 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Poisoning in Reinforcement Learning: Attacks Against Unknown Learners in Unknown Environments
Feb 16, 2021We study black-box reward poisoning attacks against reinforcement learning (RL), in which an adversary aims to manipulate the rewards to mislead a sequence of RL agents with unknown algorithms to learn a nefarious policy in an environment unknown to the adversary a priori. That is, our attack makes minimum assumptions on the prior knowledge of the adversary: it has no initial knowledge of the environment or the learner, and neither does it observe the learner's internal mechanism except for its performed actions. We design a novel black-box attack, U2, that can provably achieve a near-matching performance to the state-of-the-art white-box attack, demonstrating the feasibility of reward poisoning even in the most challenging black-box setting.
Defense Against Reward Poisoning Attacks in Reinforcement Learning
Feb 10, 2021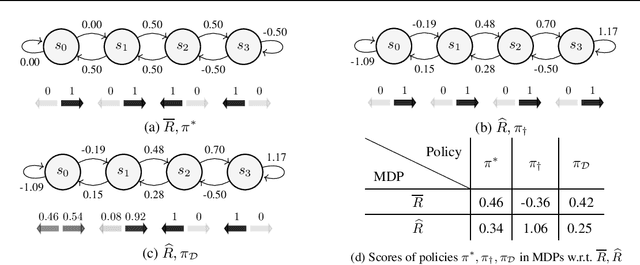
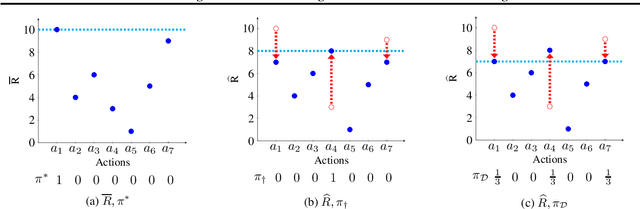
We study defense strategies against reward poisoning attacks in reinforcement learning. As a threat model, we consider attacks that minimally alter rewards to make the attacker's target policy uniquely optimal under the poisoned rewards, with the optimality gap specified by an attack parameter. Our goal is to design agents that are robust against such attacks in terms of the worst-case utility w.r.t. the true, unpoisoned, rewards while computing their policies under the poisoned rewards. We propose an optimization framework for deriving optimal defense policies, both when the attack parameter is known and unknown. Moreover, we show that defense policies that are solutions to the proposed optimization problems have provable performance guarantees. In particular, we provide the following bounds with respect to the true, unpoisoned, rewards: a) lower bounds on the expected return of the defense policies, and b) upper bounds on how suboptimal these defense policies are compared to the attacker's target policy. We conclude the paper by illustrating the intuitions behind our formal results, and showing that the derived bounds are non-trivial.
Policy Teaching in Reinforcement Learning via Environment Poisoning Attacks
