 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Leave-One-Out Conditional Mutual Information For Generalization
Jul 01, 2022

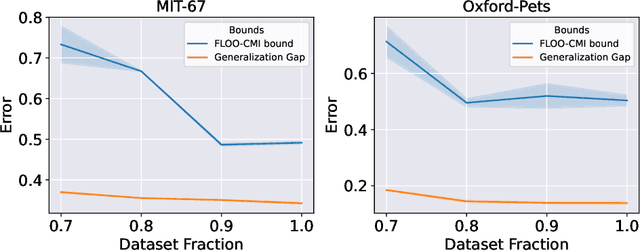
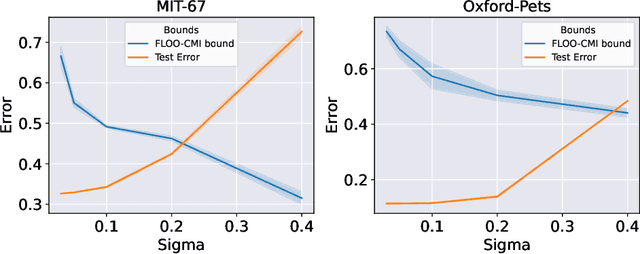
We derive information theoretic generalization bounds for supervised learning algorithms based on a new measure of leave-one-out conditional mutual information (loo-CMI). Contrary to other CMI bounds, which are black-box bounds that do not exploit the structure of the problem and may be hard to evaluate in practice, our loo-CMI bounds can be computed easily and can be interpreted in connection to other notions such as classical leave-one-out cross-validation, stability of the optimization algorithm, and the geometry of the loss-landscape. It applies both to the output of training algorithms as well as their predictions. We empirically validate the quality of the bound by evaluating its predicted generalization gap in scenarios for deep learning. In particular, our bounds are non-vacuous on large-scale image-classification tasks.
Mixed Differential Privacy in Computer Vision
Mar 28, 2022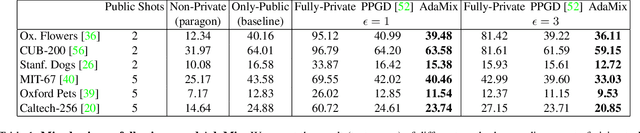
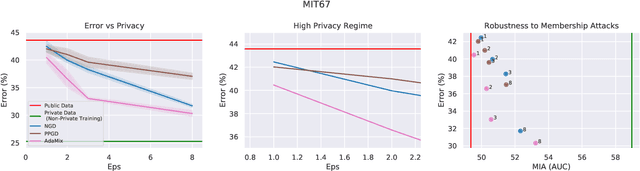
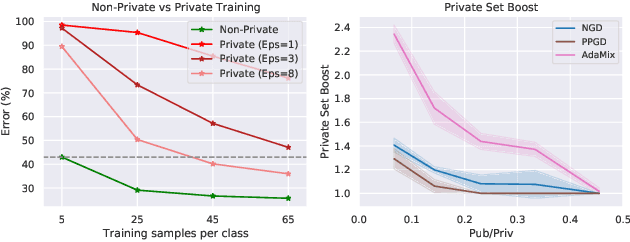
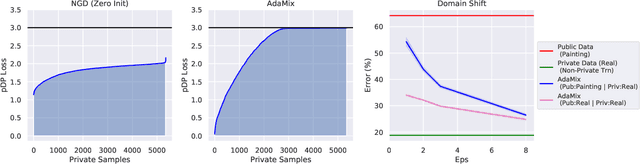
We introduce AdaMix, an adaptive differentially private algorithm for training deep neural network classifiers using both private and public image data. While pre-training language models on large public datasets has enabled strong differential privacy (DP) guarantees with minor loss of accuracy, a similar practice yields punishing trade-offs in vision tasks. A few-shot or even zero-shot learning baseline that ignores private data can outperform fine-tuning on a large private dataset. AdaMix incorporates few-shot training, or cross-modal zero-shot learning, on public data prior to private fine-tuning, to improve the trade-off. AdaMix reduces the error increase from the non-private upper bound from the 167-311\% of the baseline, on average across 6 datasets, to 68-92\% depending on the desired privacy level selected by the user. AdaMix tackles the trade-off arising in visual classification, whereby the most privacy sensitive data, corresponding to isolated points in representation space, are also critical for high classification accuracy. In addition, AdaMix comes with strong theoretical privacy guarantees and convergence analysis.
