 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differential Approach to Inference in Bayesian Networks
Jan 16, 2013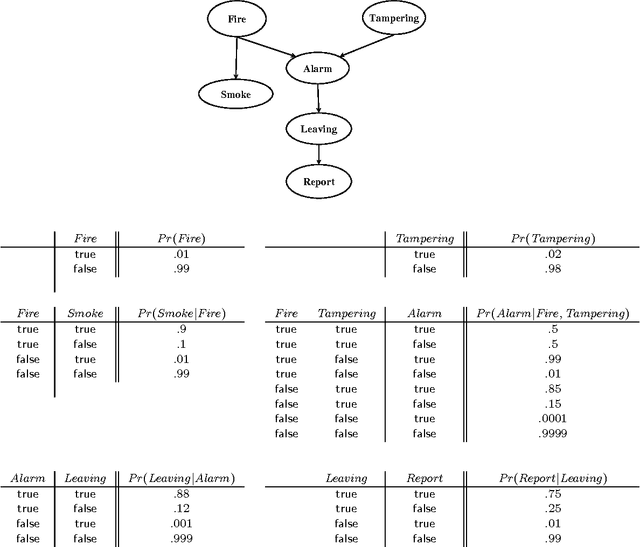
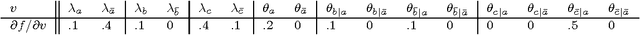
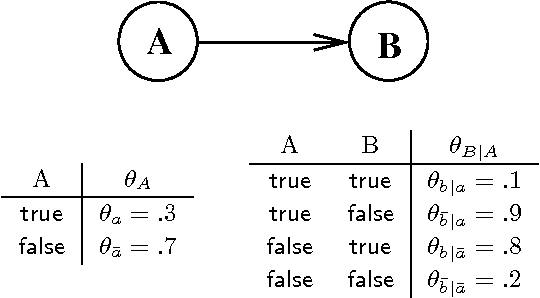
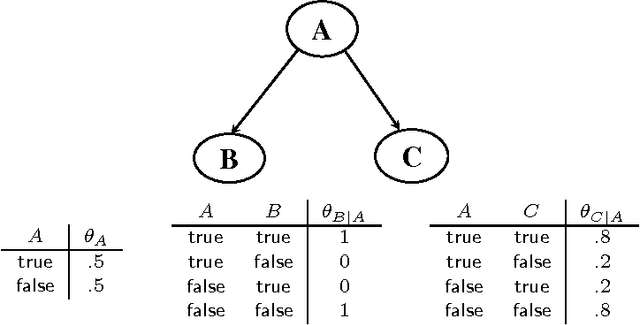
We present a new approach for inference in Bayesian networks, which is mainly based on partial differentiation. According to this approach, one compiles a Bayesian network into a multivariate polynomial and then computes the partial derivatives of this polynomial with respect to each variable. We show that once such derivatives are made available, one can compute in constant-time answers to a large class of probabilistic queries, which are central to classical inference, parameter estimation, model validation and sensitivity analysis. We present a number of complexity results relating to the compilation of such polynomials and to the computation of their partial derivatives. We argue that the combined simplicity, comprehensiveness and computational complexity of the presented framework is unique among existing frameworks for inference in Bayesian networks.
