 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Permutation Guided Node Representations for Link Prediction
Dec 13, 2020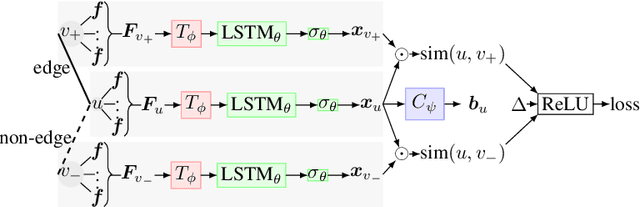
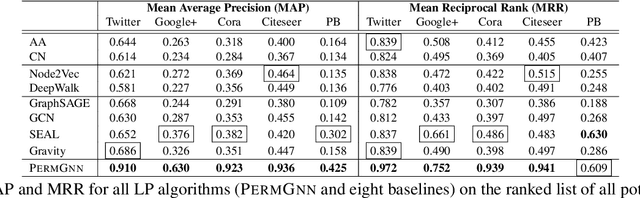
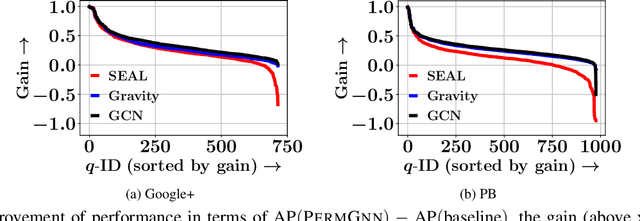

After observing a snapshot of a social network, a link prediction (LP) algorithm identifies node pairs between which new edges will likely materialize in future. Most LP algorithms estimate a score for currently non-neighboring node pairs, and rank them by this score. Recent LP systems compute this score by comparing dense, low dimensional vector representations of nodes. Graph neural networks (GNNs), in particular graph convolutional networks (GCNs), are popular examples. For two nodes to be meaningfully compared, their embeddings should be indifferent to reordering of their neighbors. GNNs typically use simple, symmetric set aggregators to ensure this property, but this design decision has been shown to produce representations with limited expressive power. Sequence encoders are more expressive, but are permutation sensitive by design. Recent efforts to overcome this dilemma turn out to be unsatisfactory for LP tasks. In response, we propose PermGNN, which aggregates neighbor features using a recurrent, order-sensitive aggregator and directly minimizes an LP loss while it is `attacked' by adversarial generator of neighbor permutations. By design, PermGNN{} has more expressive power compared to earlier symmetric aggregators. Next, we devise an optimization framework to map PermGNN's node embeddings to a suitable locality-sensitive hash, which speeds up reporting the top-$K$ most likely edges for the LP task. Our experiments on diverse datasets show that \our outperforms several state-of-the-art link predictors by a significant margin, and can predict the most likely edges fast.
Classification Under Human Assistance
Jun 21, 2020
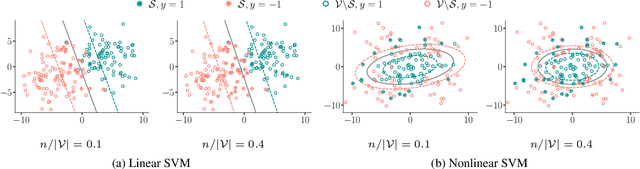
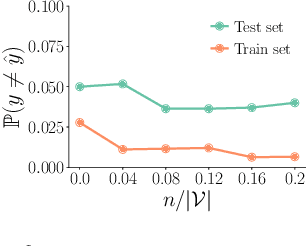
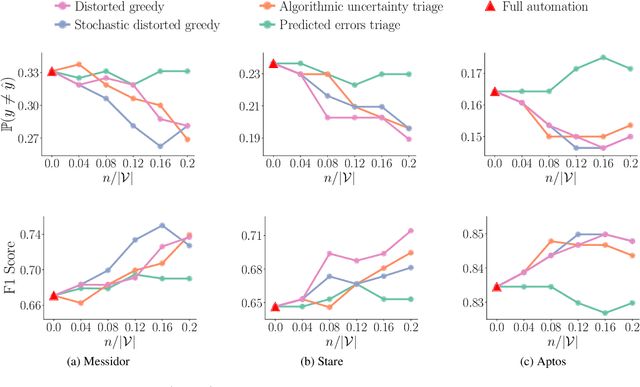
Most supervised learning models are trained for full automation. However, their predictions are sometimes worse than those by human experts on some specific instances. Motivated by this empirical observation, our goal is to design classifiers that are optimized to operate under different automation levels. More specifically, we focus on convex margin-based classifiers and first show that the problem is NP-hard. Then, we further show that, for support vector machines, the corresponding objective function can be expressed as the difference of two functions f = g - c, where g is monotone, non-negative and {\gamma}-weakly submodular, and c is non-negative and modular. This representation allows a recently introduced deterministic greedy algorithm, as well as a more efficient randomized variant of the algorithm, to enjoy approximation guarantees at solving the problem. Experiments on synthetic and real-world data from several applications in medical diagnosis illustrate our theoretical findings and demonstrate that, under human assistance, supervised learning models trained to operate under different automation levels can outperform those trained for full automation as well as humans operating alone.