Scene Uncertainty and the Wellington Posterior of Deterministic Image Classifiers
Jun 25, 2021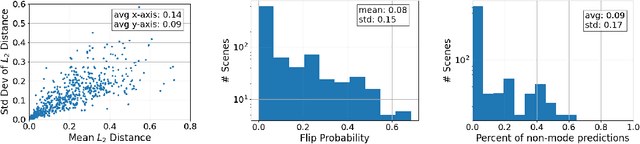
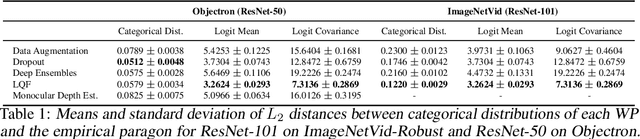
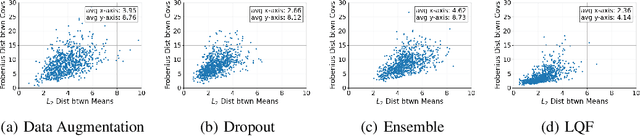
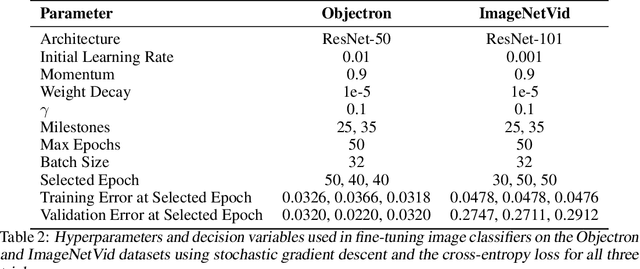
We propose a method to estimate the uncertainty of the outcome of an image classifier on a given input datum. Deep neural networks commonly used for image classification are deterministic maps from an input image to an output class. As such, their outcome on a given datum involves no uncertainty, so we must specify what variability we are referring to when defining, measuring and interpreting "confidence." To this end, we introduce the Wellington Posterior, which is the distribution of outcomes that would have been obtained in response to data that could have been generated by the same scene that produced the given image. Since there are infinitely many scenes that could have generated the given image, the Wellington Posterior requires induction from scenes other than the one portrayed. We explore alternate methods using data augmentation, ensembling, and model linearization. Additional alternatives include generative adversarial networks, conditional prior networks, and supervised single-view reconstruction. We test these alternatives against the empirical posterior obtained by inferring the class of temporally adjacent frames in a video. These developments are only a small step towards assessing the reliability of deep network classifiers in a manner that is compatible with safety-critical applications.
Mixed-Privacy Forgetting in Deep Networks
Dec 24, 2020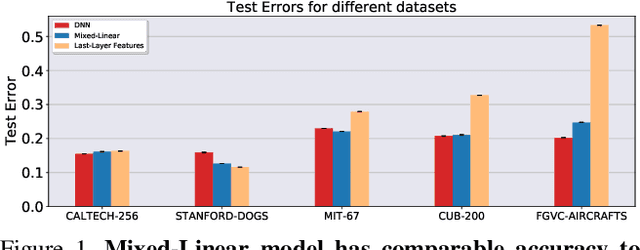
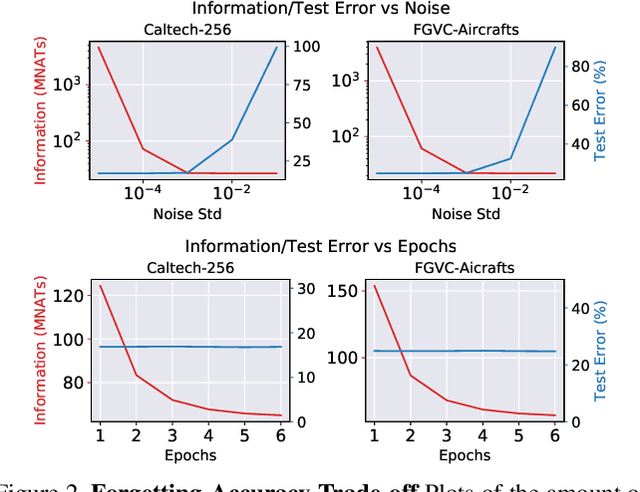
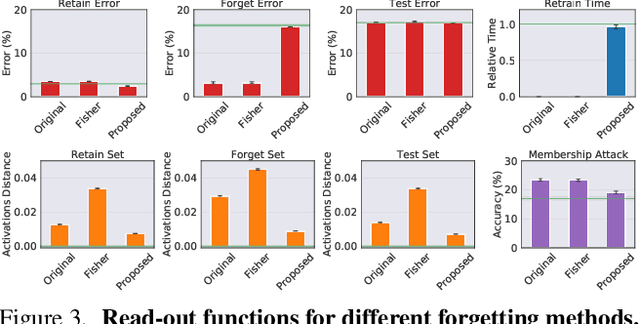
We show that the influence of a subset of the training samples can be removed -- or "forgotten" -- from the weights of a network trained on large-scale image classification tasks, and we provide strong computable bounds on the amount of remaining information after forgetting. Inspired by real-world applications of forgetting techniques, we introduce a novel notion of forgetting in mixed-privacy setting, where we know that a "core" subset of the training samples does not need to be forgotten. While this variation of the problem is conceptually simple, we show that working in this setting significantly improves the accuracy and guarantees of forgetting methods applied