Approximating MAP using Local Search
Jan 10, 2013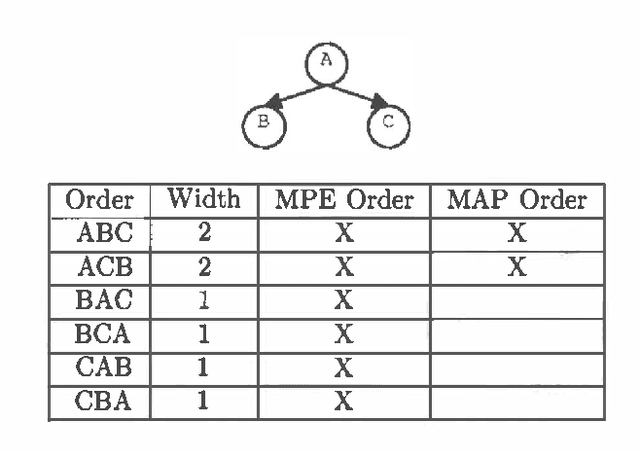
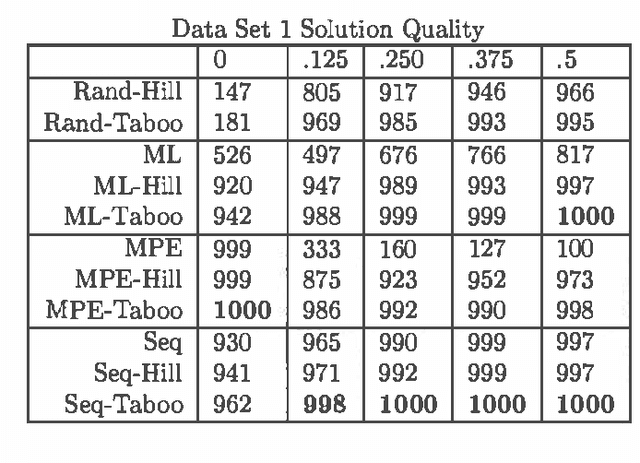
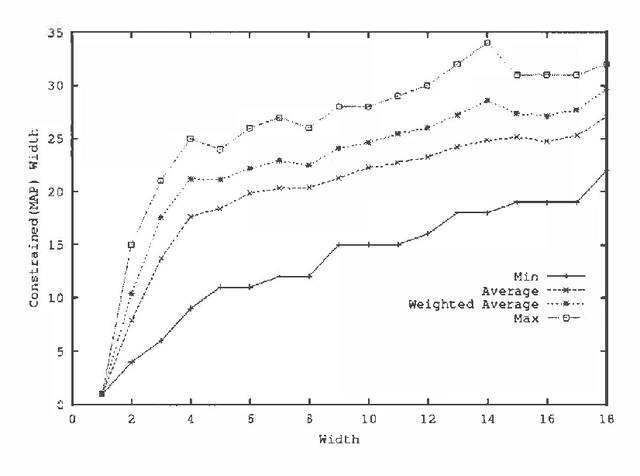
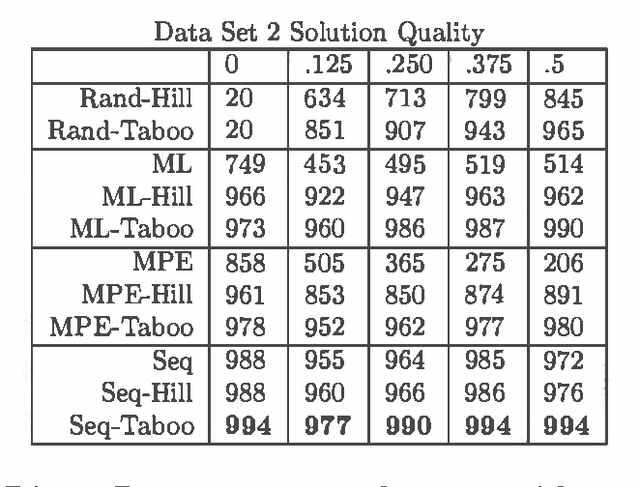
MAP is the problem of finding a most probable instantiation of a set of variables in a Bayesian network, given evidence. Unlike computing marginals, posteriors, and MPE (a special case of MAP), the time and space complexity of MAP is not only exponential in the network treewidth, but also in a larger parameter known as the "constrained" treewidth. In practice, this means that computing MAP can be orders of magnitude more expensive than computingposteriors or MPE. Thus, practitioners generally avoid MAP computations, resorting instead to approximating them by the most likely value for each MAP variableseparately, or by MPE.We present a method for approximating MAP using local search. This method has space complexity which is exponential onlyin the treewidth, as is the complexity of each search step. We investigate the effectiveness of different local searchmethods and several initialization strategies and compare them to otherapproximation schemes.Experimental results show that local search provides a much more accurate approximation of MAP, while requiring few search steps.Practically, this means that the complexity of local search is often exponential only in treewidth as opposed to the constrained treewidth, making approximating MAP as efficient as other computations.
