and automated glitch detection with VLMs. Code and data are available at the project website.
RESP: Reference-guided Sequential Prompting for Visual Glitch Detection in Video Games
Apr 13, 2026Visual glitches in video games degrade player experience and perceived quality, yet manual quality assurance cannot scale to the growing test surface of modern game development. Prior automation efforts, particularly those using vision-language models (VLMs), largely operate on single frames or rely on limited video-level baselines that struggle under realistic scene variation, making robust video-level glitch detection challenging. We present RESP, a practical multi-frame framework for gameplay glitch detection with VLMs. Our key idea is reference-guided prompting: for each test frame, we select a reference frame from earlier in the same video, establishing a visual baseline and reframing detection as within-video comparison rather than isolated classification. RESP sequentially prompts the VLM with reference/test pairs and aggregates noisy frame predictions into a stable video-level decision without fine-tuning the VLM. To enable controlled analysis of reference effects, we introduce RefGlitch, a synthetic dataset of manually labeled reference/test frame pairs with balanced coverage across five glitch types. Experiments across five VLMs and three datasets (one synthetic, two real-world) show that reference guidance consistently strengthens frame-level detection and that the improved frame-level evidence reliably transfers to stronger video-level triage under realistic QA conditions. Code and data are available at: \href{https://github.com/PipiZong/RESP_code.git}{this https URL}.
NoiseBandNet: Controllable Time-Varying Neural Synthesis of Sound Effects Using Filterbanks
Jul 16, 2023



Controllable neural audio synthesis of sound effects is a challenging task due to the potential scarcity and spectro-temporal variance of the data. Differentiable digital signal processing (DDSP) synthesisers have been successfully employed to model and control musical and harmonic signals using relatively limited data and computational resources. Here we propose NoiseBandNet, an architecture capable of synthesising and controlling sound effects by filtering white noise through a filterbank, thus going further than previous systems that make assumptions about the harmonic nature of sounds. We evaluate our approach via a series of experiments, modelling footsteps, thunderstorm, pottery, knocking, and metal sound effects. Comparing NoiseBandNet audio reconstruction capabilities to four variants of the DDSP-filtered noise synthesiser, NoiseBandNet scores higher in nine out of ten evaluation categories, establishing a flexible DDSP method for generating time-varying, inharmonic sound effects of arbitrary length with both good time and frequency resolution. Finally, we introduce some potential creative uses of NoiseBandNet, by generating variations, performing loudness transfer, and by training it on user-defined control curves.
SpecSinGAN: Sound Effect Variation Synthesis Using Single-Image GANs
Oct 14, 2021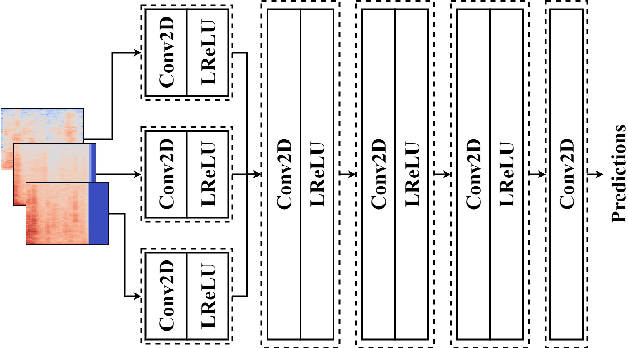
Single-image generative adversarial networks learn from the internal distribution of a single training example to generate variations of it, removing the need of a large dataset. In this paper we introduce SpecSinGAN, an unconditional generative architecture that takes a single one-shot sound effect (e.g., a footstep; a character jump) and produces novel variations of it, as if they were different takes from the same recording session. We explore the use of multi-channel spectrograms to train the model on the various layers that comprise a single sound effect. A listening study comparing our model to real recordings and to digital signal processing procedural audio models in terms of sound plausibility and variation revealed that SpecSinGAN is more plausible and varied than the procedural audio models considered, when using multi-channel spectrograms. Sound examples can be found at the project website: https://www.adrianbarahonarios.com/specsingan/