 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEEK: Semantic Evidence Extraction via Adaptive ChunKing for Multilingual Fact-Checking
May 27, 2026Multilingual fact verification requires evidence that is both relevant and sufficiently complete for reliable factuality prediction. However, existing systems often rely on search snippets, sentence-level evidence, or locally segmented passages, which can miss decisive context and produce fragmented evidence. To overcome these limitations, we propose SEEK, a Semantic Evidence Extraction with an adaptive chunKing framework that constructs coherent evidence chunks from full fact-checking articles by identifying semantic topic transitions and preserving local verification context. The constructed chunks are encoded using a multilingual encoder and then multilingual LLMs are finetuned using LoRA adapter for veracity prediction. Experiments on X-FACT and RU22Fact show that SEEK improves macro-f1 by up to 10% over semantic chunking, 19% over sentence chunking, and 20% over search-snippet baselines. Evidence completeness and significance analyses further show that SEEK preserves richer verification context and enables more reliable multilingual fact-checking.
Multimodal Fact Checking with Unified Visual, Textual, and Contextual Representations
Aug 07, 2025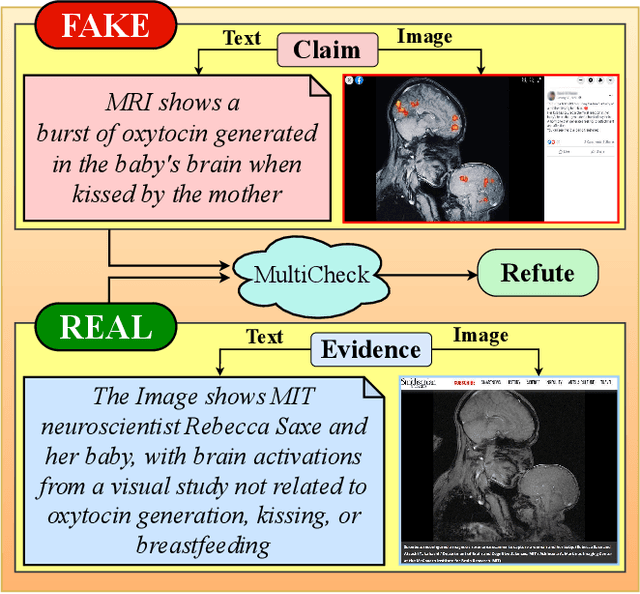



The growing rate of multimodal misinformation, where claims are supported by both text and images, poses significant challenges to fact-checking systems that rely primarily on textual evidence. In this work, we have proposed a unified framework for fine-grained multimodal fact verification called "MultiCheck", designed to reason over structured textual and visual signals. Our architecture combines dedicated encoders for text and images with a fusion module that captures cross-modal relationships using element-wise interactions. A classification head then predicts the veracity of a claim, supported by a contrastive learning objective that encourages semantic alignment between claim-evidence pairs in a shared latent space. We evaluate our approach on the Factify 2 dataset, achieving a weighted F1 score of 0.84, substantially outperforming the baseline. These results highlight the effectiveness of explicit multimodal reasoning and demonstrate the potential of our approach for scalable and interpretable fact-checking in complex, real-world scenarios.