 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAVA: Hybrid Approach to Value-Alignment through Reward Weighing for Reinforcement Learning
May 21, 2025Our society is governed by a set of norms which together bring about the values we cherish such as safety, fairness or trustworthiness. The goal of value-alignment is to create agents that not only do their tasks but through their behaviours also promote these values. Many of the norms are written as laws or rules (legal / safety norms) but even more remain unwritten (social norms). Furthermore, the techniques used to represent these norms also differ. Safety / legal norms are often represented explicitly, for example, in some logical language while social norms are typically learned and remain hidden in the parameter space of a neural network. There is a lack of approaches in the literature that could combine these various norm representations into a single algorithm. We propose a novel method that integrates these norms into the reinforcement learning process. Our method monitors the agent's compliance with the given norms and summarizes it in a quantity we call the agent's reputation. This quantity is used to weigh the received rewards to motivate the agent to become value-aligned. We carry out a series of experiments including a continuous state space traffic problem to demonstrate the importance of the written and unwritten norms and show how our method can find the value-aligned policies. Furthermore, we carry out ablations to demonstrate why it is better to combine these two groups of norms rather than using either separately.
CHIRPs: Change-Induced Regret Proxy metrics for Lifelong Reinforcement Learning
Sep 05, 2024Reinforcement learning agents can achieve superhuman performance in static tasks but are costly to train and fragile to task changes. This limits their deployment in real-world scenarios where training experience is expensive or the context changes through factors like sensor degradation, environmental processes or changing mission priorities. Lifelong reinforcement learning aims to improve sample efficiency and adaptability by studying how agents perform in evolving problems. The difficulty that these changes pose to an agent is rarely measured directly, however. Agent performances can be compared across a change, but this is often prohibitively expensive. We propose Change-Induced Regret Proxy (CHIRP) metrics, a class of metrics for approximating a change's difficulty while avoiding the high costs of using trained agents. A relationship between a CHIRP metric and agent performance is identified in two environments, a simple grid world and MetaWorld's suite of robotic arm tasks. We demonstrate two uses for these metrics: for learning, an agent that clusters MDPs based on a CHIRP metric achieves $17\%$ higher average returns than three existing agents in a sequence of MetaWorld tasks. We also show how a CHIRP can be calibrated to compare the difficulty of changes across distinctly different environments.
From Intelligent Agents to Trustworthy Human-Centred Multiagent Systems
Oct 05, 2022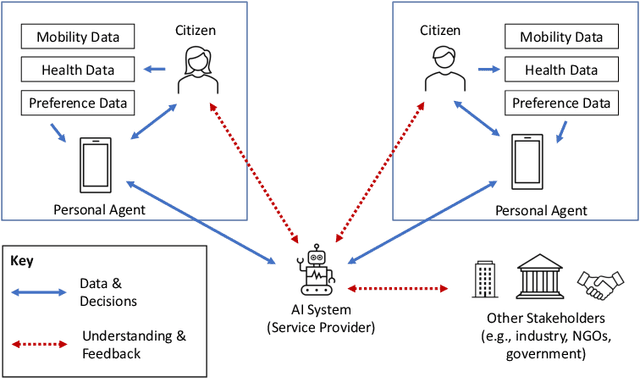
The Agents, Interaction and Complexity research group at the University of Southampton has a long track record of research in multiagent systems (MAS). We have made substantial scientific contributions across learning in MAS, game-theoretic techniques for coordinating agent systems, and formal methods for representation and reasoning. We highlight key results achieved by the group and elaborate on recent work and open research challenges in developing trustworthy autonomous systems and deploying human-centred AI systems that aim to support societal good.
* Appears in the Special Issue on Multi-Agent Systems Research in the United Kingdom