Nov 21, 2020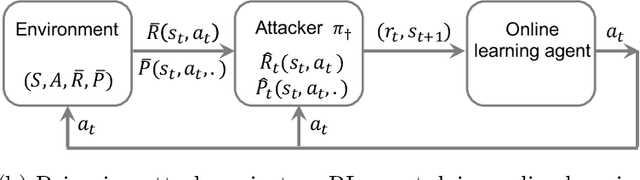
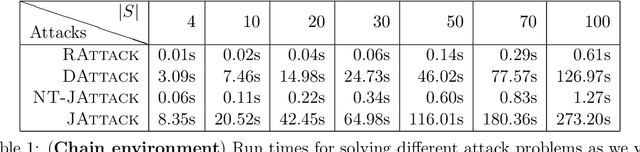
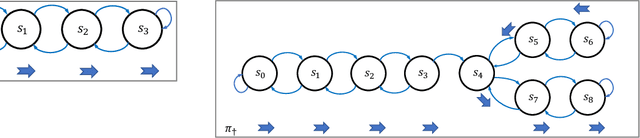
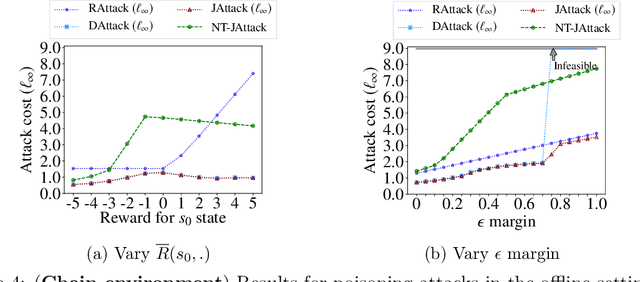
We study a security threat to reinforcement learning where an attacker poisons the learning environment to force the agent into executing a target policy chosen by the attacker. As a victim, we consider RL agents whose objective is to find a policy that maximizes reward in infinite-horizon problem settings. The attacker can manipulate the rewards and the transition dynamics in the learning environment at training-time, and is interested in doing so in a stealthy manner. We propose an optimization framework for finding an optimal stealthy attack for different measures of attack cost. We provide lower/upper bounds on the attack cost, and instantiate our attacks in two settings: (i) an offline setting where the agent is doing planning in the poisoned environment, and (ii) an online setting where the agent is learning a policy with poisoned feedback. Our results show that the attacker can easily succeed in teaching any target policy to the victim under mild conditions and highlight a significant security threat to reinforcement learning agents in practice.
The Teaching Dimension of Kernel Perceptron
Oct 27, 2020
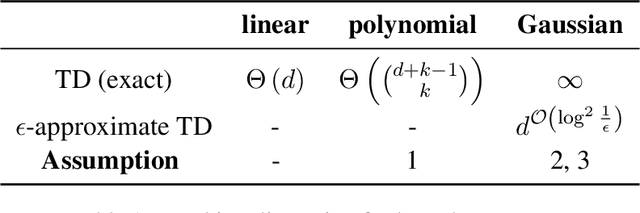
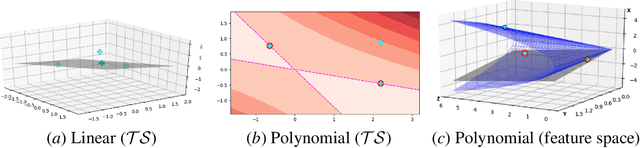
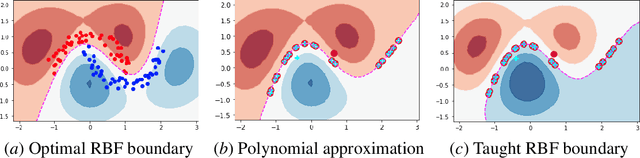
Algorithmic machine teaching has been studied under the linear setting where exact teaching is possible. However, little is known for teaching nonlinear learners. Here, we establish the sample complexity of teaching, aka teaching dimension, for kernelized perceptrons for different families of feature maps. As a warm-up, we show that the teaching complexity is $\Theta(d)$ for the exact teaching of linear perceptrons in $\mathbb{R}^d$, and $\Theta(d^k)$ for kernel perceptron with a polynomial kernel of order $k$. Furthermore, under certain smooth assumptions on the data distribution, we establish a rigorous bound on the complexity for approximately teaching a Gaussian kernel perceptron. We provide numerical examples of the optimal (approximate) teaching set under several canonical settings for linear, polynomial and Gaussian kernel perceptrons.
