 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Distributed Common Operational Picture from Heterogeneous Platforms using Multi-Agent Reinforcement Learning
Nov 08, 2024



The integration of unmanned platforms equipped with advanced sensors promises to enhance situational awareness and mitigate the "fog of war" in military operations. However, managing the vast influx of data from these platforms poses a significant challenge for Command and Control (C2) systems. This study presents a novel multi-agent learning framework to address this challenge. Our method enables autonomous and secure communication between agents and humans, which in turn enables real-time formation of an interpretable Common Operational Picture (COP). Each agent encodes its perceptions and actions into compact vectors, which are then transmitted, received and decoded to form a COP encompassing the current state of all agents (friendly and enemy) on the battlefield. Using Deep Reinforcement Learning (DRL), we jointly train COP models and agent's action selection policies. We demonstrate resilience to degraded conditions such as denied GPS and disrupted communications. Experimental validation is performed in the Starcraft-2 simulation environment to evaluate the precision of the COPs and robustness of policies. We report less than 5% error in COPs and policies resilient to various adversarial conditions. In summary, our contributions include a method for autonomous COP formation, increased resilience through distributed prediction, and joint training of COP models and multi-agent RL policies. This research advances adaptive and resilient C2, facilitating effective control of heterogeneous unmanned platforms.
Towards Linguistically-Aware and Language-Independent Tokenization for Large Language Models (LLMs)
Oct 04, 2024This paper presents a comprehensive study on the tokenization techniques employed by state-of-the-art large language models (LLMs) and their implications on the cost and availability of services across different languages, especially low resource languages. The analysis considers multiple LLMs, including GPT-4 (using cl100k_base embeddings), GPT-3 (with p50k_base embeddings), and DaVinci (employing r50k_base embeddings), as well as the widely used BERT base tokenizer. The study evaluates the tokenization variability observed across these models and investigates the challenges of linguistic representation in subword tokenization. The research underscores the importance of fostering linguistically-aware development practices, especially for languages that are traditionally under-resourced. Moreover, this paper introduces case studies that highlight the real-world implications of tokenization choices, particularly in the context of electronic health record (EHR) systems. This research aims to promote generalizable Internationalization (I18N) practices in the development of AI services in this domain and beyond, with a strong emphasis on inclusivity, particularly for languages traditionally underrepresented in AI applications.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023



Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
Model-Free Generative Replay for Lifelong Reinforcement Learning: Application to Starcraft-2
Aug 16, 2022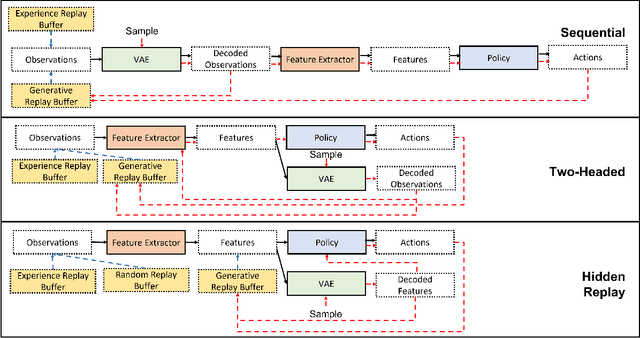