to vision classification tasks. Moreover, our method allows efficient removal of all information contained in non-core data by simply setting to zero a subset of the weights with minimal loss in performance. We achieve these results by replacing a standard deep network with a suitable linear approximation. With opportune changes to the network architecture and training procedure, we show that such linear approximation achieves comparable performance to the original network and that the forgetting problem becomes quadratic and can be solved efficiently even for large models. Unlike previous forgetting methods on deep networks, ours can achieve close to the state-of-the-art accuracy on large scale vision tasks. In particular, we show that our method allows forgetting without having to trade off the model accuracy.
LQF: Linear Quadratic Fine-Tuning
Dec 21, 2020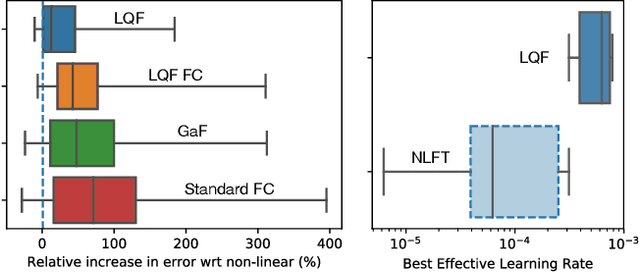
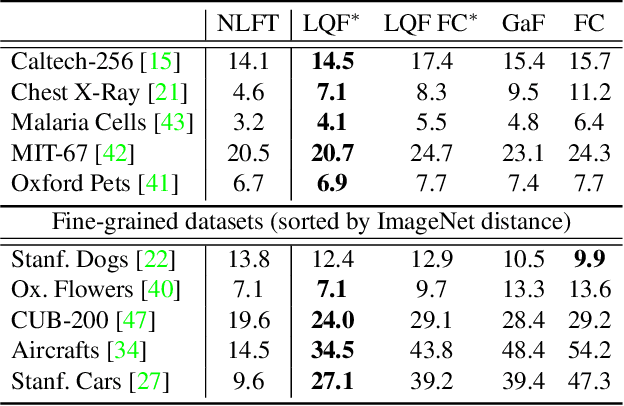
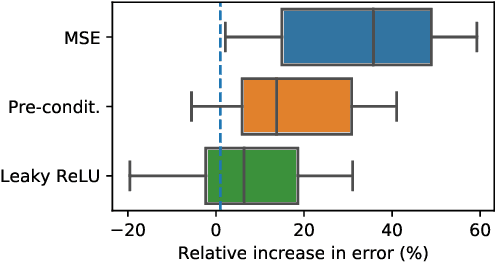
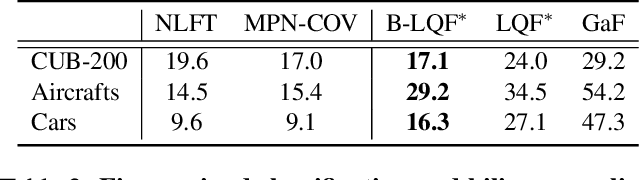
Classifiers that are linear in their parameters, and trained by optimizing a convex loss function, have predictable behavior with respect to changes in the training data, initial conditions, and optimization. Such desirable properties are absent in deep neural networks (DNNs), typically trained by non-linear fine-tuning of a pre-trained model. Previous attempts to linearize DNNs have led to interesting theoretical insights, but have not impacted the practice due to the substantial performance gap compared to standard non-linear optimization. We present the first method for linearizing a pre-trained model that achieves comparable performance to non-linear fine-tuning on most of real-world image classification tasks tested, thus enjoying the interpretability of linear models without incurring punishing losses in performance. LQF consists of simple modifications to the architecture, loss function and optimization typically used for classification: Leaky-ReLU instead of ReLU, mean squared loss instead of cross-entropy, and pre-conditioning using Kronecker factorization. None of these changes in isolation is sufficient to approach the performance of non-linear fine-tuning. When used in combination, they allow us to reach comparable performance, and even superior in the low-data regime, while enjoying the simplicity, robustness and interpretability of linear-quadratic optimization.