Preference-Based Batch and Sequential Teaching
Oct 17, 2020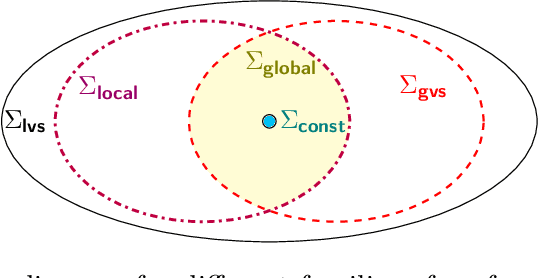
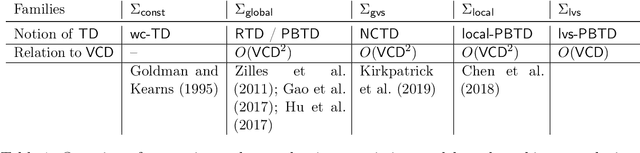
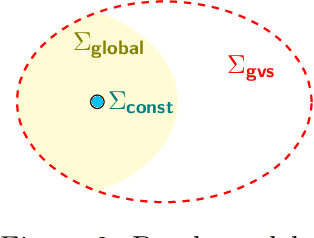

Algorithmic machine teaching studies the interaction between a teacher and a learner where the teacher selects labeled examples aiming at teaching a target hypothesis. In a quest to lower teaching complexity, several teaching models and complexity measures have been proposed for both the batch settings (e.g., worst-case, recursive, preference-based, and non-clashing models) and the sequential settings (e.g., local preference-based model). To better understand the connections between these models, we develop a novel framework that captures the teaching process via preference functions $\Sigma$. In our framework, each function $\sigma \in \Sigma$ induces a teacher-learner pair with teaching complexity as $TD(\sigma)$. We show that the above-mentioned teaching models are equivalent to specific types/families of preference functions. We analyze several properties of the teaching complexity parameter $TD(\sigma)$ associated with different families of the preference functions, e.g., comparison to the VC dimension of the hypothesis class and additivity/sub-additivity of $TD(\sigma)$ over disjoint domains. Finally, we identify preference functions inducing a novel family of sequential models with teaching complexity linear in the VC dimension: this is in contrast to the best-known complexity result for the batch models, which is quadratic in the VC dimension.
Synthesizing Tasks for Block-based Programming
Jul 01, 2020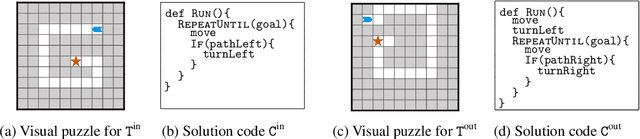
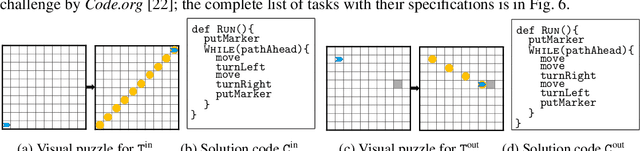

Block-based visual programming environments play a critical role in introducing computing concepts to K-12 students. One of the key pedagogical challenges in these environments is in designing new practice tasks for a student that match a desired level of difficulty and exercise specific programming concepts. In this paper, we formalize the problem of synthesizing visual programming tasks. In particular, given a reference visual task $\rm T^{in}$ and its solution code $\rm C^{in}$, we propose a novel methodology to automatically generate a set $\{(\rm T^{out}, \rm C^{out})\}$ of new tasks along with solution codes such that tasks $\rm T^{in}$ and $\rm T^{out}$ are conceptually similar but visually dissimilar. Our methodology is based on the realization that the mapping from the space of visual tasks to their solution codes is highly discontinuous; hence, directly mutating reference task $\rm T^{in}$ to generate new tasks is futile. Our task synthesis algorithm operates by first mutating code $\rm C^{in}$ to obtain a set of codes $\{\rm C^{out}\}$. Then, the algorithm performs symbolic execution over a code $\rm C^{out}$ to obtain a visual task $\rm T^{out}$; this step uses the Monte Carlo Tree Search (MCTS) procedure to guide the search in the symbolic tree. We demonstrate the effectiveness of our algorithm through an extensive empirical evaluation and user study on reference tasks taken from the \emph{Hour of the Code: Classic Maze} challenge by \emph{Code.org} and the \emph{Intro to Programming with Karel} course by \emph{CodeHS.com}.