Learning to Switch Between Machines and Humans
Feb 11, 2020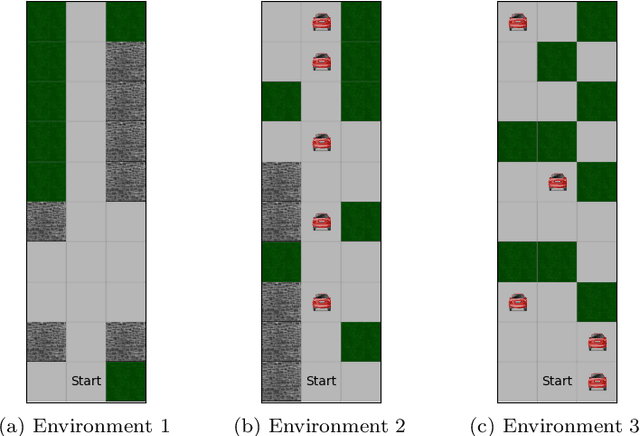
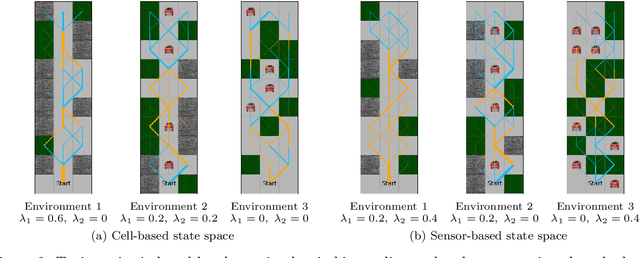
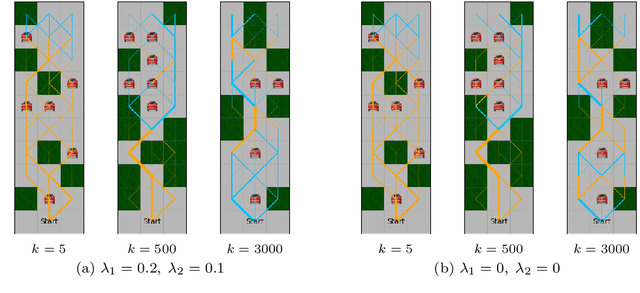
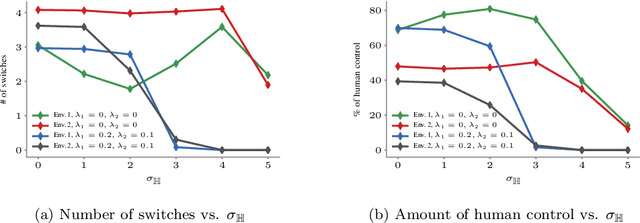
Reinforcement learning algorithms have been mostly developed and evaluated under the assumption that they will operate in a fully autonomous manner---they will take all actions. However, in safety critical applications, full autonomy faces a variety of technical, societal and legal challenges, which have precluded the use of reinforcement learning policies in real-world systems. In this work, our goal is to develop algorithms that, by learning to switch control between machines and humans, allow existing reinforcement learning policies to operate under different automation levels. More specifically, we first formally define the learning to switch problem using finite horizon Markov decision processes. Then, we show that, if the human policy is known, we can find the optimal switching policy directly by solving a set of recursive equations using backwards induction. However, in practice, the human policy is often unknown. To overcome this, we develop an algorithm that uses upper confidence bounds on the human policy to find a sequence of switching policies whose total regret with respect to the optimal switching policy is sublinear. Simulation experiments on two important tasks in autonomous driving---lane keeping and obstacle avoidance---demonstrate the effectiveness of the proposed algorithms and illustrate our theoretical findings.