Solving MAP Exactly using Systematic Search
Oct 19, 2012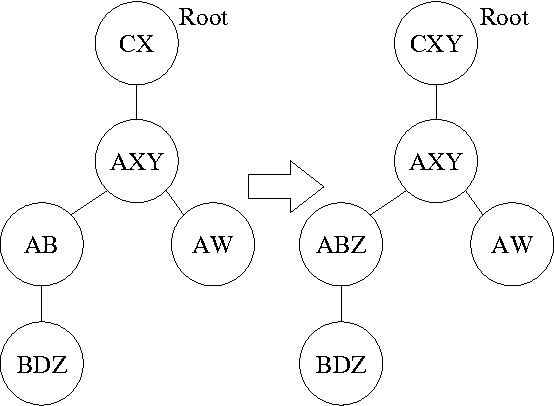
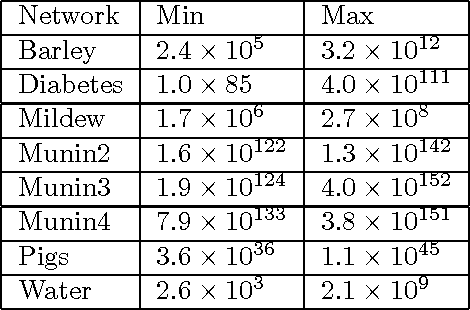
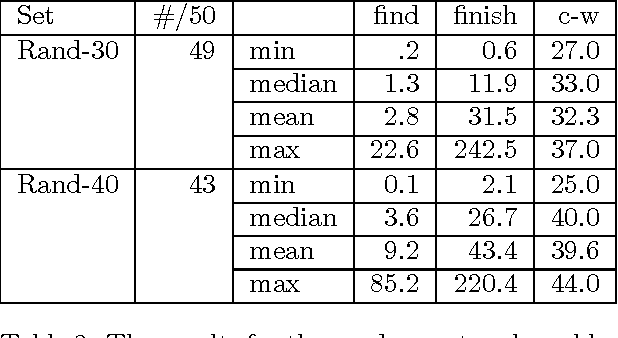
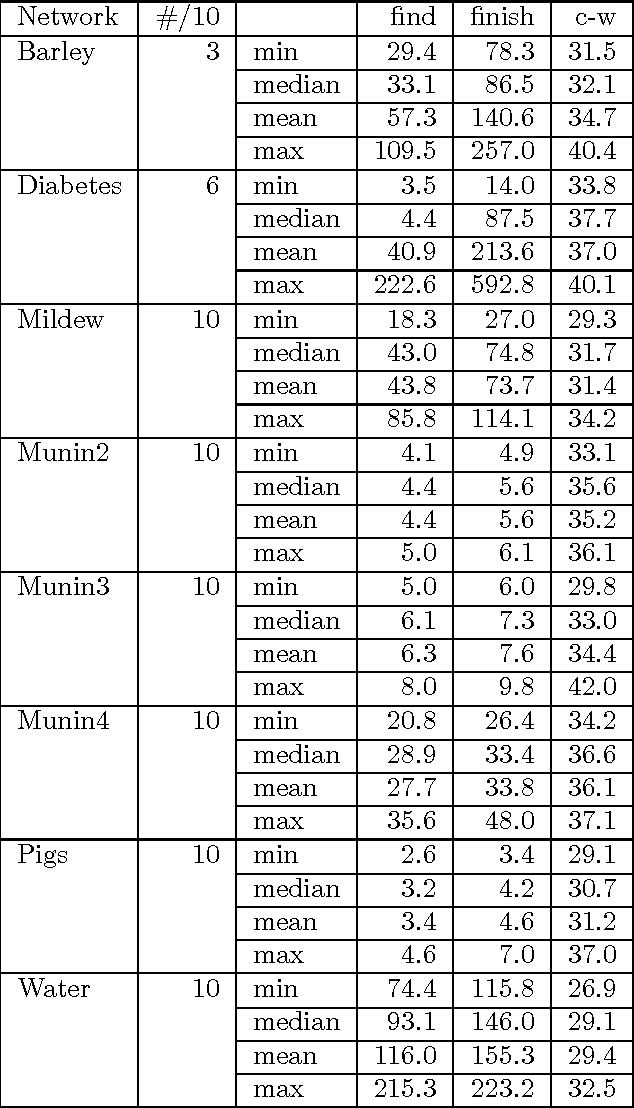
MAP is the problem of finding a most probable instantiation of a set of variables in a Bayesian network given some evidence. Unlike computing posterior probabilities, or MPE (a special case of MAP), the time and space complexity of structural solutions for MAP are not only exponential in the network treewidth, but in a larger parameter known as the "constrained" treewidth. In practice, this means that computing MAP can be orders of magnitude more expensive than computing posterior probabilities or MPE. This paper introduces a new, simple upper bound on the probability of a MAP solution, which admits a tradeoff between the bound quality and the time needed to compute it. The bound is shown to be generally much tighter than those of other methods of comparable complexity. We use this proposed upper bound to develop a branch-and-bound search algorithm for solving MAP exactly. Experimental results demonstrate that the search algorithm is able to solve many problems that are far beyond the reach of any structure-based method for MAP. For example, we show that the proposed algorithm can compute MAP exactly and efficiently for some networks whose constrained treewidth is more than 40.