Forgetting Outside the Box: Scrubbing Deep Networks of Information Accessible from Input-Output Observations
Mar 16, 2020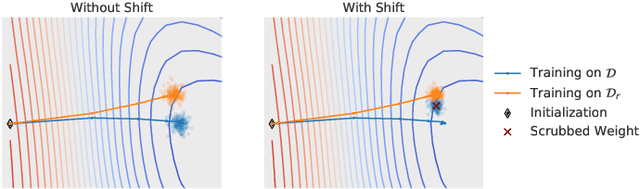
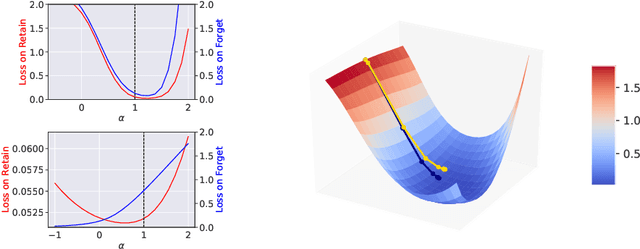
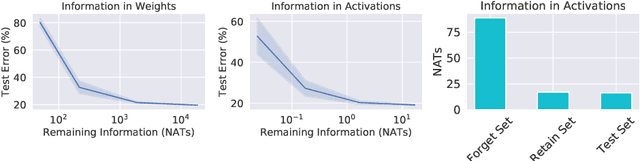
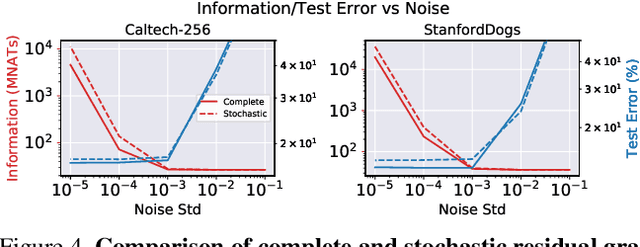
We describe a procedure for removing dependency on a cohort of training data from a trained deep network that improves upon and generalizes previous methods to different readout functions and can be extended to ensure forgetting in the activations of the network. We introduce a new bound on how much information can be extracted per query about the forgotten cohort from a black-box network for which only the input-output behavior is observed. The proposed forgetting procedure has a deterministic part derived from the differential equations of a linearized version of the model, and a stochastic part that ensures information destruction by adding noise tailored to the geometry of the loss landscape. We exploit the connections between the activation and weight dynamics of a DNN inspired by Neural Tangent Kernels to compute the information in the activations.