Can A User Anticipate What Her Followers Want?
Sep 19, 2019
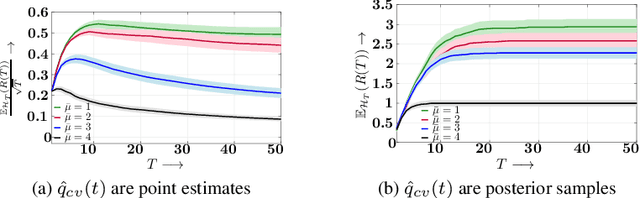
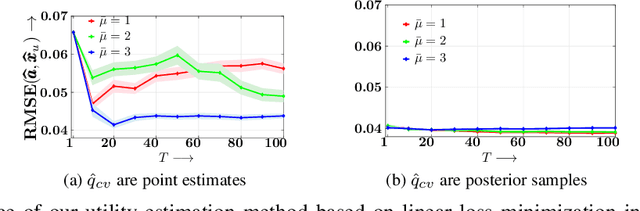
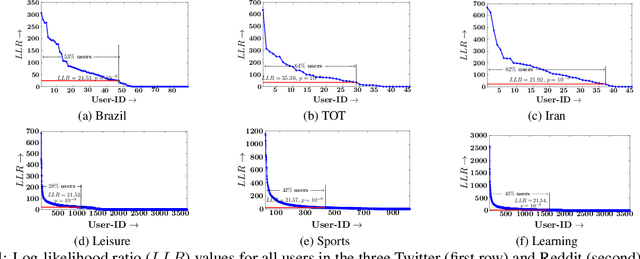
Whenever a social media user decides to share a story, she is typically pleased to receive likes, comments, shares, or, more generally, feedback from her followers. As a result, she may feel compelled to use the feedback she receives to (re-)estimate her followers' preferences and decides which stories to share next to receive more (positive) feedback. Under which conditions can she succeed? In this work, we first look into this problem from a theoretical perspective and then provide a set of practical algorithms to identify and characterize such behavior in social media. More specifically, we address the above problem from the viewpoint of sequential decision making and utility maximization. For a wide variety of utility functions, we first show that, to succeed, a user needs to actively trade off exploitation-- sharing stories which lead to more (positive) feedback--and exploration-- sharing stories to learn about her followers' preferences. However, exploration is not necessary if a user utilizes the feedback her followers provide to other users in addition to the feedback she receives. Then, we develop a utility estimation framework for observation data, which relies on statistical hypothesis testing to determine whether a user utilizes the feedback she receives from each of her followers to decide what to post next. Experiments on synthetic data illustrate our theoretical findings and show that our estimation framework is able to accurately recover users' underlying utility functions. Experiments on several real datasets gathered from Twitter and Reddit reveal that up to 82% (43%) of the Twitter (Reddit) users in our datasets do use the feedback they receive to decide what to post next.