Reasoning about Bayesian Network Classifiers
Oct 19, 2012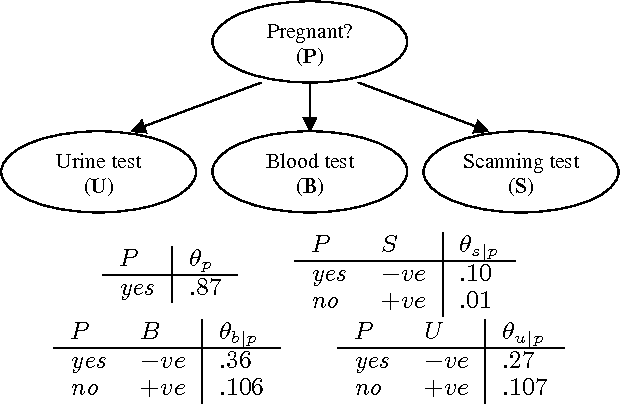
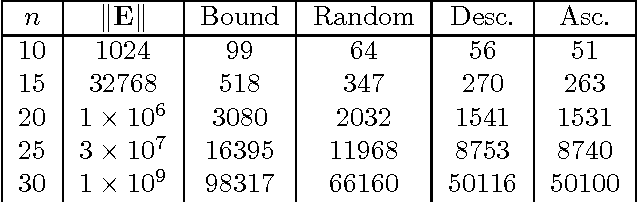
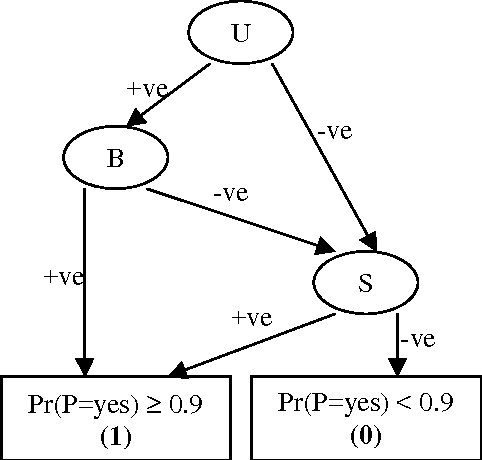
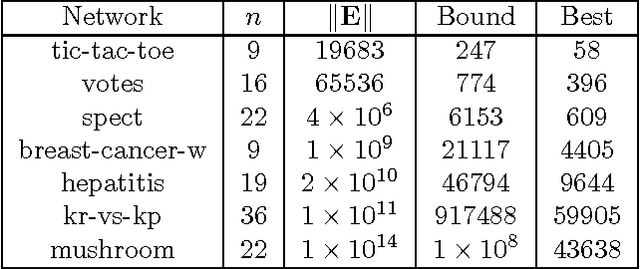
Bayesian network classifiers are used in many fields, and one common class of classifiers are naive Bayes classifiers. In this paper, we introduce an approach for reasoning about Bayesian network classifiers in which we explicitly convert them into Ordered Decision Diagrams (ODDs), which are then used to reason about the properties of these classifiers. Specifically, we present an algorithm for converting any naive Bayes classifier into an ODD, and we show theoretically and experimentally that this algorithm can give us an ODD that is tractable in size even given an intractable number of instances. Since ODDs are tractable representations of classifiers, our algorithm allows us to efficiently test the equivalence of two naive Bayes classifiers and characterize discrepancies between them. We also show a number of additional results including a count of distinct classifiers that can be induced by changing some CPT in a naive Bayes classifier, and the range of allowable changes to a CPT which keeps the current classifier unchanged.