Average-case Complexity of Teaching Convex Polytopes via Halfspace Queries
Jun 25, 2020

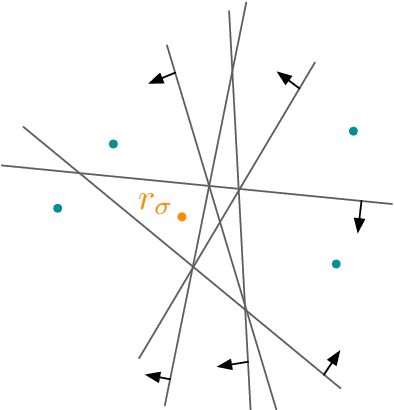
We examine the task of locating a target region among those induced by intersections of $n$ halfspaces in $\mathbb{R}^d$. This generic task connects to fundamental machine learning problems, such as training a perceptron and learning a $\phi$-separable dichotomy. We investigate the average teaching complexity of the task, i.e., the minimal number of samples (halfspace queries) required by a teacher to help a version-space learner in locating a randomly selected target. As our main result, we show that the average-case teaching complexity is $\Theta(d)$, which is in sharp contrast to the worst-case teaching complexity of $\Theta(n)$. If instead, we consider the average-case learning complexity, the bounds have a dependency on $n$ as $\Theta(n)$ for i.i.d. queries and $\Theta(d \log(n))$ for actively chosen queries by the learner. Our proof techniques are based on novel insights from computational geometry, which allow us to count the number of convex polytopes and faces in a Euclidean space depending on the arrangement of halfspaces. Our insights allow us to establish a tight bound on the average-case complexity for $\phi$-separable dichotomies, which generalizes the known $\mathcal{O}(d)$ bound on the average number of "extreme patterns" in the classical computational geometry literature (Cover, 1965).
Environment Shaping in Reinforcement Learning using State Abstraction
Jun 23, 2020
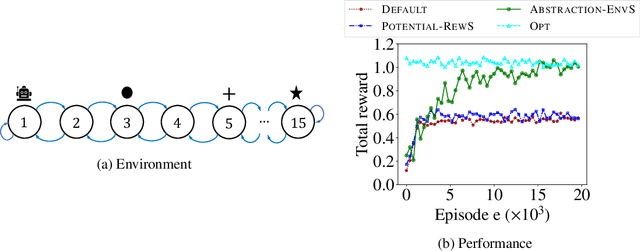
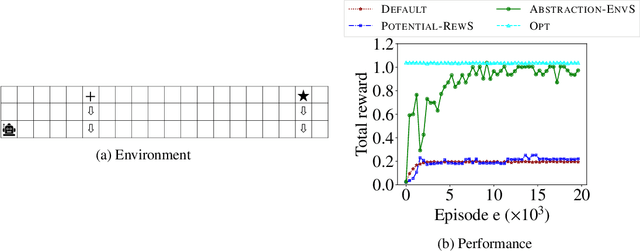
One of the central challenges faced by a reinforcement learning (RL) agent is to effectively learn a (near-)optimal policy in environments with large state spaces having sparse and noisy feedback signals. In real-world applications, an expert with additional domain knowledge can help in speeding up the learning process via \emph{shaping the environment}, i.e., making the environment more learner-friendly. A popular paradigm in literature is \emph{potential-based reward shaping}, where the environment's reward function is augmented with additional local rewards using a potential function. However, the applicability of potential-based reward shaping is limited in settings where (i) the state space is very large, and it is challenging to compute an appropriate potential function, (ii) the feedback signals are noisy, and even with shaped rewards the agent could be trapped in local optima, and (iii) changing the rewards alone is not sufficient, and effective shaping requires changing the dynamics. We address these limitations of potential-based shaping methods and propose a novel framework of \emph{environment shaping using state abstraction}. Our key idea is to compress the environment's large state space with noisy signals to an abstracted space, and to use this abstraction in creating smoother and more effective feedback signals for the agent. We study the theoretical underpinnings of our abstraction-based environment shaping, and show that the agent's policy learnt in the shaped environment preserves near-optimal behavior in the original environment.