Eternal Sunshine of the Spotless Net: Selective Forgetting in Deep Networks
Nov 25, 2019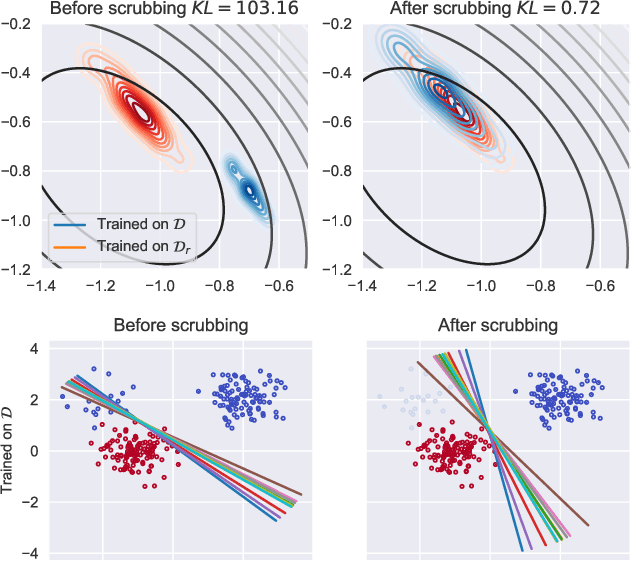
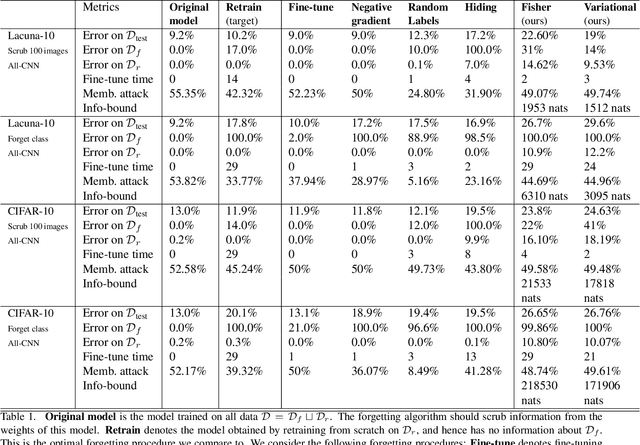
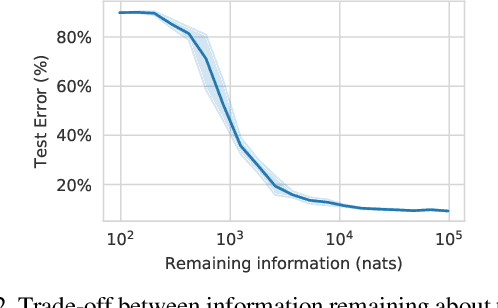
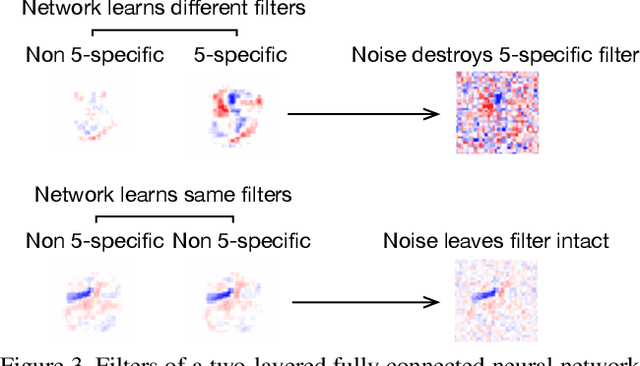
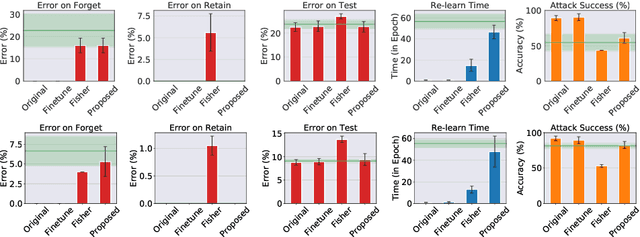
We explore the problem of selectively forgetting a particular set of data used for training a deep neural network. While the effects of the data to be forgotten can be hidden from the output of the network, insights may still be gleaned by probing deep into its weights. We propose a method for "scrubbing" the weights clean of information about a particular set of training data. The method does not require retraining from scratch, nor access to the data originally used for training. Instead, the weights are modified so that any probing function of the weights, computed with no knowledge of the random seed used for training, is indistinguishable from the same function applied to the weights of a network trained without the data to be forgotten. This condition is a generalized and weaker form of Differential Privacy. Exploiting ideas related to the stability of stochastic gradient descent, we introduce an upper-bound on the amount of information remaining in the weights, which can be estimated efficiently even for deep neural networks.