New Advances in Inference by Recursive Conditioning
Oct 19, 2012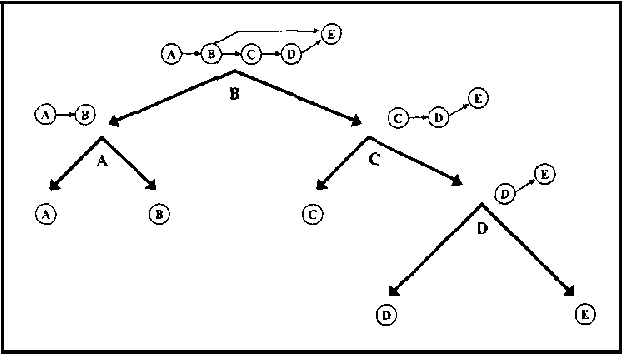
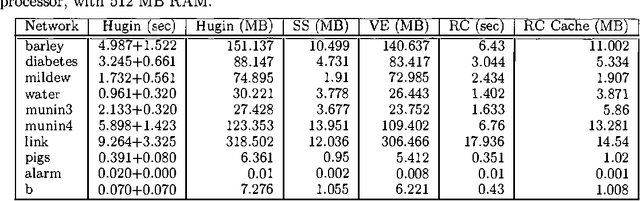
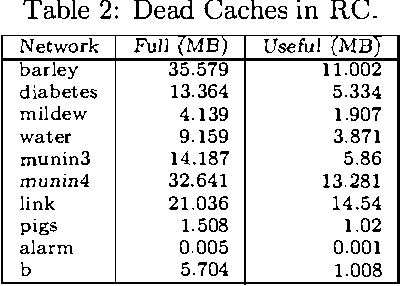
Recursive Conditioning (RC) was introduced recently as the first any-space algorithm for inference in Bayesian networks which can trade time for space by varying the size of its cache at the increment needed to store a floating point number. Under full caching, RC has an asymptotic time and space complexity which is comparable to mainstream algorithms based on variable elimination and clustering (exponential in the network treewidth and linear in its size). We show two main results about RC in this paper. First, we show that its actual space requirements under full caching are much more modest than those needed by mainstream methods and study the implications of this finding. Second, we show that RC can effectively deal with determinism in Bayesian networks by employing standard logical techniques, such as unit resolution, allowing a significant reduction in its time requirements in certain cases. We illustrate our results using a number of benchmark networks, including the very challenging ones that arise in genetic linkage analysis.
New Advances and Theoretical Insights into EDML
Oct 16, 2012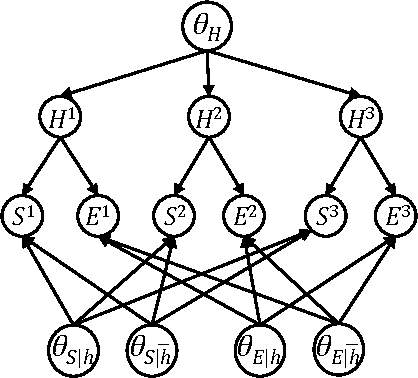
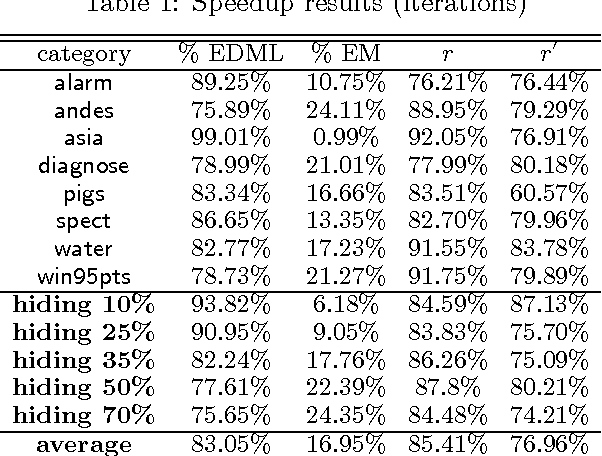
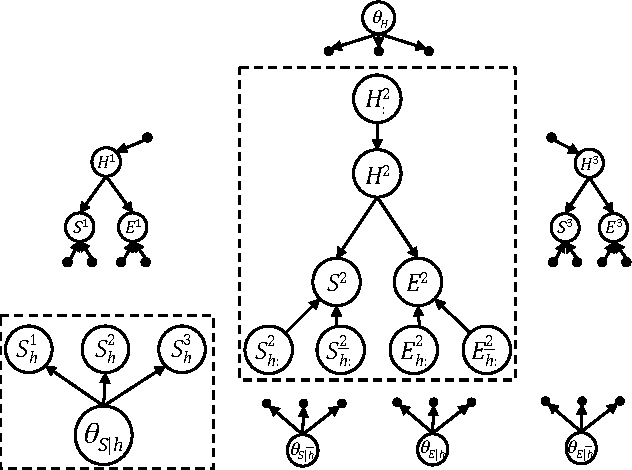
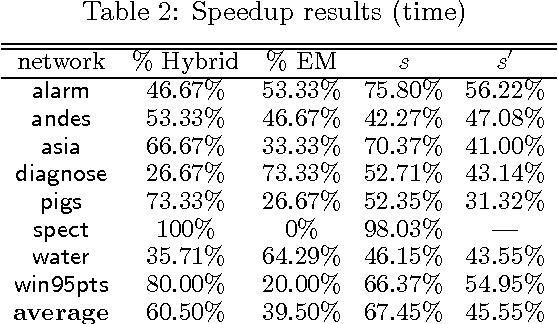