Regression Under Human Assistance
Sep 18, 2019
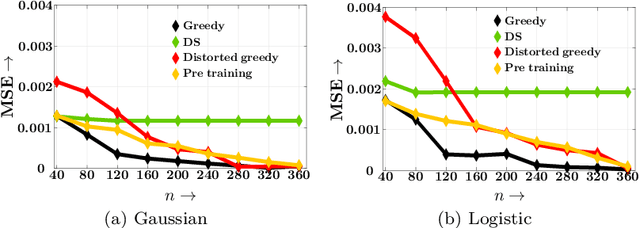
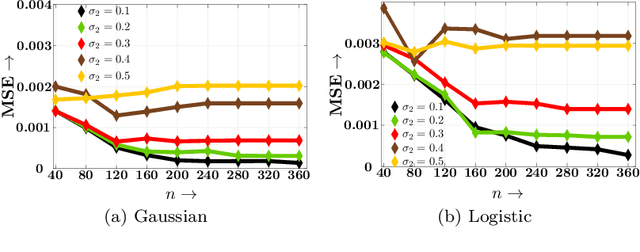
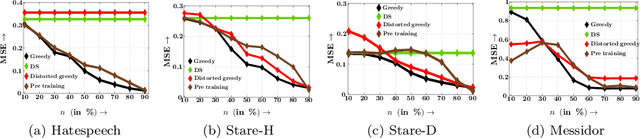
Decisions are increasingly taken by both humans and machine learning models. However, machine learning models are currently trained for full automation-they are not aware that some of the decisions may still be taken by humans. In this paper, we take a first step towards making machine learning models aware of the presence of human decision-makers. More specifically, we first introduce the problem of ridge regression under human assistance and show that it is NP-hard. Then, we derive an alternative representation of the corresponding objective function as a difference of nondecreasing submodular functions. Building on this representation, we further show that the objective is nondecreasing and satisfies \xi-submodularity, a recently introduced notion of approximate submodularity. These properties allow simple and efficient greedy algorithm to enjoy approximation guarantees at solving the problem. Experiments on synthetic and real-world data from two important applications-medical diagnoses and content moderation-demonstrate that the greedy algorithm beats several competitive baselines.
Privacy Preserving Link Prediction with Latent Geometric Network Models
Jul 20, 2019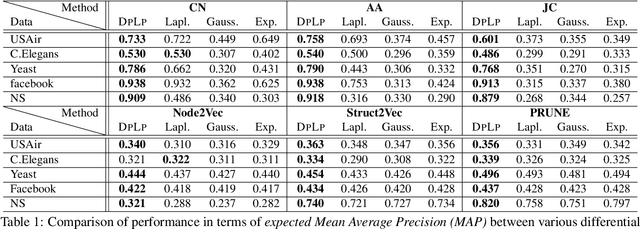
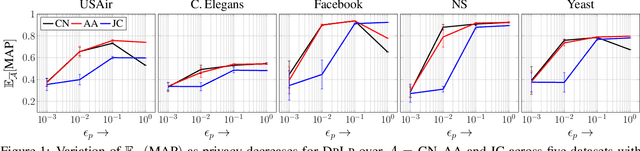
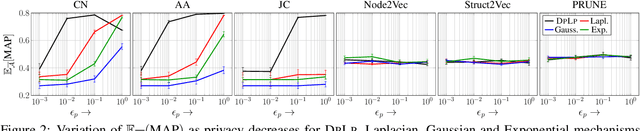
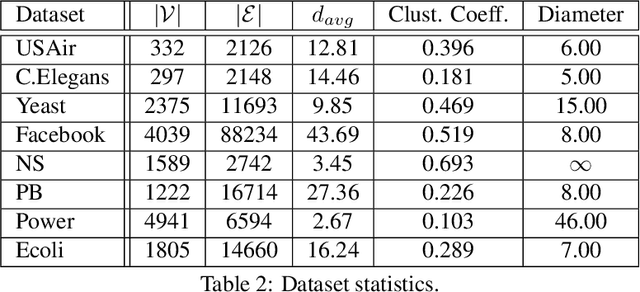
Link prediction is an important task in social network analysis, with a wide variety of applications ranging from graph search to recommendation. The usual paradigm is to propose to each node a ranked list of nodes that are currently non-neighbors, as the most likely candidates for future linkage. Owing to increasing concerns about privacy, users (nodes) may prefer to keep some or all their connections private. Most link prediction heuristics, such as common neighbor, Jaccard coefficient, and Adamic-Adar, can leak private link information in making predictions. We present D P L P , a generic framework to protect differential privacy for these popular heuristics under the ranking objective. Under a recently-introduced latent node embedding model, we also analyze the trade-off between privacy and link prediction utility. Extensive experiments with eight diverse real-life graphs and several link prediction heuristics show that D P L P can trade off between privacy and predictive performance more effectively than several alternatives.