Time Matters in Regularizing Deep Networks: Weight Decay and Data Augmentation Affect Early Learning Dynamics, Matter Little Near Convergence
May 30, 2019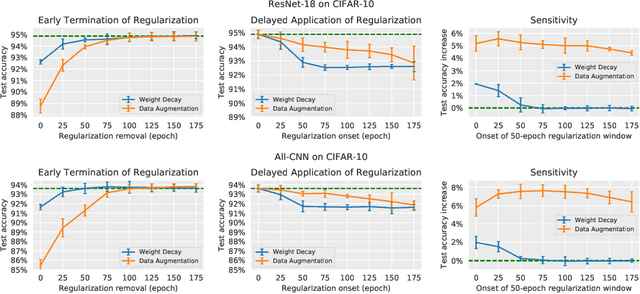
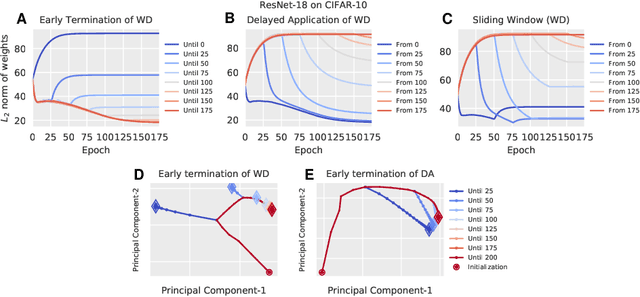
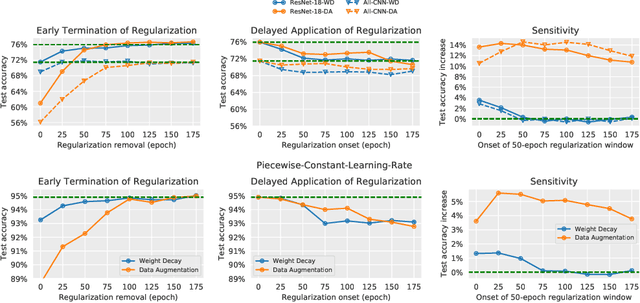
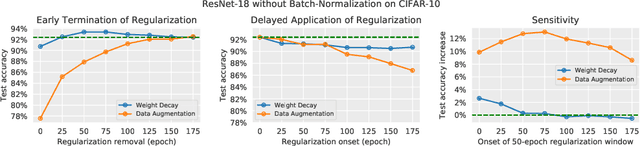
Regularization is typically understood as improving generalization by altering the landscape of local extrema to which the model eventually converges. Deep neural networks (DNNs), however, challenge this view: We show that removing regularization after an initial transient period has little effect on generalization, even if the final loss landscape is the same as if there had been no regularization. In some cases, generalization even improves after interrupting regularization. Conversely, if regularization is applied only after the initial transient, it has no effect on the final solution, whose generalization gap is as bad as if regularization never happened. This suggests that what matters for training deep networks is not just whether or how, but when to regularize. The phenomena we observe are manifest in different datasets (CIFAR-10, CIFAR-100), different architectures (ResNet-18, All-CNN), different regularization methods (weight decay, data augmentation), different learning rate schedules (exponential, piece-wise constant). They collectively suggest that there is a ``critical period'' for regularizing deep networks that is decisive of the final performance. More analysis should, therefore, focus on the transient rather than asymptotic behavior of learning.