EDML is a recently proposed algorithm for learning MAP parameters in Bayesian networks. In this paper, we present a number of new advances and insights on the EDML algorithm. First, we provide the multivalued extension of EDML, originally proposed for Bayesian networks over binary variables. Next, we identify a simplified characterization of EDML that further implies a simple fixed-point algorithm for the convex optimization problem that underlies it. This characterization further reveals a connection between EDML and EM: a fixed point of EDML is a fixed point of EM, and vice versa. We thus identify also a new characterization of EM fixed points, but in the semantics of EDML. Finally, we propose a hybrid EDML/EM algorithm that takes advantage of the improved empirical convergence behavior of EDML, while maintaining the monotonic improvement property of EM.
Lifted Relax, Compensate and then Recover: From Approximate to Exact Lifted Probabilistic Inference
Oct 16, 2012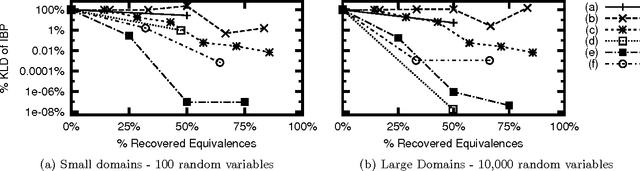
We propose an approach to lifted approximate inference for first-order probabilistic models, such as Markov logic networks. It is based on performing exact lifted inference in a simplified first-order model, which is found by relaxing first-order constraints, and then compensating for the relaxation. These simplified models can be incrementally improved by carefully recovering constraints that have been relaxed, also at the first-order level. This leads to a spectrum of approximations, with lifted belief propagation on one end, and exact lifted inference on the other. We discuss how relaxation, compensation, and recovery can be performed, all at the firstorder level, and show empirically that our approach substantially improves on the approximations of both propositional solvers and lifted belief propagation.