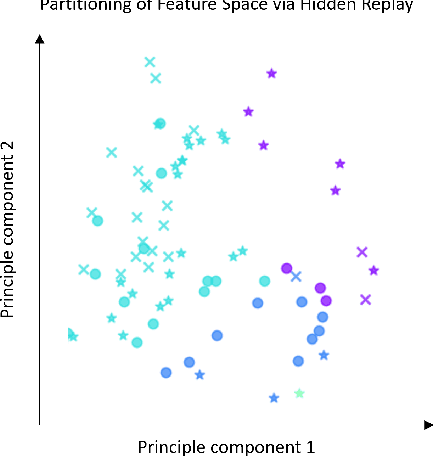

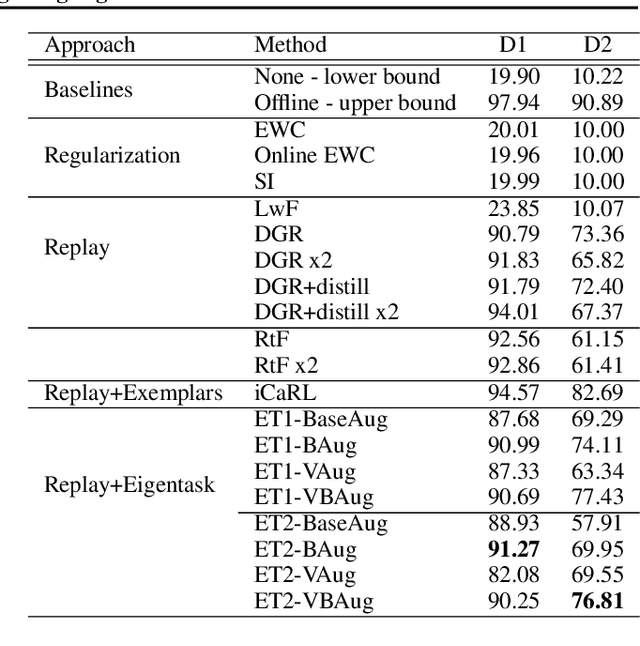
One approach to meet the challenges of deep lifelong reinforcement learning (LRL) is careful management of the agent's learning experiences, to learn (without forgetting) and build internal meta-models (of the tasks, environments, agents, and world). Generative replay (GR) is a biologically inspired replay mechanism that augments learning experiences with self-labelled examples drawn from an internal generative model that is updated over time. We present a version of GR for LRL that satisfies two desiderata: (a) Introspective density modelling of the latent representations of policies learned using deep RL, and (b) Model-free end-to-end learning. In this paper, we study three deep learning architectures for model-free GR, starting from a na\"ive GR and adding ingredients to achieve (a) and (b). We evaluate our proposed algorithms on three different scenarios comprising tasks from the Starcraft-2 and Minigrid domains. We report several key findings showing the impact of the design choices on quantitative metrics that include transfer learning, generalization to unseen tasks, fast adaptation after task change, performance wrt task expert, and catastrophic forgetting. We observe that our GR prevents drift in the features-to-action mapping from the latent vector space of a deep RL agent. We also show improvements in established lifelong learning metrics. We find that a small random replay buffer significantly increases the stability of training. Overall, we find that "hidden replay" (a well-known architecture for class-incremental classification) is the most promising approach that pushes the state-of-the-art in GR for LRL and observe that the architecture of the sleep model might be more important for improving performance than the types of replay used. Our experiments required only 6% of training samples to achieve 80-90% of expert performance in most Starcraft-2 scenarios.
Lifelong Learning using Eigentasks: Task Separation, Skill Acquisition, and Selective Transfer
Jul 14, 2020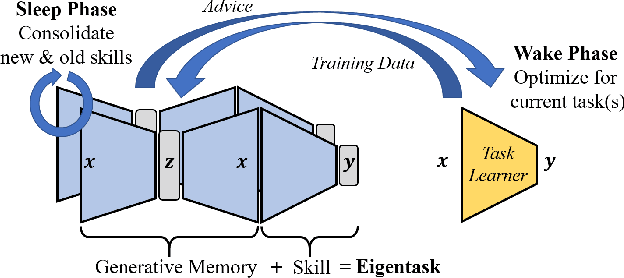
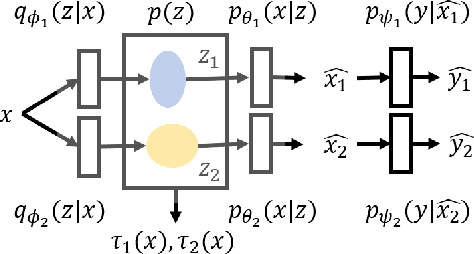

We introduce the eigentask framework for lifelong learning. An eigentask is a pairing of a skill that solves a set of related tasks, paired with a generative model that can sample from the skill's input space. The framework extends generative replay approaches, which have mainly been used to avoid catastrophic forgetting, to also address other lifelong learning goals such as forward knowledge transfer. We propose a wake-sleep cycle of alternating task learning and knowledge consolidation for learning in our framework, and instantiate it for lifelong supervised learning and lifelong RL. We achieve improved performance over the state-of-the-art in supervised continual learning, and show evidence of forward knowledge transfer in a lifelong RL application in the game Starcraft2.