Sparse Kernel PCA for Outlier Detection
Sep 13, 2018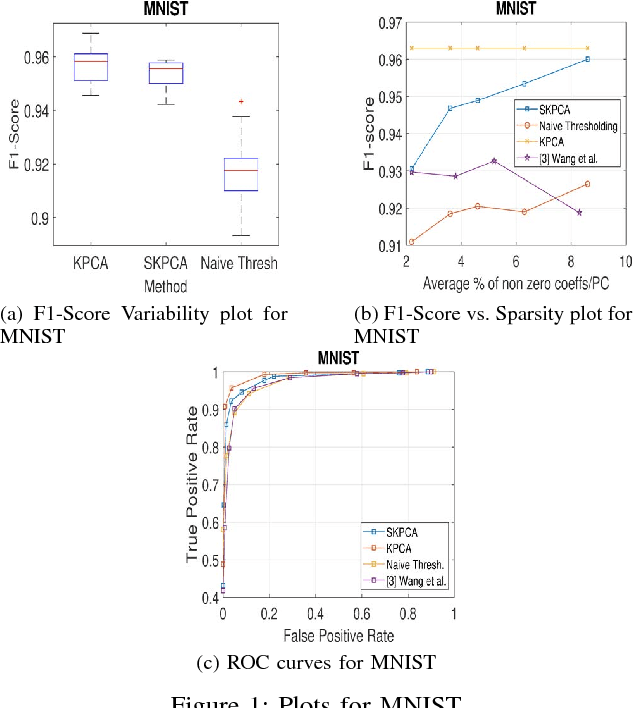
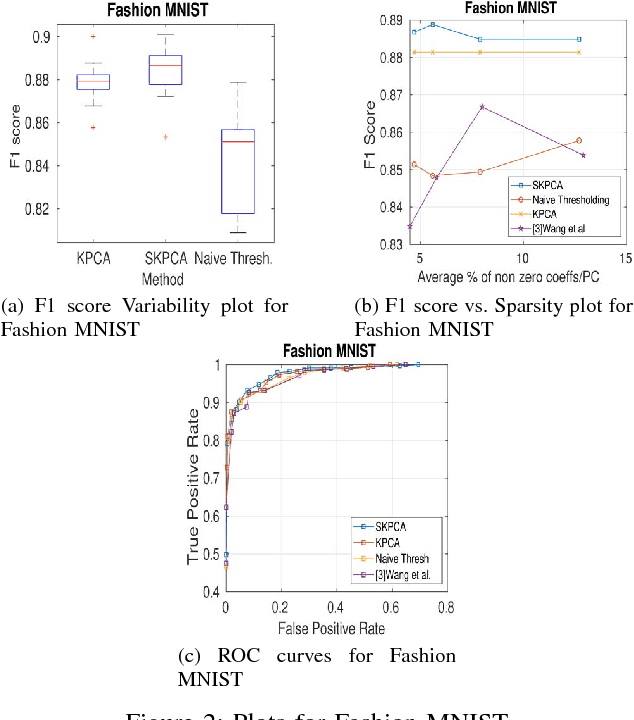
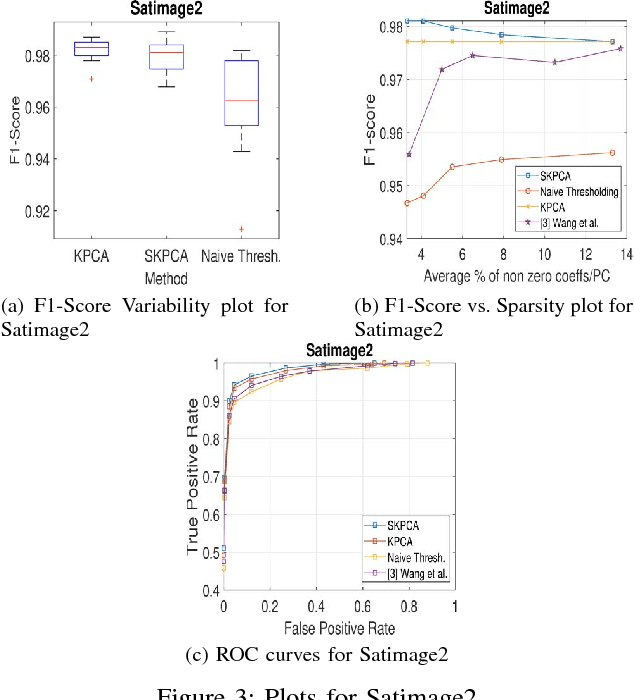
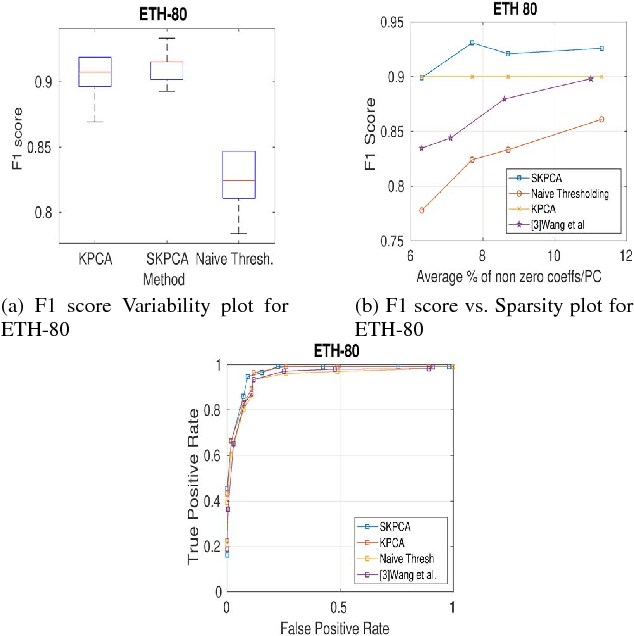
In this paper, we propose a new method to perform Sparse Kernel Principal Component Analysis (SKPCA) and also mathematically analyze the validity of SKPCA. We formulate SKPCA as a constrained optimization problem with elastic net regularization (Hastie et al.) in kernel feature space and solve it. We consider outlier detection (where KPCA is employed) as an application for SKPCA, using the RBF kernel. We test it on 5 real-world datasets and show that by using just 4% (or even less) of the principal components (PCs), where each PC has on average less than 12% non-zero elements in the worst case among all 5 datasets, we are able to nearly match and in 3 datasets even outperform KPCA. We also compare the performance of our method with a recently proposed method for SKPCA by Wang et al. and show that our method performs better in terms of both accuracy and sparsity. We also provide a novel probabilistic proof to justify the existence of sparse solutions for KPCA using the RBF kernel. To the best of our knowledge, this is the first attempt at theoretically analyzing the validity of SKPCA.