Sensitivity Analysis in Bayesian Networks: From Single to Multiple Parameters
Jul 11, 2012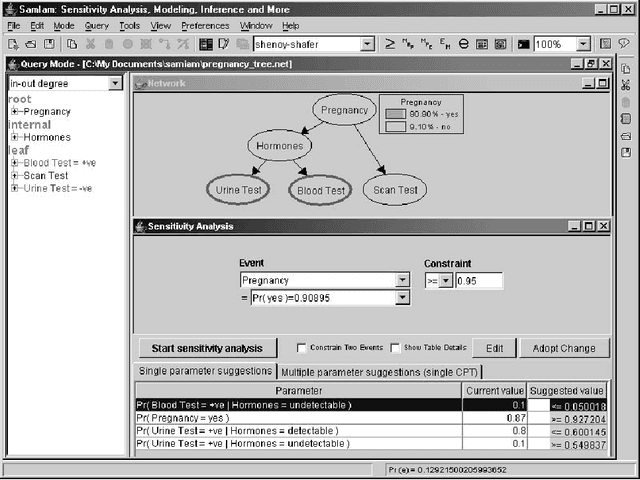
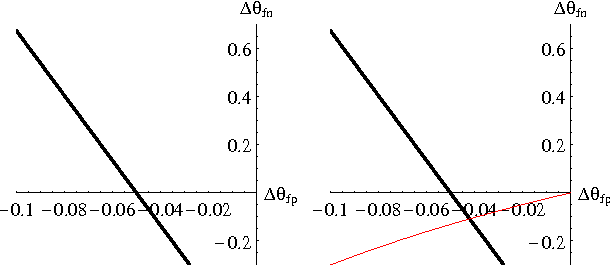
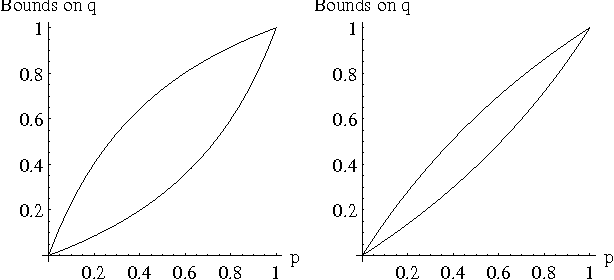
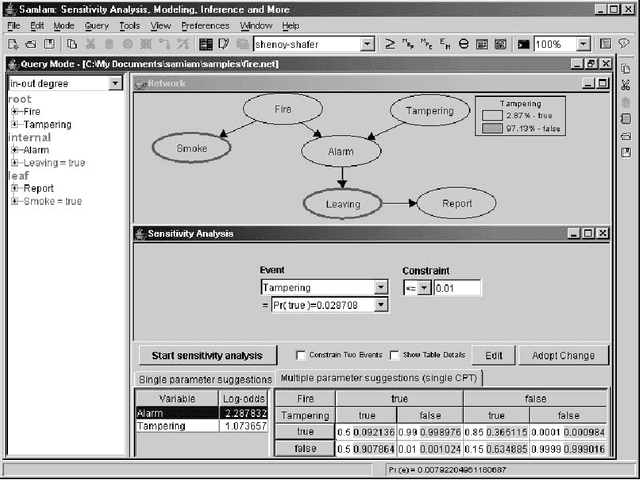
Previous work on sensitivity analysis in Bayesian networks has focused on single parameters, where the goal is to understand the sensitivity of queries to single parameter changes, and to identify single parameter changes that would enforce a certain query constraint. In this paper, we expand the work to multiple parameters which may be in the CPT of a single variable, or the CPTs of multiple variables. Not only do we identify the solution space of multiple parameter changes that would be needed to enforce a query constraint, but we also show how to find the optimal solution, that is, the one which disturbs the current probability distribution the least (with respect to a specific measure of disturbance). We characterize the computational complexity of our new techniques and discuss their applications to developing and debugging Bayesian networks, and to the problem of reasoning about the value (reliability) of new information.