Consequential Ranking Algorithms and Long-term Welfare
May 13, 2019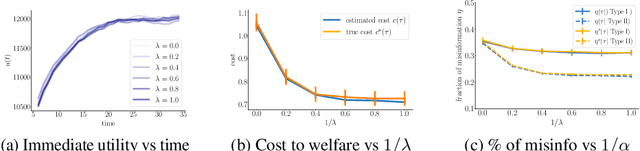

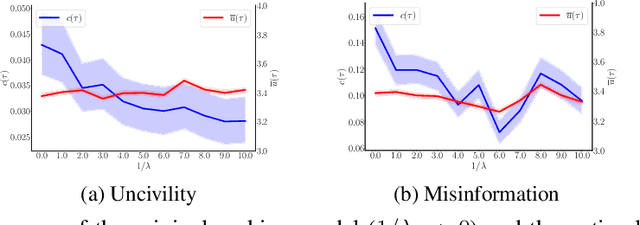

Ranking models are typically designed to provide rankings that optimize some measure of immediate utility to the users. As a result, they have been unable to anticipate an increasing number of undesirable long-term consequences of their proposed rankings, from fueling the spread of misinformation and increasing polarization to degrading social discourse. Can we design ranking models that understand the consequences of their proposed rankings and, more importantly, are able to avoid the undesirable ones? In this paper, we first introduce a joint representation of rankings and user dynamics using Markov decision processes. Then, we show that this representation greatly simplifies the construction of consequential ranking models that trade off the immediate utility and the long-term welfare. In particular, we can obtain optimal consequential rankings just by applying weighted sampling on the rankings provided by models that maximize measures of immediate utility. However, in practice, such a strategy may be inefficient and impractical, specially in high dimensional scenarios. To overcome this, we introduce an efficient gradient-based algorithm to learn parameterized consequential ranking models that effectively approximate optimal ones. We showcase our methodology using synthetic and real data gathered from Reddit and show that ranking models derived using our methodology provide ranks that may mitigate the spread of misinformation and improve the civility of online discussions.
Deep Reinforcement Learning of Marked Temporal Point Processes
Nov 06, 2018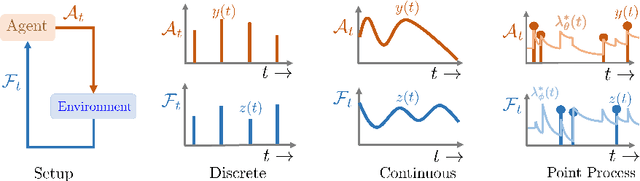

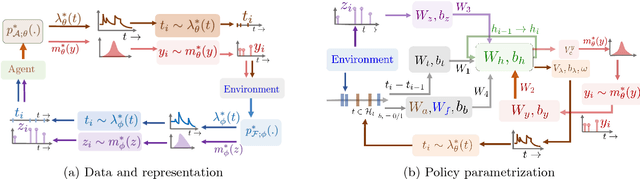
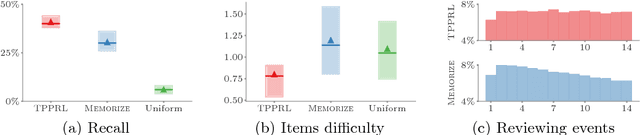
In a wide variety of applications, humans interact with a complex environment by means of asynchronous stochastic discrete events in continuous time. Can we design online interventions that will help humans achieve certain goals in such asynchronous setting? In this paper, we address the above problem from the perspective of deep reinforcement learning of marked temporal point processes, where both the actions taken by an agent and the feedback it receives from the environment are asynchronous stochastic discrete events characterized using marked temporal point processes. In doing so, we define the agent's policy using the intensity and mark distribution of the corresponding process and then derive a flexible policy gradient method, which embeds the agent's actions and the feedback it receives into real-valued vectors using deep recurrent neural networks. Our method does not make any assumptions on the functional form of the intensity and mark distribution of the feedback and it allows for arbitrarily complex reward functions. We apply our methodology to two different applications in personalized teaching and viral marketing and, using data gathered from Duolingo and Twitter, we show that it may be able to find interventions to help learners and marketers achieve their goals more effectively than alternatives.