Classification of Breast Cancer Histology using Deep Learning
Jul 25, 2018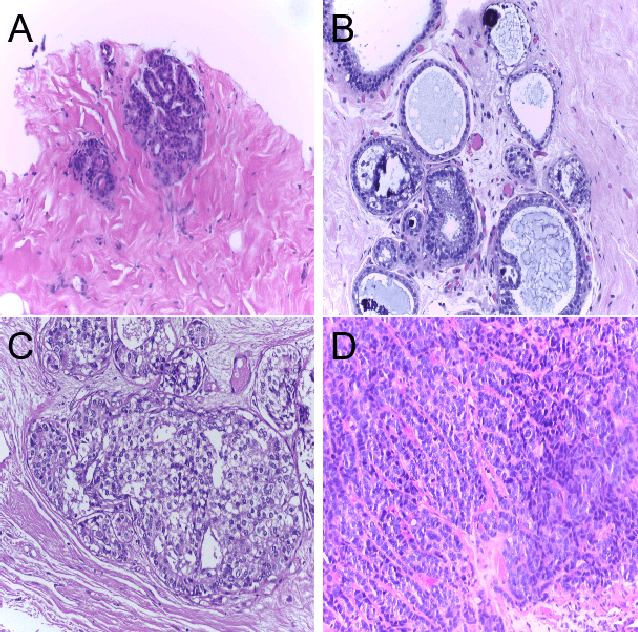

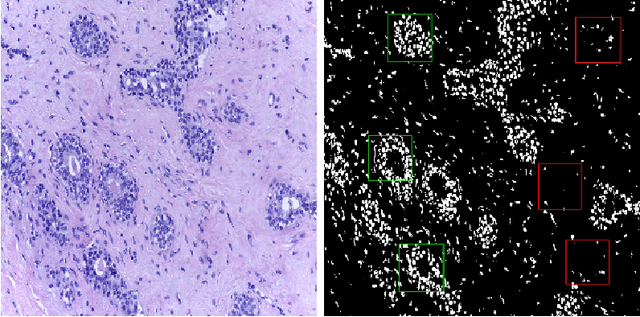
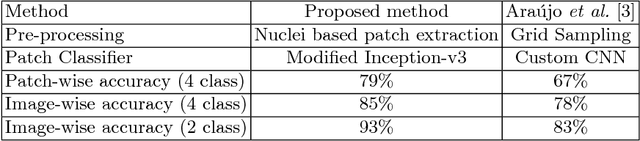
Breast Cancer is a major cause of death worldwide among women. Hematoxylin and Eosin (H&E) stained breast tissue samples from biopsies are observed under microscopes for the primary diagnosis of breast cancer. In this paper, we propose a deep learning-based method for classification of H&E stained breast tissue images released for BACH challenge 2018 by fine-tuning Inception-v3 convolutional neural network (CNN) proposed by Szegedy et al. These images are to be classified into four classes namely, i) normal tissue, ii) benign tumor, iii) in-situ carcinoma and iv) invasive carcinoma. Our strategy is to extract patches based on nuclei density instead of random or grid sampling, along with rejection of patches that are not rich in nuclei (non-epithelial) regions for training and testing. Every patch (nuclei-dense region) in an image is classified in one of the four above mentioned categories. The class of the entire image is determined using majority voting over the nuclear classes. We obtained an average four class accuracy of 85% and an average two class (non-cancer vs. carcinoma) accuracy of 93%, which improves upon a previous benchmark by Araujo et al.