Exploiting Evidence in Probabilistic Inference
Jul 04, 2012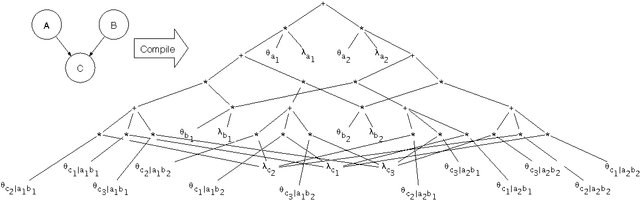
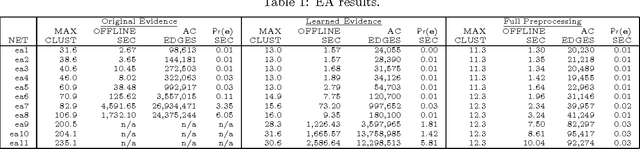
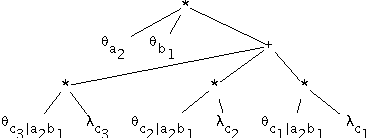
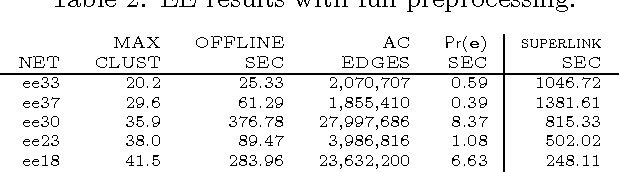
We define the notion of compiling a Bayesian network with evidence and provide a specific approach for evidence-based compilation, which makes use of logical processing. The approach is practical and advantageous in a number of application areas-including maximum likelihood estimation, sensitivity analysis, and MAP computations-and we provide specific empirical results in the domain of genetic linkage analysis. We also show that the approach is applicable for networks that do not contain determinism, and show that it empirically subsumes the performance of the quickscore algorithm when applied to noisy-or networks.
On Bayesian Network Approximation by Edge Deletion
Jul 04, 2012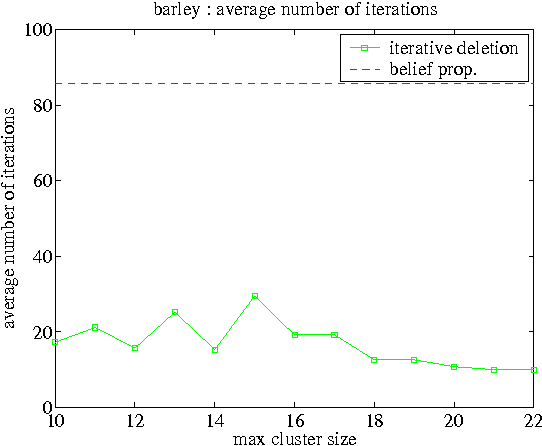
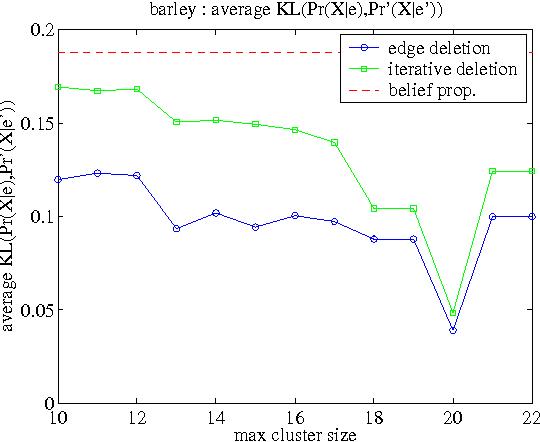
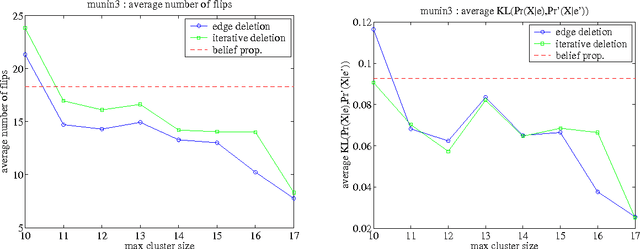
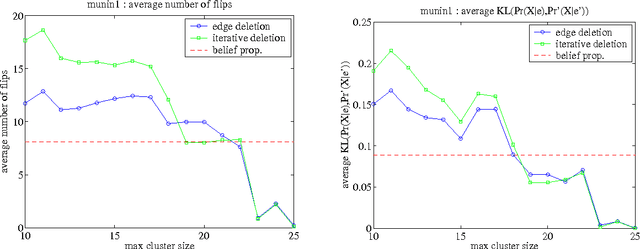
We consider the problem of deleting edges from a Bayesian network for the purpose of simplifying models in probabilistic inference. In particular, we propose a new method for deleting network edges, which is based on the evidence at hand. We provide some interesting bounds on the KL-divergence between original and approximate networks, which highlight the impact of given evidence on the quality of approximation and shed some light on good and bad candidates for edge deletion. We finally demonstrate empirically the promise of the proposed edge deletion technique as a basis for approximate inference.