Stochastic Optimal Control of Epidemic Processes in Networks
Oct 30, 2018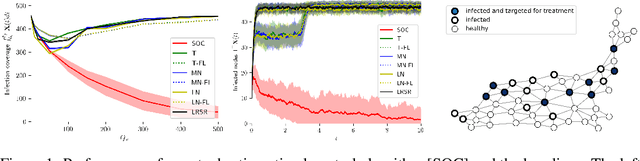
We approach the development of models and control strategies of susceptible-infected-susceptible (SIS) epidemic processes from the perspective of marked temporal point processes and stochastic optimal control of stochastic differential equations (SDEs) with jumps. In contrast to previous work, this novel perspective is particularly well-suited to make use of fine-grained data about disease outbreaks, and it lets us overcome the shortcomings of current control strategies. Our control strategy resorts to treatment intensities to determine who to treat and when to do so, to minimize the amount of infected individuals over time. Preliminary experiments with synthetic data show that our control strategy consistently outperforms several alternatives. Looking into the future, we believe our methodology provides a promising step towards the development of practical data-driven control strategies of epidemic processes.
Designing Random Graph Models Using Variational Autoencoders With Applications to Chemical Design
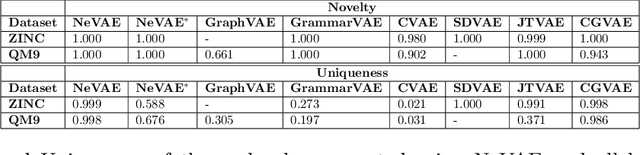
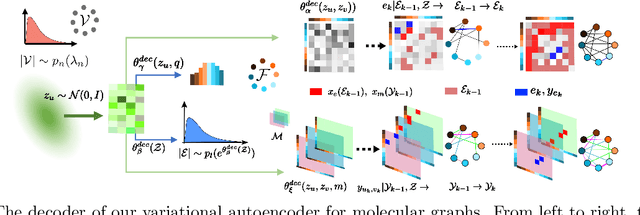
May 23, 2018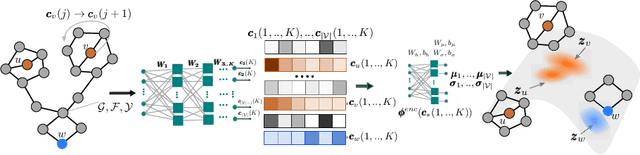

Deep generative models have been praised for their ability to learn smooth latent representation of images, text, and audio, which can then be used to generate new, plausible data. However, current generative models are unable to work with graphs due to their unique characteristics--their underlying structure is not Euclidean or grid-like, they remain isomorphic under permutation of the nodes labels, and they come with a different number of nodes and edges. In this paper, we propose NeVAE, a novel variational autoencoder for graphs, whose encoder and decoder are specially designed to account for the above properties by means of several technical innovations. In addition, by using masking, the decoder is able to guarantee a set of local structural and functional properties in the generated graphs. Experiments reveal that our model is able to learn and mimic the generative process of several well-known random graph models and can be used to discover new molecules more effectively than several state of the art methods. Moreover, by utilizing Bayesian optimization over the continuous latent representation of molecules our model finds, we can also identify molecules that maximize certain desirable properties more effectively than alternatives.