Task-agnostic Exploration in Reinforcement Learning
Jun 16, 2020
Efficient exploration is one of the main challenges in reinforcement learning (RL). Most existing sample-efficient algorithms assume the existence of a single reward function during exploration. In many practical scenarios, however, there is not a single underlying reward function to guide the exploration, for instance, when an agent needs to learn many skills simultaneously, or multiple conflicting objectives need to be balanced. To address these challenges, we propose the \textit{task-agnostic RL} framework: In the exploration phase, the agent first collects trajectories by exploring the MDP without the guidance of a reward function. After exploration, it aims at finding near-optimal policies for $N$ tasks, given the collected trajectories augmented with \textit{sampled rewards} for each task. We present an efficient task-agnostic RL algorithm, \textsc{UCBZero}, that finds $\epsilon$-optimal policies for $N$ arbitrary tasks after at most $\tilde O(\log(N)H^5SA/\epsilon^2)$ exploration episodes. We also provide an $\Omega(\log (N)H^2SA/\epsilon^2)$ lower bound, showing that the $\log$ dependency on $N$ is unavoidable. Furthermore, we provide an $N$-independent sample complexity bound of \textsc{UCBZero} in the statistically easier setting when the ground truth reward functions are known.
The Teaching Dimension of Q-learning
Jun 16, 2020
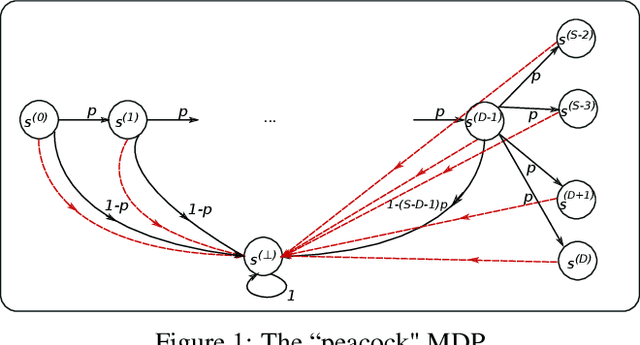
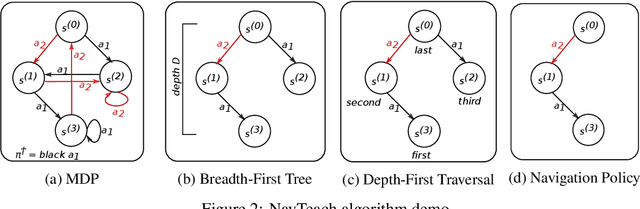
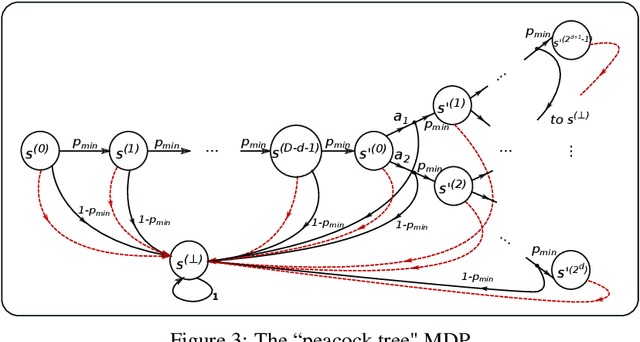
In this paper, we initiate the study of sample complexity of teaching, termed as "teaching dimension" (TDim) in the literature, for Q-learning. While the teaching dimension of supervised learning has been studied extensively, these results do not extend to reinforcement learning due to the temporal constraints posed by the underlying Markov Decision Process environment. We characterize the TDim of Q-learning under different teachers with varying control over the environment, and present matching optimal teaching algorithms. Our TDim results provide the minimum number of samples needed for reinforcement learning, thus complementing standard PAC-style RL sample complexity analysis. Our teaching algorithms have the potential to speed up RL agent learning in applications where a helpful teacher is available.